







 本文探讨了多种基于自注意力机制的Transformer模型在乳腺癌组织病理学图像分类中的应用,如ViT、PiT、CvT、CrossFormer、NesT、MaxViT和SepViT。这些模型在BreakHis和IDC数据集上进行训练和微调,展示出在资源效率和分类精度方面的优势。CNN模型如AlexNet、ResNet和VGG-16也在文中提及,尽管ViT有良好性能,但存在归纳偏差问题。
本文探讨了多种基于自注意力机制的Transformer模型在乳腺癌组织病理学图像分类中的应用,如ViT、PiT、CvT、CrossFormer、NesT、MaxViT和SepViT。这些模型在BreakHis和IDC数据集上进行训练和微调,展示出在资源效率和分类精度方面的优势。CNN模型如AlexNet、ResNet和VGG-16也在文中提及,尽管ViT有良好性能,但存在归纳偏差问题。
Vision Transformer作为一种基于自注意力机制的高效图像分类工具被提出。近年来出现了基于Poolingbased Vision Transformer (PiT)、卷积视觉变压器(CvT)、CrossFormer、CrossViT、NesT、MaxViT和分离式视觉变压器(SepViT)等新模型。
它们被用于BreakHis和IDC数据集上的图像分类,用于数字乳腺癌组织病理学。在BreakHis上训练之后,他们在IDC上进行微调,以测试他们的泛化能力。
组织病理学是医学诊断的一个重要分支,涉及组织疾病的研究和发现。组织病理学家在显微镜下观察组织样本的许多特性,如细胞密度、大小、细胞核和组织颜色。在乳腺癌组织病理学中,需要检测的组织样本取自患者的乳房,用于诊断患者是否患有乳腺癌。诊断还可以揭示病人可能患的癌症的阶段和类型。
数字组织病理学:使用计算机视觉的图像分类用于帮助机器学习如何区分健康和病变组织样本
当模型被训练来明确区分代表健康和癌变乳腺组织样本的图像时,这个过程被称为数字乳腺癌组织病理学。
Vision Transformer显示出了在使用更少的计算资源的同时提供更高分类精度的潜力。
CNN模型仍然是处理计算机视觉任务的首选。它们已被广泛用于各种应用,如蒙面识别、行人检测、植物病害分类、道路物体检测等。AlexNet, ResNet和VGG-16架构似乎是最受欢迎的,并且很少显示出低于95%的准确性。
尽管ViT对任何类型的图像数据都具有良好的分类精度,但是其缺乏归纳偏差。
归纳偏差的含义如下:
- 指人们根据有限的样本和经验得出普遍性的结论时产生的偏差 。这种偏差在一定程度上是有道理的,但如果样本和经验有限或不典型,就会导致结论出现偏差。
- 指机器学习算法在学习过程中出现的不准确和不稳定的情况 。由于机器学习算法通常基于训练数据进行学习,并且在训练数据的分布上存在一定的偏差,算法可能无法在学习过程中完全归纳到这些偏差,导致学习结果的偏差和不准确性。
数据集
本研究选择BreakHis和IDC两个乳腺癌组织病理学数据集。来自这些数据集的图像在用于训练和测试所选模型之前进行数据增强。
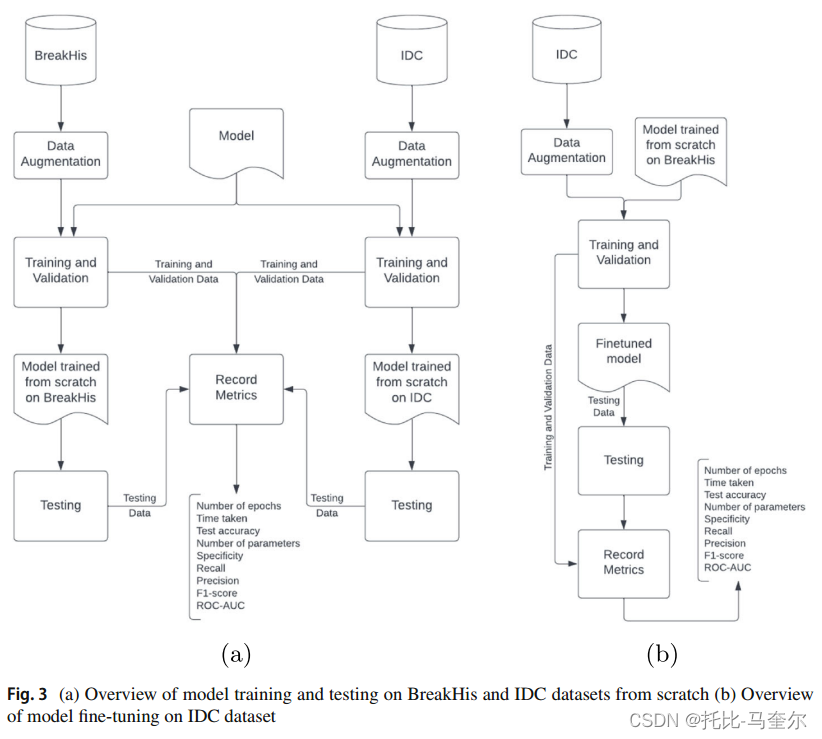
- 本研究选择的所有模型都在BreakHis和IDC数据集上进行了训练和测试。(左图所示)
- 一旦记录了初始性能,在BreakHis数据集上从头开始训练的所有模型(现在被认为是预训练模型)也会在IDC数据集上进行微调。(右图所示)这样做不会对执行环境作出任何更改,但是会再次记录前面提到的指标。选择IDC数据集进行微调,因为其图像仅代表导管癌的存在或不存在
BreakHis数据集
BreakHis数据集由7909张乳腺肿瘤组织图像组成,以四种不同的放大倍数:40倍、100倍、200倍和400倍。其中良性样本2480个,恶性样本5429个。每张图像的大小为700 x 460像素,3通道(RGB),并提供PNG格式。
IDC数据集
IDC数据集采集了162张40x扫描的浸润性导管癌(乳腺恶性肿瘤的一种)整张幻灯片图像,从中提取50x50大小的斑块277,524块。由此产生的补丁集被标记为“IDC”(78,786个样本)或“非IDC”(198,738个样本)。所有图像都有3个通道(RGB),并以PNG格式提供。本研究还使用该数据集进行二值分类。为了大致匹配BreakHis数据集的大小,我们的实验中只使用了7906个补丁。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1766
1766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









