






 本文详细介绍了禁忌搜索算法,包括其基本原理、特点,如避免局部最优、记忆功能和灵活性,以及如何通过改进初始解、并行化和多样性的考虑来提升性能。还给出了一个MATLAB仿真实例,展示了禁忌搜索求解函数极值的问题过程。
本文详细介绍了禁忌搜索算法,包括其基本原理、特点,如避免局部最优、记忆功能和灵活性,以及如何通过改进初始解、并行化和多样性的考虑来提升性能。还给出了一个MATLAB仿真实例,展示了禁忌搜索求解函数极值的问题过程。
一、算法理论
禁忌搜索是著名的启发式搜索算法。所谓禁忌,就是禁止重复前面的操作。为了改进局部邻域搜索容易陷入局部最优点的不足,禁忌搜索算法引入一个禁忌表,记录下已经搜索过的局部最优点,在下一次搜索中,对禁忌表中的信息不再搜索或有选择地搜索,以此来跳出局部最优点,从而最终实现全局优化。禁忌搜索算法是对局部邻域搜索的一种扩展,是一种全局邻域搜索、逐步寻优的算法。另外,为了尽可能不错过产生最优解的“移动”,禁忌搜索还采用“特赦准则”的策略。
二、禁忌搜索算法的特点
邻域函数沿用局部邻域搜索的思想,用于实现邻域搜索;禁忌表和禁忌对象的设置,体现了算法避免迂回搜索的特点;藐视准则,则是对优良状态的奖励,它是对禁忌策略的一种放松。
(1)禁忌搜索算法的新解不是在当前解的邻域中随机产生,它要么是优于“best so far”的解,要么是非禁忌的最佳解,因此选取优良解的概率远远大于其他劣质解的概率。
(2)由于禁忌搜索算法具有灵活的记忆功能和藐视准则,并且在搜索过程中可以接受劣质解,所以具有较强的“爬山”能力,搜索时能够跳出局部最优解,转向解空间的其他区域,从而增大获得更好的全局最优解的概率。因此,禁忌搜索算法是一种局部搜索能力很强的全局迭代寻优算法。
三、禁忌搜索的改进方向
(1)对初始解有较强的依赖性,好的初始解可使禁忌搜索算法在解空间中搜索到好的解,而较差的初始解则会降低禁忌搜索的收敛速度。因此可以与遗传算法、模拟退火算法等优化算法结合,先产生较好的初始解,再用禁忌搜索算法进行搜索优化。
(2)迭代搜索过程是串行的,仅是单一状态的移动,而非并行搜索。为了进一步改善禁忌搜索的性能,一方面可以对禁忌搜索算法本身的操作和参数选取进行改进,对算法的初始化、参数设置等方面实施并行策略,得到各种不同类型的并行禁忌搜索算法;另一方面则可以与遗传算法、神经网络算法以及基于问题信息的局部搜索相结合。
(3)在集中性与多样性搜索并重的情况下,多样性不足。集中性搜索策略用于加强对当前搜索的优良解的邻域做进一步更为充分的搜索,以期找到全局最优解。多样性搜索策略则用于拓宽搜索区域,尤其是未知区域,当搜索陷入局部最优时,多样性搜索可改变搜索方向,跳出局部最优,从而实现全局最优。增加多样性策略的简单处理手段是对算法的重新随机初始化,或者根据频率信息对一些已知对象进行惩罚。
四、关键参数说明
| 关键参数 | 设置 | 原因 |
| 初始解 | 随机给出初始解,也可以事先使用其他启发式算法等给出一个较好的初始解。 | 由于禁忌搜索算法主要是基于邻域搜索的,初始解的好坏对搜索的性能影响很大。 |
| 适配值函数 | 禁忌搜索的适配值函数用于对搜索进行评价,进而结合禁忌准则和特赦准则来选取新的当前状态。目标函数值和它的任何变形都可以作为适配值函数。适配值函数的选择主要考虑提高算法的效率、便于搜索的进行等因素。 | |
| 邻域结构 | 所谓邻域结构,是指从一个解(当前解)通过“移动”产生另一个解(新解)的途径,它是保证搜索产生优良解和影响算法搜索速度的重要因素之一。邻域结构的设计通常与问题相关。邻域结构的设计方法很多,对不同的问题应采用不同的设计方法,常用设计方法包括互换、插值、逆序等。不同的“移动”方式将导致邻域解个数及其变化情况的不同,对搜索质量和效率有一定影响。通过移动,目标函数值将产生变化,移动前后的目标函数值之差,称之为移动值。如果移动值是非负的,则称此移动为改进移动;否则,称之为非改进移动。最好的移动不一定是改进移动,也可能是非改进移动,这一点能保证在搜索陷入局部最优时,禁忌搜索算法能自动把它跳出局部最优。 | |
| 禁忌对象 | 禁忌对象,就是被置入禁忌表中的那些变化元素。禁忌的目的则是为了尽量避免迂回搜索而多搜索一些解空间中的其他地方。归纳而言,禁忌对象通常可选取状态本身或状态分量等。 | |
| 候选解选择 | 候选解通常在当前状态的邻域中择优选取,若选取过多将造成较大的计算量,而选取较少则容易“早熟”收敛,但要做到整个邻域的择优往往需要大量的计算=算,因此可以确定性地或随机性地在部分邻域中选取候选解,具体数据大小则可视问题特征和对算法的要求而定。 | |
| 禁忌表 | 不允许恢复(即被禁止)的性质称作禁忌(Tabu)。禁忌表的主要目的是阻止搜索过程中出现循环和避免陷入局部最优,它通常记录前若干次的移动,禁止这些移动在近期内返回。在迭代固定次数后,禁忌表释放这些移动,重新参加运算,因此它是一个循环表,每迭代一次,就将最近的一次移动放在禁忌表的末端,而它的最早的一个移动就从禁忌表中释放出来。从数据结构上讲,禁忌表是具有一定长度的先进先出的队列。禁忌搜索算法使用禁忌表禁止搜索曾经访问过的解,从而禁止搜索中的局部循环。禁忌表可以使用两种记忆方式:明晰记忆和属性记忆。明晰记忆是指禁忌表中的元素是一个完整的解,消耗较多的内存和时间;属性记忆是指禁忌表中的元素记录当前解移动的信息,如当前解移动的方向等。 | |
| 禁忌长度 | 所谓禁忌长度,是指禁忌对象在不考虑特赦准则的情况下不允许被选取的最大次数。通俗地讲,禁忌长度可视为禁忌对象在禁忌表中的任期。禁忌对象只有当其任期为0时才能被解禁。在算法的设计和构造过程中,一般要求计算量和存储量尽量小,这就要求禁忌长度尽量小。但是,禁忌长度过小将造成搜索的循环。禁忌长度的选取与问题特征相关,它在很大程度上决定了算法的计算复杂性。一方面,禁忌长度可以是一个固定常数(如 t=c,c为一常数),或者固定为与问题规模相关的一个量(如t= ,n为问题维数或规模),如此实现起来方便、简单,也很有效;另一方面,禁忌长度也可以是动态变化的,如根据搜索性能和问题特征设定禁忌长度的变化区间,而禁忌长度则可按某种规则或公式在这个区间内变化。 | |
| 藐视准则 | 在禁忌搜索算法中,可能会出现候选解全部被禁忌,或者存在一个优于“best so far”状态的禁忌候选解,此时特赦准则将某些状态解禁,以实现更高效的优化性能。特赦准则的常用方式有:(1)基于适配值的原则:某个禁忌候选解的适配值优于“bestso far”状态,则解禁此候选解为当前状态和新的“best so far”状态。 (2)基于搜索方向的准则;若禁忌对象上次被禁忌时使得适配值有所改善,并且目前该禁忌对象对应的候选解的适配值优于当前解,则对该禁忌对象解禁。 | |
| 搜索策略 | 集中性搜索策略、多样性搜索策略 | 集中性搜索策略用于加强对优良解的邻域的进一步搜索。其简单的处理手段可以是在一定步数的迭代后基于最佳状态重新进行初始化,并对其邻域进行再次搜索。在大多数情况下,重新初始化后的邻域空间与上一次的邻域空间是不一样的,当然也就有一部分邻域空间可能是重叠的。多样性搜索策略则用于拓宽搜索区域,尤其是未知区域。其简单的处理手段可以是对算法的重新随机初始化,或者根据频率信息对一些已知对象进行惩罚。 |
| 终止准则 | 严格理论意义上的收敛条件,即在禁忌长度充分大的条件下实现状态空间的遍历,这显然是不可能实现的。因此,在实际设计算法时通常采用近似的收敛准则。常用的方法有: (1)给定最大迭代步数。当禁忌搜索算法运行到指定的迭代步数之后,则终止搜索。 (2)设定某个对象的最大禁忌频率。若某个状态、适配值或对换等对象的禁忌频率超过某一阈值,或最佳适配值连续若干步保持不变,则终止算法。 (3)设定适配值的偏离阈值。首先估计问题的下界,一旦算法中最佳适配值与下界的偏离值小于某规定阈值,则终止搜索。 |
五、算法流程
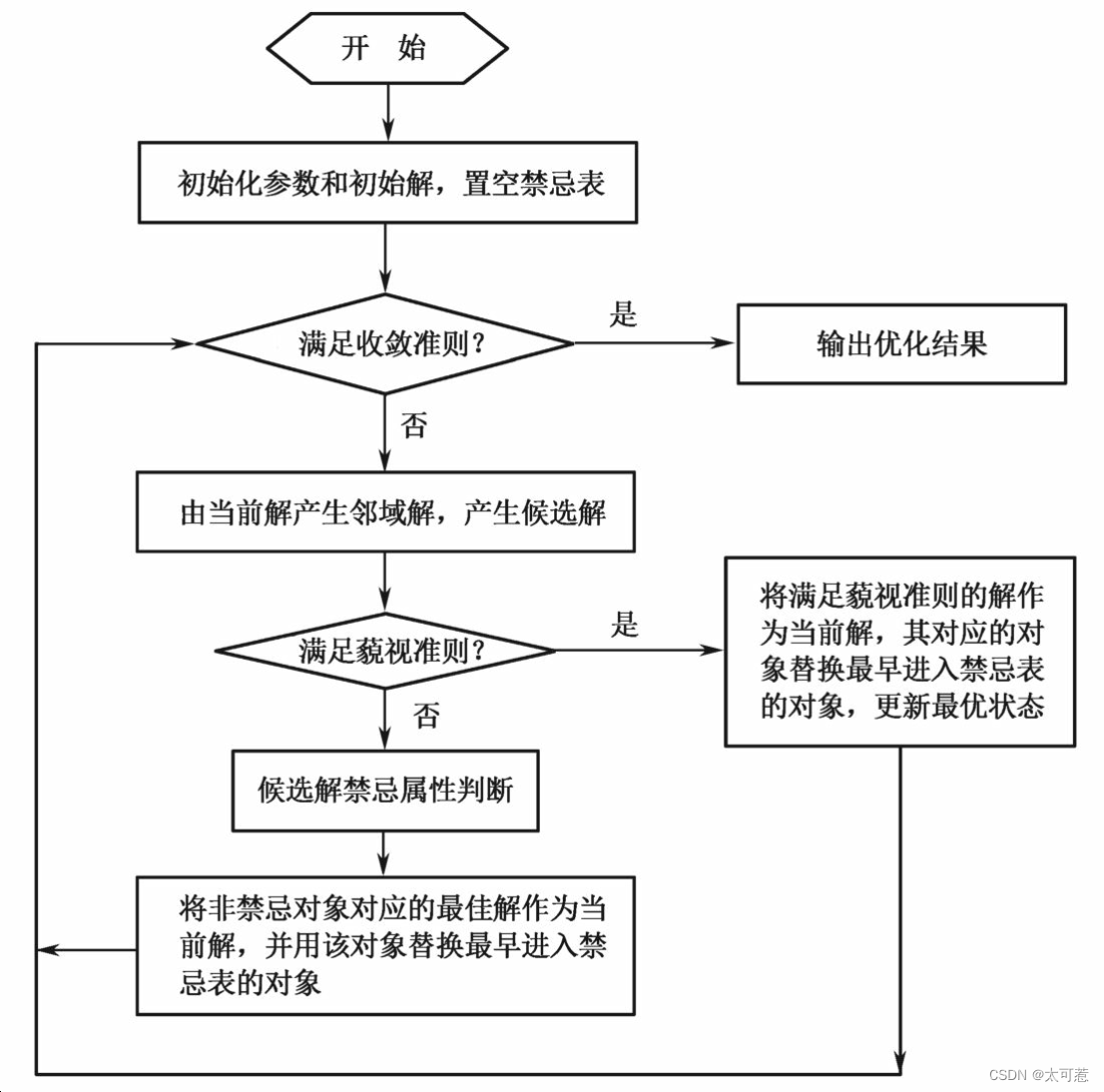
简单禁忌搜索算法的基本思想是:给定一个当前解(初始解)和一种邻域,然后在当前解的邻域中确定若干候选解;若最佳候选解对应的目标值优于“best so far”状态,则忽视其禁忌特性,用它替代当前解和“best so far”状态,并将相应的对象加入禁忌表,同时修改禁忌表中各对象的任期;若不存在上述候选解,则在候选解中选择非禁忌的最佳状态为新的当前解,而无视它与当前解的优劣,同时将相应的对象加入禁忌表,并修改禁忌表中各对象的任期。如此重复上述迭代搜索过程,直至满足停止准则。其算法步骤可描述如下:
(1)给定禁忌搜索算法参数,随机产生初始解x,置禁忌表为空。
(2)判断算法终止条件是否满足:若是,则结束算法并输出优化结果;否则,继续以下步骤。
(3)利用当前解的邻域函数产生其所有(或若干)邻域解,并从中确定若干候选解。
(4)对候选解判断藐视准则是否满足:若满足,则用满足藐视准则的最佳状态y替代x成为新的当前解,即x=y,并用与y对应的禁忌对象替换最早进入禁忌表的禁忌对象,同时用y替换“best so far”状态,然后转步骤(6);否则,继续以下步骤。
(5)判断候选解对应的各对象的禁忌属性,选择候选解集中非禁忌对象对应的最佳状态为新的当前解,同时用与之对应的禁忌对象替换最早进入禁忌表的禁忌对象。
(6)判断算法终止条件是否满足:若是,则结束算法并输出优化结果;否则,转步骤(3)。
六、MATLAB仿真实例

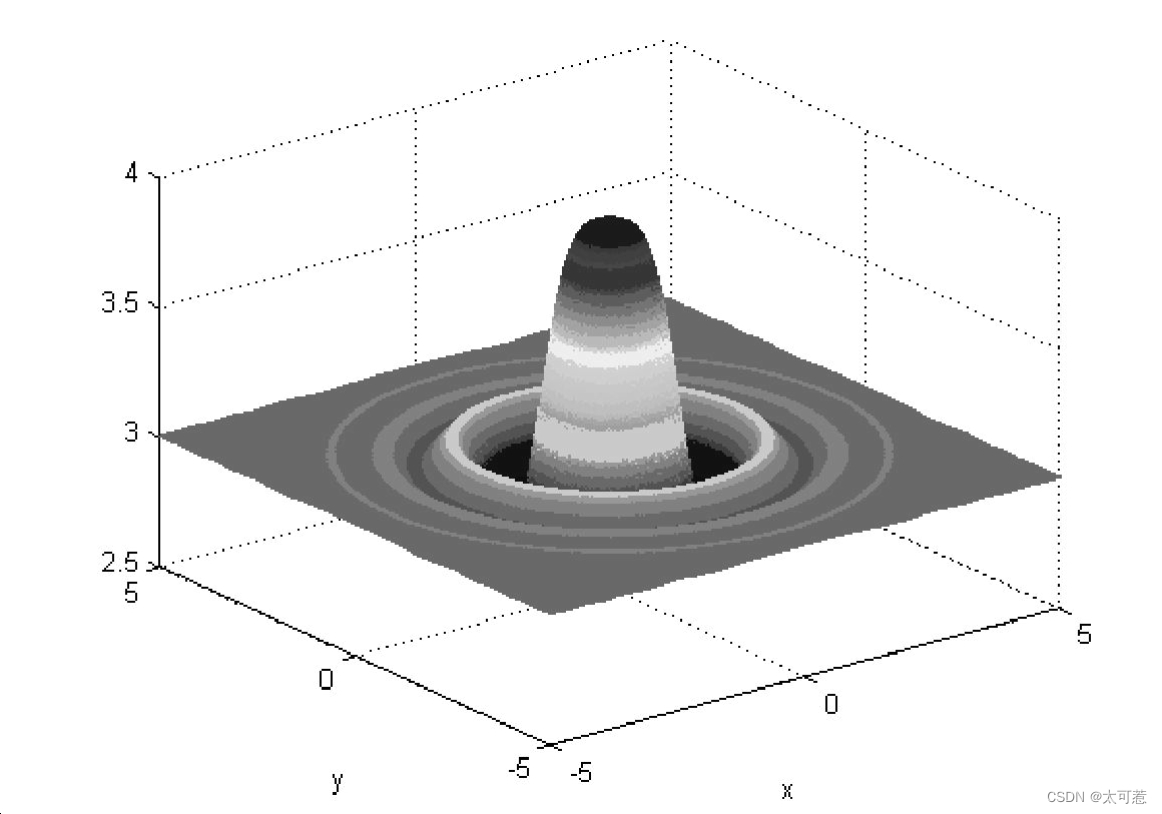


%%%%%%f(x,y)=(cos(x^2+y^2)-0.1)/(1+0.3*(x^2+y^2)^2)+3%%%%%%
clear all; %清除所有变量
close all; %清图
clc; %清屏
x=-5:0.01:5;
y=-5:0.01:5;
N=size(x,2);
for i=1:N
for j=1:N
z(i,j)=(cos(x(i)^2+y(j)^2)-0.1)/(1+0.3*(x(i)^2+y(j)^2)^2)+3;
end
end
mesh(x,y,z)
xlabel('x')
ylabel('y')%%%%%%%%%%%%%%%%%%%%%%%%%%%%适配值函数%%%%%%%%%%%%%%%%%%%%%%%%
function y=func2(x)
y=(cos(x(1)^2+x(2)^2)-0.1)/(1+0.3*(x(1)^2+x(2)^2)^2)+3;
%%%%%%%%%%%%%%%%禁忌搜索算法求函数极值问题%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%初始化%%%%%%%%%%%%%%%%%%%%%%%%%%%
clear all; %清除所有变量
close all; %清图
clc; %清屏
xu=5; %上界
xl=-5; %下界
L=randint(1,[5 11]); %禁忌长度取5,11之间的随机数
Ca=5; %邻域解个数
Gmax=200; %禁忌算法的最大迭代次数;
w=1; %自适应权重系数
tabu=[]; %禁忌表
x0=rand(1,2)*(xu-xl)+xl; %随机产生初始解
bestsofar.key=x0; %最优解
xnow(1).key=x0; %当前解
%%%%%%%%%%%%%%%%最优解函数值,当前解函数值%%%%%%%%%%%%%%%%%
bestsofar.value=func2(bestsofar.key);
xnow(1).value=func2(xnow(1).key);
g=1;
while g<Gmax
x_near=[]; %邻域解
w=w*0.998;
for i=1:Ca
%%%%%%%%%%%%%%%%%%%%%产生邻域解%%%%%%%%%%%%%%%%%%%%
x_temp=xnow(g).key;
x1=x_temp(1);
x2=x_temp(2);
x_near(i,1)=x1+(2*rand-1)*w*(xu-xl);
%%%%%%%%%%%%%%%%%边界条件处理%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%边界吸收%%%%%%%%%%%%%%%%%%%%%
if x_near(i,1)<xl
x_near(i,1)=xl;
end
if x_near(i,1)>xu
x_near(i,1)=xu;
end
x_near(i,2)=x2+(2*rand-1)*w*(xu-xl);
%%%%%%%%%%%%%%%%%边界条件处理%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%边界吸收%%%%%%%%%%%%%%%%%%%%%
if x_near(i,2)<xl
x_near(i,2)=xl;
end
if x_near(i,2)>xu
x_near(i,2)=xu;
end
%%%%%%%%%%%%%%计算邻域解点的函数值%%%%%%%%%%%%%%%%%%%
fitvalue_near(i)=func2(x_near(i,:));
end
%%%%%%%%%%%%%%%%%%%%最优邻域解为候选解%%%%%%%%%%%%%%%%%%%
temp=find(fitvalue_near==max(fitvalue_near));
candidate(g).key=x_near(temp,:);
candidate(g).value=func2(candidate(g).key);
%%%%%%%%%%%%%%候选解和当前解的评价函数差%%%%%%%%%%%%%%%%%%
delta1=candidate(g).value-xnow(g).value;
%%%%%%%%%%%%%%候选解和目前最优解的评价函数差%%%%%%%%%%%%%%%
delta2=candidate(g).value-bestsofar.value;
%%%%%候选解并没有改进解,把候选解赋给下一次迭代的当前解%%%%%%
if delta1<=0
xnow(g+1).key=candidate(g).key;
xnow(g+1).value=func2(xnow(g).key);
%%%%%%%%%%%%%%%%%%%%%更新禁忌表%%%%%%%%%%%%%%%%%%%%%%%
tabu=[tabu;xnow(g+1).key];
if size(tabu,1)>L
tabu(1,:)=[];
end
g=g+1; %更新禁忌表后,迭代次数自增1
%%%%%%%如果相对于当前解有改进,则应与目前最优解比较%%%%%%%%%%
else
if delta2>0 %候选解比目前最优解优
%%%%%%%%%%把改进解赋给下一次迭代的当前解%%%%%%%%%%%%
xnow(g+1).key=candidate(g).key;
xnow(g+1).value=func2(xnow(g+1).key);
%%%%%%%%%%%%%%%%%%%%更新禁忌表%%%%%%%%%%%%%%%%%%%%%
tabu=[tabu;xnow(g+1).key];
if size(tabu,1)>L
tabu(1,:)=[];
end
%%%%%%%%把改进解赋给下一次迭代的目前最优解%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%包含藐视准则%%%%%%%%%%%%%%%%%%%%%%%
bestsofar.key=candidate(g).key;
bestsofar.value=func2(bestsofar.key);
g=g+1; %更新禁忌表后,迭代次数自增1
else
%%%%%%%%%%%%%%%判断改进解时候在禁忌表里%%%%%%%%%%%%%%%
[M,N]=size(tabu);
r=0;
for m=1:M
if candidate(g).key(1)==tabu(m,1)...
& candidate(g).key(2) == tabu(m,1)
r=1;
end
end
if r==0
%%改进解不在禁忌表里,把改进解赋给下一次迭代的当前解
xnow(g+1).key=candidate(g).key;
xnow(g+1).value=func2(xnow(g+1).key);
%%%%%%%%%%%%%%%%%%%%%更新禁忌表%%%%%%%%%%%%%%%%%%
tabu=[tabu;xnow(g).key];
if size(tabu,1)>L
tabu(1,:)=[];
end
g=g+1; %更新禁忌表后,迭代次数自增1
else
%%%如果改进解在禁忌表里,用当前解重新产生邻域解%%%%%
xnow(g).key=xnow(g).key;
xnow(g).value=func2(xnow(g).key);
end
end
end
trace(g)=func2(bestsofar.key);
end
bestsofar; %最优变量及最优值
figure
plot(trace);
xlabel('迭代次数')
ylabel('目标函数值')
title('搜索过程最优值曲线')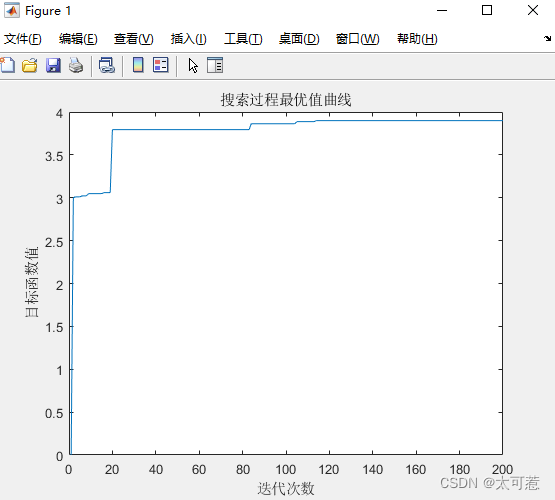
源自《智能优化算法及其MATLAB实例(第2版)》

















 3838
3838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









