







数据表示的最佳方法不仅取决于数据的语义,还取决于所使用的模型种类。
线性模型与基于树的模型(决策树、梯度提升树、随机森林)很常用的模型,但他们在处理不同特征表示时具有非常不同的性质。
(1)线性回归和决策树在make_wave数据集中的对比
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
X, y = mglearn.datasets.make_wave(n_samples=120)
line = np.linspace(-3, 3, 1000, endpoint=False).reshape(-1, 1)
reg = DecisionTreeRegressor(min_samples_leaf=3).fit(X, y)
plt.plot(line, reg.predict(line), label="decision tree")
reg = LinearRegression().fit(X, y)
plt.plot(line, reg.predict(line), label="linear regression")
plt.plot(X[:, 0], y, 'o', c='k')
plt.ylabel("Regression output")
plt.xlabel("Input feature")
plt.legend(loc="best")

线性模型对单个特征的建模,决策树可以构建更复杂的数据表示,但依赖于数据表示
(2)分箱
分箱(binning,离散化):将单个特征划分为多个特征,让线性模型在连续的数据上变得更加强大
假设特征输入范围,划分为固定个数箱子。
1、创建箱子
bins = np.linspace(-3,3,11)
bins.shape
2、记录数据点所属箱子
which_bin = np.digitize(X,bins=bins)
print("\nBin memebership for data points:\n"which_bin[0:5])
3、编码
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(sparse=False).fit(which_bin)
X_binned = encoder.transform(which_bin)
print(X_binned[0:5])
4、编码后数据上构建模型进行比较
line_binned = kb.transform(np.digitize(line,bins=bins))
reg = LinearRegression().fit(X_binned, y)
plt.plot(line, reg.predict(line_binned), label='linear regression binned')
reg = DecisionTreeRegressor(min_samples_split=3).fit(X_binned, y)
plt.plot(line, reg.predict(line_binned), label='decision tree binned')
plt.plot(X[:, 0], y, 'o', c='k')
plt.vlines(bins, -3, 3, linewidth=1, alpha=.2)
plt.legend(loc="best")
plt.ylabel("Regression output")
plt.xlabel("Input feature")
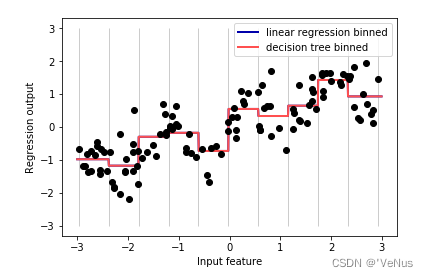
实线虚线重合,说明做出了完全相同的预测。
由于每个箱子内特征值相同,所以预测值都相同。
线性模型更加灵活,而决策树灵活性降低















 76
76











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









