






1.EA和RL结合的动机:
RL:探索是局部和有限的,但学习效率高,充分利用经验。
EA:探索是全局的、多样的,但却是冗余的,学习效率低,特别是在高维问题中,且很难从经验中学习,严重依赖于人类现有的知识。
2.ERL的三个方向:
- EA辅助的RL优化:这种方法侧重于利用EAs的探索优势和全局优化能力来增强RL过程,解决RL在探索和易受局部最优解影响的局限性。
- RL辅助的EA优化:相反,这种策略涉及将RL技术纳入EAs中以改善如种群评估、变异算子或动态算法配置等方面,利用RL的学习效率和经验利用。
- EA和RL的协同优化:一种更加集成的方法,其中保持EA和RL过程并行,允许相互增强,利用它们各自的优势更有效地解决复杂的序贯决策问题。
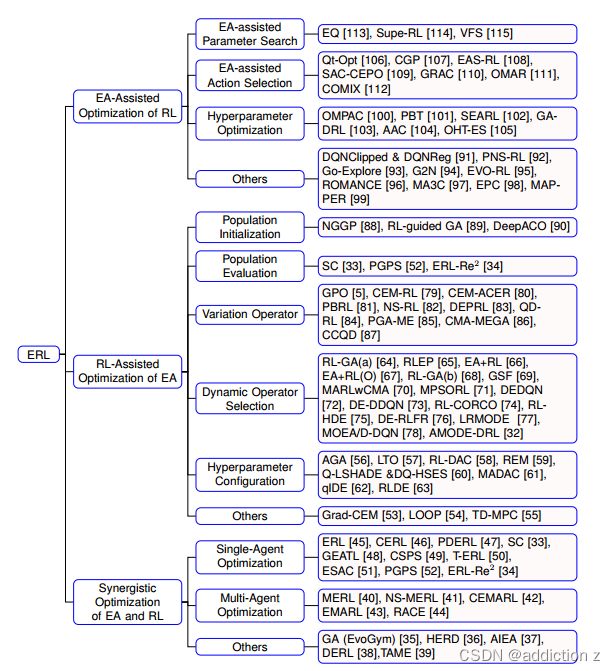
2.1EA辅助的RL优化
2.1.1EA辅助参数搜索
这里的参数搜索指演员或评论家网络的参数。如EQ:创建了评论家种群,每个评论家都用策略梯度优化相应的演员。Super-RL:每隔一定的时间间隔,引入基于当前RL策略(演员)的扰动来初始化种群。种群与环境交互,精英个体将其参数软更新到RL策略。而且缓冲区只收集精英在种群评估阶段的经验。VFS基本和Super-RL相同,区别是优化评论家种群。
和ERL的区别:ERL中RL代理能从EA评估时取得的经验学习,EA种群最弱个体也能定期同步RL代理的参数,是协同优化的。
2.1.2EA辅助动作选择
动作选择贯穿于优化Q网络和做出决策的过程,极为重要。在动作空间很大时,传统的强化学习通常采用贪婪策略或从分布中随机抽样进行选择,但很难准确地捕捉到最佳行为。
做法:初始化一群行动,并使用Q值作为适应度来评估它们的质量。
2.1.3EA辅助超参数优化
主要解决强化学习中臭名昭著的超参数敏感性问题。
如OMPAC和PBT采用遗传算法进行RL超参数优化包括λ,γ,lr,softmax动作选择的温度τa等。
SEARL比起前两种还优化了网络架构(层、节点、激活函数)以及Actor和Critic的学习率。在五分之四的MuJoCo任务中,SEARL的性能优于PBT。GA-DRL侧重于调整更大范围的超参数,可以在大多数机械臂控制任务中获得较好的性能。
2.1.4其他
如:Evo-Meta RL使用进化的思想来寻找能够在不同环境中泛化的RL损失函数。PNS-RL由多个种群组成,每个种群由多个勘探策略和一个指导策略组成,提高了探索能力,优于PBT-TD3, P3S-TD3, CEM-TD3等等。
2.1.5挑战和未来方向
挑战1)研究人员需要定义个体形式、适应度函数、变异和选择运算符,需要领域知识。2)引入EA增加了计算成本3)EA引入了额外的超参数,而且EA对超参数也很敏感,调参困难。4)涉及EA辅助RL的工作主要展示了它们在序贯决策问题中的有效性,其他领域仍需探索。
未来方向1)建立一个自动配置机制,以增强EA的可用性。 2)提高EA的样本效率和收敛性能,例如构建更加样本有效和准确的种群评估方法。 3)尝试引入更高效、更稳健、对超参数不太敏感的RL的EA。 4)此外,EA在RL中的作用,超越了上述方面,仍有待进一步探索。此外,还需要更深入地研究EA辅助RL在各种其他优化问题中的潜力。
2.2RL辅助的EA优化
2.2.1种群初始化
主要是利用RL的学习能力为种群提供初始解,取代启发式解,提高EA的优化效率。
如 NGGP(解决符号回归问题(SRP)),使用了一个策略梯度引导的序列生成器来生成初始总体,随后进行遗传迭代。DeepACO使用经过强化训练的图神经网络来初始化蚁群优化(ACO)的启发式度量,这个度量本来是专家定义的,这样避免了引入专家知识,同时加快了求解效率。
2.2.2RL协助的种群评估
当用EA来解决样本成本敏感问题时,例如机器人控制,评估过程需要将种群中的解应用于问题以获得适应度。因此可以使用RL值函数来评估EA个体的适应度,从而提高样本效率。
SC通过利用强化学习的评论家作为适应度的代理,并基于重放缓冲区中的样本评估个体。使用两种方法:1.以一定的概率P使用代理进行种群评估,同时以1-P的概率与环境交互。2.初始时,使用代理模型生成一个大于原始大小两倍的种群,然后使用代理模型筛选出一半的个体,之后让经过精炼的种群与环境交互。PGPS采用SC的第二种方法进行评估和个体过滤。ERL-Re2引入h步自举法进行总体评价。以上方法均显著提高了样本效率。G2N采用二值遗传算法种群来控制RL策略网络中隐藏神经元的激活,旨在增强探索能力,在Atari任务上改进PPO和A2C。
2.2.3RL辅助变异算子
传统的变异是无梯度的,依赖随机搜索,探索效率低。为了提高效率,一些工作建议在EA中加入策略梯度指导辅助变异操作。
主要分为两种问题:
1.单目标优化:找到使单个目标最大化的解决方案。GPO通过策略蒸馏和策略梯度(策略蒸馏将一个教师模型的知识转移到一个学生模型中。随后在学生模型用策略梯度精确地调整策略参数)算法设计了基于梯度的交叉和变异。CEM- RL随机选一半的人口用于策略优化TD3评论家,再把评论家的策略梯度注入这些人口中,另一半人口加入高斯噪声进行策略搜索。比起TD3,CEM- RL性能优越.CEM-ACER与CEM- RL相似,但采用ACER代替了TD3。PBRL与CEM- RL相似,但关键的区别是用GA代替CEM,同时结合DDPG进行突变,PBRL显著优于GPO和DDPG。NS-RL不追求性能,而是追求探索,适应度定义为策略与行为表征空间中最接近的k个策略之间的L2距离。群体中最新颖的个体被选为精英。DEPRL在梯度优化中同时最大化奖励和MMD(策略之间的距离),并以奖励和MMD作为适应度度量,在部分MOJOCO任务DEPRL优于CEM- RL。
2.质量-多样性优化:同时考虑解质量和解多样性
QD-RL维护一个存档来保存所有过去的策略。在每次迭代开始时,QD-RL从从存档构造的多样性返回帕累托前沿(指在性能和多样性这两个维度上,没有其他解能同时支配它的解的集合)中选择个体。一半被选中的个体是通过质量批评来优化的,另一半是通过多样性批评来优化的。最后,对后代进行评估并插入到存档中。PGA-ME遵循了类似的过程来改进Map Elite,在QDMuJoCo任务中优于QD- rl和其他QD方法。CCQD将共享状态表示集成到QD域中,还将策略分解为共享表示和独立的策略表示,实现知识共享。CCQD优于以前的QD算法,在QDMuJoCo上达到了新的最先进的性能。
2.2.4RL辅助动态算法配置
许多研究都试图通过动态选择算子和调整超参数配置来提高EA的可用性和鲁棒性,这种超参数配置通常被称为动态算法配置(DAC)。用RL来协助DAC。主要分为:动态算子选择:这里讨论的算法主要针对组合优化问题(COP)、多目标优化问题(MOP)、多目标优化问题(MOOP)和连续优化问题(CTOP)。动态超参数选择:用RL来调整EA超参数配置,包括交叉概率、突变率、种群大小等。
动态算子选择:如RL-GA:人口状态作为RL的输入,reward被定义为后代相对于父母的改进。在每个时间步骤中,RL为GA使用适当的交叉和突变操作符,以及这些操作符应该应用于的父类型。RLEP动态选择EP的变异算子,并直接对变异算子的累计奖励进行建模。除了遗传算子,EA+RL采用RL动态选择适应度函数。......等等
动态超参数选择:引入了rl辅助EA超参数配置,包括交叉概率、突变率、种群大小等。如:AGA利用q-learning动态改变EA的交叉率、变异率、锦标赛大小和种群大小。RL状态对应于种群信息,包括最大适应度、平均适应度、先前的动作向量等信息。RL奖励函数定义为最佳适应度值的改进,激励RL算法以一种导致更优解的方式调整参数。
2.2.5其他
Grad-CEM,LOOP,TD-MPC主要提高了用于模型预测控制(MPC)的CEM的效率。
2.2.6挑战和未来方向
挑战1)利用RL辅助EA优化需要研究人员对要解决的问题有深刻的理解,并将其建模为马尔可夫决策过程(MDP)。这需要丰富的RL知识和对问题的全面把握。2)强化学习引入了额外的超参数,这些超参数通常需要根据具体问题进行调整,以充分发挥强化学习的有效性。一方面,这需要对强化学习和正在解决的问题有深入的了解,另一方面,这可能需要额外的试错开销。3)尽管RL在不同分支的实验中已经证明了增强EA的能力,但缺乏理论支持和收敛保证。4)尽管采用了类似的技术,但缺乏不同方法之间的比较,特别是在动态算法配置中,使得确定哪种方法目前在解决特定问题方面表现更好具有挑战性。
未来方向1)更先进、更稳定的RL算法。例如,探索更一般化的建模方法和开发更通用的强化学习算法。2)建立RL辅助EA算法的理论保证,包括收敛性和性能界限。3)对于每个研究分支对现有方法局限性进行进一步调查
2.3EA与RL的协同优化
2.3.1单智能体优化
最初工作是ERL。之后CERL解决了RL 折扣因子 γ 的敏感性问题,不过这里CERL中的GA并不是为了超参调优,它引入了具有不同γ的演员评论家种群,根据演员表现动态分配资源,这里的γ不会动态调整。受到GPO的启发,PDERL提出了新的交叉和突变算子,解决了ERL中的灾难性遗忘问题。SC动机是降低评估成本,显著提高了EA的采样效率。 与以往将离线策略强化学习(RL)与进化算法(EA)相结合的方法不同,GEATL将在线策略强化学习与进化算法结合起来,而且它与ERL不同的是,EA对RL的影响运作方式不同:当种群中的精英策略优于RL策略时,精英策略取代RL策略。此外,如果它们的表现相似,则精英策略取代RL策略的概率为50%。CSPS集成了SAC、PPO和CEM。当SAC或PPO种群中的策略时它取代这些个体,同时为SAC引入了一个额外的本地经验缓冲区来存储最近生成的经验,并结合了几种经验过滤机制,确保增加的本地经验是最新的。T-ERL将ES与TD3集成在一起,构建的缓冲区类似CSPS一个缓冲区保存所有个体的经验,而另一个保存最近的强化学习经验。ESAC采用ERL框架,用SAC代替DDPG,用改进的ES:引入了自动调节机制来调节ES中附加高斯噪声的系数,记为A-ES代替了GA,该系数根据总体中确定的最佳表现与平均表现之间的差距进行更新。与 GA 不同,ESAC 不会保护精英个体免受突变干扰,相反它采用精英个体和更新后的 ES 分布之间的交叉来将有利特性从精英传递给后代。PGPS将 CEM 与 TD3 结合,在 PGPS 中,大小为 N 的种群由上一代的精英(1 个个体)、从 CEM 分布中随机采样的个体(1 到 N/2)、以及使用 SC 中的代理机制从大型 CEM 采样池中选择的个体(N/2 到 N)组成,还引入了引导策略学习使得精英个体和RL代理的行为不超过阈值(相似),PGPS表现优异,优于CEMRL、PDERL、CERL、CEM等。ERL-Re2加强了种群联系,提出了新的遗传算子,并用h步自举减少了种群评估的成本。
2.3.2多智能体优化
多智能体强化学习(MARL)的重点是合作设置,需要控制一个团队来实现目标。在MARL中,EA提供了一种避免将MARL问题建模为马尔可夫决策过程(MDP)的方法,这样做的优点是能够规避非平稳性问题(即一个智能体的最优行为可能因为其他智能体策略的变化而变得不再最优),EA用于优化基于团队整体奖励信号的团队策略种群,同时使用RL来对个体策略进行优化。CEMARL主要是用CEM代替GA。EMARL将GA与COMA结合起来,首先使用GA对种群中的个体进行优化,然后使用策略梯度进一步增强优化后的种群。RACE将共享表示的概念引入了MARL和EA的集成中,展现出了卓越性能。
2.3.3其他
另一个有前途的方向是形态进化。形态进化不断优化机器人的形态和控制策略。在这类问题中,最终解由两个组成部分构成:最佳形态及其关联的策略。
2.3.4挑战和未来方向
挑战:进一步研究如何有效地将EA和RL的优势整合到策略搜索中。EA和RL的协同优化方向面临着与EA辅助RL优化和RL辅助EA优化类似的挑战,例如对领域知识的需求、对超参数的敏感性等。目前,这个方向主要关注顺序决策问题。需要进一步研究如何在其他优化问题中补充并提供优势。
未来方向:
1)探索如何整合EA和RL来协同优化解决其他问题。2)用更先进的EA或RL算法替换当前ERL方法中的基础算法,充分利用两个领域的前沿技术。3)设计更有效的机制,使EA影响RL或RL影响EA,增强EA和RL之间的积极影响。4)开发更有效的机制来评估适应性,以提高演化的样本效率。在多智能体设置中,结合EA和MARL仍处于起步阶段,但具有重大的进展潜力。

















 2557
2557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









