







文章目录
前言
休闲大半个月,终于又要开始认真工作了,果然游戏害人(淦),废话不多说,现在开始工作,我在转模型的时候遇到总总问题,先是转化不成功(前面有文章说过这个问题),后面转成功了但是我前几天想用那个模型的时候发现,转化的模型有大问题,首先是数值上和pth文件不一致,其次甚至没有BatchNormalization模块,具体看下图(netron查看onnx模型)


这种问题可能是pytorch版本问题,建议用比较高的版本,下面给出转模型的全过程以及解决上述问题的方法。
一、pth转onnx模型
首先通过一个简单的例子来介绍转模型的过程。下面是我搭建的一个简单的用作分类的卷积网络(文件名 model.py):
import torch.nn as nn
import torch.nn.functional as F
# 定义卷积神经网络结构
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 卷积层 (32x32x3的图像)
self.conv1 = nn.Conv2d(3, 16, 3,stride=1, padding=1)
# 卷积层(16x16x16)
self.conv2 = nn.Conv2d(16, 32, 3, stride=2,padding=1)
# 卷积层(8x8x32)
self.conv3 = nn.Conv2d(32, 64, 3,stride=1, padding=1)
# 最大池化层
self.pool = nn.MaxPool2d(2, 2)
# linear layer (64 * 4 * 4 -> 500)
self.fc1 = nn.Linear(64 * 4 * 4, 500)
# linear layer (500 -> 10)
self.fc2 = nn.Linear(500, 10)
# dropout层 (p=0.3)
self.dropout = nn.Dropout(0.3)
def forward(self, x):
# add sequence of convolutional and max pooling layers
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
# flatten image input
#print(x.shape)
x = x.view(-1, 64 * 4 * 4)
# add dropout layer
x = self.dropout(x)
# add 1st hidden layer, with relu activation function
x = F.relu(self.fc1(x))
# add dropout layer
x = self.dropout(x)
# add 2nd hidden layer, with relu activation function
x = self.fc2(x)
return x
还是比较简单的,想必大家都能轻松看懂,当然懂不懂没关系,只是想让大家知道,转模型的过程中必须要import模型文件。
其次在我们保存模型的过程中,一般而言是保存state_dict格式(非state_dict格式在应用过程中会出现各种问题,pytorch官网也推荐使用state_dict格式),具体保存的函数可以见如下(仅供参考):
torch.save(model.state_dict(), 'model_figure_classfiy.pth')
需要注意的是保存的state_dict格式的pth文件中仅仅含有的是模型的参数信息,而不具备模型的结构信息,因此其不具备直接使用的功能,在我们使用的过程中(load后)需要将参数赋予模型(简单来说就是创建一个模型,将参数赋予这个模型,然后将其应用于诸如测试、转模型的工作),以上述搭建的简单的分类网络为例,下面介绍:
import torch
from model import Net
model_test = Net()
model_statedict = torch.load("model_figure_classfiy_e500.pth",map_location=lambda storage,loc:storage) #导入Gpu训练模型,导入为cpu格式
model_test.load_state_dict(model_statedict) #将参数放入model_test中
model_test.eval() # 测试,看是否报错
#下面开始转模型,cpu格式下
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
dummy_input = torch.randn(1, 3, 64, 64,device=device)
input_names = ["input"]
output_names = ["output"]
torch.onnx.export(model_test, dummy_input, "model_.onnx", opset_version=9, verbose=False, output_names=["hm"])
上述代码可以成功将模型转化成功,但是可能会报一个warning,后面我用opencv的dnn模块调用此onnx模型,发现可以成功。
import cv2 as cv
import numpy as np
def img_process(image):
mean = np.array([0.5,0.5,0.5],dtype=np.float32).reshape(1,1,3)
std = np.array([0.5,0.5,0.5],dtype=np.float32).reshape(1,1,3)
new_img = ((image/255. -mean)/std).astype(np.float32)
return new_img
img = cv.imread("figure_1.jpg")
img_t = cv.resize(img,(64,64)) #将图片改为模型适用的尺寸
img_t = img_process(img_t)
#img_t = np.transpose(img_t,[2,0,1])
#img_t = img_t[np.newaxis,:] #扩展一个新维度
layerNames = ["hm"] # 这里的输出的名称应该于前面的转模型时候定义的一致
blob=cv.dnn.blobFromImage(img_t,scalefactor=1.0,swapRB=True,crop=False) # 将image转化为 1x3x64x64 格式输入模型中
net = cv.dnn.readNetFromONNX("model_.onnx")
net.setInput(blob)
outs = net.forward(layerNames)
print(outs)
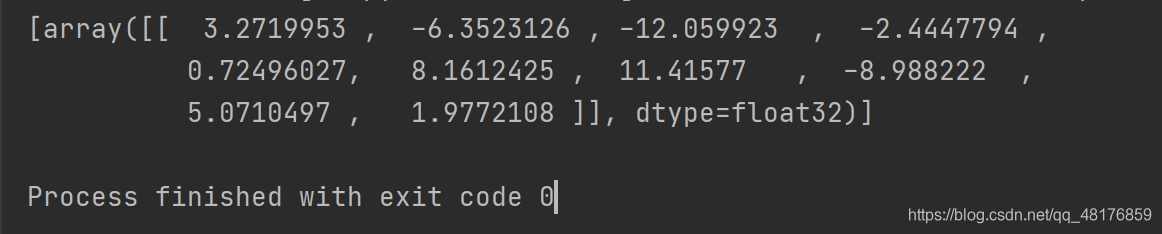
结果如下:
并且我输入的图片如下:

对应的输出中下标为6的值最大为11.41577 ,分类正确。
后续我会将整个小项目的资源打包汇总一下,希望能对你有用。
其实看到这,你应该对pth模型转onnx模型有一个比较清晰的了解了,其实归根结底就是一个torch.onnx.export()函数的应用,这是此函数的一些参数介绍,希望能够帮助你更加清晰的了解:
torch.onnx.export(model, args, f, export_params=True, verbose=False, training=False,
input_names=None, output_names=None, aten=False, export_raw_ir=False,
operator_export_type=None, opset_version=None, _retain_param_name=True,
do_constant_folding=False, example_outputs=None, strip_doc_string=True,
dynamic_axes=None, keep_initializers_as_inputs=None)
参数介绍:
model (torch.nn.Module) – 要导出的模型.
args (tuple of arguments) – 模型的输入, 任何非Tensor参数都将硬编码到导出的模型中;
任何Tensor参数都将成为导出的模型的输入,并按照他们在args中出现的顺序输入。因为export运行模型,
所以我们需要提供一个输入张量x。只要是正确的类型和大小,其中的值就可以是随机的。请注意,除非指定为动态轴,
否则输入尺寸将在导出的ONNX图形中固定为所有输入尺寸。在此示例中,我们使用输入batch_size 1导出模型,
但随后dynamic_axes 在torch.onnx.export()。因此,导出的模型将接受大小为[batch_size,3、100、100]的输入,
其中batch_size可以是可变的。
f - 保存后的onnx文件名
export_params (bool, default True) – 如果指定为True或默认, 参数也会被导出. 如果你要导出一个没训练过的就设为 False
verbose (bool, default False) - 如果指定,我们将打印出一个导出轨迹的调试描述
training (bool, default False) - 在训练模式下导出模型。目前,ONNX导出的模型只是为了做推断,所以你通常不需要将其设置为True
input_names (list of strings, default empty list) – 按顺序分配名称到图中的输入节点
output_names (list of strings, default empty list) –按顺序分配名称到图中的输出节点
以上就是整个模型的转化过程了,下面是我在转一些比复杂的模型的时候遇到的一些问题。如果遇到相同问题的可以了解一下。















 1357
1357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









