







 超级会员免费看
超级会员免费看
Motivation
1,上述研究没有考虑到图像区域和单词层面的潜在视觉语言对应。
2,我们将赋予不同权重的图像区域和单词作为推断图像-文本相似性的上下文。
Framework

- 首先,我们先考虑对整个句子施加注意力让整个句子去表示每个单独的区域,我们首先计算所有可能对的余弦相似矩阵:
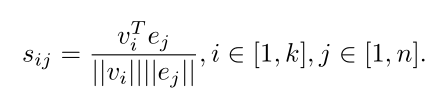
sij表示第i个区域与第j个单词的相似性。
我们根据经验发现,将相似性限制在零是有益的,并且我们将相似矩阵归一化: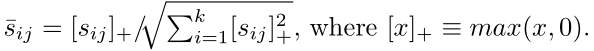
- 为了在每个图像区域上关注单词,我们定义一个单词表示的加权组合(即关于第i个图像区域的句子向量)
<

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 4813
4813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









