






摘要
扩散模型是一类灵活的生成模型,通常通过近似对数似然目标进行训练。然而,大多数扩散模型的使用场景并不直接关心似然,而是关注下游目标,如人类感知的图像质量或药物的有效性。本文研究了直接针对这些目标优化扩散模型的强化学习方法,提出了一种将去噪视为多步决策问题的方法,开发了更有效的策略梯度算法,即去噪扩散策略优化(DDPO)。实验证明,DDPO能够适应文本到图像扩散模型,以优化难以通过提示表达的目标,如图像可压缩性,以及来自人类反馈的目标,如美学质量。此外,DDPO还可以利用视觉语言模型的反馈改善提示与图像的对齐,而无需额外的数据收集或人工标注。
Introduction
拟解决的问题:扩散模型通常通过近似对数似然目标进行训练,但在许多实际应用中,模型的性能评估和优化需要针对特定的下游目标,如图像质量、药物效果等。而这些目标往往难以通过传统的似然估计方法直接优化。因此,本文旨在解决如何直接针对这些下游目标优化扩散模型的问题,特别是对于那些难以通过提示或编程方式指定的目标。
效果图如下所示:

具体来说,图中展示了在三个不同的奖励函数下,即图像可压缩性、美学质量和提示与图像对齐,DDPO如何通过训练逐步优化生成的图像样本:
- 在美学质量奖励函数下,生成的图像逐渐变得更加美观和艺术化;
- 在可压缩性奖励函数下,图像的背景被去除,前景被平滑处理,以减少文件大小;
- 而在提示与图像对齐奖励函数下,生成的图像更加忠实地反映了提示内容。
创新之处:
-
提出了将去噪过程视为多步决策问题的方法,从而能够应用强化学习中的策略梯度算法来优化扩散模型。
-
开发了去噪扩散策略优化(DDPO)算法,该算法在优化扩散模型以满足下游目标方面比基于奖励加权似然的方法更有效。
-
提出了利用视觉语言模型(VLM)作为反馈机制,以自动化的方式替代大规模人工标注,从而实现对扩散模型的优化。
方法:
-
问题建模:将扩散模型的去噪过程建模为马尔可夫决策过程(MDP),其中状态包括上下文、时间步和当前噪声样本,动作是预测的去噪样本,奖励函数根据下游目标定义。
-
策略梯度算法:基于MDP模型,应用策略梯度方法来优化扩散模型的参数。具体地,提出了两种DDPO变体,分别基于得分函数估计器和重要性采样估计器。
-
奖励函数设计:针对文本到图像扩散模型,设计了多种奖励函数,包括基于图像可压缩性、美学质量和视觉语言模型对齐的奖励函数。
Method
DDPO的核心思想是将扩散模型的去噪过程视为一个多步决策问题,并利用强化学习中的策略梯度算法来优化模型参数。通过这种方式,可以直接针对特定的下游目标(如图像质量、提示与图像的对齐等)进行优化,而无需依赖于传统的基于似然的方法。
3.1 前置知识
扩散模型是一种生成模型,通过一个马尔可夫链的前向过程逐渐向数据中添加噪声,然后通过一个反向过程逐步去除噪声以生成样本。具体来说:

考虑条件扩散概率模型,它表示样本x0和相应的上下文c数据集上的分布p(x0|c)。该分布被建模为马尔可夫正向过程 q(xt | xt−1) 的反向,该过程迭代地向数据添加噪声。反转正向过程可以通过训练具有以下目标的神经网络 μθ (xt, c, t) 来完成::
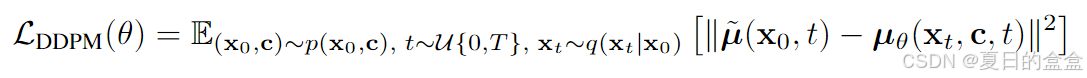
其中:

马尔可夫决策过程 (MDP) 是顺序决策问题的形式化。MDP 由元组 (S, A, ρ0, P, R) 定义,其中 S 是状态空间,A 是动作空间,ρ0 是初始状态的分布,P 是过渡核,R 是奖励函数。在每个时间步 t,代理观察状态 st ∈ S,在 at∈ A 处采取行动,获得奖励 R(st, at),并过渡到新状态 st+1 ∼ P (st+1 | st, at)。代理根据策略 π(a | s) 采取行动。
由于代理作用于MDP,它产生轨迹,轨迹是状态和动作的序列τ = (s0, a0, s1, a1,…,, sT , aT )。强化学习 (RL) 目标是代理最大化 JRL(π),即对其策略采样的轨迹的预期累积奖励:
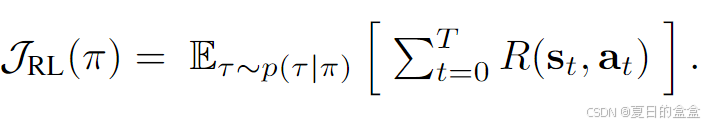
3.2 扩散模型的强化学习训练
问题陈述:我们假设预先存在的扩散模型,可以预先训练或随机初始化。假设采样器固定,扩散模型诱导样本分布 pθ (x0 | c)。去噪扩散 RL 目标是最大化定义在样本和上下文上的奖励信号 r:
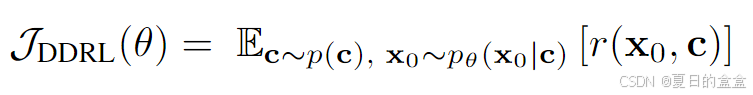
其中,p(c) 是上下文的分布,可以选择为训练数据中的上下文分布。
去噪扩散策略优化:(Denoising Diffusion Policy Optimization, DDPO)通过将去噪过程视为一个多步决策问题,直接优化奖励函数 。这种方法基于策略梯度估计器,能够直接利用去噪过程中的似然和似然梯度。
将去噪过程映射到MDP:

在这种MDP中,轨迹由 T 个时间步组成,最终状态是一个终止状态。每个轨迹的累积奖励等于 r(x0,c),因此最大化 等价于最大化这个MDP中的强化学习目标
。
策略梯度估计: 利用似然和似然梯度,可以直接估计 ∇θJDDRL。DDPO有两种变体:
- DDPOSF(得分函数估计器):
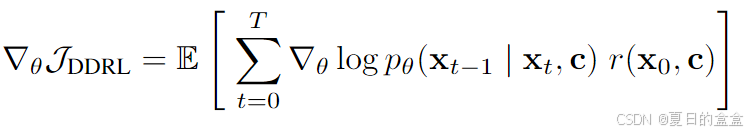
其中期望是通过对由当前参数 θ 生成的去噪轨迹进行的。
- DDPOIS(重要性采样估计器):
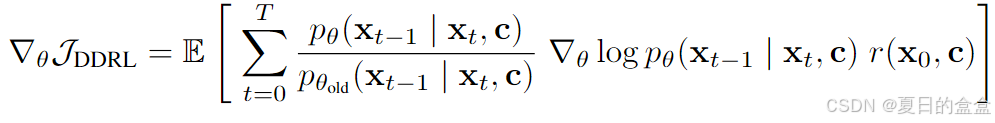
其中,pθold 是旧策略的分布。重要性采样允许使用旧策略生成的数据来更新新策略,从而提高采样效率。
3.3 文本到图像扩散的奖励函数
这一节介绍了在文本到图像扩散模型中使用的多种奖励函数。这些奖励函数用于定义和量化生成图像的质量,从而指导扩散模型的优化过程。分为压缩性、美学性以及一致性。
3.3.1 图像可压缩性
文本到图像扩散模型的生成能力受到训练数据中文本和图像共现的限制。例如,图像很少会用文件大小来标注,因此无法通过提示来指定所需的文件大小。这使得基于文件大小的奖励函数成为一个方便的研究案例,因为它们简单易计算,但无法通过传统的似然最大化或提示工程来控制。
任务定义:
-
压缩性(Compressibility):最小化图像在JPEG压缩后的文件大小。
-
不可压缩性(Incompressibility):最大化图像在JPEG压缩后的文件大小。
实现:
-
固定扩散模型生成的图像分辨率为512x512,因此文件大小仅由图像的可压缩性决定。
-
定义两个任务:压缩性和不可压缩性,分别通过最小化和最大化JPEG压缩后的文件大小来实现。
3.3.2 美学质量
为了捕捉对人类用户有用的奖励函数,作者定义了一个基于感知美学质量的任务。美学质量的评估通常需要人类的主观判断,因此这一任务也构成了从人类反馈中进行强化学习的一个案例。
任务定义:
- 使用LAION美学预测器(Schuhmann, 2022),该预测器基于CLIP嵌入训练,能够给出图像的美学评分。
- 美学质量的评分范围为1到10,其中最高评分的图像大多是艺术作品。
实现:
-
LAION美学预测器是一个线性模型,基于CLIP嵌入进行训练。
-
通过该预测器对生成的图像进行评分,将评分作为奖励函数,指导扩散模型的优化。
3.3.3 自动化提示对齐
提示与图像对齐是文本到图像模型的一个重要目标,但直接指定一个能够捕捉通用提示对齐的奖励函数是困难的,通常需要大规模的人工标注。为了替代额外的人工标注,作者提出使用现有的视觉语言模型(VLM)来提供反馈。
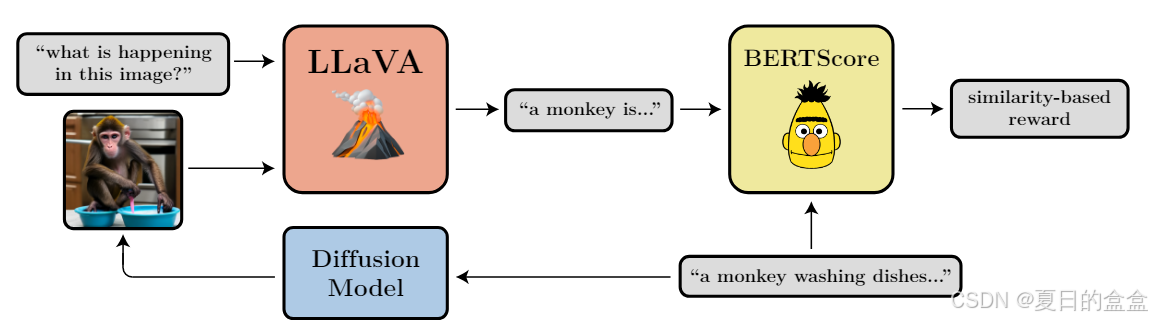
任务定义:
-
使用LLaVA(Liu et al., 2023),一个先进的视觉语言模型,来描述生成的图像。
-
以BERTScore(Zhang et al., 2020)的召回度量作为奖励函数,使用原始提示作为参考句子,VLM描述作为候选句子。
实现:
-
LLaVA为生成的图像提供一个简短的描述。
-
奖励函数是BERTScore的召回度量,衡量语义相似性。
-
生成的样本如果更忠实地包含所有提示的细节,将获得更高的奖励。
结论
本文提出的DDPO方法在优化扩散模型以满足各种下游目标方面表现出色。通过将去噪过程视为多步决策问题,并应用强化学习策略梯度算法,DDPO能够有效地适应文本到图像扩散模型,以优化难以通过提示表达的目标,如图像可压缩性,以及来自人类反馈的目标,如美学质量。此外,利用视觉语言模型的反馈,DDPO还可以改善提示与图像的对齐,无需额外的数据收集或人工标注。实验结果表明,DDPO在优化奖励函数方面优于基于奖励加权似然的方法,并且其优化效果具有较好的泛化能力,能够应用于未见过的提示和场景。


















 1221
1221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









