






论文摘要
强化学习从人类反馈(RLHF)的方法被广泛用于增强预训练语言模型(LM),使它们能更好地与人类偏好对齐。然而,现有的基于RLHF的LM在引入新查询或反馈时需要完全重新训练,因为人类的偏好可能在不同的领域或主题之间有所不同。现有的RLHF方法在引入新的查询或反馈时需要对语言模型(LM)进行重新训练,这在实际应用中往往因时间、计算成本和数据隐私问题而不可行。本文提出了CPPO(连续近端策略优化,Continual Proximal Policy Optimization),这是一种用于强化学习中人类反馈(Reinforcement Learning from Human Feedback, RLHF)的持续学习方法。CPPO通过采用加权策略来决定哪些样本用于增强策略学习,哪些样本用于巩固以往经验,从而在策略学习和知识保留之间寻求平衡。实验结果表明,CPPO在持续与人类偏好对齐方面优于现有的持续学习(Continual Learning, CL)基线,并且在非持续学习场景中比PPO(Proximal Policy Optimization)更高效、更稳定。
Introduction
拟解决的问题:现有的RLHF方法在引入新的查询或反馈时需要对语言模型进行完全重新训练,这在实际应用中存在以下问题:
- 时间成本:重新训练需要大量时间。
- 计算成本:重新训练需要大量的计算资源。
- 数据隐私:重新训练可能涉及数据隐私问题,尤其是当数据包含敏感信息时。
- 模型适应性:重新训练可能导致模型在新任务上表现良好,但在旧任务上出现遗忘(catastrophic forgetting)。
创新之处:
- 持续学习能力:CPPO能够在不完全重新训练的情况下,持续地与动态变化的人类偏好对齐。
- 加权策略:通过样本级别的加权策略,CPPO在策略学习和知识保留之间寻求平衡,避免了传统方法中的遗忘问题。
- 高效性和稳定性:与PPO相比,CPPO在非持续学习场景中表现出更高的学习效率和稳定性,尤其是在处理高方差和过拟合样本时。
方法
CPPO 的核心思想是通过样本级别的加权策略来平衡策略学习(policy learning)和知识保留(knowledge retention)。具体来说,CPPO 通过以下步骤实现:
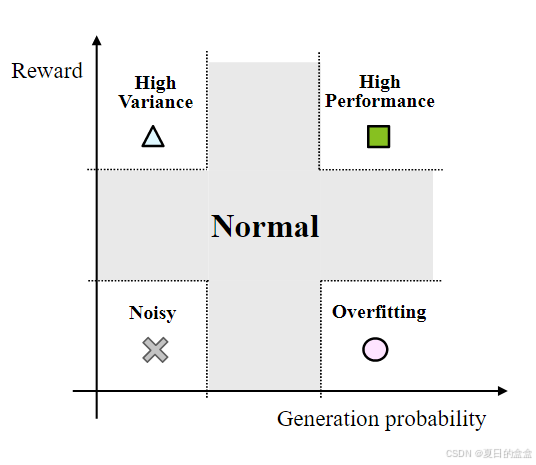
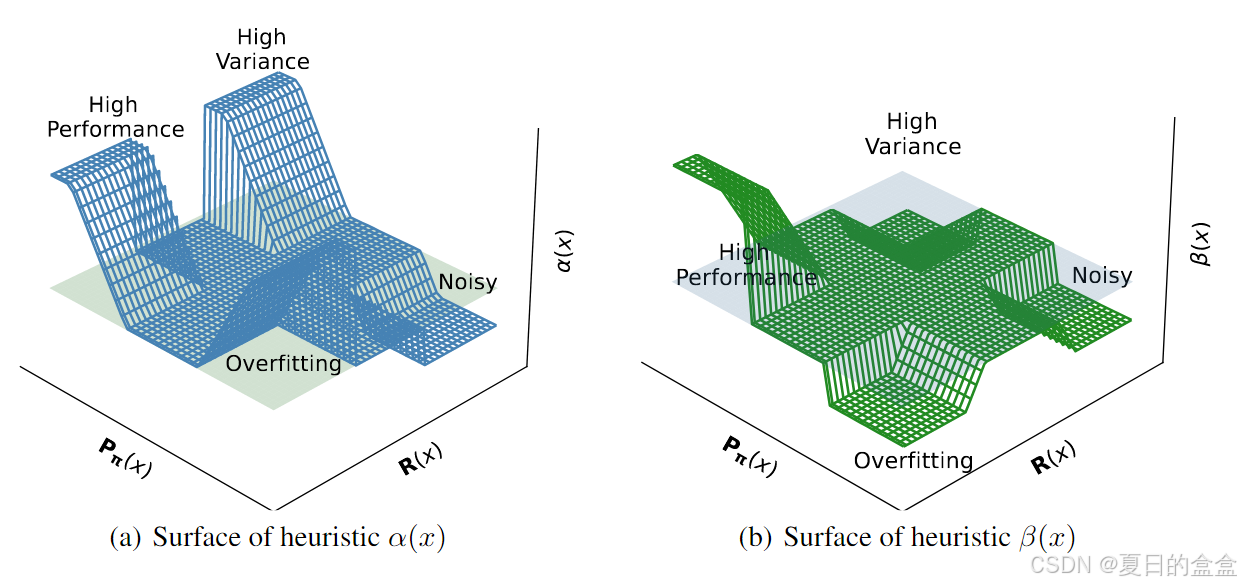
- 样本分类:根据样本的奖励(reward)和生成概率(generation probability),将样本分为五类:高性能样本、过拟合样本、高方差样本、噪声样本和正常样本。
- 加权策略:为每类样本分配不同的策略学习权重(α)和知识保留权重(β)。例如,对于高性能样本,同时增加α和β以巩固知识;对于噪声样本,降低α和β以减少其对学习的影响。
- 优化目标:基于上述加权策略,CPPO设计了一个新的优化目标,通过最大化策略学习和知识保留的加权和来优化模型。
- 权重学习:CPPO提供了两种权重学习方法:启发式方法(heuristic method)和可学习方法(learnable method)。启发式方法根据预定义的规则动态调整权重,而可学习方法则通过优化一个拉格朗日函数来自动学习最佳权重。
3.1 PPO算法
PPO(Proximal Policy Optimization)算法是一种广泛使用的强化学习算法,它通过优化一个剪辑的目标函数来更新策略网络,从而在策略学习过程中保持稳定。PPO 算法的核心思想是通过限制策略更新的幅度来避免过大的策略变化,从而提高训练的稳定性。
PPO 算法的总目标函数可以表示为:
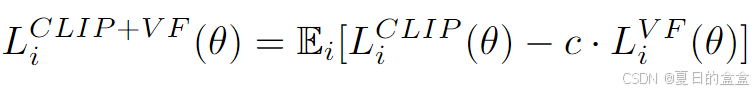
其中:

此外,PPO 算法还引入了熵奖励(entropy bonus)来鼓励策略的探索性:
![]()
![]()
3.2 问题定义
论文提出了一个持续学习人类偏好的任务,该任务在离线持续学习设置下进行。具体来说,任务序列 T={T1,T2,…} 包含多个子任务,每个子任务 都有一个对应的人类偏好数据集
和提示数据集
。对于每个任务
,策略模型
通过在奖励模型
上进行训练来学习人类偏好,其中奖励模型
是基于
学习得到的。
任务的最终目标是学习一个策略模型,使其在所有已学习的人类偏好上最大化总体奖励:

3.3 理论分析
在持续学习(Continual Learning, CL)的背景下,关键挑战是如何在学习新任务的同时保留旧任务的知识。这被称为“稳定性-可塑性困境”(stability-plasticity dilemma):一方面,模型需要足够稳定以保留旧知识;另一方面,模型需要足够灵活以适应新知识。
为了优化持续学习中的目标,需要在策略学习(policy learning)和知识保留(knowledge retention)之间找到一个平衡。具体来说,策略学习的目标是最大化模型生成高奖励结果的概率,而知识保留的目标是保留生成高奖励结果的知识。
为了优化 CL 范式中的目标函数,关键是平衡策略学习和知识保留之间的权衡,即学习一个不仅适合当前任务 t 的策略,而且还保留了先前任务的知识。这通常是通过最大化 πt 的平均奖励来实现的,同时通过基于 KL 的知识蒸馏最小化
和
之间的差异:
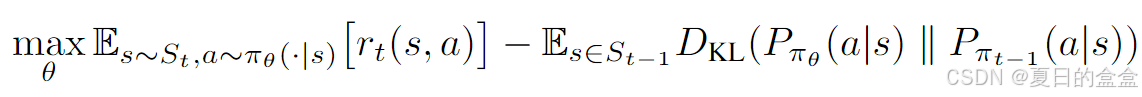
在 RLHF 设置中,我们认为实现策略学习的一种更有效的方法是最大化产生高概率的结果的奖励。这是因为 LM 通常具有巨大的动作空间(词汇量),并采用采样策略,例如有利于高概率生成结果的波束搜索。另一方面,对于知识保留,使
保留
的某些知识以生成高奖励输出而不是全部更重要更为重要。
为了完成上述想法,提出了一个理论上理想的连续RLHF任务目标:
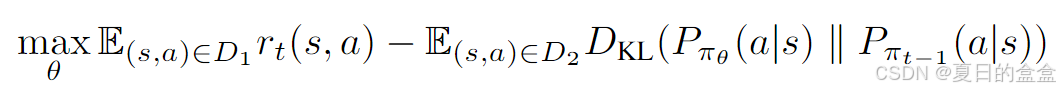
其中:

由于直接优化上述目标函数在实际中不可行(特别是计算 KL 散度需要存储整个词汇表的概率分布),论文提出了一个简化的目标函数。具体来说,用 L2 距离代替 KL 散度,仅计算真实标记的概率差异,从而大大减少了内存需求。简化后的知识保留损失为:
![]()
最终目标函数: 基于上述简化,论文提出了一个实际可操作的目标函数:
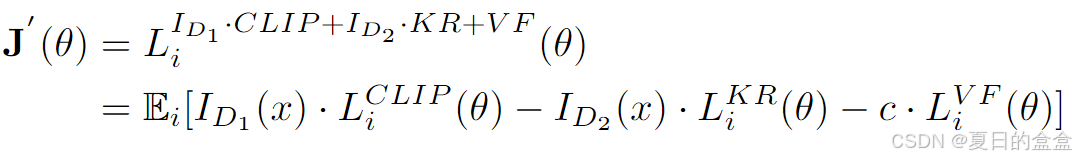
其中:

3.4 加权策略
利用样本平衡权重 α(x) 和 β(x) 来调节策略学习和知识保留过程,旨在找到知识保留和策略学习之间的平衡。最终目标是:
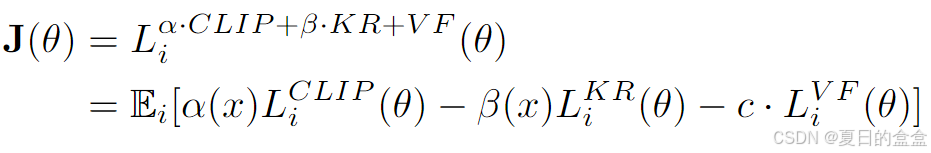
对于任务 t = 1, 2,。.., T.接下来,提出了一种平衡策略学习和知识保留的加权策略。
3.5 平衡策略学习和知识保留
这一部分详细介绍了 CPPO 方法中如何通过样本级别的权重 α(x) 和 β(x) 来平衡策略学习(policy learning)和知识保留(knowledge retention)。
分为三个部分:
- 样本分类:根据样本的奖励 R(x) 和生成概率
,将样本分为五类:高性能样本、过拟合样本、高方差样本、噪声样本和正常样本。
- 权重策略:为每类样本分配不同的策略学习权重 α(x) 和知识保留权重 β(x),以平衡策略学习和知识保留。
- 具体计算:通过操作符 F[⋅] 和 G[⋅] 定义样本的分类阈值,并根据分类结果调整权重。
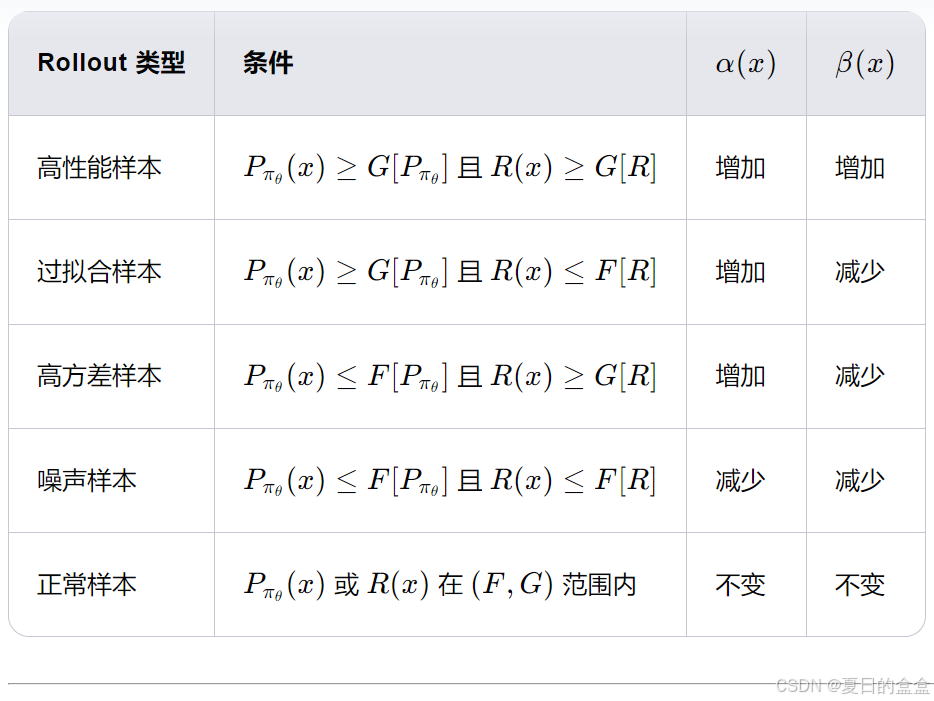
样本分类:为了实现策略学习和知识保留的平衡,首先需要对样本进行分类。根据样本的奖励 R(x) 和生成概率,将样本分为以下五类:
-
高性能样本(High-performance samples):
-
过拟合样本(Overfitting samples):
-
高方差样本(High-variance samples):
-
噪声样本(Noisy samples):
-
正常样本(Normal samples):
权重策略:根据上述分类,为每类样本分配不同的策略学习权重 α(x) 和知识保留权重 β(x)。具体策略如下:
-
高性能样本:α(x) 和 β(x) 均增加。巩固这些样本的知识,因为它们已经表现良好。
-
过拟合样本:α(x) 增加,β(x) 减少。通过策略学习减少这些样本的生成概率,同时减少知识保留以避免过拟合。
-
高方差样本:α(x) 增加,β(x) 减少。通过策略学习增加这些样本的生成概率,同时减少知识保留以降低方差。
-
噪声样本:α(x) 和 β(x) 均减少。减少这些样本对学习过程的影响,避免过优化。
-
正常样本:不改变 α(x) 和 β(x)。目的:保持正常的策略学习和知识保留。
权重的具体计算:为了实现上述策略,论文定义了两个操作符:
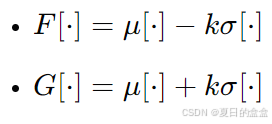
其中,μ 和 σ 分别表示均值和标准差,k 是超参数,用于控制样本的分类阈值。
具体权重策略如下表所示:
3.6 如何平衡权重
上述权重策略构成了 α(x) 和 β(x) 的几个不等式约束,如下表所示:

确定平衡权重需要找到一个满足这些约束的可行解决方案。我们提供了两种方法来确定平衡权重,包括启发式权重方法(上表所示)和可学习权重方法。
启发式方法通过预定义的规则动态调整权重 α(x) 和 β(x)。具体来说,根据样本的分类结果,权重会线性增加或减少。这种方法简单且易于实现,但可能缺乏对动态学习过程的适应性。
其中:

可学习方法通过优化一个拉格朗日函数来自动学习最佳权重 α(x) 和 β(x)。这种方法具有更强的适应性,能够根据动态学习过程自动调整权重,使得在满足预定义的约束条件下,策略学习和知识保留之间的平衡达到最优。
为了实现这一目标,论文构造了一个无约束优化目标函数 Lcoef(ϕ),其中 ϕ 是权重参数。优化目标函数如下:
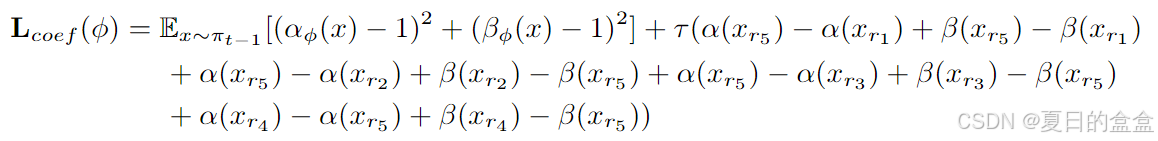
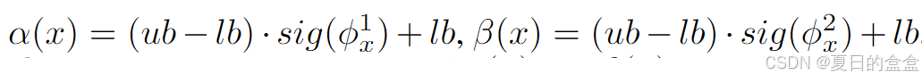
其中:sig表示sigmoid函数,ub和lb表示上届和下届,

结论
-
实验结果:CPPO在持续学习任务中显著优于现有的CL基线方法,并且在非持续学习任务中也表现出比PPO更高的效率和稳定性。
-
稳定性分析:CPPO在训练过程中表现出更好的稳定性,尤其是在处理小模型时,能够有效避免PPO训练中的不稳定性。
-
人类评估:通过人类评估,CPPO生成的摘要与人类和ChatGPT生成的摘要相当,但PPO生成的摘要质量较低。
-
实际应用:CPPO为实际应用中持续更新语言模型提供了一种高效、稳定且保护数据隐私的方法,具有广泛的应用前景。


















 1421
1421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









