







这里写自定义目录标题
参考资料
-
开放环境下的协作多智能体强化学习进展综述
袁雷, 张子谦, 李立和, 管聪, 俞扬. 开放环境下的协作多智能体强化学习进展综述. 中国科学: 信息科学, 在审文章 -
An Overview of Multi-agent Reinforcement Learning from Game Theory Perspective
杨耀东 北京大学人工智能研究院助理教授(博导)
汪军
杨耀东知乎 -
多智能体机器学习
UCL汪军
伦敦大学学院计算机系2020-2021学年课程
UCL 汪军教授《Multi-agent AI》课程(中文字幕) -
多智能体强化学习的基础和应用
杨旭韵,工程硕士 -
多智能体强化学习
实战云 -
博士万字总结 || 多智能体强化学习(MARL)大总结与论文详细解读腾讯
博士万字总结 || 多智能体强化学习(MARL)大总结与论文详细解读微信
李文浩-华东师范大学博士生
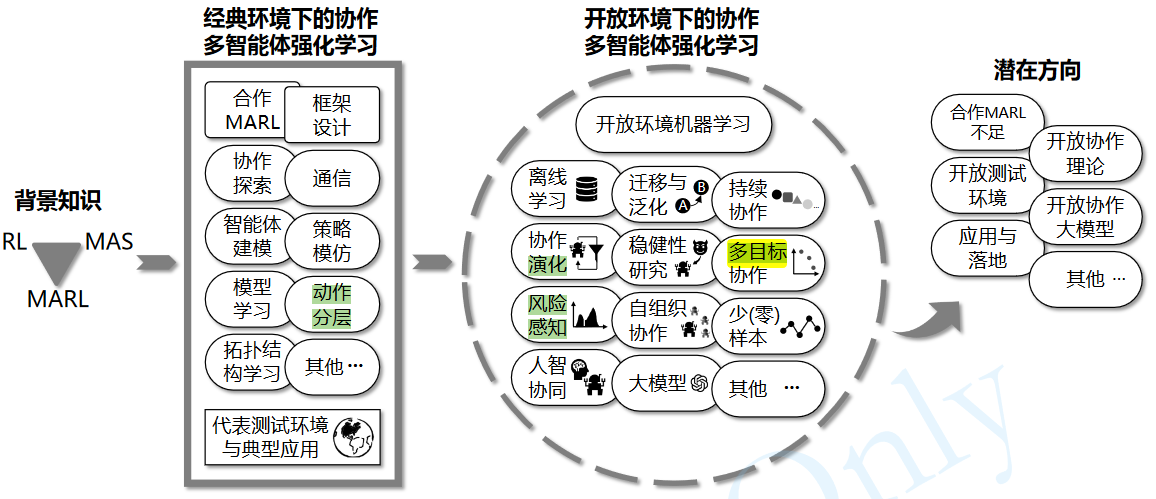
多目标包含安全强化学习(建模为Constrained MDP)
风险感知应该是指奖励的方差不要太大
T. Li et al., “Applications of Multi-Agent Reinforcement Learning in Future Internet: A Comprehensive Survey,” in IEEE Communications Surveys & Tutorials, vol. 24, no. 2, pp. 1240-1279, Secondquarter 2022, doi: 10.1109/COMST.2022.3160697.
Li, T., Zhu, K., Luong, N. C., Niyato, D., Wu, Q., Zhang, Y., & Chen, B.
南京航空航天大学

A SUMMARY OF MARL ALGORITHMS BASED ON INFORMATION SHARING
多智能体强化学习(multi-agent reinforcement learning,MARL)
单智能体强化学习算法的基本假设:动态环境是稳态的(stationary),即状态转移概率和奖励函数不变。
多智能体强化学习要比单智能体更困难:
- 在每个智能体的视角下,环境是非稳态的(non-stationary),即对于一个智能体而言,即使在相同的状态下采取相同的动作,得到的状态转移和奖励信号的分布可能在不断改变;
- 多个智能体的训练可能是多目标的,不同智能体需要最大化自己的利益;
- 训练评估的复杂度会增加,可能需要大规模分布式训练来提高效率。
独立学习(independent learning):完全去中心化的算法
独立 PPO(Independent PPO,IPPO)算法
中心化训练去中心化执行(centralized training with decentralized execution,CTDE)
中心化训练:在训练的时候使用一些单个智能体看不到的全局信息而以达到更好的训练效果
去中心化执行:在执行时不使用这些信息,每个智能体完全根据自己的策略直接动作。
优点:能够在训练时有效地利用全局信息以达到更好且更稳定的训练效果,同时在进行策略模型推断时可以仅利用局部信息,使得算法具有一定的扩展性。
CTDE 算法主要分为两种:
基于值函数的方法:VDN,QMIX 算法等
基于 Actor-Critic 的方法:MADDPG 和 COMA 等
多智能体 DDPG(muli-agent DDPG,MADDPG)
每个智能体实现一个 DDPG 的算法。
所有智能体共享一个中心化的 Critic 网络,该 Critic 网络在训练的过程中同时对每个智能体的 Actor 网络给出指导,而执行时每个智能体的 Actor 网络则是完全独立做出行动,即去中心化地执行。

















 1547
1547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











