







基于计算机视觉的工业金属表面缺陷检测综述 (aas.net.cn)
计算机视觉检测技术(Automated optical inspection, AOI)[2]是一种以计算机视觉为基础, 通过自动光学系统获取检测目标图像, 运用算法进行分析决策, 判断目标是否符合检测规范的非接触式检测方法.
表面缺陷检测系统的基本原理是利用金属表面的光学物理性质, 在特定的光学成像条件下, 令缺陷表现出区别于背景的图像特征, 然后通过图像处理技术和缺陷检测算法进行缺陷识别和定位. 其基本流程如图1所示, 大致可分为以下步骤:
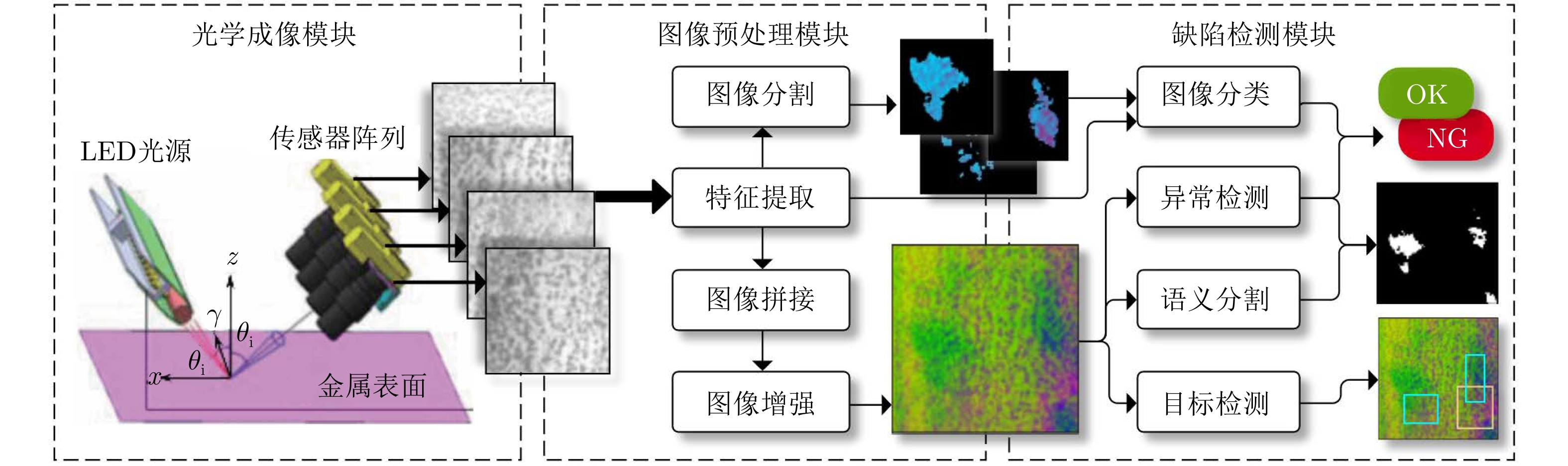
光学成像: 通过光学图像传感方式来获取产品表面二维灰度图像或三维深度图像信息.
图像预处理: 对采集到的图像进行降噪、增强、分割、拼接等图像预处理操作, 以便获得感兴趣区域(Region of interest, ROI)或更适用于图像检测算法的输入尺寸, 并通过各种图像处理算法或他们的组合, 提取出最容易区分缺陷和背景的特征.
缺陷检测: 采用图像对比、统计模式识别、机器学习或深度学习等算法, 从背景中识别出可能存在的缺陷, 对其进行分类和定位.
根据金属表面缺陷检测的背景和成像方式, 通常可分为二维(2D)视觉检测和三维(3D)视觉检测. 二维(2D)视觉检测: 主要针对具有平整表面或圆弧型连续规则结构的表面, 又可进一步分为均匀背景、周期性背景和随机纹理背景下的缺陷检测, 在冷轧、热轧金属板带表面缺陷、精密加工件和金属外壳外观件瑕疵检测等领域得到了广泛应用[3]
三维(3D)视觉检测: 后者针对具有三维复杂结构背景的金属制成品外观进行检测.
在这一领域仍有许多理论和关键应用技术亟待解决. 例如:
1)由于检测对象的表面光学特性复杂多变、种类繁多, 如何设计合适的视觉成像系统来捕获检测对象的图像特征, 突出缺陷与背景的特征差异, 使之达到并超越肉眼检测的效果, 是所有工业表面缺陷检测任务的关键问题.
2)针对二维图像的缺陷检测算法已经相对成熟, 但基于三维深度信息的缺陷检测技术尚未普及. 而工业金属制成品实际大都具有复杂的表面结构, 需求比二维背景表面检测更加广泛, 这些领域背后蕴藏着巨大的商业价值有待发掘.
3)金属表面缺陷检测数据集相对匮乏, 尤其是三维深度图像数据. 基于商业或其他因素影响, 许多研究未能公开它们的数据集. 另一方面, 由于工业产品不断改进生产工艺, 缺陷样本数量稀少, 并且样本类别极度不均衡. 同时在生产工艺改进的过程中, 还有可能出现未曾定义过的缺陷模式, 这进一步增加了检测任务的难度.
光学成像系统不仅仅是简单对被测物体进行照明并用相机获取图像, 根据金属表面和光的物理特性, 合理选用不同的成像技术和光路来获取被测缺陷的特征, 并使之与背景的特征差异最大化, 是实现金属表面缺陷检测的前提. 根据光学成像方式的不同, 光学检测技术可分为基于2D灰度图像信息的检测技术和基于3D深度图像信息的检测技术[10]. 2D检测技术主要用于冷轧、热轧金属板带的生产过程, 而3D检测常用于金属制成品、精密加工件、金属外观件的生产过程中检测.
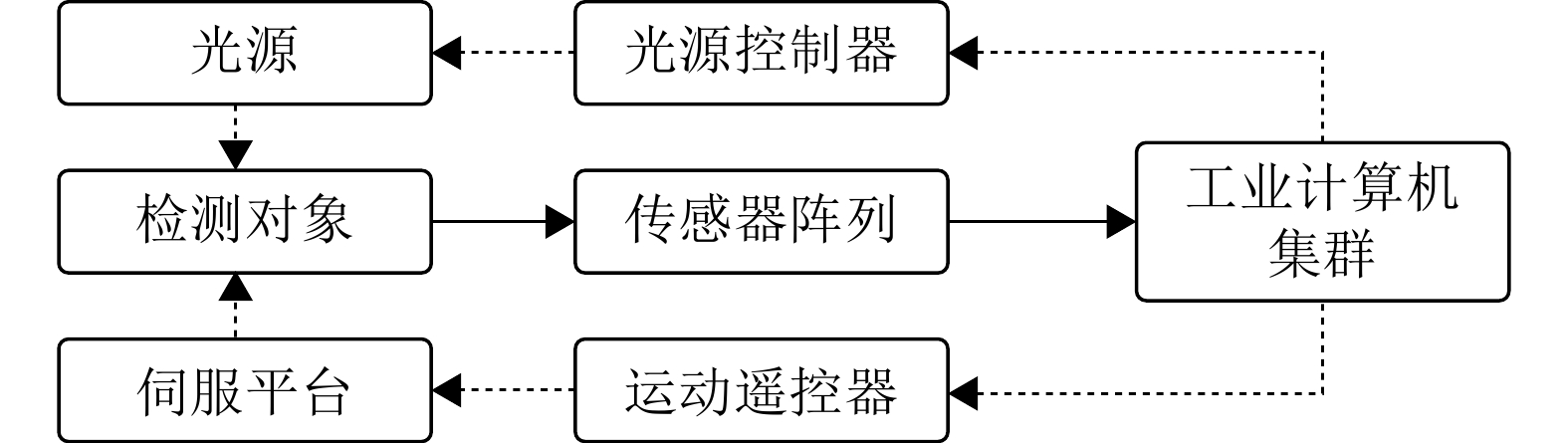
二维成像检测技术
二维成像技术主要包括角度分辨技术[11]、色彩分辨技术[12]和光谱分辨技术[13]. 由于金属制品表面往往颜色、材质单一, 因此色彩分辨技术和光谱分辨技术很少用于金属表面缺陷检测, 最常用的是角度分辨技术.
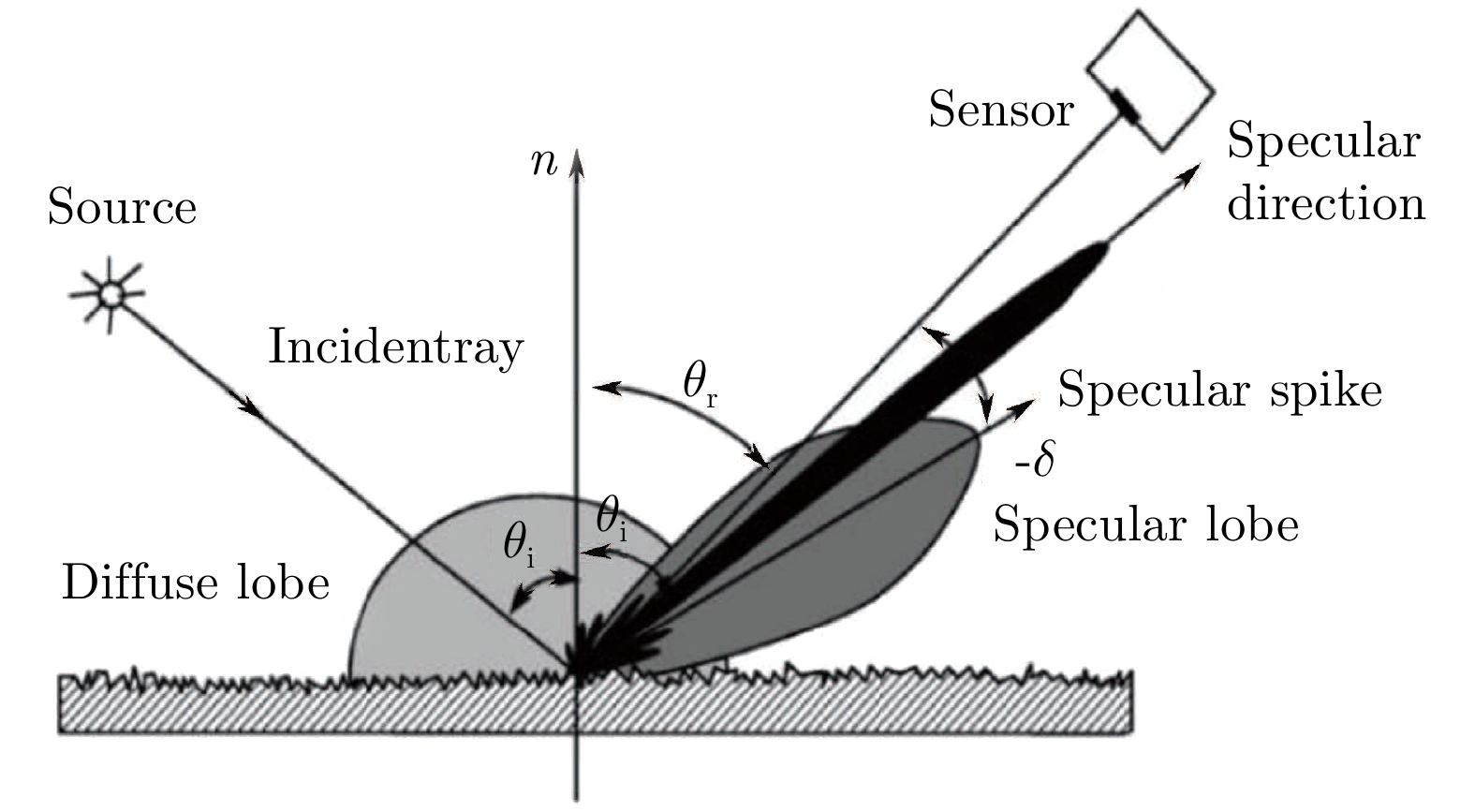
角度分辨技术的基本原理是表面散射模型[14], 如图3所示. 当光束照射金属表面时, 根据产品表面粗糙度的不同会发生朗伯反射、方向反射和镜面反射现象, 通过成像光路获取二维灰度图像, 然后根据缺陷和背景的敏明暗特征来检测缺陷.
朗伯反射又叫均匀反射, 在各个角度的反射光线能量强度几乎相等, 可用双向散射分布函数(BSDF) 来表达; 方向反射发生在光线波长与金属表面粗糙度投影尺寸相耦合的情况下, 反射光线的能量强度在某一空间角内最大; 镜面反射服从镜面反射定律, 其能量分布受金属表面粗糙度和起伏程度的影响. 除此之外, 光线反射还受到微观几何尺度上的表面起伏对光线遮挡的影响. 根据上述效应的影响, 散射光场可分为漫反射光瓣、镜面反射光瓣、镜面反射峰和微观纹理形成的菊花瓣.
根据光的物理反射特性, 针对不同类型的金属表面背景以及缺陷特点, 产生了不同的光学角度散射分辨技术.
通过高强度线光源和线阵CCD相机采集钢板表面图像, 并提出了明场、暗场、漫反射照明技术用于金属表面缺陷检测[15]. 随着光学传感技术的发展, 又出现了同轴、背光等多种照明技术, 这一类技术又被称为角度分辨技术, 如图4.
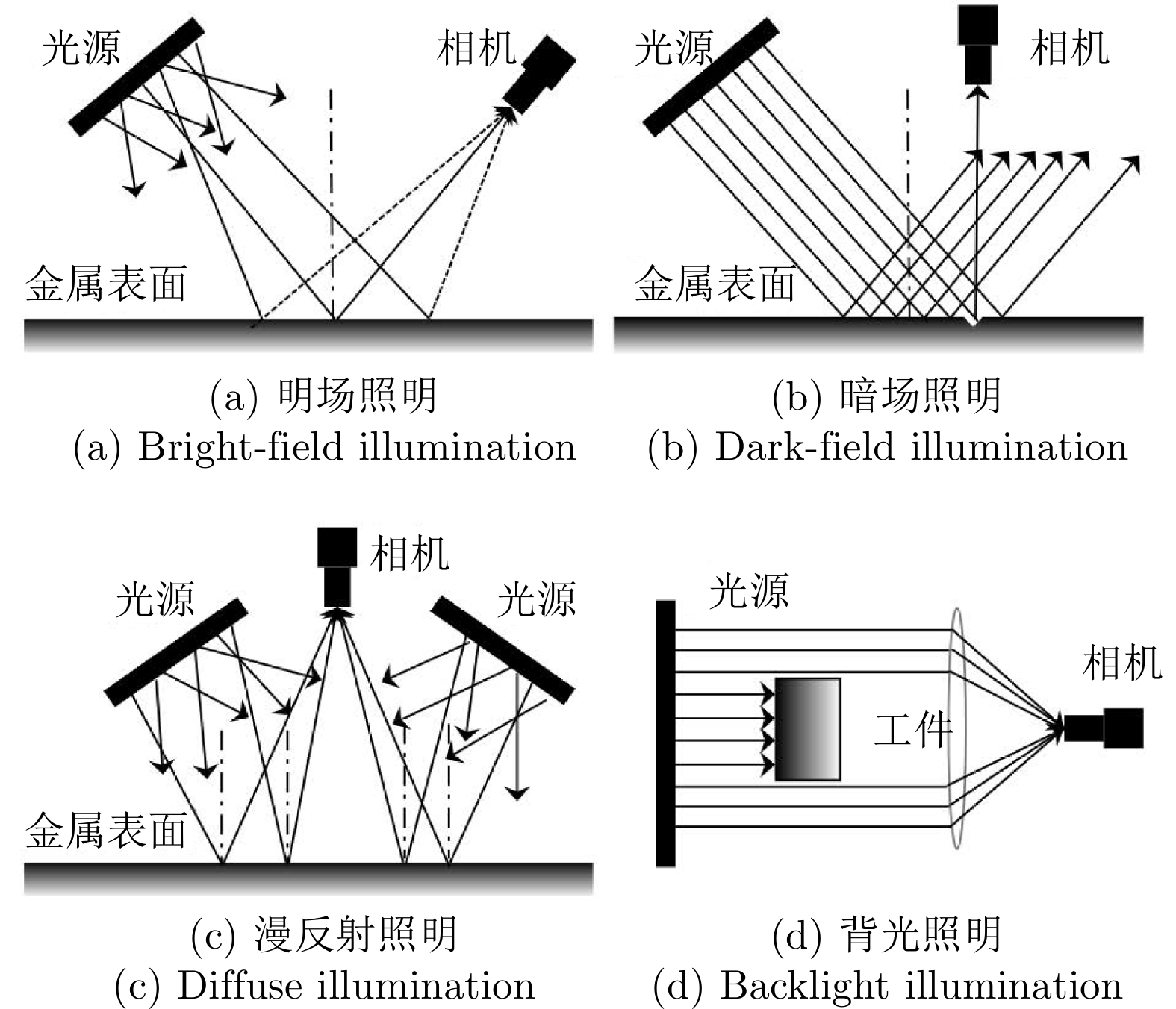
a)明场照明成像方式主要针对均匀的漫反射金属表面背景, 背景成像结果为均匀的明亮图像. 当金属表面存在缺陷时, 反射光将在其他方向发生散射, 从而在明亮的背景中产生暗点。
b)暗场照明成像方式主要针对镜面金属表面, 此时背景的散射光线十分微弱, 背景成像结果为暗灰色图像. 当背景中存在缺陷时, 光线会在多个方向发生散射, 在灰暗的背景中产生明亮的特征。
c)漫反射照明成像主要针对凹凸不平或有压制纹理的金属表面, 光线从不同角度照明被测产品表面形成平滑过渡的图像, 褶皱或划痕则会形成阴影或高亮区域, 从而产生区别于背景的特征。
d)背光照明成像方式针对金属产品外围轮廓, 相机与背光照明光源位于被测金属产品两侧, 光线被金属遮挡产生投影, 在相机中形成清晰的高对比度图像。
多种光学成像方式组合以提升系统的检测性能, 成为该领域的一个重要发展方向.
三维成像检测技术
2D成像方式在检测具有凹凸结构的金属表面时缺少深度、法线方向、曲率等微观特征信息,
3D视觉成像技术可以获取裂纹、辊印等缺陷的深度、法线方向等信息, 如图5, 能够显著提高表面缺陷检测系统的分辨能力.

3D成像检测技术包括光学方法和非光学方法, 其中光学方法应用最为广泛, 主要包括光度立体法、飞行时间法、扫描法、立体视觉法、结构光法和光场3维成像等.
混合成像检测技术
2D成像技术通常可获取高分辨率以及高对比度的图像, 能够更好的捕获缺陷的纹理细节特征信息, 对夹杂、气孔、划痕等微小瑕疵有更好的检测效果. 然而2D成像局限于金属表面形状的投影, 无法获取深度和法线方向等信息, 对于油污、锈迹等伪缺陷容易发生误判; 与此同时3D成像可以提供深度、褶皱、凹凸纹理等形状信息, 但计算量较大且空间分辨率有限, 对微小缺陷特征不够敏感. 混合成像检测技术能够克服两者的局限性, 结合2D纹理细节和3D深度信息更准确的判别缺陷, 在相同成像条件下准确率高于单一成像方式检测技术,如图8所示. 但这一类技术实现成本较高, 目前尚难以推广.
图像预处理技术
图像预处理包括图像增强、特征提取、图像分割和拼接等技术. 降噪有助于消除任何可能掩盖缺陷的不必要的视觉干扰或干扰. 图像增强技术如直方图均衡化和对比度拉伸可以帮助提高缺陷的可见性和对比度. 图像分割有助于将缺陷从图像的其余部分分离出来, 使它们更容易分离和分析.
图像增强
在金属表面缺陷检测系统中, 图像预处理的主要任务是抑制噪声并增强缺陷区域的特征, 令图像更容易被人眼观察或者被算法检测. 图像增强的常用方法可分为基于滤波器的方法、基于模型的方法和基于学习的方法.
基于滤波器的方法利用了噪声能量和正常图像的频谱则分布在一定范围区间的特点[35], 通过人工设计的带通滤波器来抑制噪声, 常见的方法包括快速傅里叶变换、小波方法[36] 等.
基于模型的方法尝试对噪声和复原图像的分布进行建模, 并使用模型分布作为先验来获得清晰的复原图像和优化算法[37], 包括非局部自相似模型(NSS)、梯度模型、稀疏模型和马尔科夫随机场模型.
基于学习的方法则将图像去噪任务定义为学习一个有噪声图像到正常图像的映射, 一般可分为基于传统机器学习和基于深度学习的方法.
图像特征提取
特征提取将高维图像空间的样本特征映射到低维特征空间, 以便缺陷检测算法进行处理. 这就要求提取出的特征不仅可以很好的描述图像, 同时可以更好的区分不同类别的对象.
目前针对二维成像检测技术的特征提取已经相对成熟. 而针对三维点云数据则有两种处理方式, 一种将三维点云数据变换到二维图像域并进行二维图像特征提取, 另一种方式则直接从三维点云数据中捕获形状特征用于表面缺陷识别任务.
二维图像特征提取
统计法把纹理和形状看作随机变量, 用统计量来表述纹理的随机变量分布, 包括直方图特征、灰度共生矩特征(GLCM)[38]、局部二值模式(LBP)[39]、方向梯度直方图(HOG)特征[40]、SIFT特征[41-42]、Haar-like特征[43-44] 等.
信号处理法把图像当做二维分布的信用, 通过设计滤波器将纹理转到变换域, 并采用响应的能量准则提取纹理特征, 主要包括傅里叶变换、Gabor滤波器[45-46]、小波变换、Laws纹理等. 模型法尝试拟合一个模型, 将不同取值的模型参数作为纹理特征, 包括随机马尔科夫场(MRF)、分形模型和自回归模型等, 这一类方法的关键在于如何估计模型的参数.
与手工设计的传统特征提取方法相比, 深度学习方法从大量数据中自动学习特征表示, 相对于传统方法表现出了显著的优势. 基于深度学习的图像特征提取方法主要包括基于深度卷积网络(CNN) 的方法和基于ViT(Vision Transformer)[51]的方法[7].
三维点云特征的提取
图像分割
在大多数工业场景下仅对产品某一块区域是否存在缺陷感兴趣, 因此需要先定位感兴趣区域 (ROI) 后, 再对ROI区域进行缺陷检测和分类, 以降低计算消耗并提高检测效率.
图像分割的原则是使划分后的子图保持内部相似性最大、同时子图之间相似性最小. 经典分割方法主要包括阈值法、区域生长法、分水岭算法、边缘检测法、小波变换法[58]和基于主动轮廓模型的方法.
图像拼接
在工业金属板、带加工场景, 由于检测对象往往尺寸较大, 为了同时满足大视场、高分辨率成像的需求, 往往采用扫描成像和阵列成像, 或者两种方法的组合来实现.
图像拼接技术就是为了在阵列成像系统中, 将多个光学传感器获取的图像通过图像匹配、重投影和融合技术来生成更大画布的图像, 以满足大幅面金属表面在线缺陷检测的需求.
图像拼接可分为三个步骤: 图像匹配(Registration)、重投影(Reprojection)和融合(Blending)[64]. 图像匹配通过求解多个图像坐标系之间的几何变换矩阵来寻找几何对应关系; 重投影通过几何变换将多张图像投影到同一坐标系; 最后融合图像之间重叠的像素, 获取在空间上或者通道上扩展后的图像. 在工业金属表面检测领域, 通常对空间精度有较高的要求, 因此往往使用图像像素的特征进行图像匹配.
缺陷检测器
缺陷检测器的主要功能是从特征图中识别缺陷、并对缺陷进行分类和定位. 根据表面缺陷检测算法的任务目标和实现原理, 大致可分为模板匹配[66]、图像分类、目标检测、图像语义分割和图像异常检测[67]五类.
图像分类把缺陷检测视为分类问题, 即判断图像窗口内是否为缺陷, 或属于哪一类缺陷[68].
目标检测可以一次性检测出缺陷的类别、位置和大小, 其中缺陷的位置和大小可以用一个包围盒 (Bounding box) 来描述[69].
这些算法会将已知的缺陷归纳成明确的类别, 通过标签对缺陷图像的位置、大小、边缘、类别进行标注, 因此这类方法更关注缺陷的特征, 通常用有监督学习的方式来构造和训练模型. 而异常检测则关注正常产品的特征分布范围, 将与正常产品有明显不同的样本都看作缺陷样本, 通常只需要无缺陷样本即可进行训练, 该方法又被称为异常检测, 更关注正常样本的特征[71].
模拟匹配
模板匹配 (Template matching) 根据已知模板图像到另一待检图像中寻找与模板图像相似的子图像, 然后通过相似度度量计算模板与待检样本之间的相似性, 即可判断样本是否存在缺陷.
模板匹配方法一般可分为两大类, 一类是基于灰度匹配的方法, 另一类是基于特征匹配的方法.
基于灰度匹配的方法[73]也称为图像相关匹配算法, 是一种逐像素地把一个匹配窗口与模板图像的所有可能窗口的灰度阵列按某种相似性度量方法进行搜索比较的匹配方法. 图像相关匹配算法具有计算量小、易于硬件实现等优点, 但是要求两幅图像有大量重复像素.
基于特征的方法大致可分为点特征匹配[74]、边缘特征匹配[75]和区域匹配三大类别. 点匹配通常用人工设计的特征提取方法, 例如Harris特征、SURF特征、ASIFT特征、光流法等[76]. 边缘特征包括LoG算子、Robert算子、Sobel算子、Canny算子等. 由参与匹配的点特征、边缘特征构成特征空间, 在特征空间中通过相似度度量来确定模板与待检样本特征之间的相似性, 它通常定义为某种代价函数或者距离函数. 经典的相似度度量包括Minkowski距离、Hausdorff距离、互信息等.
图像分类
基于图像分类的表面缺陷检测算法将已知的缺陷归纳成明确的类别, 通过算法给样本分配一个标签, 以实现最小的分类误差. 通过与滑动窗口法组合, 图像分类可以实现较粗粒度的缺陷定位.
通过图像分割与图像分类组合, 可以实现像素级的缺陷边界检测. 根据模型结构设计中是否有神经网络参与, 通常又可分为传统机器学习方法和基于深度学习的方法两大类.
传统机器学习方法
统计模式识别就是利用有限数量的给定样本集, 在已知总体样本统计模型或已知判别函数类的条件下, 根据一定准则学习一个模型, 将样本特征空间划分为c个区域, 根据样本落入哪一个区域来判别样本所属的类别.
通过图像预处理技术抑制噪声、并通过特征提取和特征选择来控制样本特征空间, 使样本在特征空间中的分布尽可能满足以上条件. 在将原始图像信息映射到特征空间后, 即可通过各种准则函数设计分类器, 常用的分类器包括贝叶斯分类器、决策树、线性判别器、K近邻法、支持向量机、集成分类方法等.
基于深度学习的方法
一般而言, 表面缺陷分类往往采用经过预训练的VGG、ResNet、DenseNet、SENet等网络作为骨干网络, 然后针对实际问题搭建简单的网络结构, 输入一副测试图像到网络中, 输出缺陷分类及其置信度, 或者一组特征向量. 根据分类网络的实现方法差异, 可将其细分为直接用网络分类、利用网络进行缺陷定位和利用网络作为特征提取器三种方式.
与基于手工特征提取的早期方法相比, 深度度量学习 (Deep metric learning) 使用深度神经网络直接学习相似度度量[87]. 这种方法对于个体级别的细粒度识别非常有用, 常见的应用是图像匹配、行人重识别[88]或人脸识别[89].
常见的度量学习架构包括孪生网络(Siamese network) 和三元网络[90]. 不同于表征学习输入单幅图像来进行分类、定位或分割任务, 孪生网络的输入为两幅成对图像, 通过网络学习输入图片的相似度, 来判断是否属于同一个类别.
如图10 所示, 在三元网络架构中[91], 由三个不同图像组成的三元组被输入同一个网络, 其中两张属于同一类, 一张属于不同的类, 然后训练网络以创建一个特征空间, 在该空间中同类别样本之间的距离比不同类别样本之间的距离要小.
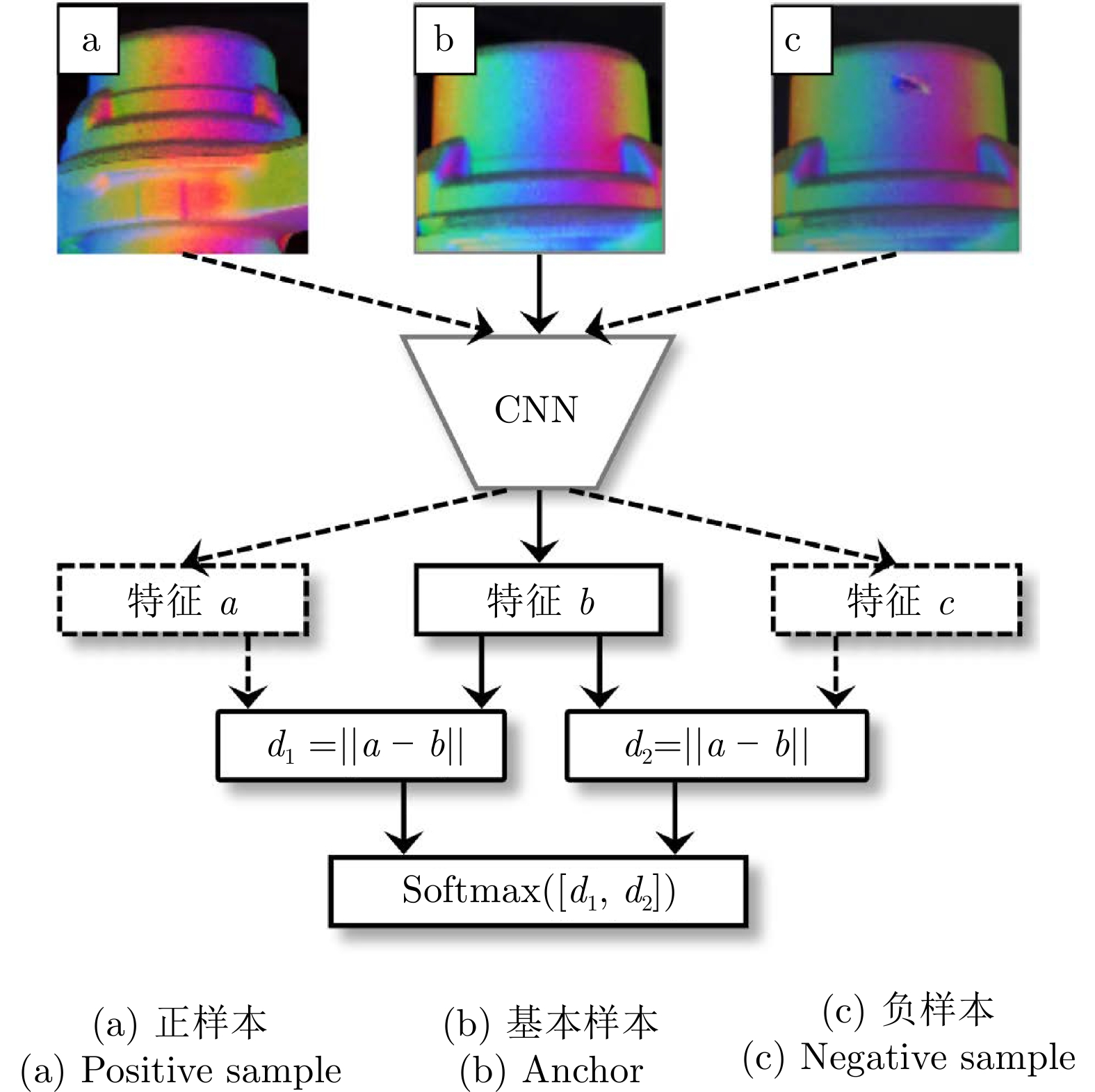
深度度量学习用于表面缺陷检测的一个基本策略是计算正常样本与待检样本之间的距离.
与表征学习相比, 度量学习可以看作学习样本在特征空间中的流形分布, 而表征学习则可看作学习样本在特征空间的分界面. 在工业金属表面缺陷检测领域, 经常使用人工生成负样本来训练网络以解决负样本稀少的问题.
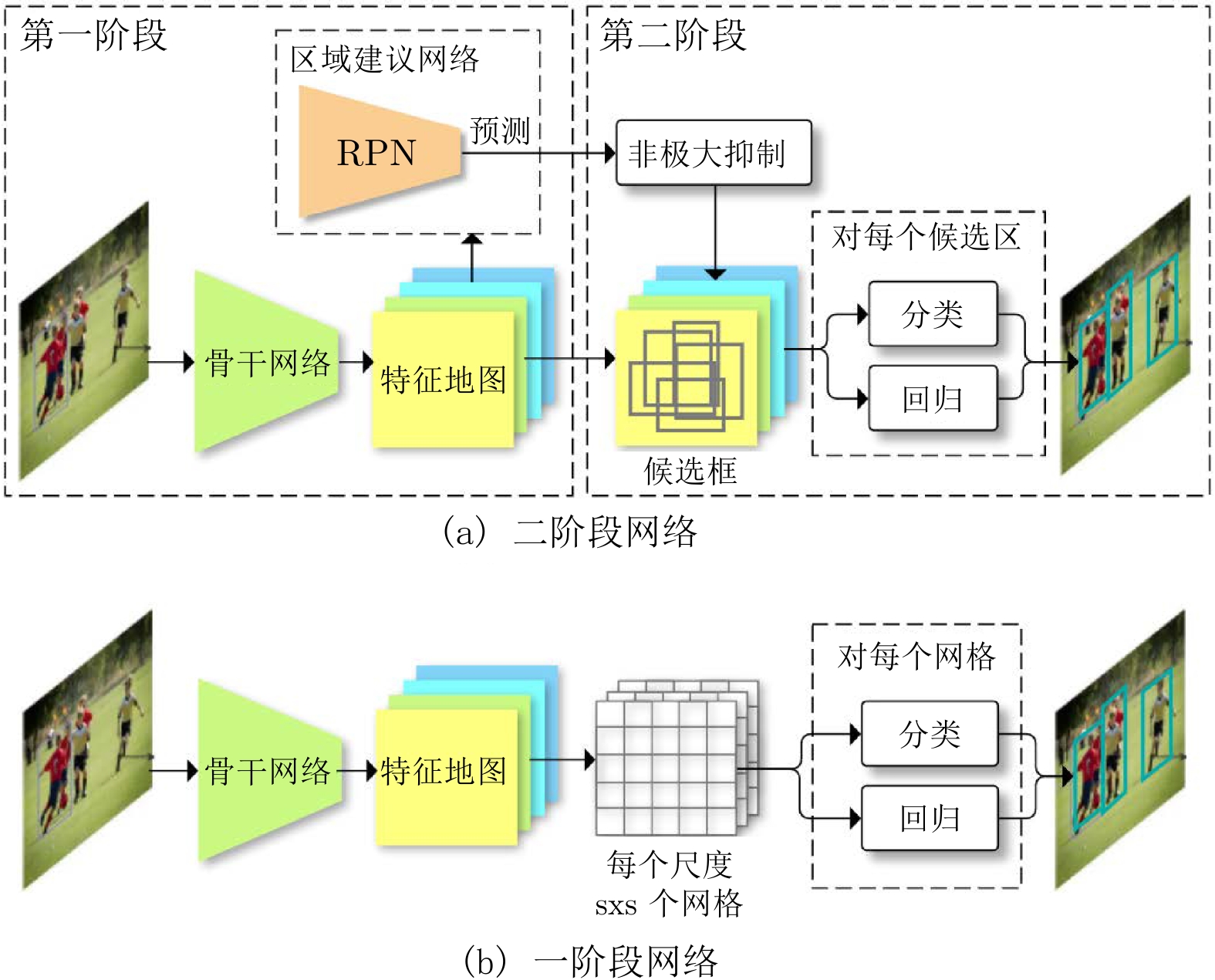
二阶段网络
一阶段网络
相比二阶段网络, YOLO不需要提议候选框, 可直接根据全图背景信息识别出所有的物体的类别和位置, 因此又被称为Region-free方法, 流程如图12(b).
语义分割
语义分割网络将表面缺陷检测任务转化为像素级分割任务, 一种简单的分割网络可以将正常背景与缺陷区域分割; 另一种网络可以将多个缺陷分割成不同的实体. 语义分割网络不仅能分割出缺陷, 而且可以精确描述缺陷的位置、类别以及像素级的集合属性, 例如长度、宽度、面积、轮廓、几何中心等等. 根据分割网络的原理不同, 可以分为基于全卷积神经网络的方法和基于上下文知识的方法.
全卷积神经网络
全卷积神经网络 (Full connected network, FCN)是一种经典的端到端图像语义分割方法, 网络中所有的层都是卷积层, 故称为全卷积神经网络[122]. 全卷积神经网络由三种结构组成: 卷积 (Convolutional)、上采样 (Upsample) 和跳级 (Skip Layer).
而在FCN网络中, 高维特征图通过上采样 (Upsample) 操作将图像放大回原图像的尺寸, 输出像素级分类. 但是在多次下采样过程中损失了位置信息, 因此得到的分割结果比较粗糙, 所以作者通过跳级, 将倒数几层的输出也进行上采样, 并与最后一层的输出结果混合.
基于上下文信息的方法
语义分割是一种像素级标注任务, 一般FCN网络的一元损失函数只考虑了标注中的独立像素, 而忽略了与相邻像素之间的上下文语义关系. 同时由于卷积层的感受野只能随层数线性增加的限制, CNN网络并不擅长掌握图像的全局上下文信息. 为了解决这个问题, 通常采用以下几种方法: 条件随机场(Condition random field, CRF)、循环神经网络(RNN)、多尺度特征融合、图神经网络(GCNs)和基于记忆(Memory-based)的方法等.
异常检测
在实际工业生产场景中, 大量数据是缺乏标注的, 随着生产工艺的变化, 未定义过的缺陷类型也可能出现, 这就给表面缺陷检测带来了极大的挑战. 基于无监督或弱监督学习的图像异常检测技术是解决这个问题的有效手段. 传统表面缺陷检测方法通常会训练一个模型来拟合正常图像, 然后在检测阶段根据待检样本与模型之间的差异来进行异常检测. 基于深度学习的方法尝试重构一个正常样本, 并根据重构误差来检测可能存在的表面缺陷.


















 2861
2861

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









