







 本文详细介绍了命名实体识别(NER)的任务背景、标注语料库、工具库、序列标注标签方案以及各种NER方法,包括规则、无监督、机器学习和深度学习。深度学习模型如Bi-LSTM+CRF已成为NER的标准配置,但也面临数据标注复杂性、实体类型多样、实体重叠和计算资源限制等挑战。未来研究方向包括多类别实体、嵌套实体和结合知识图谱的NER方法。
本文详细介绍了命名实体识别(NER)的任务背景、标注语料库、工具库、序列标注标签方案以及各种NER方法,包括规则、无监督、机器学习和深度学习。深度学习模型如Bi-LSTM+CRF已成为NER的标准配置,但也面临数据标注复杂性、实体类型多样、实体重叠和计算资源限制等挑战。未来研究方向包括多类别实体、嵌套实体和结合知识图谱的NER方法。
文章目录
1 简介
命名实体识别(Named Entity Recongnition,NER)是自然语言处理中的一个基础任务,也是知识图谱构建的关键步骤。一句话就是,NER从自由文本里面识别出预定义的文本片段。
在2005年之前,实体识别任务数据集主要是对新闻做的标注,实体类别数量较少,如实体、时间、数字三大类,人名、机构名、地名、时间、日期、货币和百分比7小类。现在NER任务已经深入到各个垂直领域,比如医疗,金融,法律等等。(通用类实体和特定领域类实体)
2 NER标注语料库
对现有公开评测任务使用的NER语料库进行了汇总,包括链接地址、类别个数以及语料类型。如下图。

3 NER工具库
目前已经有很多现成的(off-the-shelf)NER工具,论文(见参考文献)对学术界和工业界一些NER工具进行汇总,工具中通常都包含预训练模型,可以直接在自己的语料上做实体识别。如果涉及到自己所在特定的领域,还需要依据待抽取领域语料重新训练模型。

4 序列标注标签方案
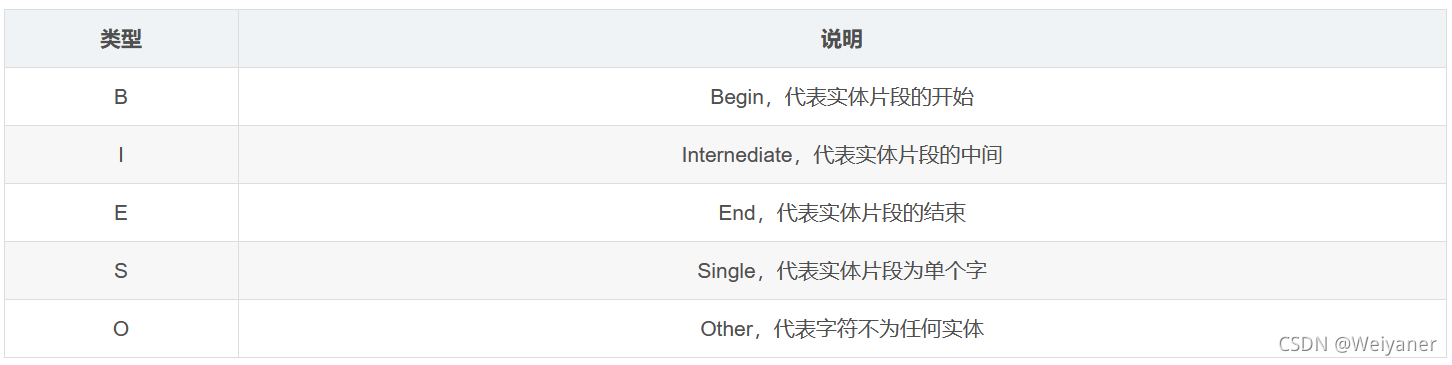 BIO:标识实体的开始,中间部分和非实体部分
BIO:标识实体的开始,中间部分和非实体部分
BIOS:增加S单个实体情况的标注
BIOSE:增加E实体的结束标识
下面是BIO和BIOSE的举例

采用不同的标注体系,会对模型产生不同的影响。“BIO”、“BMES”、“BIOES”是常用的三种标签体系,此外还有BIO、BIOSE、IOB、BILOU、BMEWO等,其思想在于一个实体词拥有起始位置和终止位置,而每个字符都充当了构成一个实体词的特定成分,例如:
1)单标签实体标注
在进行多个实体类型识别时,则需要构造相应数量级的实体标签集合。
例如,在这个框架下进行标注时,机构类型ORG,对应于B-ORG,I-ORG的标签类型,给定句子: “我毕业于北京语言大学”,
利用BIO标签标注为:
“我/O 毕/O 业/O 于/O 北/B-ORG 京/I-ORG 语/I-ORG 言/I-ORG 大/I-ORG 学/I-ORG”。
2)多标签实体标注
针对所有可能出现重叠的实体类型,进行标签的两两组合,产生新的标签集合。
例如将“B-Loc”与“B-Org”组合起来,构造一个新的标签“B-Loc|Org”,然后同样作为一个单标签分类问题,针对每个字符,输出对应的标签。
设置多个标签层,对于每一个token给出其所有的label,然后将所有标签层合并。
3)单层指针标注
MRC中通常根据1个question从passage中抽取1个答案片段,转化为若干个n元SoftMax分类预测头指针和尾指针。
对于NER可能会存在多个实体Span,因此需要转化为n个2元Sigmoid分类预测头指针和尾指针。
对每个span的start和end进行标记,对于多片段抽取问题转化为N个2分类(N为序列长度),如果涉及多类别可以转化为层叠式指针标注(C个指针网络,C为类别总数)。
4)多层指针标注
多层label指针网络是对单层指针网络的扩展。由于只使用单层指针网络时,无法抽取多类型的实体,通常可以构建多层指针网络,每一层都对应一个实体类型。
5)多头指针标注
对对每个token pair进行标记,其实就是构建一个 [公式] 的分类矩阵,可以用于实体或关系抽取。其重点就是如何强有力的表征构建分类矩阵。对于每类实体,常采用标签-实体类型的方式进行标记,构建一个 [公式] 的Span矩阵。
5)片段序列标注
片段序列标注源自于Span-level NER的思想,枚举所有可能的span进行分类,同序列长度进行解耦,可以更加灵活地处理复杂抽取和低资源问题。
对于含T个token的文本,理论上共有N=T(T+1)/2种片段排列。如果文本过长,会产生大量的负样本,在实际中需要限制span长度并合理削减负样本。
5 四类NER方法(规则-无监督学习-机器学习-深度学习)
5.1 基于规则的NER
基于规则,其思想在于在观察特定的领域文本以及实体出现的语法构成和模式的情况后,设计特定的实体提取规则以完成提取。
实体词
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1235
1235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











