







好的表示学习策略必须具备一定的深度
深度(Depth)
神经网络层级个数,层数越多则越深
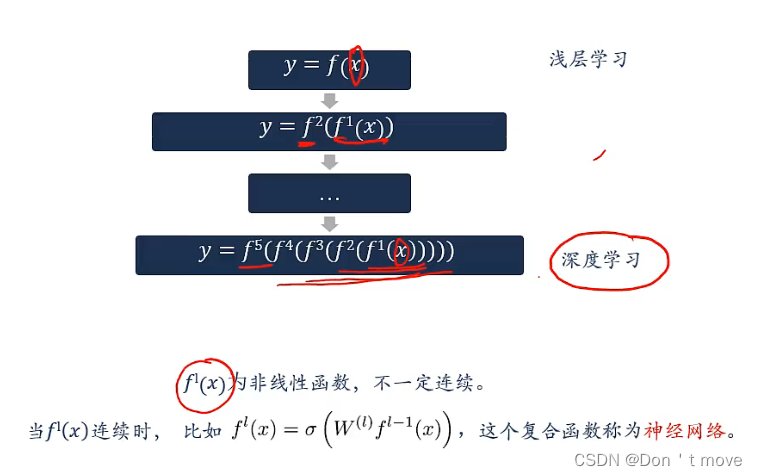
深度学习=表示学习+浅层(决策/预测)学习

这种从原始数据直接产生预测结果,中间特征提取部分不需要人工干预的形式叫做端到端(End-to-End)。大多数的深度学习模型都是端到端模型。
深度学习的难点——贡献度分配问题
深度学习采用的模型一般比较复杂,指样本的原始输入到输出目标之间的数据流经过多个线性或非线性的组件(component)。因为每个组件都会对信息进行加工,并进而影响后续的组件,所以当我们最后得到输出结果时,我们并不清楚其中每个组件的贡献是多少。这个问题叫作贡献度分配问题(Credit Assignment Problem,CAP)1。
解决贡献度分配问题的一个好方法就是神经网络。
深度学习的数学描述
x
x
x是参数,在浅层学习中,需要人为通过进行特征工程来获得这个代表高层语义的参数。通过不断的嵌套函数,使函数嵌套的更”深“,来实现使用计算机来提取特征,用上图深度学习一行解释,
f
1
f^1
f1—
f
4
f^4
f4是特征提取函数,通过提取四层函数来不断提取出特征,最后通过
f
5
f^5
f5分类器函数对特征进行分类。
f n ( x ) f^n(x) fn(x)为非线性函数的原因
对于线性函数来说,嵌套的结果仍是线性函数,这样的嵌套没有意义。比如说:
f 1 ( x ) = a 1 x + b 1 , f 2 ( x ) = a 2 x + b 2 f^1(x)=a_1x+b_1,f^2(x)=a_2x+b_2 f1(x)=a1x+b1,f2(x)=a2x+b2
f ( x ) = f 2 ( f 1 ( x ) ) = a 2 ( a 1 x + b 1 ) + b 2 = a 2 a 1 x + a 2 b 1 + b 2 = A x + B \begin{aligned} f(x)&=f^2(f^1(x))\\ &=a_2(a_1x+b_1)+b_2\\ &=a_2a_1x+a_2b_1+b_2\\ &=Ax+B \end{aligned} f(x)=f2(f1(x))=a2(a1x+b1)+b2=a2a1x+a2b1+b2=Ax+B
变量与符号无关,可近似认为 A x + b = a 1 x + b 1 Ax+b=a_1x+b_1 Ax+b=a1x+b1,相当于没有嵌套,因此说线性函数的嵌套是没有意义的。
















 861
861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











