







redis原理分析
一、 数据结构
1.总览
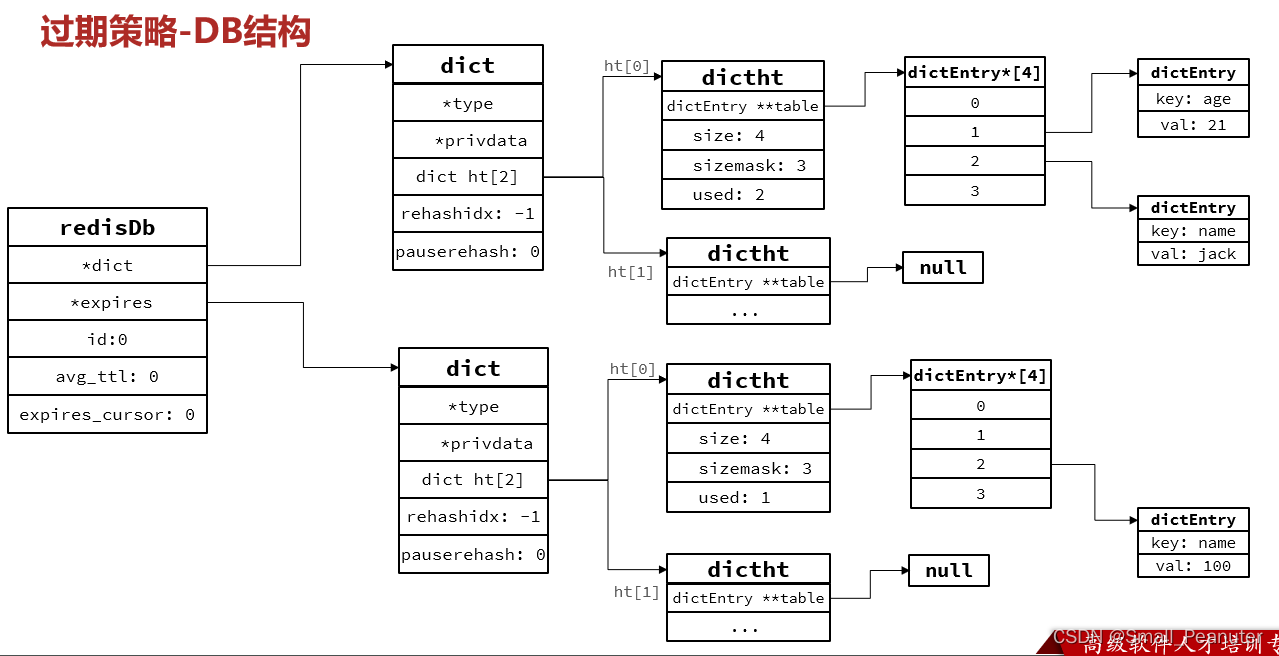
redis是一个典型的key-value结构的数据库,每个数据库的所有的key和value以及key和ttl都通过redisDb联系起来。
typedef struct redisDb {
dict *dict; /* 存放所有key及value的地方,也被称为keyspace*/
dict *expires; /* 存放每一个key及其对应的TTL存活时间,只包含设置了TTL的key*/
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID,0~15 */
long long avg_ttl; /* 记录平均TTL时长 */
unsigned long expires_cursor; /* expire检查时在dict中抽样的索引位置. */
list *defrag_later; /* 等待碎片整理的key列表. */
} redisDb;
redisDb的两个dict指针分别指向两个记录key-value对和key-ttl对的Dict,
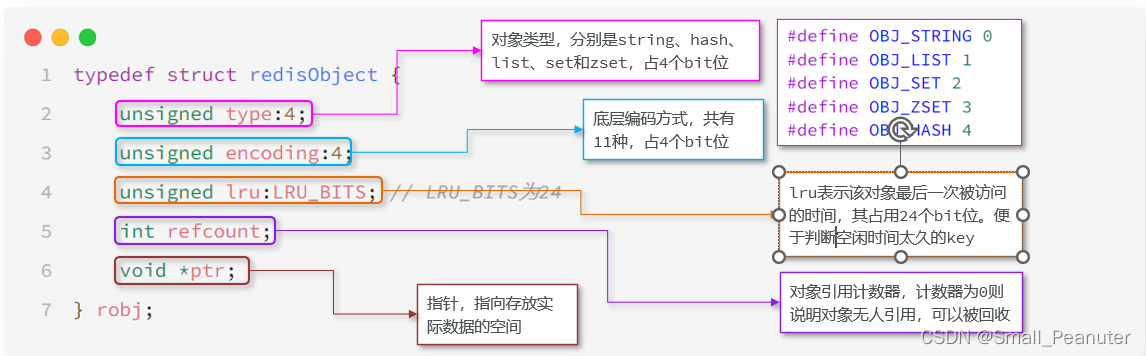
Redis中的任意数据类型的key和value都会被封装为一个RedisObject,也叫做Redis对象,源码如下:
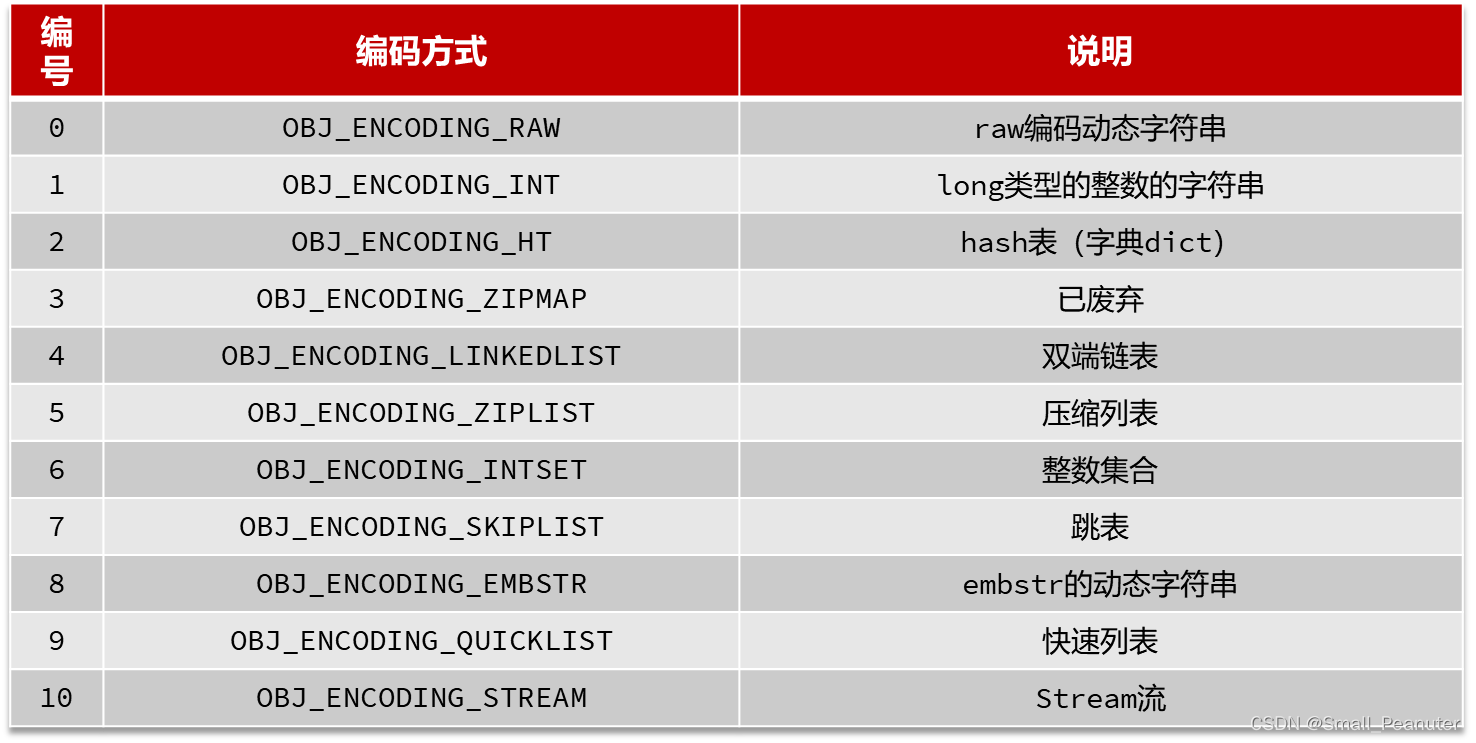
encoding的11种编码:
 unsigned lru :LRU_BITS; 不同淘汰策略LRU_BITS表示不同含义
unsigned lru :LRU_BITS; 不同淘汰策略LRU_BITS表示不同含义
- LRU模式: 以秒为单位记录最近一次访问时间,长度24bit
- LFU模式:高16位以分钟为单位记录最近一次访问时间,低8位记录逻辑访问次数
2.string的内部结构(SDS)
1.string
-
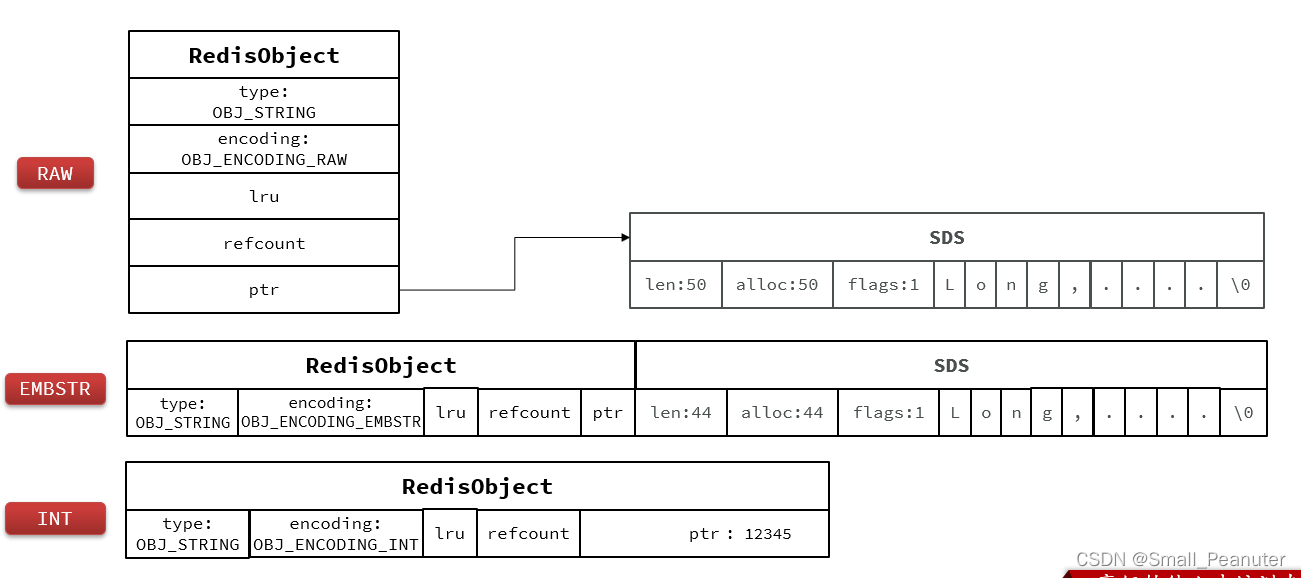
其基本编码方式是RAW,基于简单动态字符串(SDS)实现,存储上限为512mb。
-
如果存储的SDS长度小于44字节,则会采用EMBSTR编码,此时object head与SDS是一段连续空间。申请内存时只需要调用一次内存分配函数,效率更高。
-
如果存储的字符串是整数值,并且大小在LONG_MAX范围内,则会采用INT编码:直接将数据保存在RedisObject的ptr指针位置(刚好8字节),不再需要SDS了。
2.SDS
- 简单动态字符串(Simple Dynamic String),记录了申请和使用的不包含结束标志(\0字符)的字符串长度。因而可以直接字符串长度,同时也是二进制安全的。

- 如果SDS结构体中的len和alloc都是unit8限定了buf的最大长度,因而源码中设计了多个SDS的结构体,不同的结构体中的len和alloc类型不同,同时用flags标记SDS类型。因而记录SDS的buf可以保存更多的字符。

- SDS扩容策略:我们申请SDS后,又加入新的字符串后,由于初始化的时候申请的空间是刚刚好够原来的字符串长度的,所以加入的字符串必定会引起SDS扩容,扩容后的SDS空间会额外多申请一部分空间,以防之后会有其他的字符串再加入SDS中。
如果新字符串小于1M,则新空间为扩展后字符串长度的两倍+1;
如果新字符串大于1M,则新空间为扩展后字符串长度+1M+1。称为内存预分配。
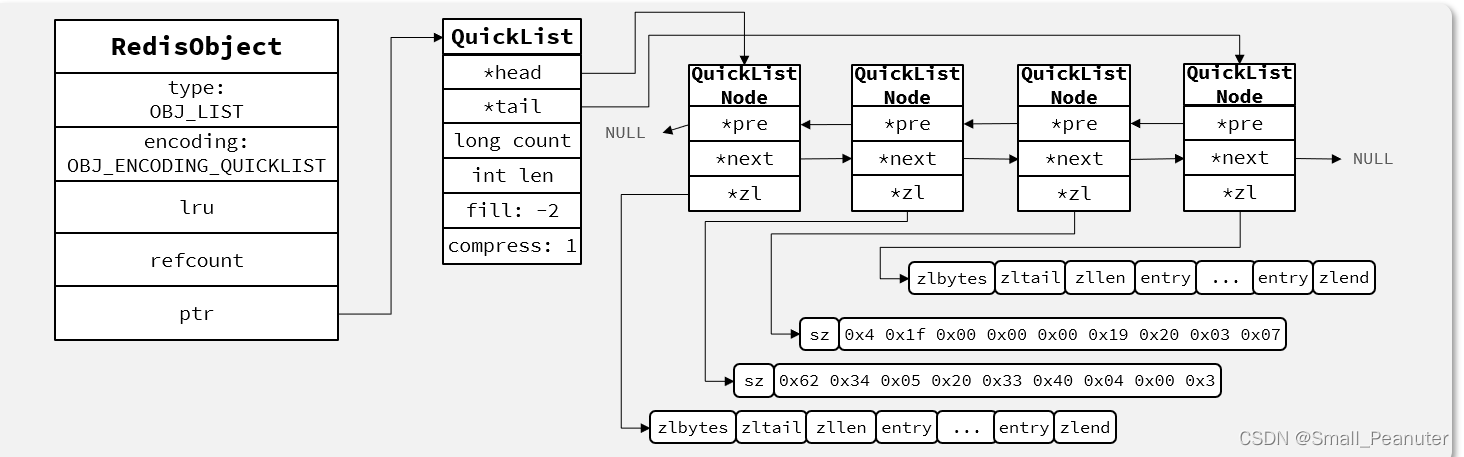
3.List内部结构(ziplist和QuickList)
1.List
list要满足首位操作链表元素,因而QuickList是可以满足其要求的。
2.ziplist的内部结构(intset和dict)
-
ziplist的结构:传统的list需要指针占64位的地址,因而浪费很多的空间给了指针,所以可以采用ziplist的结构进行优化。
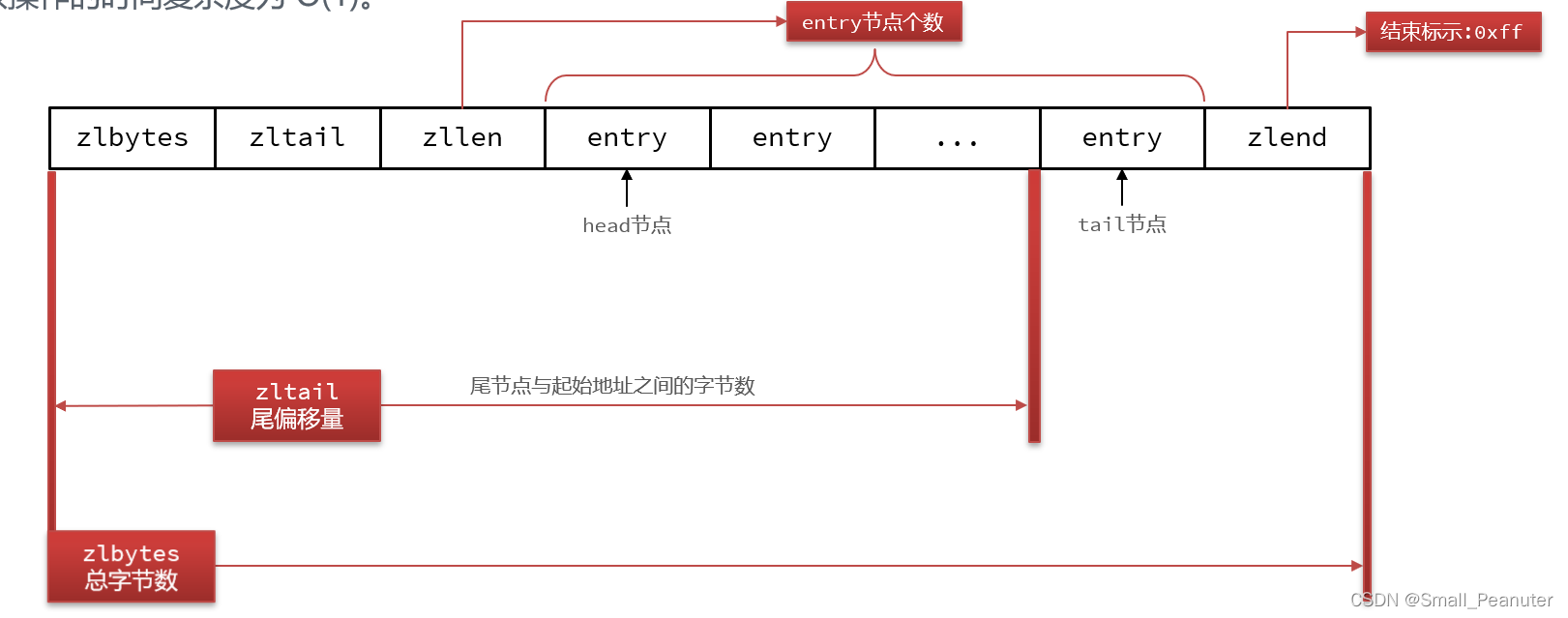
ziplist关键字含义:
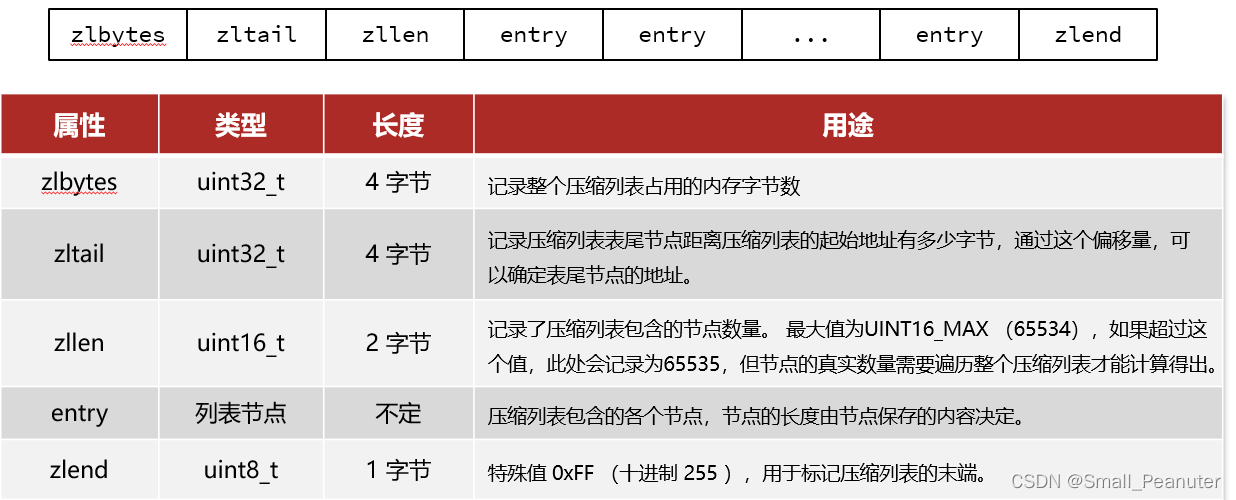
-
ziplist中的entry结构

由于每一个entry都有encoding,所以每个entry都可以字符串和数字类型,同时
previous_entry_length记录了上一个entry的长度,因而每个entry的长度亦可以是不同的。
3.quicklist
ZipList虽然节省内存,但申请内存必须是连续空间,如果内存占用较多,申请内存效率很低 ,QuickList,它是一个双端链表,只不过链表中的每个节点都是一个ZipList。
为了避免QuickList中的每个ZipList中entry过多,Redis提供了一个配置项:list-max-ziplist-size来限制,
list-max-ziplist-size的值:
- 如果值为正,则代表ZipList的允许的entry个数的最大值
- 如果值为负,则代表ZipList的最大内存大小
typedef struct quicklist {
// 头节点指针
quicklistNode *head;
// 尾节点指针
quicklistNode *tail;
// 所有ziplist的entry的数量
unsigned long count;
// ziplists总数量
unsigned long len;
// ziplist的entry上限,默认值 -2
int fill : QL_FILL_BITS; // 首尾不压缩的节点数量
unsigned int compress : QL_COMP_BITS;
// 内存重分配时的书签数量及数组,一般用不到
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
typedef struct quicklistNode {
// 前一个节点指针
struct quicklistNode *prev;
// 下一个节点指针
struct quicklistNode *next;
// 当前节点的ZipList指针
unsigned char *zl;
// 当前节点的ZipList的字节大小
unsigned int sz;
// 当前节点的ZipList的entry个数
unsigned int count : 16;
// 编码方式:1,ZipList; 2,lzf压缩模式
unsigned int encoding : 2;
// 数据容器类型(预留):1,其它;2,ZipList
unsigned int container : 2;
// 是否被解压缩。1:则说明被解压了,将来要重新压缩
unsigned int recompress : 1;
unsigned int attempted_compress : 1; //测试用
unsigned int extra : 10; /*预留字段*/
} quicklistNode;
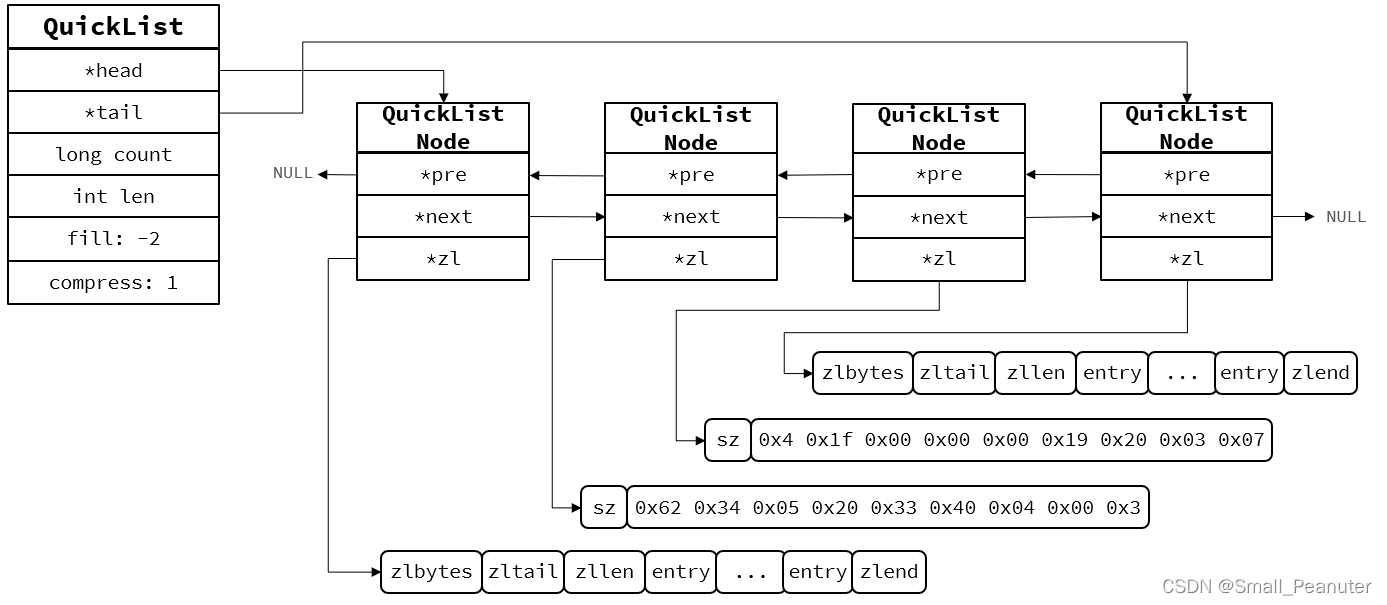
4.set内部结构(intset和dict)
1.set
Set是Redis中的集合,不一定确保元素有序,可以满足元素唯一、查询效率要求极高。
- 为了查询效率和唯一性,set采用intset和HT编码(Dict)。Dict中的key用来存储元素,value统一为null。我们的set数据都是整数时,则采用intset编码,否则使用dict编码。
当存储的所有数据都是整数,并且元素数量不超过set-max-intset-entries时,Set会采用IntSet编码,以节省内存,下图执行命令SADD s1 5 10 20,

之后再执行命令SADD s1 m1后,redisobject的encoding变成IBJ_ENCODING_HT,此时用dict去存储数据。
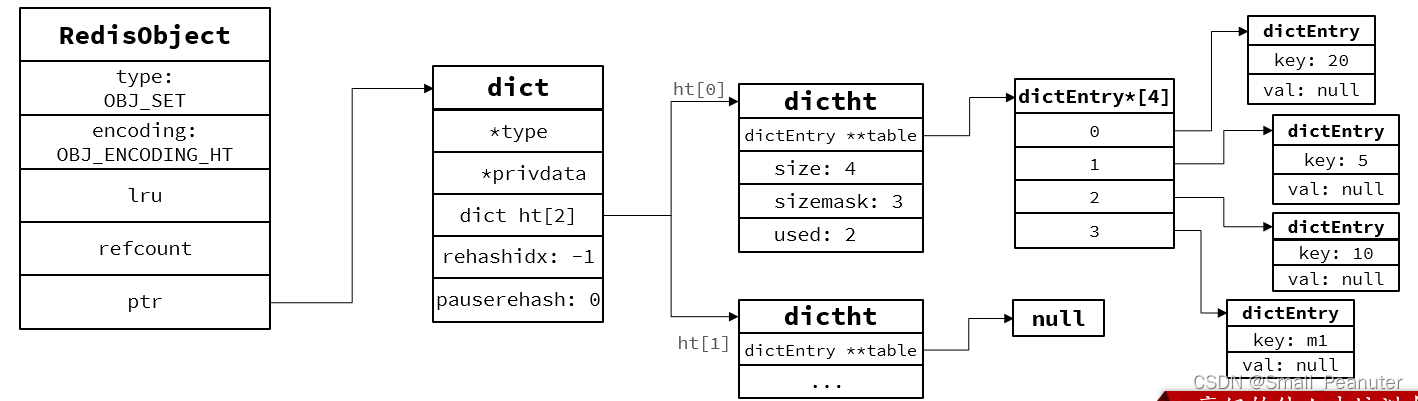
2.intset
intset的encoding决定contents缓存中的数据类型,redis在向系统申请intset的堆区内存前,会对contents[]进行类型强转,以实现intset的存储不同尺寸的整数类型,存放数据的最大值可存储2^31-1

但是length的类型是固定的,只能占4个字节,所以contents中只能存放2^32-1个数字。
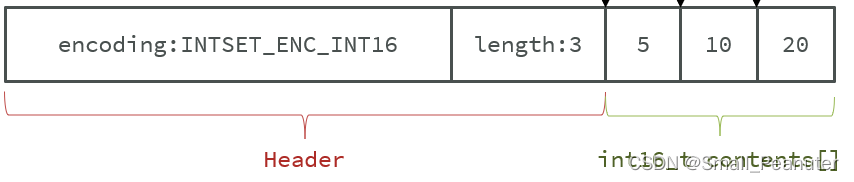
3.DICT
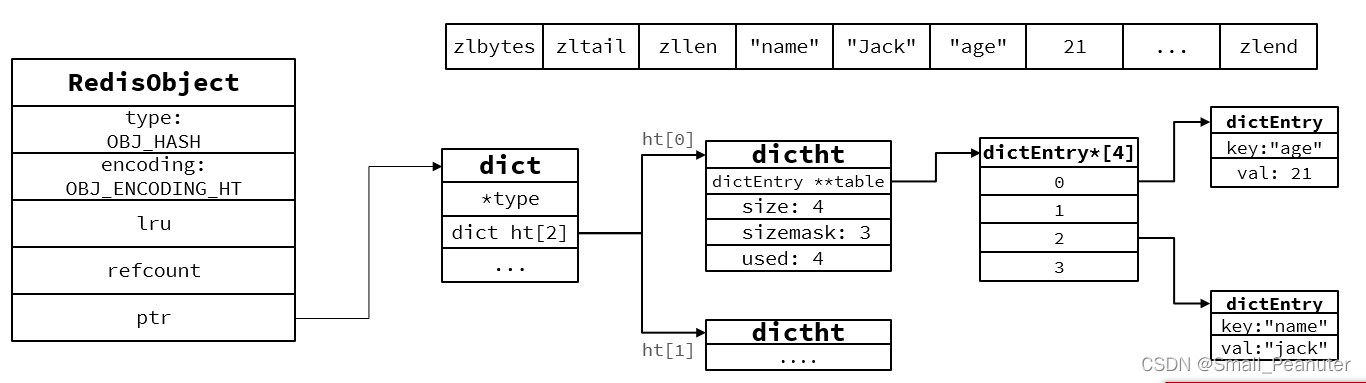
1.Dict的结构
Dict由三部分组成,分别是:哈希表(DictHashTable)、哈希节点(DictEntry)、字典(Dict)
typedef struct dictht {
// entry数组
// 数组中保存的是指向entry的指针
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小的掩码,总等于size - 1
unsigned long sizemask;
// entry个数
unsigned long used;
} dictht;
typedef struct dictEntry {
void *key; // 键
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v; // 值
// 下一个Entry的指针
struct dictEntry *next;
} dictEntry;
typedef struct dict {
dictType *type; // dict类型,内置不同的hash函数
void *privdata; // 私有数据,在做特殊hash运算时用
dictht ht[2]; // 一个Dict包含两个哈希表,其中一个是当前数据,另一个一般是空,rehash时使用
long rehashidx; // rehash的进度,-1表示未进行
int16_t pauserehash; // rehash是否暂停,1则暂停,0则继续
} dict;
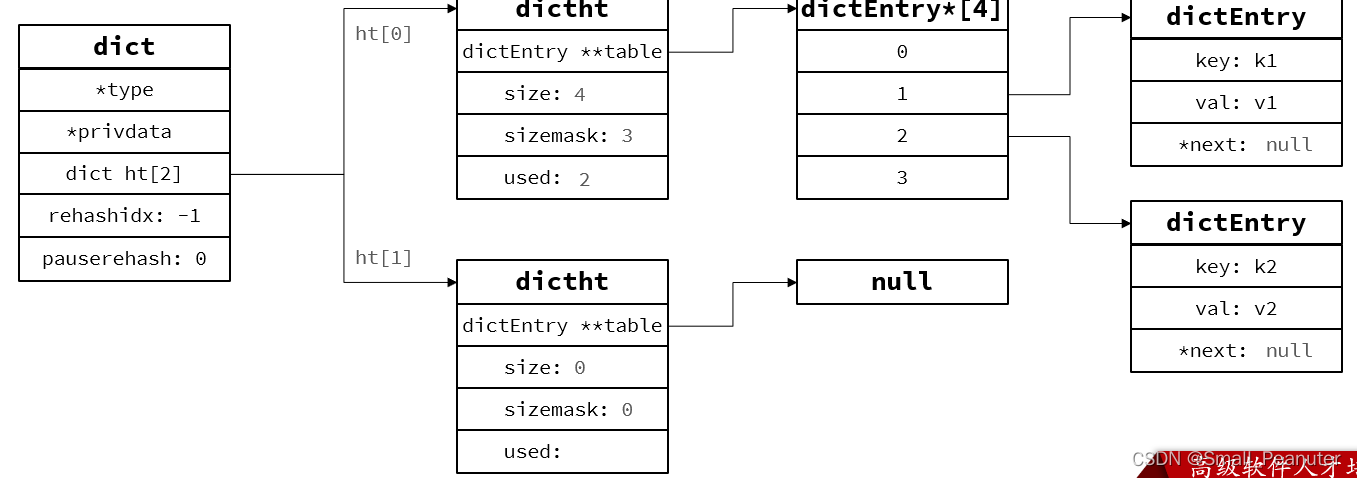
dict的key是void指针,value是union(也可作为void指针),因而key和value都可以是指向任意类型的,redisDb的dict*dict中的dictEntry中的key和value都是redisobject实例化对象。
2.dict的扩容和收缩
Dict在每次新增键值对时都会检查负载因子(LoadFactor = used/size) ,满足以下两种情况时会触发哈希表扩容:
- 哈希表的 LoadFactor >= 1,并且服务器没有执行 BGSAVE 或者 BGREWRITEAOF 等后台进程;
- 哈希表的 LoadFactor > 5 ;
- 但当LoadFactor < 0.1 时,会做哈希表收缩。
- 如果是扩容,则新size为第一个大于等于dict.ht[0].used + 1的2^𝑛
- 如果是收缩,则新size为第一个大于等于dict.ht[0].used的2^𝑛 (不得小于4)
当新的dictentry要加入dictentry时,检查是否时需要扩容或收缩,如果需要rehash则将rehashidx置0。

ht[1]申请dictentry*[8] 空间,并将dictentry一个个的连接到dictht*[1]中。,同时改变dictht的内部参数的值。
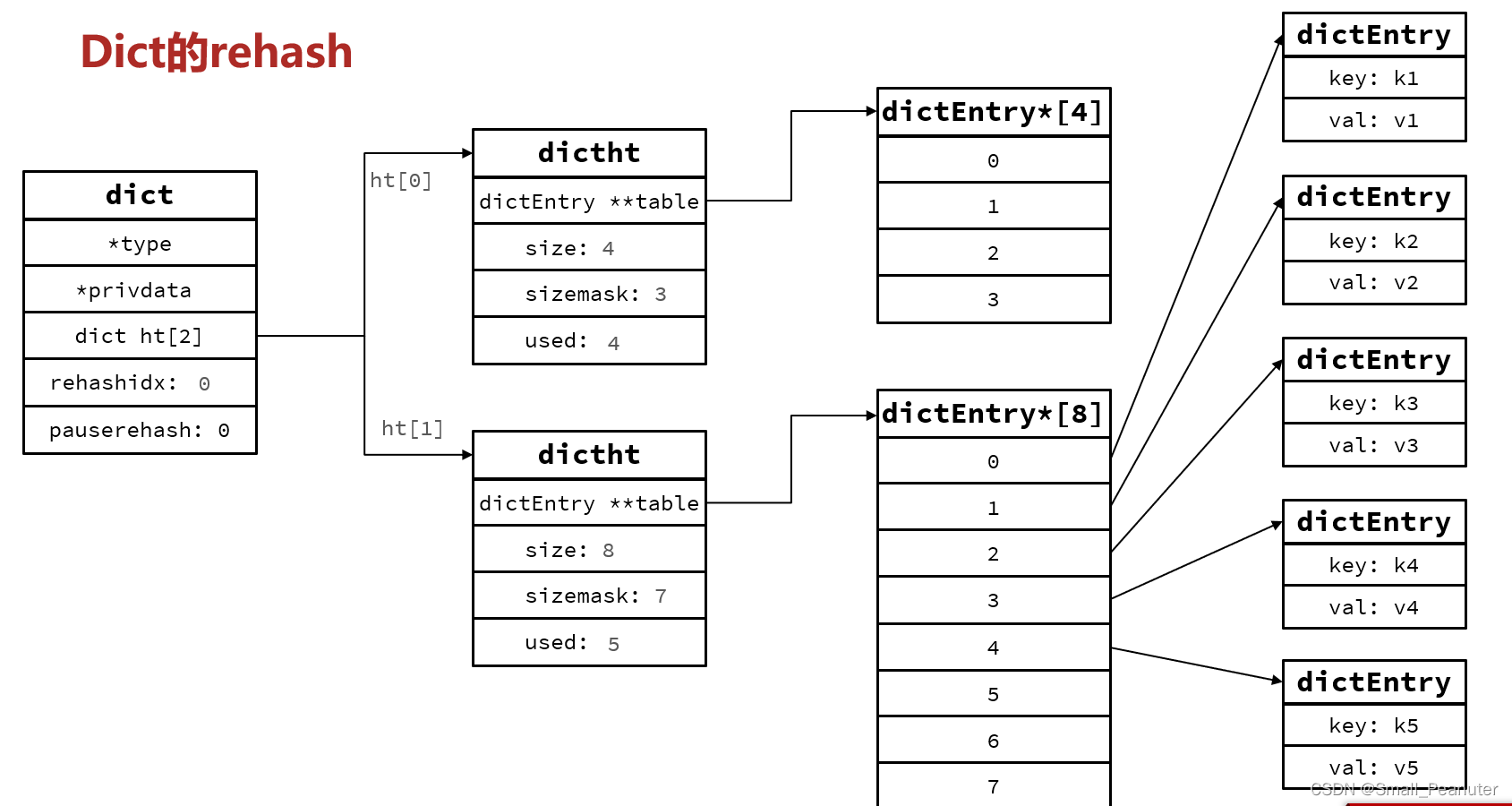
将ht[0]原来的指向的空间释放,同时将ht[1]的对应参数赋值给ht[0],将ht[1]还原到没rehash的状态。
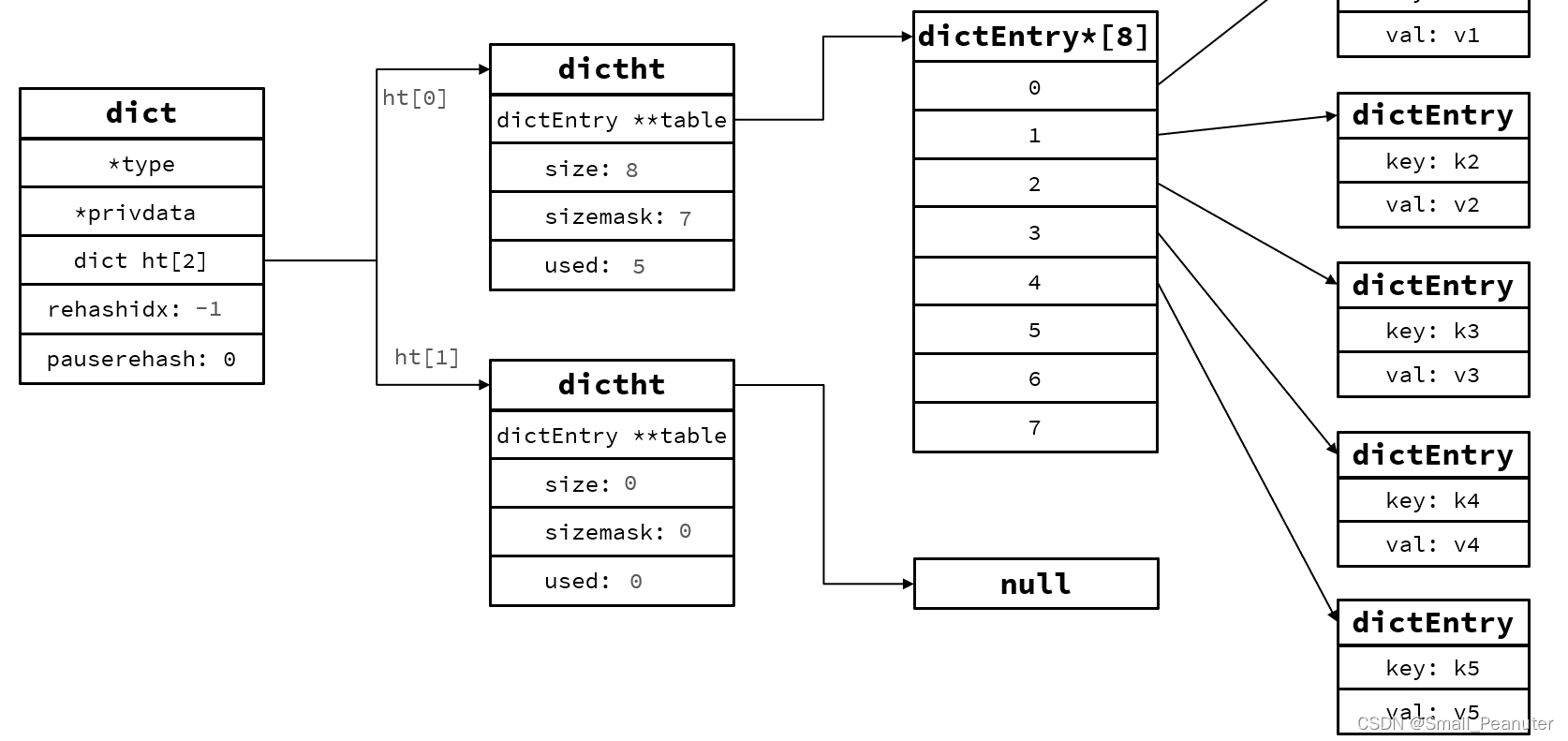
渐进式rehash:rehashidx从0开始递增,并完成ht[0][table[rehashidx]]到ht[1][table[rehashidx]]的转移,并再rehashidx递增到最大值时将ht[1]的参数转移到ht[0].
Dict的rehash并不是一次性完成的。试想一下,如果Dict中包含数百万的entry,要在一次rehash完成,极有可能导致主线程阻塞。因此Dict的rehash是分多次、渐进式的完成,因此称为渐进式rehash。
- 计算新hash表的size,值取决于当前要做的是扩容还是收缩:
- 如果是扩容,则新size为第一个大于等于dict.ht[0].used + 1的2^𝑛
- 如果是收缩,则新size为第一个大于等于dict.ht[0].used的2^𝑛 (不得小于4)
- 按照新的size申请内存空间,创建dictht,并赋值给dict.ht[1]
- 设置dict.rehashidx = 0,标示开始rehash
- 每次执行新增、查询、修改、删除操作时,都检查一下dict.rehashidx是否大于-1,如果是则将dict.ht[0].table[rehashidx]的entry 链表rehash到dict.ht[1],并且将rehashidx++。直至dict.ht[0]的所有数据都rehash到dict.ht[1]
- 将dict.ht[1]赋值给dict.ht[0],给dict.ht[1]初始化为空哈希表,释放原来的dict.ht[0]的内存
- 将rehashidx赋值为-1,代表rehash结束
- 在rehash过程中,新增操作,则直接写入ht[1],查询、修改和删除则会在dict.ht[0]和dict.ht[1]依次查找并执行。这样可以确保ht[0]的数据只减不增,随着rehash最终为空
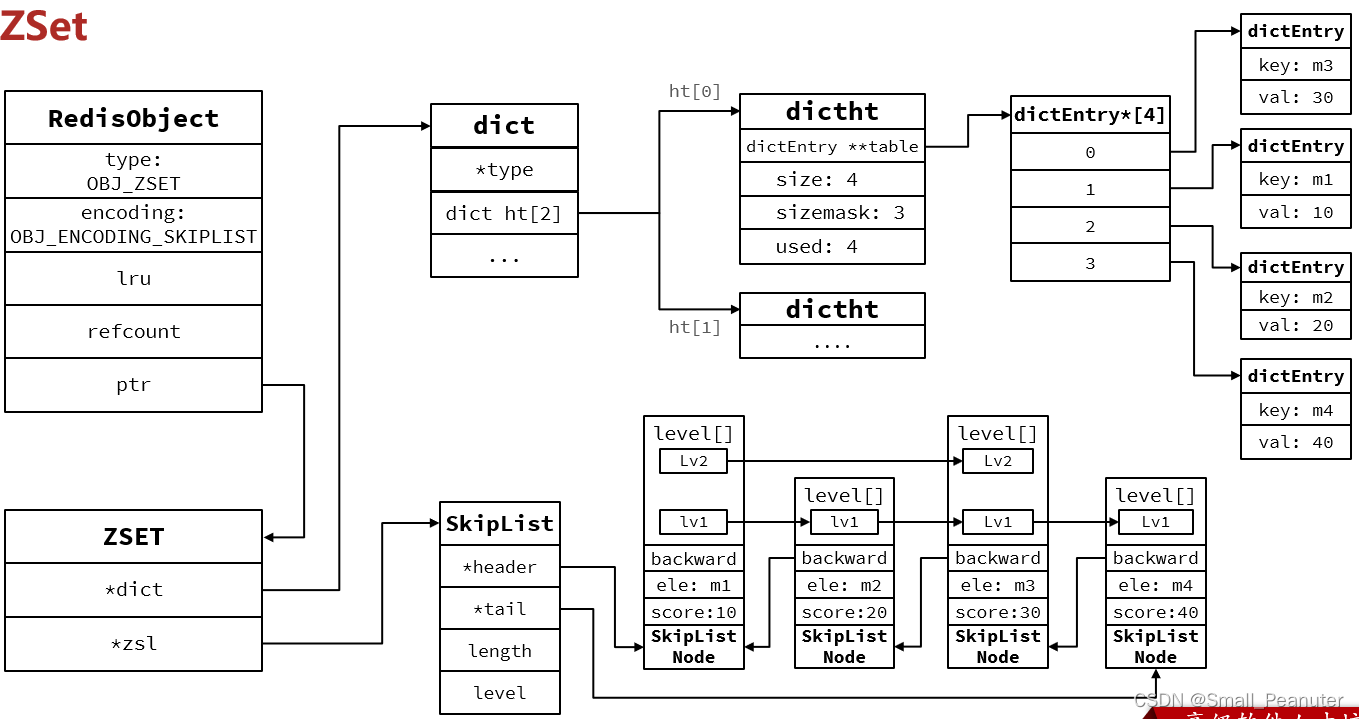
5.zset的内部结构
1.zset
ZSet也就是SortedSet,zset底层数据结构必须满足键值存储、键必须唯一、可排序其中每一个元素都需要指定一个score值和member值:
- 可以根据score值排序后
- member必须唯一
- 可以根据member查询分数
SkipList:可以排序,并且可以同时存储score和ele值(member)
HT(Dict):可以键值存储,并且可以根据key找value
// zset结构
typedef struct zset {
// Dict指针
dict *dict;
// SkipList指针
zskiplist *zsl;
} zset;
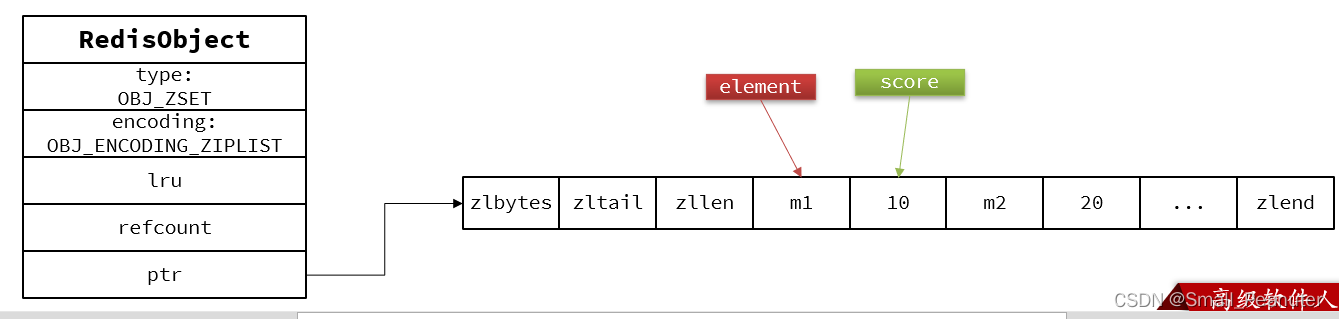
Zset的另一种格式当元素不多时,使用的ziplist的结构。
当元素数量不多时,HT和SkipList的优势不明显,而且更耗内存。因此zset还会采用ZipList结构来节省内存,不过需要同时满足两个条件:
ziplist本身没有排序功能,而且没有键值对的概念,因此需要有zset通过编码实现:
ZipList是连续内存,因此score和element是紧挨在一起的两个entry, element在前,score在后
score越小越接近队首,score越大越接近队尾,按照score值升序排列
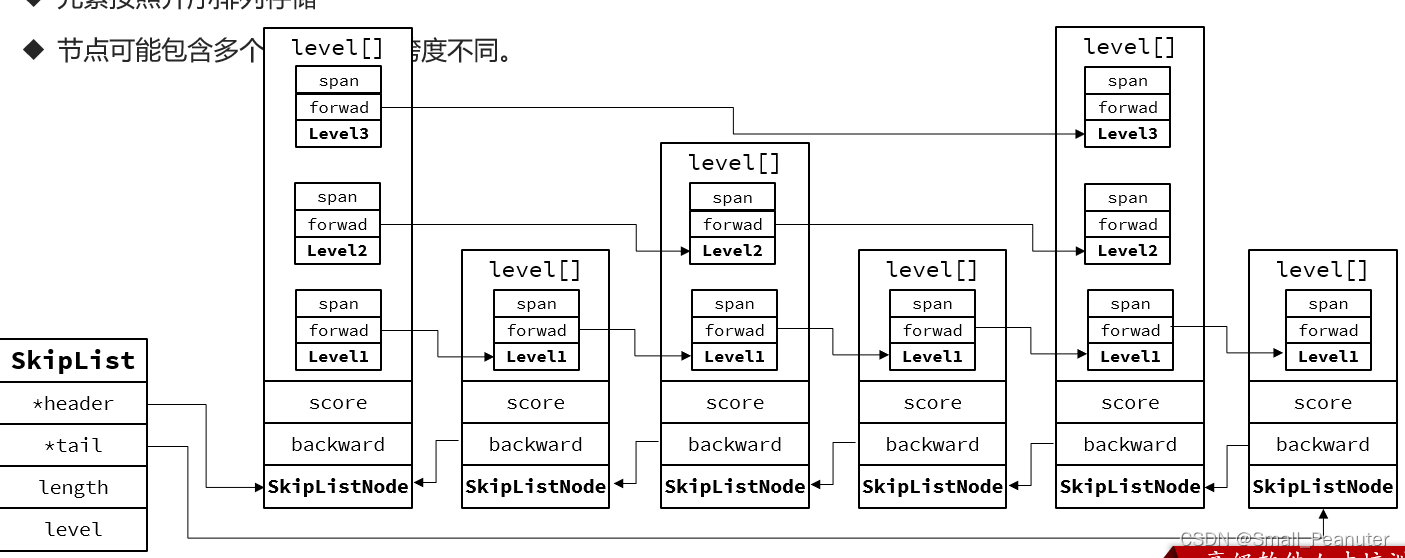
2.skiplist
SkipList(跳表)
- 元素按照升序排列存储
- 节点可能包含多个指针,指针跨度不同。
// t_zset.c
typedef struct zskiplist {
// 头尾节点指针
struct zskiplistNode *header, *tail;
// 节点数量
unsigned long length;
// 最大的索引层级,默认是1
int level;
} zskiplist;
// t_zset.c
typedef struct zskiplistNode {
sds ele; // 节点存储的值
double score;// 节点分数,排序、查找用
struct zskiplistNode *backward; // 前一个节点指针
struct zskiplistLevel {
struct zskiplistNode *forward; // 下一个节点指针
unsigned long span; // 索引跨度
} level[]; // 多级索引数组
} zskiplistNode;
跳表根据score排序,ele是sds类型,不同node的level是不同的。
6.hash的内部结构(ziplist和dict)
Hash结构与Redis中的Zset非常类似:
- 都是键值存储
- 都需求根据键获取值
- 键必须唯一
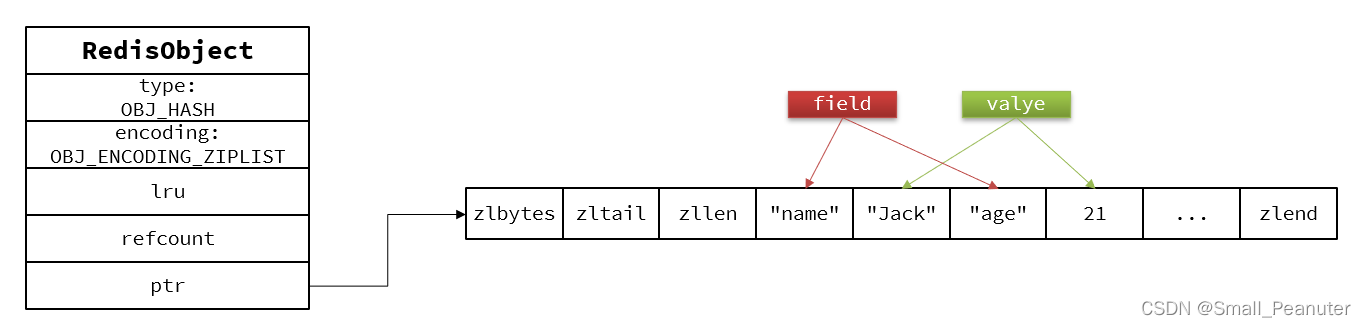
Hash结构默认采用ZipList编码,用以节省内存。 ZipList中相邻的两个entry 分别保存field和value
当数据量较大时,Hash结构会转为HT编码,也就是Dict
- hash的ziplist结构:
- hash的dict结构
二、redis通信协议和网络模型
1.RESP协议
Redis是一个CS架构的软件,通信一般分两步:
客户端(client)向服务端(server)发送一条命令
服务端解析并执行命令,返回响应结果给客户端
因此客户端发送命令的格式、服务端响应结果的格式必须有一个规范,这个规范就是通信协议
-
单行字符串:首字节是 ‘+’ ,后面跟上单行字符串,以CRLF( “\r\n” )结尾。例如返回"OK": “+OK\r\n”
-
错误(Errors):首字节是 ‘-’ ,与单行字符串格式一样,只是字符串是异常信息,例如:“-Error message\r\n”
-
数值:首字节是 ‘:’ ,后面跟上数字格式的字符串,以CRLF结尾。例如:“:10\r\n”
-
多行字符串:首字节是 ‘$’ ,表示二进制安全的字符串,最大支持512MB: $5\r\nhello\r\n
-
数组:首字节是 ‘*’,后面跟上数组元素个数,再跟上元素,元素数据类型不限:

2.网络模型
1.内核空间两个阶段
阶段一:
用户进程尝试读取数据(比如网卡数据)
此时数据尚未到达,内核需要等待数据
阶段二:
数据到达并拷贝到内核缓冲区,代表已就绪
将内核数据拷贝到用户缓冲区
2.IO模型
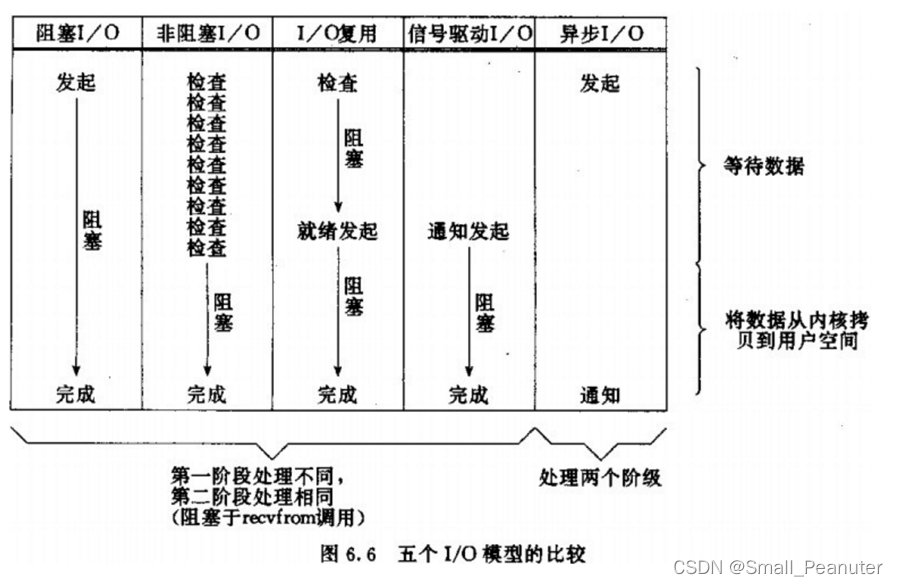
在《UNIX网络编程》一书中,总结归纳了5种IO模型:
-
阻塞IO(Blocking IO):阻塞IO模型中,用户进程在两个阶段都是阻塞状态。
-
非阻塞IO(Nonblocking IO):非阻塞IO模型中,用户进程在第一个阶段是非阻塞,第二个阶段是阻塞状态。虽然是非阻塞,但性能并没有得到提高。而且忙等机制会导致CPU空转,CPU使用率暴增。
-
IO多路复用(IO Multiplexing)
- 阶段一:
用户进程调用select,指定要监听的FD集合
内核监听FD对应的多个socket
任意一个或多个socket数据就绪则返回readable
此过程中用户进程阻塞 - 阶段二:
用户进程找到就绪的socket
依次调用recvfrom读取数据
内核将数据拷贝到用户空间
用户进程处理数据
- 阶段一:
-
信号驱动IO(Signal Driven IO)
- 阶段一:不阻塞
用户进程调用sigaction,注册信号处理函数
内核返回成功,开始监听FD
用户进程不阻塞等待,可以执行其它业务
当内核数据就绪后,回调用户进程的SIGIO处理函数 - 阶段二:阻塞
收到SIGIO回调信号
调用recvfrom,读取
内核将数据拷贝到用户空间
用户进程处理数据
缺点:当有大量IO操作时,信号较多,SIGIO处理函数不能及时处理可能导致信号队列溢出,而且内核空间与用户空间的频繁信号交互性能也较低。
- 阶段一:不阻塞
-
异步IO(Asynchronous IO)
- 第一阶段:调用aio_read,并创建回调函数,通知内核工作,不阻塞
- 第二阶段:内核将数据从内核缓冲区拷贝到用户缓冲区,内核递交信号触发aio_read中的回调函数,不阻塞。
- 信号IO和异步IO的主要区别在于用户空间注册信号后,内核通知的时机,前者在第二阶段开始前,用户空间开始阻塞等待数据的到来,而后者则是在数据已经到达用户空间则通知用户进程完成后续工作,所以第二阶段也不用阻塞
IO操作是同步还是异步,关键看数据在内核空间与用户空间的拷贝过程(数据读写的IO操作),也就是阶段二是同步还是异步
三、redis内存回收
1.过期数据处理策略
redisDb结构体记录了所有的key和TLL存活时间,我们通过expires指向的字典检查是否过期,如果过期,通过expires找到key,再通过dict找到对应的数据,进行删除。
typedef struct redisDb {
dict *dict; /* 存放所有key及value的地方,也被称为keyspace*/
dict *expires; /* 存放每一个key及其对应的TTL存活时间,只包含设置了TTL的key*/
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID,0~15 */
long long avg_ttl; /* 记录平均TTL时长 */
unsigned long expires_cursor; /* expire检查时在dict中抽样的索引位置. */
list *defrag_later; /* 等待碎片整理的key列表. */
} redisDb;
-
惰性删除:在访问一个key的时候,检查该key的存活时间,如果已经过期才执行删除。
-
周期删除:顾明思议是通过一个定时任务,周期性的抽样部分过期的key,然后执行删除。执行周期有两种:
- SLOW模式规则:
执行频率受server.hz影响,默认为10,即每秒执行10次,每个执行周期100ms。
执行清理耗时不超过一次执行周期的25%.默认slow模式耗时不超过25ms
逐个遍历db,逐个遍历db中的bucket,抽取20个key判断是否过期
如果没达到时间上限(25ms)并且过期key比例大于10%,再进行一次抽样,否则结束 - FAST模式规则(过期key比例小于10%不执行 ):
执行频率受beforeSleep()调用频率影响,但两次FAST模式间隔不低于2ms
执行清理耗时不超过1ms
逐个遍历db,逐个遍历db中的bucket,抽取20个key判断是否过期
如果没达到时间上限(1ms)并且过期key比例大于10%,再进行一次抽样,否则结束
- SLOW模式规则:
2.内存达到上限时的淘汰策略
Redis支持8种不同策略来选择要删除的key,主要作用是决定是否只清除有过期时效限制的数据和判断使用LRU还是LFU:
- noeviction: 不淘汰任何key,但是内存满时不允许写入新数据,默认就是这种策略。
- volatile-ttl: 对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰
- allkeys-random:对全体key ,随机进行淘汰。也就是直接从db->dict中随机挑选
- volatile-random:对设置了TTL的key ,随机进行淘汰。也就是从db->expires中随机挑选。
- allkeys-lru: 对全体key,基于LRU算法进行淘汰
- volatile-lru: 对设置了TTL的key,基于LRU算法进行淘汰
- allkeys-lfu: 对全体key,基于LFU算法进行淘汰
- volatile-lfu: 对设置了TTL的key,基于LFI算法进行淘汰

LFU的访问次数之所以叫做逻辑访问次数,并不是每次key被访问都计数,因为访问次数太多会超过lru的最大值,所以当访问很多次后,再次访问就会提高计数器以再加一的难度,
- LFU步骤:
生成0~1之间的随机数R
计算 (旧次数 * lfu_log_factor + 1),记录为P
如果 R < P ,则计数器 + 1,且最大不超过255
访问次数会随时间衰减,距离上一次访问时间每隔 lfu_decay_time 分钟,计数器 -1















 1938
1938











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









