







机器学习解决模式识别任务一般流程

- 特征处理:即特征工程,在机器学习的过程中不关注,但却是完成机器学习任务的重点工程,需要人工提取特征并表示,工作量巨大
- 浅层学习:不涉及特征学习,特征主要靠人工经验或特征转换抽取
人工智能挑战——语义鸿沟
- 底层特征:直接能从数据中提取出的特征,一般指轮廓、边缘、颜色、纹理和形状特征。
- 高层语义:我们所能看的东西,比如对一张人脸提取低层特征我们可以提取到连的轮廓、鼻子、眼睛之类的,那么高层的特征就显示为一张人脸。高层的特征语义信息比较丰富,但是目标位置比较粗略。1
语义鸿沟问题指人们对文本、图像的理解无法从字符串或者图像的底层特征直接获得
数据表示
为解决语义鸿沟问题,需要从底层特征中构造出一些表示(Represention),这些表示能够反映出事物的高层语义特征。数据表示是机器学习的核心问题。
好的数据表示应:
-
具有很强的表示能力
-
使后续学习任务变得简单
-
具有一般性,是任务或领域独立的
在计算机中的表示形式有: -
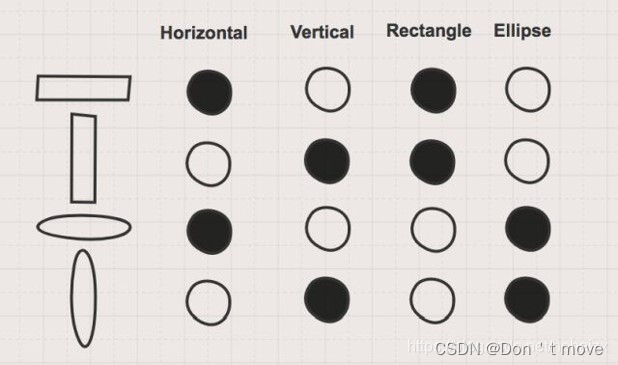
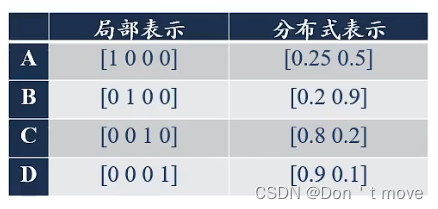
局部表示:又称为离散表示,符号表示。 每个内存单元存储一个数据,向量高维稀疏2,比如One-Hot向量(下图所示就是One-Hot向量)

-
分布式表示:向量中每个分量对应一个数据,各个分量相互排斥2。比方说有N个维度,每个维度可以表示两种语义,则采用分布式表示共可以表示 2 k 2^k 2k个语义
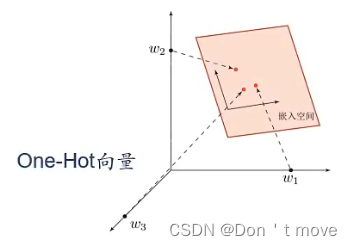
可以使用神经网络来将高维的局部表示空间映射到一个非常低维的分布式表示空间。在这个低维空间中,每个特征不再是坐标轴上的点,而是分散在整个低维空间中。在机器学习中,这个过程也称为嵌入(Emdding)3。
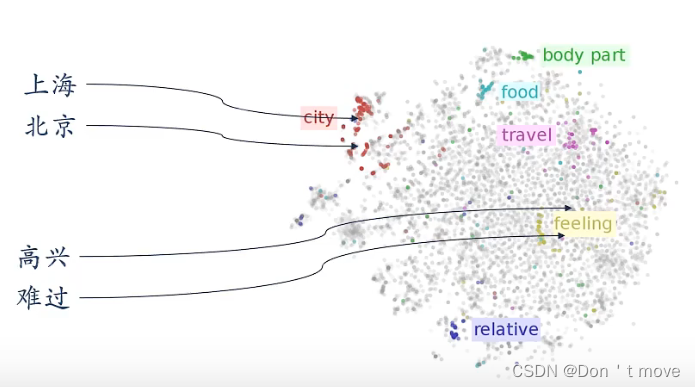
e.g. 词嵌入
要表示一个词的语义,将这个词投到一个语义空间,在空间中越靠近的语义越相似
有了好的数据表示,表示学习只需要关注如何从数据中学习好的表示,通过构建具有一定”深度“的模型,让模型自动学习好的特征表示,从而提升预测或识别的准确性。

表示学习与传统特征提取对比
- 特征提取:基于任务或先验去除无用特征
- 表示学习:通过深度模型学习高层语义特征
特征提取得到的特征并不一定会提高分类器的效果,表示学习是相当于将数据从输入到输出串联到一起,学到的表示对后面的分类有直接的帮助。
表示学习的难点在于没有明确的目标,因此要与模型的预测结果一起进行学习(端到端学习)
















 742
742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











