






帮可爱的对象处理所需数据时的代码——第十弹(实现功能:该程序读取一个 CSV 文件,删除空值,计算每个值的出现次数,并将结果按出现次数排序后保存到新的 CSV 文件中)
一.程序实现功能
该程序实现了以下功能:
1.从指定路径读取一个大型 CSV 文件。
2.使用 Dask 将 DataFrame 从宽格式转换为长格式。
3.删除空值并计算每个值的出现次数。
4.将计数结果按照出现次数排序,并将结果保存到新的 CSV 文件中
二.所需库
程序使用了以下 Python 库:
1.dask.dataframe: 用于处理大型数据集,支持并行计算。
2.dask.diagnostics.ProgressBar: 提供进度条功能,监控计算进度。
三.程序优势
该程序具有以下优势:
1.处理大型数据集: 使用 Dask 可以处理大于内存的数据集,避免了内存溢出问题。
2.并行计算: Dask 能够利用多核处理器进行并行计算,加快数据处理速度。
3.数据清洗: 能够有效地清洗数据,处理空值并转换数据格式。
4.灵活性: 可以通过修改输入和输出路径轻松适应不同的数据集和输出需求。
四.程序运行注意地方
在运行程序时需要注意以下几点:
1.文件路径: 确保输入文件路径 input_file_path 和输出文件路径 output_file_path 是正确的,并且具有适当的访问权限。
2.数据类型和缺失值处理: 根据实际情况调整数据类型和缺失值处理方式,确保数据清洗过程正确。
3.计算资源: 考虑到程序可能处理大量数据,确保计算资源充足,以避免过长的运行时间。
五.程序运行实例
原始数据(包含多列多行的数据):

数据清洗和数据分析(可以将重复的数据删除,并统计出现次数):
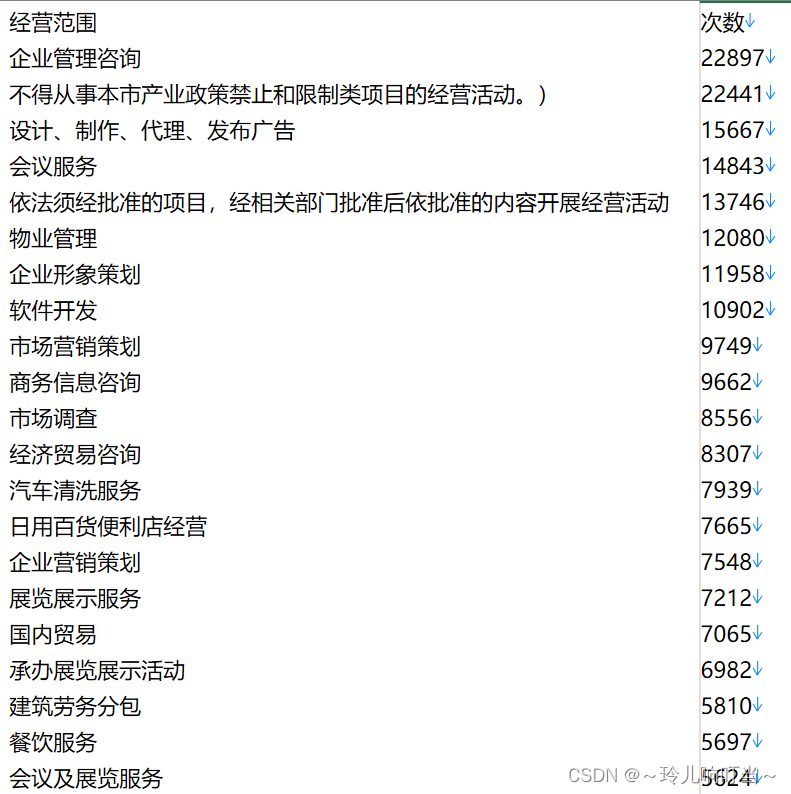
六.完整程序
import dask.dataframe as dd
from dask.diagnostics import ProgressBar
# 定义 CSV 文件路径
input_file_path = r"E:\test\ling\原数据\11.csv"
output_file_path = r"E:\test\ling\已处理\11去重.csv"
# 读取 CSV 文件到 Dask DataFrame
ddf = dd.read_csv(input_file_path, dtype=str, assume_missing=True, on_bad_lines='skip', quoting=3, quotechar='"')
# 初始化进度条
pbar = ProgressBar()
pbar.register()
# 使用 melt 将 DataFrame 从宽格式转换为长格式
long_format = ddf.melt(value_name="value")
# 删除任何 NaN 值,这对于计数是必要的
long_format = long_format.dropna(subset=["value"])
# 计算每个值的出现次数
value_counts = long_format['value'].value_counts().compute()
# 将 Series 转换为 DataFrame
value_counts_df = value_counts.reset_index()
value_counts_df.columns = ['经营范围', '次数']
# 按次数排序
value_counts_df = value_counts_df.sort_values(by='次数', ascending=False)
# 保存结果到 CSV 文件
value_counts_df.to_csv(output_file_path, index=False)
# 打印完成信息
print("Complete value counts across all columns!")
# 注销进度条
pbar.unregister()
如有不足,欢迎留言指正交流哈!!!
















 452
452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











