






BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents
发表于AAAI 2022
团队作者:Teakgyu Hong, Donghyun Kim, Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park
Abstract
目前的问题是:对于KIE就需要需要理解文本在二维(2D)空间中的上下文和空间语义。
目前的研究的重点是将文档图像的视觉特征与文本及布局相结合。文还揭示了KIE任务中的两个现实挑战–(1)最小化错误的文本排序和(2)从较少的下游例子(应该是用于下游任务的训练集)中有效地学习,并证明了BROS相对于以前的方法的优越性。
Conclusion
论文提出的BROS模型将重点放在了文本和布局特征的建模上,通过在二维空间中对文本的相对位置进行编码,并通过区域掩码策略对模型进行预训练,让模型不通过任何额外的视觉特征的情况下也有卓越的性能。并且有更精确的文本序列化和少量的实例训练上也有很好的效果。
提出了一个预先训练好的语言模型,名为BROS(BERT Relying On Spatiality),它对文本在二维空间的相对位置进行编码,并通过区域屏蔽策略的unlabeled的文档中学习(无监督)。
通过这种优化的训练方案来理解二维空间中的文本,BROS在四个KIE基准(FUNSD,SROIE∗,CORD和SciTSR)上显示出与以前的方法相当或更好的性能,而不依赖于视觉特征。
Introduction
提及了阅读顺序的重要性,体现了文档布局的作用。
准确的文档解析在很大程度上取决于文本块的顺序。一旦序列化器确定了一个顺序(例如光栅),文本块的集合就会被转换为文本序列,并通过语言模型如BERT进行处理。
但是将二维空间的文本转换为一维空间的文本序列会导致布局信息的损失。
由于额外的图像信息的加入会增大运算量,所以更希望实用布局这种可以简单的和文本进行结合的布局方式。
通过文本块之间的相对位置来体现文本布局。同时还引入了一种自监督方式叫做“area-masked language model”,它将文本隐藏在文档的某个区域(这里是说随机替换某个区域的文本信息吗?)并监督被屏蔽的文本(学习被屏蔽的文本特征)。
在现实中,KIE具有两个挑战:
一个是对于文本块的顺序依赖,由于在常规的方法中,经过OCR过程之后的序列化过程是固定的,通常采用从上到下从左到右顺序对文本块进行组合,但是通常在实际生活中的文档图像并不规则,这就导致不按照真实顺序对数据进行BIO标注的话效果就会很差。为了规避这个问题,论文采用了SPADE解码器,在没有任何顺序信息的情况下提取关键文本块,和文本块顺序被改变的新基准上对提取进行对比评估。与LayoutLM(Xu等人,2020)和LayoutLMv2(Xu等人,2021)相比,BROS在序列器上显示出更好的鲁棒性。第二个挑战是与了解目标关键内容所需的标注实例数量有关。由于一个KIE的例子由数百个应该被分类的文本块组成,所以标注的成本很高。
BROS在FUNSD的KIE任务上表现更好,而且BROS只用20∼30%的FUNSD例子就比LayoutLM用100%的例子取得更好的性能。
文章的贡献:
- 提出了一种有效的空间布局编码方法,考虑了文本块的相对位置。
- 提出了一种新的区域屏蔽自我监督策略,反映了文本块的二维性质。
- 所提出的模型在不依赖视觉特征的情况下实现了与最先进的性能相媲美。
- 将现有的预训练模型与失去文本块顺序的permuted KIE数据集进行比较。
- 比较了各种预训练模型在数据稀缺情况下的微调效率。比较了在数据稀缺的环境下各种预训练模型的精确性。
BERT Relying on Spatiality (BROS)
BROS的主要结构遵循了LayoutLM,且有两个改进:(1)将文本块之间的空间关系作为空间编码指标;(2)使用了为2D空间中的文本块设计的2D pre-train 预训练目标。
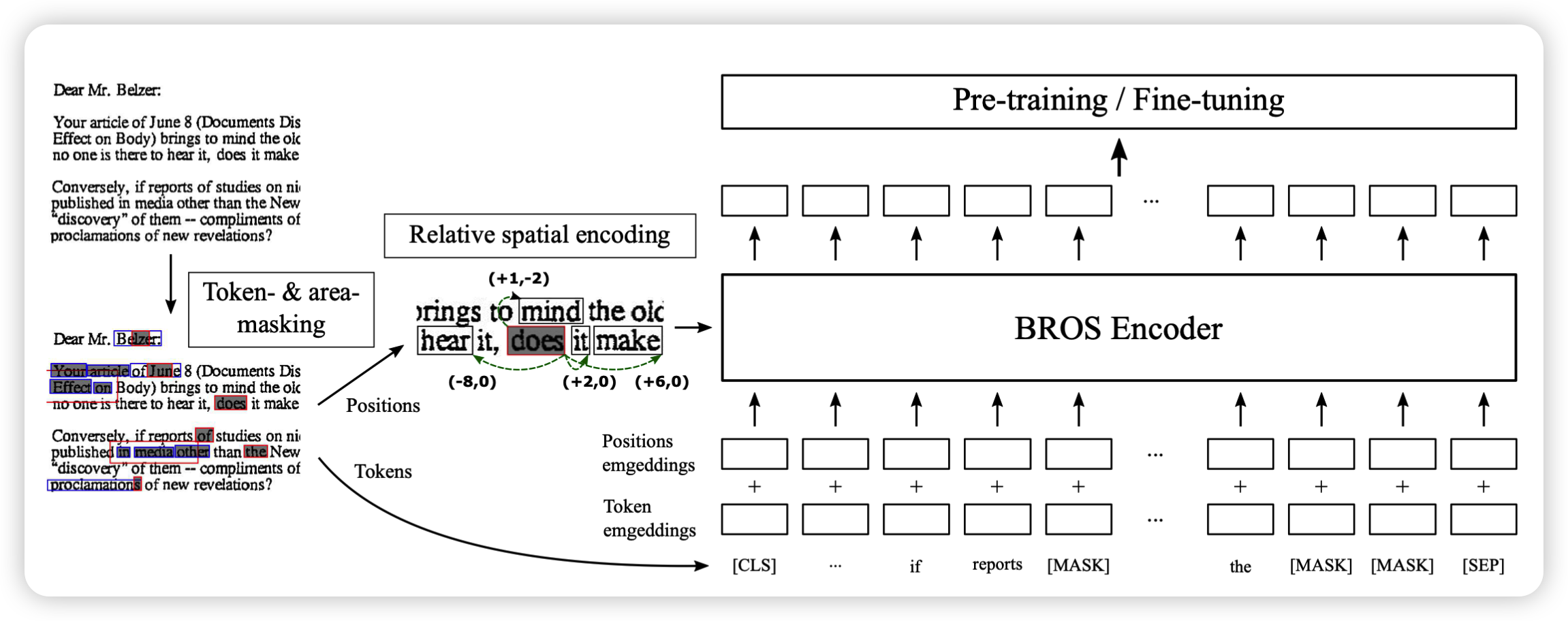
BROS的概述。文档图像中的token通过toekn-masking和 area-masking策略被mask。文本块之间的位置差异被直接编码到Transformer的注意力机制中。输出的标记表征被用于预训练和微调。
对文本块的空间信息编码的方式决定了模型如何理解文本块之间空间关系。BROS采用了文本块之间的相对位置信息来编码空间关系,通过相对位子可以更好的识别具有键值结构的实体。
p = (x, y )来表示二维空间上的一个点。用ptl、ptr、pbr和pbl分别比傲视一个文本块的边界框四个顶点。BROS首先利用图像的大小对文本块的所有二维点进行标准化。然后,BROS会计算不同文本框之间相同位置顶点的相对距离pij。如下图所示

绝对位置和相对位置之间的比较。”Project #”和 "总样本 "的配对值分别为 "72-31 "和 “285”。在(a)中,成对的文本块基于其绝对位置具有不同的模式。另一方面,在(b)中,它们可以持有共模态,以表示它们的语义耦合位置。表示其语义耦合的文本块的位置。
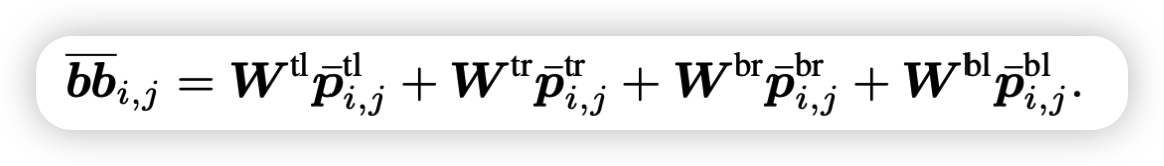
bbi,j表示两个文本块的bbox的相对位置,BROS通过应用线性变换将这四个相对位置结合起来,其中W是线性变换矩阵,H是BERT的隐藏大小,A是自注意力中多头的数量。
在识别相对位置矢量bb的过程中,应用两个部分:正弦函数F,和注意力模块的多个头的共享嵌入。首先,正弦函数可以比使用grid embedding更自然地编码连续距离(这里应该是因为对于同一个区域用grid的话就要被分成多个网格,而正弦函数本身是一个连续的函数所以出来的结果会更好)。其次,Transformer中的多头注意力模块可以共享相同的相对位置嵌入,将文本块之间的共同空间关系强加给由多头识别的多个语义特征(就是说多头注意力在学习不同特征的时候还同时利用上了空间关系,这样可以让布局信息和文本信息结合的更好)。

BROS直接对文本块的上下文空间关系进行编码。它计算了一个结合语义和空间特征的注意力分数。
其中,ti和tj是第i和j个token的上下文表示,Wq和Wh都是第h个多头注意力头的KEY和QUREY的变换矩阵。前者与Transformer中的原始注意力机制相同。后者在给出源语境(token embedding * Wq)和位置(bbij)的情况下考虑目标文本块的相对空间信息(这里就是说文章设计的这个多头注意力机制是由传统的QK的计算方式+将相对位置考虑进相对位置信息与文本语义embedding的关联度)。正如上面提到的,我们在所有不同的注意力头中共享相对空间嵌入,以施加共同的空间关系。
作者将相对嵌入与标记的语义信息结合起来,以便更好地注意力机制在文本和它们的空间关系之间建立联系。在计算两个文本块之间的相对空间信息时,作者计算了每个文本框的4个顶点的相对位置。通过这样做,编码不仅可以纳入相对距离,还可以纳入相对形状和大小,这在区分文档中的关键和价值方面起着重要作用。
Area-masked Language Model
BROS的预训练目标之一:是BERT中使用的token-masking的LM(TMLM),另一个是本文介绍的新型area-masking的LM(AMLM)。其中area-masking是根据文档中的一个二维区域来捕捉连续的文本块。
TMLM在保留token的空间信息的同时会随机遮蔽token,然后该模型以空间信息和其他未遮蔽的token为线索预测被遮蔽的token(这个token-masking的过程和BERT还有LayoutLM是的Masked Visual-Language Model是一样的)。由于文本块中的token可以被部分屏蔽,它们的估计可以通过参考同一文本块中的其他token或被屏蔽标记附近的文本块来进行。
AMLM是在一个随机选择的区域内对所有文本块进行屏蔽,步骤如下:(1)随机选择一个文本块,(2)通过扩大文本块的区域来确定一个区域,(3)确定分配在该区域的文本块,(4)遮蔽文本块的所有token并预测它们。
在第(2)步中,通过从具有超参数λ的指数分布中取样确定扩展程度。使用指数分布的理由是SpanBERT中用于将离散域的几何分布转换成连续域的分布的方法。因此,设定λ=-ln(1-p),其中SpanBERT中使用的p=0.2。此外,我们用1来截断指数分布,以防止一个不完整的值覆盖文件的所有空间(这里的意思应该是防止覆盖区域内有不完整的单词出现)。应该注意的是,mask区域是从随机选择的文本块中扩展出来的,因为该区域应该与文本的大小和位置有关,以代表二维空间中的文本跨度。因为AMLM将空间上接近的token隐藏在一起,它们的估计需要更多来自远离估计目标的文本块的线索(这里的意思应该是想要预测他们,就需要有更多他们周边的文本块信息才行,不能只看被mask周边的文本信息)。

两种掩蔽策略的图示:1)随机token选择(红色)和标记屏蔽(灰色);2)随机区域选择(红色)和区块屏蔽(灰色)。蓝色的 框代表包括被遮蔽token的文本块。在这两个图中,都有15%的标记被屏蔽
Key Information Extraction Tasks
论文解决了两类KIE任务:实力提取(EE),和实体链接(EL)。EE任务是识别代表所需目标文本的文本块序列;(a)中举例EE任务:识别出标题、问题、和答案的实体。EL任务则是通过关键实体的层次或语义关系将它们连接起来。(b)是EL任务的一个例子:对菜单实体进行分组,如名称、单价、金额和价格。如下图所示: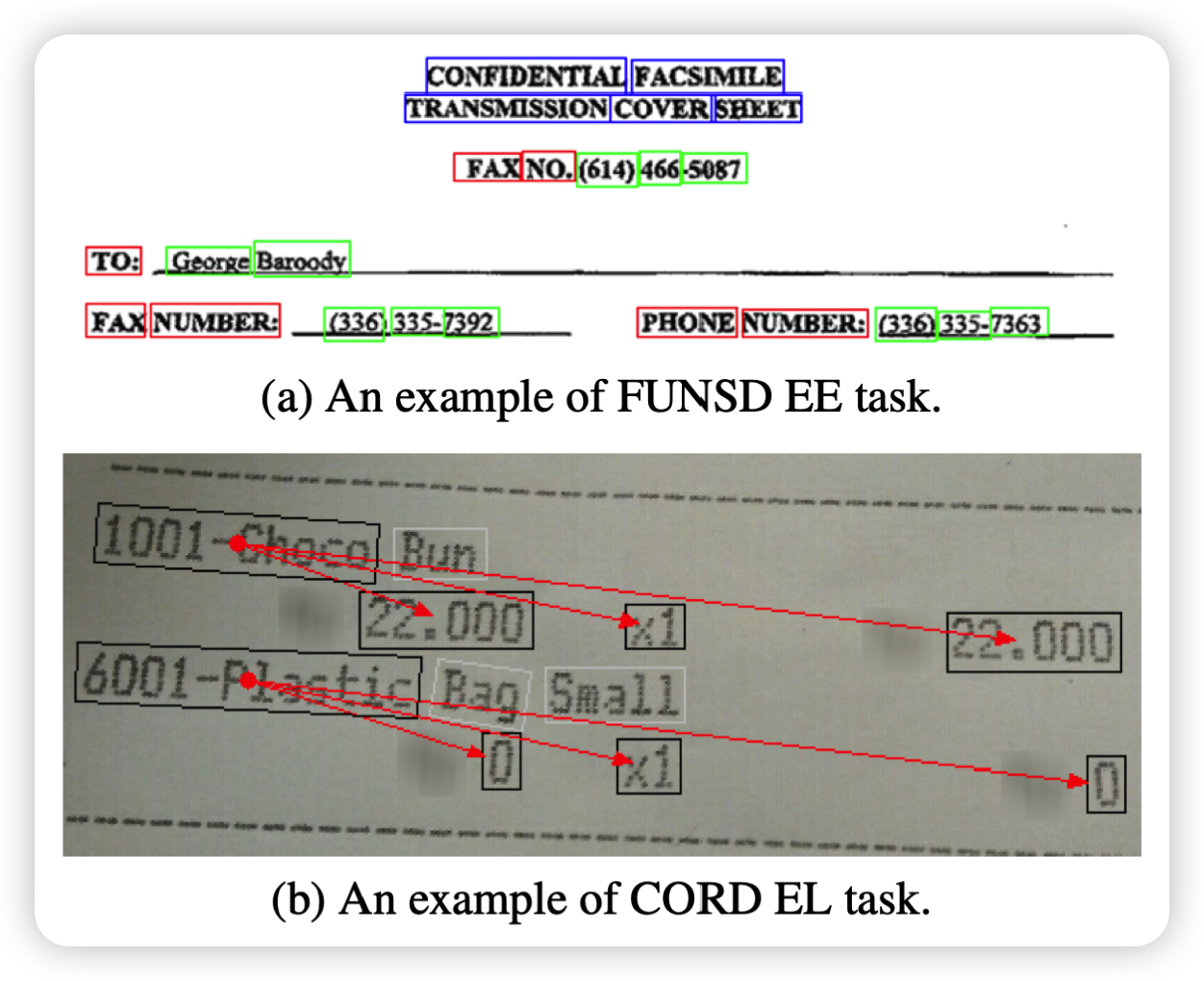
相关知识
Token-masking和area-masking策略
Token-masking和area-masking策略是自然语言处理任务中使用的技术,例如语言建模或文本分类,其中某些句子或文档的特定部分被选择性地隐藏或“掩盖”,以便进行训练或评估。
Token-masking是一种策略,在该策略中,句子或文档中的某些单词会被随机替换为特殊标记,例如“[MASK]”或“[UNK]”。通常这样做是为了防止模型过分依赖特定的单词或短语,强制它更仔细地考虑上下文。例如,在语言建模任务中,输入文本中的一定比例的标记可以被掩盖,然后模型需要根据周围的上下文来预测掩盖的标记。
- Token-masking示例: 假设我们正在使用语言建模任务,我们有以下句子: “今天是[MASK]月[MASK]日,天气[MASK]。” 在此示例中,我们可以随机选择将第一个和第三个标记掩盖,以得到以下输入文本: “今天是 [MASK] 月 [MASK] 日,天气 [MASK]。” 模型现在需要使用其周围的上下文来预测掩盖的标记的正确单词。
另一方面,area-masking涉及隐藏输入文本的整个区域,而不仅仅是单个标记。这对于模型需要处理更长的文本片段的任务非常有用,例如文档分类或情感分析。通过有选择地掩盖输入的某些区域,模型可以专注于其他更相关的区域以完成任务。
- 假设我们正在进行文本分类任务,我们有一篇长篇文章,其中许多段落都与任务无关。我们可以选择将这些无关段落的区域掩盖,只保留与任务相关的段落。模型现在只需专注于任务相关的段落,并忽略其他部分的干扰,以便更好地完成任务。
Semantically Coupled 语义耦合
“Semantically Coupled” 意味着两个或多个单词、短语或句子的意义是密切相关的。这意味着这些元素的意思不能独立地理解,而是需要考虑它们之间的关联。
例如,“红色汽车” 中的 “红色” 和 “汽车” 是语义上耦合的,因为这两个单词在一起传达了一种特定的含义,即指一种特定颜色的车辆。同样,“我要吃饭” 中的 “我要” 和 “吃饭” 也是语义上耦合的,因为它们一起传达了一个特定的含义,即表达了一种食物需求。
实体链接
实体链接(Entity Linking,简称EL),实体链接任务的输入是一段文本,输出是将文本中出现的实体链接到知识库中的对应实体。实体通常是指具有独立身份的对象,如人、组织、地点、事件等。知识库是指存储结构化知识的数据库,如维基百科、Freebase、YAGO等。实体链接任务的核心是将文本中的实体与知识库中的实体进行对应。为了实现这个目标,通常需要进行如下步骤:
- 实体识别:识别文本中出现的实体,如人名、地名、组织名等。
- 候选实体生成:从知识库中生成可能匹配文本实体的候选实体集合。
- 实体消歧:从候选实体集合中确定文本实体对应的实体。
- 实体链接:将文本中的实体链接到确定的知识库实体上。
以下是一个例子来说明实体链接任务的应用场景:
文本:明天北京天气怎么样?
对于这段文本,实体链接任务的目标是将文本中的实体“北京”链接到对应的知识库实体上。假设我们使用维基百科作为知识库,那么实体链接任务的具体步骤如下:
- 实体识别:识别文本中出现的实体,这里是“北京”。
- 候选实体生成:从维基百科中生成可能匹配“北京”实体的候选实体集合。这个步骤可以通过使用信息检索技术和实体链接相关的算法来完成。在这里,我们可以从维基百科中找到“北京市”、“北京”等多个候选实体。
- 实体消歧:从候选实体集合中确定文本实体对应的实体。这个步骤可以通过使用实体消歧算法来完成,算法会综合考虑实体在文本中的上下文信息、知识库中实体的属性特征、实体之间的关系等多个因素来判断候选实体的准确性。在这里,我们可以通过分析文本上下文信息和知识库实体的属性特征,最终确定“北京”实体对应的是“北京市”这个知识库实体。
- 实体链接:将文本中的实体“北京”链接到确定的知识库实体“北京市”上。
同一实体在不同文本中可能会有不同的表达方式,如“IBM”、“International Business Machines”等。为了在不同文本中准确识别同一实体,需要进行实体链接,将文本中的实体与知识库中的实体进行对应。















 1500
1500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









