






引言
与第一期相比,增加了对文件的处理。如果是docx文件,会把文件内部的标题实体和关系也提取出来;其他文件就是增加了一个content属性(包含文件的所有内容)。
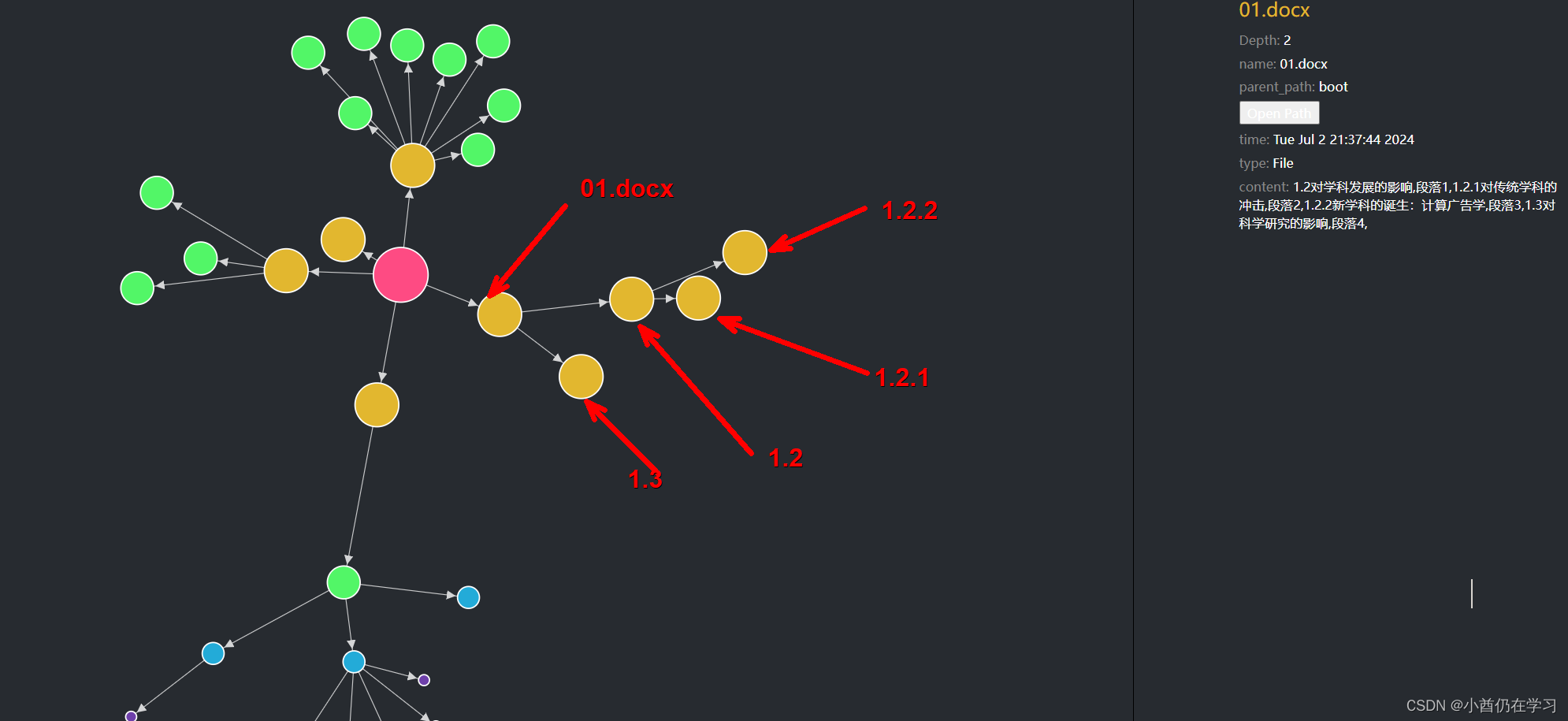
最后的可视化效果:
箭头指向就是表示包含关系,01.docx是文档,1.2,1.3等是章节。
代码
ner_excel.py:
import os
import pandas as pd
from datetime import datetime
import time
from omegaconf import DictConfig
import hydra
from hydra import utils
import re
from docx import Document
import sys
# 获取文件或文件夹时间属性的函数
def get_attributes(path,root_dir):
try:
stat = os.stat(path)
relative_path = os.path.relpath(path, os.path.dirname(root_dir))
# parent_dir = '' if path == root_dir else os.path.dirname(relative_path)
attributes = {
'Name': os.path.basename(path),
'Path': path,
'Creation Time': time.ctime(stat.st_ctime),
# 'Modification Time': datetime.fromtimestamp(stat.st_mtime),
# 'Access Time': datetime.fromtimestamp(stat.st_atime),
'Type': 'Directory' if os.path.isdir(path) else 'File',
'Title': None,
'Content': None,
# 'parent_title': None,
}
if os.path.isfile(path):
if path.endswith('.txt') or path.endswith('.py'):
with open(path, 'r', encoding='utf-8') as file:
attributes['Content'] = file.read()
return attributes
except Exception as e:
print(f"Error processing {path}: {e}")
return {'Path': os.path.basename(path), 'Creation Time': None, 'Type': None}
def dir_content(doc_path, root_dir):
all_attributes = []
# 提取标题层级
def get_heading_level(paragraph):
if paragraph.style.name.startswith('Heading'):
# 提取标题级别(Heading 1, Heading 2, etc.)
level = int(paragraph.style.name.split(' ')[-1])
return level
return None
document = Document(doc_path)
doc_name = os.path.basename(doc_path)
# 当前段落内容
current_content = []
number = 0
# 栈,存储标题和标题级别
stack = [(number, doc_name, 0, [])]
for paragraph in document.paragraphs:
level = get_heading_level(paragraph)
if level is not None:
current_heading = paragraph.text.strip()
stack[-1][3].extend(current_content)
current_content = []
number += 1
stack.append((number, current_heading, level, [current_heading]))
else:
current_content.append(paragraph.text.strip())
stack[-1][3].extend(current_content)
# 更新每个节点的内容
for i in range(0, len(stack) - 1):
j = i + 1
while j < len(stack) and stack[i][2] < stack[j][2]:
stack[i][3].extend(stack[j][3])
j += 1
# 遍历stack
for i in range(len(stack)):
current_number, current_title, current_level, current_content = stack[i]
attribute=get_attributes(doc_path,root_dir)
current_content = ','.join(current_content).strip('"')
# 查找父标题
parent_title = None
for j in range(i - 1, -1, -1):
if stack[j][2] < current_level:
parent_title = stack[j][1]
break
attribute['Content']=current_content
attribute['Title']=current_title
# attribute['parent_title']=parent_title
all_attributes.append(attribute)
return all_attributes
@hydra.main(config_path='conf', config_name='config', version_base='1.1')
def main(cfg: DictConfig):
cwd = utils.get_original_cwd()
cfg.cwd = cwd
# 定义要处理的根目录和结果存储目录
root_dir = os.path.join(cwd,cfg.root_dir)
result_dir = os.path.join(cwd,cfg.excel_path)
os.makedirs(result_dir, exist_ok=True)
# 获取根目录本身的属性
all_attributes = [get_attributes(root_dir,root_dir)]
# 遍历根目录下的所有文件夹和文件
for dirpath, dirnames, filenames in os.walk(root_dir):
dirnames.sort()
filenames.sort()
# 获取当前文件夹下所有子文件夹的属性
for dirname in dirnames:
all_attributes.append(get_attributes(os.path.join(dirpath, dirname),root_dir))
# 获取当前文件夹下所有文件的属性
for filename in filenames:
# all_attributes.append(get_attributes(os.path.join(dirpath, filename),root_dir))
if filename.endswith('.docx') and os.path.getsize(os.path.join(dirpath,filename)) > 0:
all_attributes.extend(dir_content(os.path.join(dirpath, filename),root_dir))
else:
all_attributes.append(get_attributes(os.path.join(dirpath, filename),root_dir))
# 将所有属性保存到一个CSV文件
df = pd.DataFrame(all_attributes)
csv_filename = os.path.join(result_dir, 'ner_all.xlsx')
df.index.name = 'ID'
df.to_excel(csv_filename, index=True)
print("所有属性已成功提取并保存到excel文件中。")
if __name__ == '__main__':
main()
triples_run.py
import os
import pandas as pd
import time
from omegaconf import DictConfig
from docx import Document
import hydra
from hydra import utils
import re
# 从ner_all.csv中读取路径和编号映射关系
def load_number_mapping(ner_all_path):
df = pd.read_excel(ner_all_path,dtype={'Path':str,'Title':str})
df['path_title'] = df.apply(lambda row: os.path.join(str(row['Path']), str(row['Title'])), axis=1)
number_mapping_title = dict(zip(df['path_title'], df['ID']))
number_mapping=dict(zip(df['Path'], df['ID']))
return number_mapping_title,number_mapping
def get_attributes(path, number_mapping,root_dir):
# 获取从根目录到当前路径的相对路径
relpath_path = os.path.relpath(path, os.path.dirname(root_dir))
# 获取当前路径的编号
number = number_mapping.get(path, None)
try:
stat = os.stat(path)
parent_dir = '' if path == root_dir else os.path.dirname(relpath_path)
# 计算当前路径相对于root_dir的深度
depth = relpath_path.count(os.sep) + 1
attributes = {
'Number': number,
'Name': os.path.basename(path),
'Parent': parent_dir,
'Path': relpath_path,
'Creation Time': time.ctime(stat.st_ctime),
'Type': 'Directory' if os.path.isdir(path) else 'File' ,
'Depth': depth ,
'Title': None,
'Content': None,
'Parent_title': None,
}
if os.path.isfile(path):
if path.endswith('.txt') or path.endswith('.py'):
with open(path, 'r', encoding='utf-8') as file:
attributes['Content'] = file.read()
return attributes
except Exception as e:
print(f"Error processing {path}: {e}")
return {'Number': number, 'Path': os.path.basename(path), 'Creation Time': None,
'Type': None, 'Depth': None, 'Content': f"Error processing file: {e}"}
def dir_content(doc_path, root_dir,number_mapping_title,number_mapping):
all_attributes = []
relationships = []
# 提取标题层级
def get_heading_level(paragraph):
if paragraph.style.name.startswith('Heading'):
# 提取标题级别(Heading 1, Heading 2, etc.)
level = int(paragraph.style.name.split(' ')[-1])
return level
return None
document = Document(doc_path)
doc_name = os.path.basename(doc_path)
# 当前段落内容
current_content = []
path_title=os.path.join(doc_path,doc_name)
number = number_mapping_title.get(path_title, None)
# 栈,存储标题和标题级别
stack = [(number, doc_name, 0, [])]
for paragraph in document.paragraphs:
level = get_heading_level(paragraph)
if level is not None:
current_heading = paragraph.text.strip()
stack[-1][3].extend(current_content)
current_content = []
doc_path_title= os.path.join(doc_path,current_heading)
number = number_mapping_title.get(doc_path_title, None)
stack.append((number, current_heading, level, [current_heading]))
else:
current_content.append(paragraph.text.strip())
stack[-1][3].extend(current_content)
# 更新每个节点的内容
for i in range(0, len(stack) - 1):
j = i + 1
while j < len(stack) and stack[i][2] < stack[j][2]:
stack[i][3].extend(stack[j][3])
j += 1
# 遍历stack
for i in range(len(stack)):
current_number, current_title, current_level, current_content = stack[i]
attribute=get_attributes(doc_path,number_mapping,root_dir)
current_content = ','.join(current_content)
# 查找父标题
parent_title = ''
for j in range(i - 1, -1, -1):
if stack[j][2] < current_level:
parent_title = stack[j][1]
break
if parent_title:
doc_path_fa_title=os.path.join(doc_path,parent_title)
parent_number=number_mapping_title.get(doc_path_fa_title, None)
relationships.append((parent_number,current_number,'include'))
else:
attr=get_attributes(os.path.dirname(doc_path),number_mapping,root_dir)
parent_number=attr['Number']
relationships.append((parent_number,current_number,'include'))
attribute['Number']=current_number
attribute['Content']=current_content
attribute['Title']=current_title
attribute['Parent_title']=parent_title
all_attributes.append(attribute)
return all_attributes,relationships
@hydra.main(config_path='conf', config_name='config', version_base='1.1')
def main(cfg: DictConfig):
cwd = utils.get_original_cwd()
cfg.cwd = cwd
# 定义要处理的根目录和结果存储目录
root_dir = os.path.join(cwd, cfg.root_dir)
result_dir = os.path.join(cwd, cfg.triple_number_path)
os.makedirs(result_dir, exist_ok=True)
# 读取ner_all.xlsx中的路径和编号映射关系
ner_all_path = os.path.join(cwd, 'excel','ner_all.xlsx')
number_mapping_title,number_mapping = load_number_mapping(ner_all_path)
# 定义结果文件路径
csv_filename_ner = os.path.join(result_dir, f'ner.csv')
csv_filename_relation = os.path.join(result_dir, f'relation.csv')
# 在循环开始之前删除文件
if os.path.exists(csv_filename_ner):
os.remove(csv_filename_ner)
if os.path.exists(csv_filename_relation):
os.remove(csv_filename_relation)
# 开始处理根目录
root_attributes = [get_attributes(root_dir, number_mapping,root_dir)]
df_ner = pd.DataFrame(root_attributes)
df_ner.to_csv(csv_filename_ner, mode='a',index=False, header=False)
# 获取当前目录下所有子文件夹和文件的属性
for dirpath, dirnames, filenames in os.walk(root_dir):
if not dirnames and not filenames:
continue
dirnames.sort()
filenames.sort()
all_attributes_tail = []
relationships = []
# 获取子文件夹的属性
all_attributes_head = [get_attributes(dirpath, number_mapping,root_dir)]
head = all_attributes_head[0]['Number']
for dirname in dirnames:
sub_dirpath = os.path.join(dirpath, dirname)
tail_attributes = get_attributes(sub_dirpath, number_mapping,root_dir)
all_attributes_tail.append(tail_attributes)
tail = tail_attributes['Number']
relationships.append((head, tail, 'include'))
# 获取文件的属性
for filename in filenames:
filepath = os.path.join(dirpath, filename)
if filepath.endswith('.docx') and os.path.getsize(filepath) > 0:
some_attributes,some_relationships =dir_content(filepath,root_dir,number_mapping_title,number_mapping)
all_attributes_tail.extend(some_attributes)
relationships.extend(some_relationships)
else:
tail_attributes = get_attributes(filepath, number_mapping,root_dir)
tail = tail_attributes['Number']
relationships.append((head, tail, 'include'))
all_attributes_tail.append(tail_attributes)
df_tail = pd.DataFrame(all_attributes_tail)
df_tail.to_csv(csv_filename_ner, mode='a',index=False, header=False)
df_relation = pd.DataFrame(relationships, columns=['head', 'tail', 'Relation'])
df_relation.to_csv(csv_filename_relation, mode='a',index=False, header=False)
print("所有属性已成功提取并保存到CSV文件中。")
if __name__ == '__main__':
main()
csv_json_ner.py
import csv
import json
# 输入CSV文件名
csv_re = 'triples_number/relation.csv'
csv_ner = 'triples_number/ner.csv'
# 输出JSON文件名
json_re = 'triples_number/relation.json'
json_ner = 'triples_number/ner.json'
# 初始化一个空的字典,用于存储最终的JSON数据
json_links = {"links": []}
json_nodes = {"nodes": []}
json_item = {}
# 读取关系CSV文件
with open(csv_re, mode='r', newline='', encoding='utf-8') as csv_file:
csv_reader = csv.reader(csv_file)
for row in csv_reader:
source, target, relation = row
json_links["links"].append({
"relation": relation,
"source": int(source),
"target": int(target)
})
# 读取NER CSV文件
with open(csv_ner, mode='r', newline='', encoding='utf-8') as csv_file:
csv_reader = csv.reader(csv_file)
for row in csv_reader:
number, name, parent_path, path, time, type, depth, title, content, parent_title = row
json_item[number] = {
"name": name,
"parent_path": parent_path,
"path": path,
"time": time,
"type": type,
"content": content.strip(),
}
json_nodes["nodes"].append({
"index": int(number),
"name": name,
"type": type,
"depth": int(depth),
})
# 合并链接和节点数据
json_combined = {**json_links, **json_nodes}
# 将链接和节点数据写入JSON文件
with open(json_re, mode='w', encoding='utf-8') as json_file:
json.dump(json_combined, json_file, ensure_ascii=False, indent=4)
# 将NER数据写入JSON文件
with open(json_ner, mode='w', encoding='utf-8') as json_file:
json.dump(json_item, json_file, ensure_ascii=False, indent=4)
print("JSON文件已生成!")
小结
代码虽然可以完成预期任务,但仍有很多需要改进的地方。先存一期,后面再修改。
目录知识图谱的代码,我会上传到我的资源,上次有东西少传了,该部分的代码就是增加了指向的箭头和一个按钮。















 328
328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









