







无公开代码
Generative Named Entity Recognition.
Electronics 2024, 13, 1407. https://
doi.org/10.3390/electronics13071407
Academic Editor: Manohar Das
Received: 14 March 2024
Revised: 1 April 2024
Accepted: 4 April 2024
Published: 8 April 202
摘要
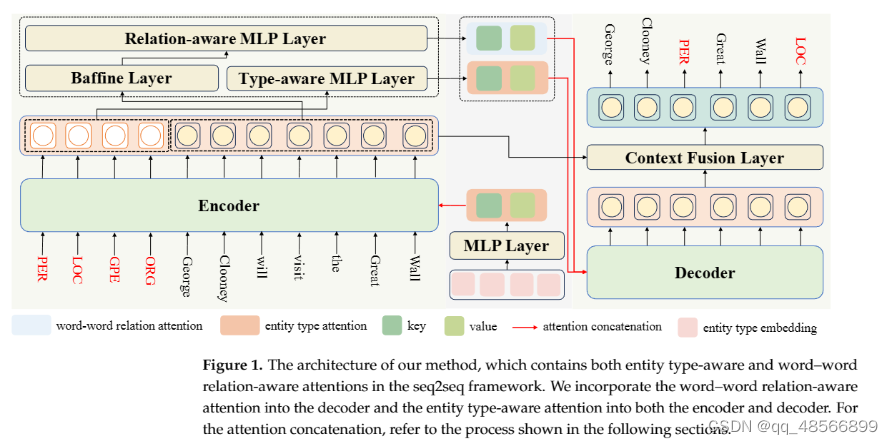
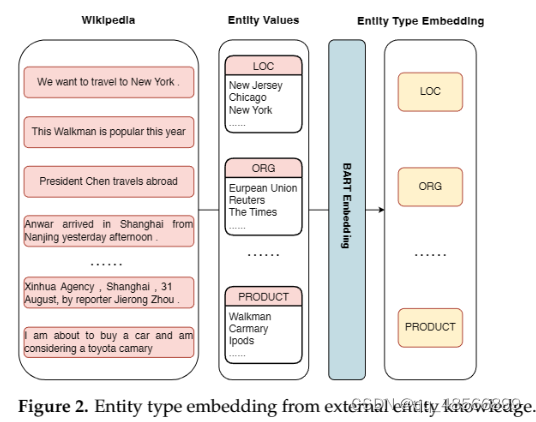
命名实体识别(NER)是自然语言处理中的一个关键子任务。当解决NER问题时,深入理解实体边界和实体类型尤为重要。大多数以前的序列标注模型都是任务特定的,而近年来,由于在编码器-解码器框架中处理NER任务的优势,生成模型逐渐兴起。尽管生成模型取得了不错的表现,我们的初步研究表明,现有的生成模型在检测实体边界和估计实体类型方面效果不佳。本文提出了一种多重注意力框架,引入了实体类型嵌入和词-词关系的注意力机制到命名实体识别任务中。为了提高实体类型映射的准确性,我们采用了外部知识库来计算先验实体类型分布,然后通过编码器的自注意力将该信息输入到模型中。为了增强上下文信息,我们将实体类型作为输入的一部分。我们的方法从实体类型的隐藏状态中获取另一种注意力,并在解码器中利用它进行自注意力和交叉注意力机制。我们将序列中的实体边界信息转换为词-词关系,并将相应的嵌入提取到交叉注意力机制中。通过词-词关系信息,该方法可以学习和理解更多的实体边界信息,从而提高实体识别的准确性。我们在大量NER基准上进行了实验,包括四个平面实体和两个长实体基准。我们的方法显著提高了生成NER模型的性能或达到了相当的效果。实验结果表明,我们的方法可以大大增强生成NER模型的能力。
关键词
命名实体识别;注意力;生成模型
主要内容:
-
NER概述:
- 命名实体识别(NER)是自然语言处理中的一个重要任务,涉及识别和分类文本中的实体(例如人名、组织名称、地点等)。
- 准确识别实体边界(实体在文本中的起止位置)和实体类型(实体的类别,如人名、组织名等)非常关键。
-
现有模型的局限性:
- 传统的序列标注模型通常是任务特定的,在不同任务之间的泛化能力有限。
- 最近的生成模型(使用编码器-解码器框架)在NER中表现出色,但在准确检测实体边界和识别实体类型方面仍有不足。
-
提出的解决方案——多重注意力框架:
- 作者提出了一种新方法,介绍了多重注意力机制以提高NER的性能。
- 实体类型嵌入和词-词关系:
- 引入注意力机制,专注于嵌入实体类型和理解文本中的词与词之间的关系。
- 外部知识库:
- 使用外部知识库预先计算实体类型的可能分布,并通过编码器的自注意力将其整合到模型中。
- 增强上下文信息:
- 将实体类型信息直接纳入输入,增强模型理解上下文的能力。
- 自注意力和交叉注意力机制:
- 利用实体类型的隐藏状态在解码器中进行自注意力和交叉注意力机制,以提高实体识别能力。
- 词-词关系嵌入:
- 将实体边界信息转换为词与词之间的关系嵌入,并在交叉注意力机制中使用这些信息,以更好地理解实体边界。
-
实验结果:
- 作者在多个NER基准数据集上进行了实验,包括平面实体(简单的、非嵌套的实体)和长实体(更复杂的、嵌套的实体)数据集。
- 提出的方法显著提高了现有最好的生成NER模型的性能,或表现相当,展示了方法的有效性。
-
结论:
- 研究表明,多重注意力框架显著增强了生成模型在NER任务中的能力,带来了更好的实体识别和分类效果。
这段文本主要介绍了一种新颖的、多重注意力机制的框架,该框架通过结合外部知识库、实体类型嵌入和词-词关系信息,显著提升了生成模型在命名实体识别任务中的性能。















 586
586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









