






一、摘要
大多数基于卷积网络的图像修复方法采用普通卷积对有效像素和孔洞进行无差别处理,这使得它们在处理不规则孔洞时受到限制,更容易产生色差和模糊的修复结果。部分卷积被提出用来解决这个问题,但是它采用了手工制作的特征重归一化,并且只考虑前向掩码更新。本文提出了一种可学习的注意映射模块,以端到端的方式学习特征重新归一化和掩码更新,该模块能够有效地适应不规则孔洞和卷积层的传播。
二、介绍
PatchMatch通过在已知区域中搜索并复制相似的补丁,逐步填补孔洞。对抗损失被用于提高结果的感知质量和自然度。
部分卷积
部分卷积层(PConv层)优点:使用掩码卷积使输出仅以未掩码输入为条件,并引入特征重新归一化以缩放卷积输出。进一步提出了一种掩码更新规则来更新下一层的掩码,使PConv在处理不规则孔时非常有效。
PConv缺点:①PConv通过绝对信任所有填充的中间特征,采用硬0-1掩码和手工特征重新归一化,而且PConv只考虑前向掩码更新,使得它在处理颜色差异和模糊性方面仍然受到限制。
②PConv简单的在解码器特征上使用全一掩码,使得解码器应该在孔洞和已知区域产生伪影。已知区域的编码器特征将会被连接起来,因此解码器只需要关注孔洞的修复。
在本文中,提出了可学习的双向注意映射模块,用于U-Net架构的编码器和解码器的特征重新归一化,用于学习特征重新归一化和掩码更新。得益于端到端训练,可学习注意映射能够有效适应不规则孔洞和卷积层的传播。而且进一步引入可学习的反向注意映射,让U-Net的解码器只专注于修复孔洞,从而得到我们可学习的双向注意映射。与PConv相比,可学习的双向注意映射的部署在经验上有利于网络训练,使得包含对抗损失以提高结果的视觉质量成为可能。
贡献
①提出了一种可学习的图像修复注意力映射模块。与PConv相比,可学习注意力映射在适应任意不规则孔洞和卷积层的传播方面更有效。
②正向和反向注意映射结合起来组成我们可学习的双向注意映射,进一步有利于视觉效果的提高。
③在两个数据集和现实世界对象去除上的实验表明,我们的方法在幻觉形状、更连贯和视觉上可信的结果方面优于最先进的方法。
三、相关的工作
基于样本的修复
大多数基于样本的图像修复方法都是从已知区域进行搜索粘贴,从外部到内部逐渐填充孔洞],其结果高度依赖于传播过程。一般来说,先填充结构,再填充其他缺失区域,可以获得较好的修复效果。为了指导补丁处理顺序,引入了补丁优先级度量,作为置信度项(置信度项通常被定义为输入块中已知像素的比例)与数据项的乘积。
深度基于CNN的修复
《上下文编码器》采用了编码器-解码器网络,并结合了重建加对抗性损失,以更好地恢复语义结构。
《全局和局部一致的图像补全》结合了全局和局部判别器,以再现语义上合理的结构和局部现实的细节。
《不规则孔洞的局部卷积修复》提出了一种部分卷积层,包括三个步骤,即掩码卷积、特征重新归一化、掩码更新。
《基于门控卷积的自由形式图像修复》提出了门控卷积,该卷积通过考虑损坏的图像、掩码、用户草图来学习信道软掩码。
四、方法
部分卷积

(1)掩码卷积(2)特征重新归一化(3)掩码更新
= M ⓧ K1/9 ,
是卷积掩码,ⓧ是卷积算子, K1/9代表了3 * 3的卷积滤波器,而且每一个元素为1/9。
注意力映射和更新掩码的激活函数:
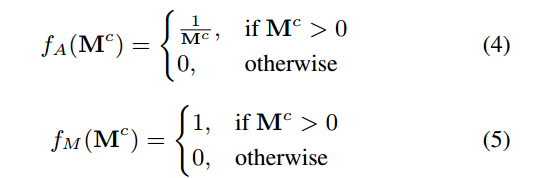
PConv也可以解释为掩码和卷积特征映射之间的一个特殊的相互作用模型。PConv采用手工制作的卷积滤波器K1/9以及手工制作的激活函数fA()和fM(
),fM(
)的非微分性质增加了端到端学习的困难性,将对抗损失与PConv结合起来训练U-Net仍然是一个难题。PConv只考虑掩码及其对编码器特征的更新。在解码器特征上,它简单地采用全一掩码,使得PConv在填充孔洞方面受到限制。
可学习注意力映射
去除偏差时,更新孔中的卷积特征为0,等价的改写成为标准卷积。
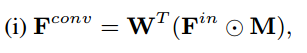
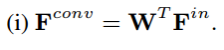
特征重新归一化可以解释为卷积特征与注意力映射的逐元素乘积。
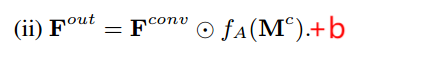
手工制作的卷积滤波器K1/9是固定的,不适应掩码。更新后的掩码激活函数绝对信任区域> 0的修复结果,但对Mc越高的区域赋予越高的置信度更为明智。
改进——提出了可学习注意力映射
①为了使掩码适应不规则孔洞和随层传播,用分层和可学习的卷积滤波器Km代替K1/9。
②代替硬0-1掩码更新,修改更新后的掩码激活函数。当α = 0时fM() = gM(
) 。
③引入非对称高斯形状作为注意力映射的激活函数。
总公式为:
![]()
![]()
![]()
![]() 超参数α = 0.8
超参数α = 0.8
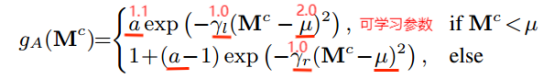
可学习注意映射更加灵活,可以端到端训练,使其有效地适应不规则孔洞和卷积层的传播。
可学习双向注意力映射
编码器特征的l层将与解码器特征的L-l层联合起来,仅能关注孔洞中解码器L-l层的产生。
可学习反向注意力映射的公式为:

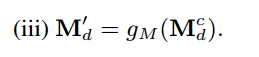
反向注意力映射把编码器特征和解码器特征都考虑进去了。反向注意力映射将更新后的掩码应用于前一解码器层,正向注意力映射将更新后的掩码应用于下一层编码器层。
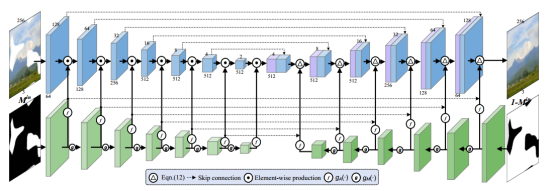
完全可学习注意力映射(f-激活函数、g掩码更新函数)
不规则孔洞的输入图像,
二进制掩码,1代表有效像素,0代表孔洞像素。正向注意力映射以
为输入掩码,对第一层编码器特征进行重新归一化,并逐步更新掩码,将其应用于下一层编码器。反向注意力映射以1-
为输入,对最后一层(L层)解码器特征重新归一化,并逐步更新掩码,将掩码应用于前一层解码器。反向注意力映射使解码器只专注填充不规则的孔洞。
模型架构
修改了14层U-Net架构,去除了瓶颈层,加入了双向注意力映射,编码器的前六层采用正向注意力映射,解码器的后六层采用反向注意力映射。在U-Net架构中,对重新归一化后的特征采用批量归一化和非线性leaky ReLU,最后一层卷积之后应用tanh非线性。我们采用非对称高斯形状的激活函数(gA(·))来激活注意力映射,采用改进的基于ReLU的激活函数(gM(·))来更新掩码图。考虑到U-Net结构的跳跃连接,将对称的正向和反向注意力映射连接起来,用于对解码器中相应层的连接特征进行归一化。此外,对注意力重新归一化后的特征采用了批量归一化和Leaky ReLU非线性。我们的LBAM模型的最后一层使用大小为4 × 4, stride = 2, padding = 1的滤波器直接反卷积,然后进行tanh非线性激活。
可学习的双向注意模型以受损图像、掩码Min和反向掩码1−Min作为输入。我们采用基本的14层U-Net结构,编码器和解码器都由7层组成。正向注意图以掩码Min为输入,共7层,反向注意图以反掩码1−Min为输入,共6层。
批量归一化
批量归一化(Batch Normalization),该方法依靠两次连续的线性变换,希望转化后的数值满足一定的特性(分布),不仅可以加快了模型的收敛速度,也一定程度缓解了特征分布较散的问题,使深度神经网络(DNN)训练更快、更稳定。
随着网络深度的增加,每层特征值分布会逐渐的向激活函数的输出区间的上下两端(激活函数饱和区间)靠近,长此以往则会导致梯度消失,从而无法继续训练模型。BN就是通过方法将该层特征值分布重新拉回标准正态分布,特征值将落在激活函数对于输入较为敏感的区间,输入的小变化可导致损失函数较大的变化,使得梯度变大,避免梯度消失,同时也可加快收敛。
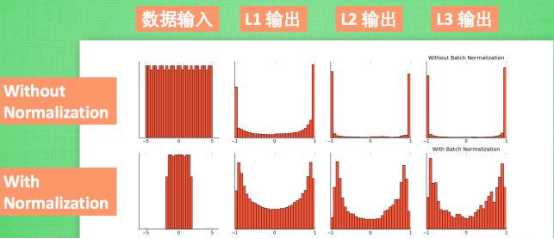
激活函数本质上想要放大差别。BN 层使训练更快,并允许更广泛的学习率,而不会影响训练收敛。有BN的模型比没有BN的激活曲线更平滑。添加 BN 层显着降低了训练期间各层之间的相互依赖性(从分布稳定性的角度来看)。
损失函数
逐像素重建损失、感知损失、风格损失、对抗损失。
逐像素重建损失:在捕获高级语义方面受到限制,并且与人类对图像质量的感知不一致。
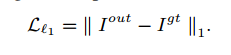
感知损失:其中pi(·)为第i池化层的特征映射。
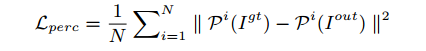
风格损失:特征映射pi (i)的大小为Hi × Wi × Ci。
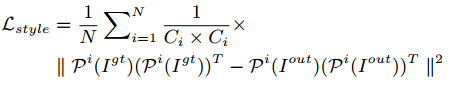
对抗损失:D(.)判别器,I尖通过随机选择的因子线性插值,从Igt和Iout中采样出来的。
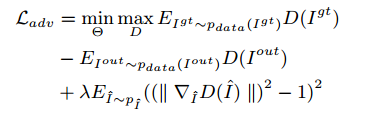
总损失函数:
![]()















 1111
1111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









