







降维
对iris数据集分别进行PCA降维和LDA降维后,再使用logisticRegression、SGDClassifier、Perceptron进行分类
# PCA降维
pca = PCA(n_components=2)
pca.fit(X)
X_PCA = pca.transform(X)
# LDA降维
lda = LinearDiscriminantAnalysis(n_components=2)
lda.fit(X, y)
X_LDA = lda.transform(X)
分类
# logisticRegression分类
lr_PCA = LogisticRegression(max_iter=5000, random_state=1)
lr_PCA.fit(X_train_PCA_scaler, y_train_PCA)
y_pred_PCA_lr = lr_PCA.predict(X_test_PCA_scaler)
# LR
lr_LDA = LogisticRegression(max_iter=5000, random_state=1)
lr_LDA.fit(X_train_LDA_scaler, y_train_LDA)
y_pred_LDA_lr = lr_LDA.predict(X_test_LDA_scaler)
# Perceptron
perceptron_PCA = Perceptron(max_iter=500, random_state=1)
perceptron_PCA.fit(X_train_PCA_scaler, y_train_PCA)
y_pred_perceptron_PCA = perceptron_PCA.predict(X_test_PCA_scaler)
perceptron_LDA = Perceptron(max_iter=500, random_state=1)
perceptron_LDA.fit(X_train_LDA_scaler, y_train_LDA)
y_pred_perceptron_LDA = perceptron_LDA.predict(X_test_LDA_scaler)
# SGDClassifier
SGD_LDA = SGDClassifier(max_iter=5000, random_state=1)
SGD_LDA.fit(X_train_LDA_scaler, y_train_LDA)
y_pred_SGD_LDA = SGD_LDA.predict(X_test_LDA_scaler)
SGD_PCA = SGDClassifier(max_iter=5000, random_state=1)
SGD_PCA.fit(X_train_PCA_scaler, y_train_PCA)
y_pred_SGD_PCA = SGD_PCA.predict(X_test_PCA_scaler)
结果展示
Perceptron分类器的平均性能更好,由实验结果可以看出Perceptron分类器的准确率最高,但是SGDClassifier分类器不太稳定有时候效果很好,但是有的时候准确率比其他两个都要低,所以整体看Perceptron分类器的性能更好。
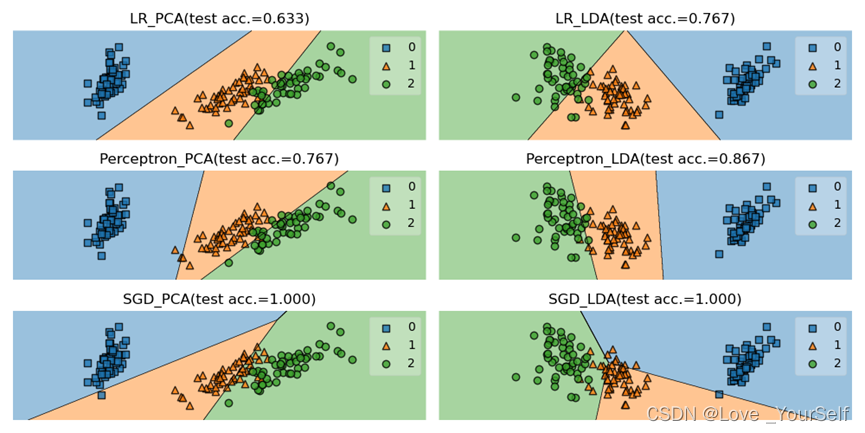
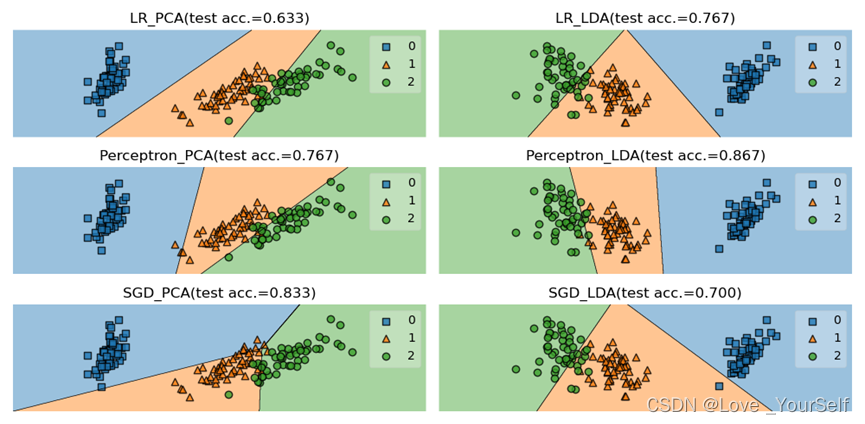
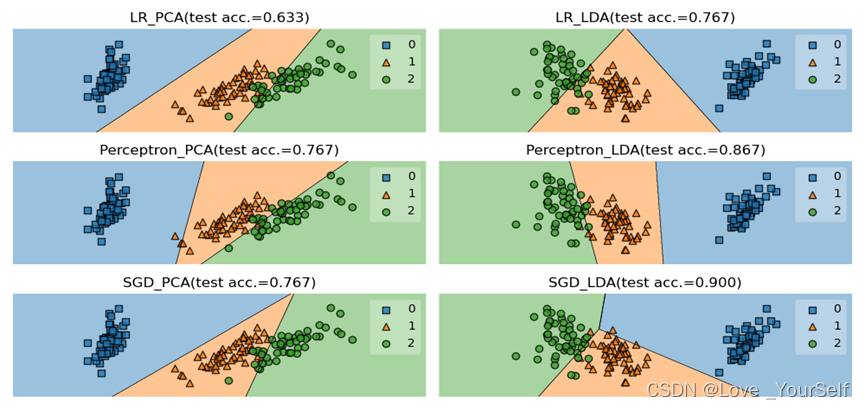
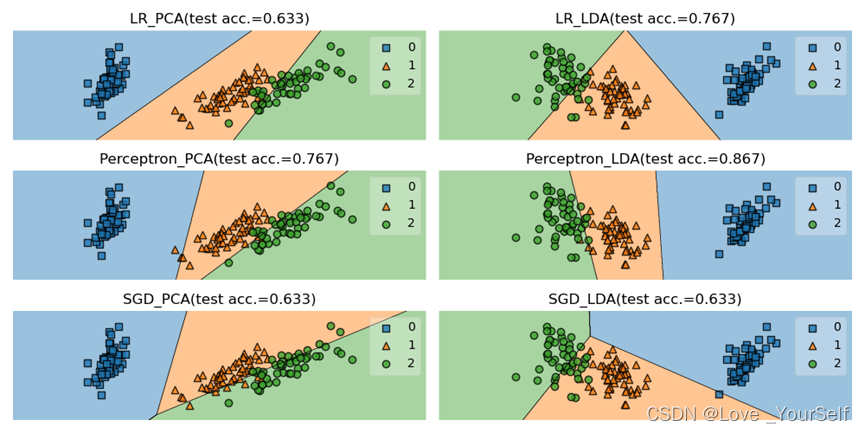
当在划分降维后的数据集的train_test_split函数中的shuffle参数改为True,让数据集乱序排列之后,然后在每个分类器定义的时候加入max_iter参数,并设置为5000时,可以明显的提高每个分类器的性能。
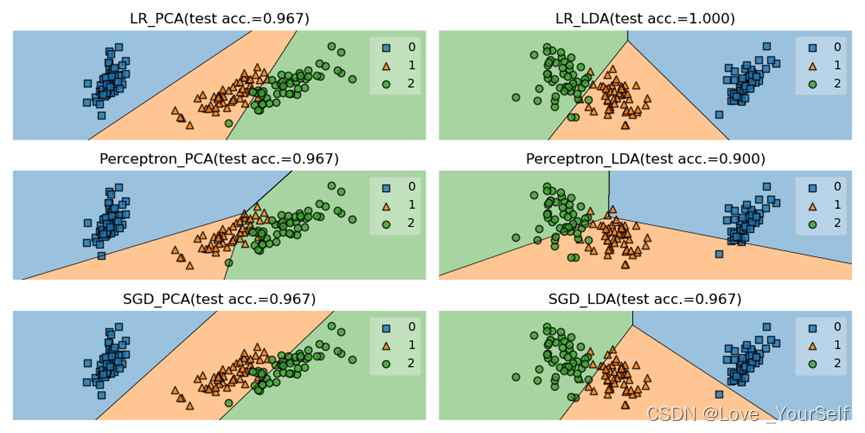
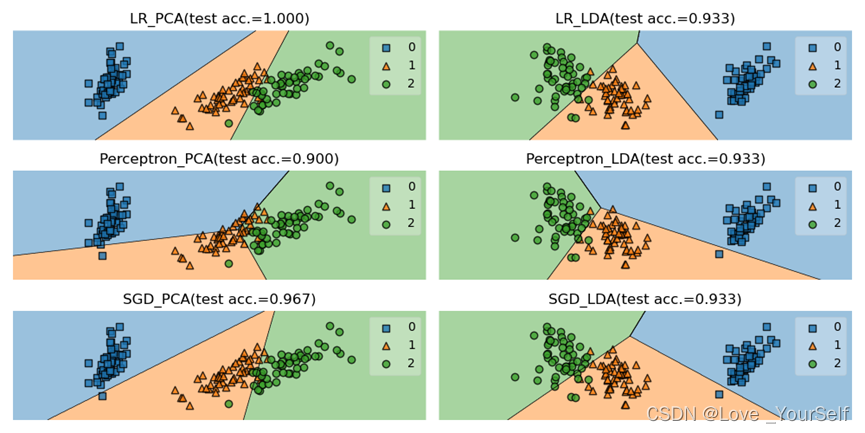
这个参数代表了迭代的次数,通过调整这个值每个分类器的准确率提高了很多。















 1010
1010











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









