










 本文介绍了一种使用深度学习模型生成莎士比亚风格诗歌的方法。通过预处理诗词,构建输入序列,训练LSTM和双向LSTM模型,最终能够根据种子文本生成新的诗句。模型的精度和损失随着训练epoch的增加而改善,最终模型能够以一定的随机性生成不超过11个词的诗句,保持了莎士比亚诗作的韵味。
本文介绍了一种使用深度学习模型生成莎士比亚风格诗歌的方法。通过预处理诗词,构建输入序列,训练LSTM和双向LSTM模型,最终能够根据种子文本生成新的诗句。模型的精度和损失随着训练epoch的增加而改善,最终模型能够以一定的随机性生成不超过11个词的诗句,保持了莎士比亚诗作的韵味。
导入需要的工具包
诗词句子很短,每个of等词都有意义,不需要过滤词汇,所以预处理过程比较简短。
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Embedding, LSTM, Dense, Bidirectional, Dropout
from tensorflow.keras.models import Sequential
from tensorflow.keras import regularizers
from tensorflow.keras.optimizers import Adam
import numpy as np
定义tokenizer对象,并准备训练数据
tokenizer = Tokenizer()
data= open('sonnets.txt').read()
corpus = data.lower().split('\n')
tokenizer.fit_on_texts(corpus)
total_words = len(tokenizer.word_index) + 1
#print(tokenizer.word_index)
print(len(corpus))
print(total_words)
所以一共由2159句诗词,总共有3211个单词

‘from fairest creatures we desire increase,’, “that thereby beauty’s rose might never die,”
 前两行是’from fairest creatures we desire increase,’, “that thereby beauty’s rose might never die,”
前两行是’from fairest creatures we desire increase,’, “that thereby beauty’s rose might never die,”
input_sequences = []
for line in corpus:
token_list = tokenizer.texts_to_sequences([line])[0]
for i in range(1, len(token_list)):
n_gram_sequence = token_list[:i+1]
input_sequences.append(n_gram_sequence)
print(len(input_sequences))
#pad sequences
max_sequence_len = max([len(seq) for seq in input_sequences])
print(max_sequence_len, total_words)
input_sequences = np.array(pad_sequences(input_sequences, padding='pre', maxlen=max_sequence_len))
print(input_sequences[:,-1].shape)
#构建<seed, next_word>训练数据对
xs, labels = input_sequences[:,:-1], input_sequences[:,-1]
ys = tf.keras.utils.to_categorical(labels, num_classes=total_words)
print(ys.shape)
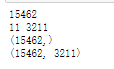
input_suquences中34 417分别代表着from 、fairest
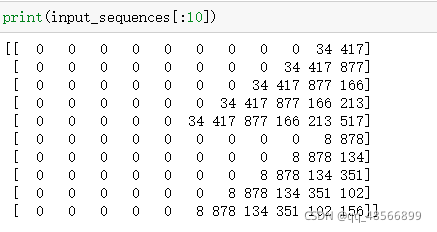
input_sequences中,第一行代表from 、fairest
第五行代表from fairest creatures we desire increase
第10行代表that thereby beauty’s rose might never die
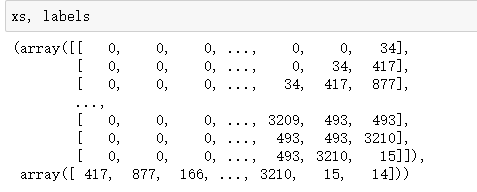
由xs表示seed 来推测下一个单词labels。
比如input_sequences第一行就是用from推出下一个单词fairest
然后在用from fairest推出下一个单词creatures
由以上分析知道:input_sequeces 有15462行,每行的 前:-1的单词作为x,而最后一个单词作为y。
一共有15462对(x,y)
给每个单词一个做一个onehot编码。然后每个y对应编码形式、
ys就是表示了将15462个y,每个都用单词的编号进行表示。
构建深度模型并训练
双边:从开头到结尾,从结尾到开头,能够有更好的记忆
embed_dim数据重复了100多次
embed_dim = 100
model = Sequential()
model.add(Embedding(total_words, embed_dim, input_length=max_sequence_len-1))
model.add(Bidirectional(LSTM(128)))
#model.add(Bidirectional(LSTM(96)))
#model.add(Dropout(0.3))
#model.add(Dense(total_words/2, activation='relu', kernel_regularizer=regularizers.l2(0.01)))
model.add(Dense(total_words, activation='softmax'))
model.summary()

model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])
history = model.fit(xs, ys, batch_size=64, epochs=100, verbose=1)

画出精度随epoch变化曲线
注意观察模型在什么时候开始收敛
import matplotlib.pyplot as plt
def plot_graphs(history, string):
plt.plot(history.history[string])
plt.xlabel("Epochs")
plt.ylabel(string)
plt.show()
plot_graphs(history, 'acc')
plot_graphs(history, 'loss')
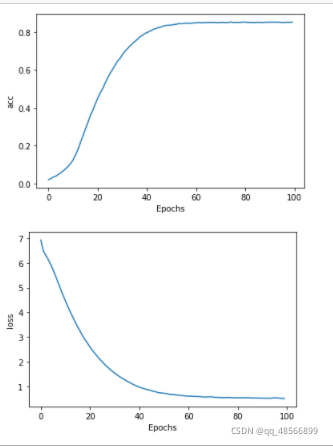
Epochs不是越多越好,选择50 就可以了。
保存训练好的模型
model.save('shakespeare_model.h5')
输入种子文本,并产生接下来的50个单词
def predict_next_words(seed_text, next_words):
for _ in range(next_words):
token_list = tokenizer.texts_to_sequences([seed_text])[0]
token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')
#predicted = model.predict_classes(token_list, verbose=0)
predicted = np.argmax(model.predict(token_list), axis=-1)
output_word = ""
for word, index in tokenizer.word_index.items():
#print(word,type(index))
if index == predicted:
output_word = word
break
seed_text += " " + output_word
print(seed_text)
return seed_text
seed_text = "from fairest creatures we desire increase"
next_words = 50
generated_text = predict_next_words(seed_text, next_words)

seed_text = "making a famine where"
generated_text = predict_next_words(seed_text, next_words)

每一行不多于11词,每次需要加入换行,
给定了种子,每次结果是一样的,生成的文本确定性问题,但是不需要文本一样,所以需要一定的随机性,但也不能完全随机,如果随机从文本中输出单词就没有意义了。max对应概率最大的进行输出。
解释numpy.random.multinomial()函数:
从多项式分布中提取样本。
多项式分布是二项式分布的多元推广。做一个有P个可能结果的实验。这种实验的一个例子是掷骰子,结果可以是1到6。从分布图中提取的每个样本代表n个这样的实验。其值x_i = [x_0,x_1,…,x_p] 表示结果为i的次数。
函数语法
numpy.random.multinomial(n, pvals, size=None)
参数
n : int:实验次数
pvals:浮点数序列,长度p。P个不同结果的概率。这些值应该和为1(但是,只要求和(pvals[:-1])<=1,最后一个元素总是被假定为考虑剩余的概率)。
size : int 或 int的元组,可选。 输出形状。如果给定形状为(m,n,k),则绘制 mnk 样本。默认值为无,在这种情况下返回单个值。
返回值
ndarray,每个条目 [i,j,…,:] 都是从分布中提取的一个n维值。
实例
- 掷骰子20次:
np.random.multinomial(20, [1/6.]*6, size=1)
array([[4, 1, 7, 5, 2, 1]])
表示它落在1号4次,落在2号1次,等等
修改代码:
def predict_next_words(seed_text, next_words):
for _ in range(next_words):
token_list = tokenizer.texts_to_sequences([seed_text])[0]
token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')
#predicted = model.predict_classes(token_list, verbose=0)
#predicted = np.argmax(model.predict(token_list), axis=-1)
predicted=model.predict(token_list,verbose=0)[0]
len_p=len(predicted)
#print(predicted)
temperature=0.5
predicted=predicted**(1/temperature)
p=predicted/np.sum(predicted)
top_n=5
vocab_size=1
p[np.argsort(p)[:-top_n]] = 0#选取了概率较大的前k个
p = p / np.sum(p) # 归一化概率
predicted = np.random.choice(list(range(0,len_p)), 1, p=p)[0]# 随机选取一个字符
output_word = ""
for word, index in tokenizer.word_index.items():
#print(word,type(index))
if index == predicted:
output_word = word
break
seed_text += " " + output_word
print(seed_text)
return seed_text
修改后可以看见,输出不同的内容。
因为每一行不超过11个词,所以如果长度大于11了,就自动换行。
def predict_next_words(seed_text, next_words):
count=0
for _ in range(next_words):
token_list = tokenizer.texts_to_sequences([seed_text])[0]
token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')
#predicted = model.predict_classes(token_list, verbose=0)
#predicted = np.argmax(model.predict(token_list), axis=-1)
predicted=model.predict(token_list,verbose=0)[0]
len_p=len(predicted)
#print(predicted)
temperature=0.5
predicted=predicted**(1/temperature)
p=predicted/np.sum(predicted)
top_n=5
vocab_size=1
p[np.argsort(p)[:-top_n]] = 0
p = p / np.sum(p) # 归一化概率
predicted = np.random.choice(list(range(0,len_p)), 1, p=p)[0]# 随机选取一个字符
output_word = ""
for word, index in tokenizer.word_index.items():
#print(word,type(index))
if index == predicted:
output_word = word
break
count=count+1
if count==10:
output_word=output_word+"\n"
count=0
seed_text += " " + output_word
print(seed_text)
return seed_text
于是生成了有不同结果,且可以换行的诗句。
总结
1.在生成文本时,需要给一个种子片段作为输入,然后就可以进行生成,重复进行以下几步:
把segment输入神经网络
神经网络输出各个字符的概率
从概率值中进行Sample得到next_char
把新生成的字符接到片段的后面
2.可以通过画图的方式 画出精度随epoch变化曲线,观察模型在什么时候开始收敛,选择epoch参数。
3.通过多项式抽样,可以使得生成文本有一定程度的随机性。
预测下一个字符时
在模型搭建好后,我们有以下三种策略来选择下一个字符。
Option 1:Greedy selection
第一种方法是进行贪婪选择,直接选最大概率的那个。但这种方法生成的文本是确定的,文章都是固定的,可读性极差
predicted=model.predict(token_list,verbose=0)[0]
predicted = np.argmax(model.predict(token_list), axis=-1)
Option 2:Sampling from the multinomial distribution
第二种方法是根据输出的各个字符概率值进行多项式分别抽样,这种情况下具有随机性,生成效果较好。但是可能过于随机。
predicted=model.predict(token_list,verbose=0)[0]
Next_onehot=np.random.multinomial(1,predicted,1)
Next_index=np.argmax(next_onehot)
Option 3:adjust the multinomial distribution
第三种方式则是在原始概率分布上加幂次再重新计算概率分别,这种情况下,会使得在方法二中概率大的更大一些。效果也更好一些。这种方法使综合了方法1和2的优点,具有随机性,也能控制随机性
predicted=model.predict(token_list,verbose=0)[0]
temperature=0.5
predicted=predicted**(1/temperature)
Predicted=predicted/np.sum(predicted)
4.换行,诗词的每一行不会超过11个,所以对输出文本进行技术,如果超过了11就输出\n

















 1193
1193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









