






Intelligent Reference Curation for Visual Place Recognition via Bayesian Selective Fusion
基于贝叶斯选择融合的视觉场景识别智能参考策展 论文注解
摘要:
视觉场景识别(VPR)的一个关键挑战就是,尽管由于时间、季节、天气或光照条件等因素导致的视觉外观的急剧变化,仍能识别出场景。许多基于深入学习的图像描述子、序列匹配、域翻译和概率定位的方法成功地解决了这一挑战,但大多数方法都依赖于精心策划的可能地点的代表性参考图像的可用性。 在本文中,我们提出了一种新
的方法,称为贝叶斯选择性融合,用于主动选择和融合信息丰富的参考图像,以确定给定查询图像的最佳位置匹配。该方法的选择性元素避免了对每一幅参考图像进行反效果的融合,并允许在视觉条件不断变化的环境中动态选择信息丰富的参考图像(比如在灯光闪烁的室内、在阳光下或昼夜交替的室外)。我们方法的概率元素提供了一种融合多个参考图像的方法,该方法通过一种新的VPR无训练似然函数来解释其变化的不确定性。对于来自两个基准数据集的难以查询的图像,我们证明了我们的方法匹配并超过了几种可选融合方法的性能,以及具有最佳参考图像的先验(不公平)知识的最先进的技术。我们的方法非常适合于长期的机器人自主,因为动态视觉环境是常见的,因为它无需训练,描述符不可知,并补充了现有的技术,如序列匹配。
关键词: 定位,概率估计,识别,自动驾驶导航
PART1:介绍
视觉位置识别(VPR)是确定给定查询图像捕获位置的问题,是移动机器人定位的关键实现技术。绝大多数VPR方法都涉及到将查询图像与之前在环境[1]的地图或数据库中的每个候选位置捕获的参考图像进行比较。因此,在过去几十年的VPR研究中,[1]探索了包括深度学习图像描述符[2]-[4]、序列匹配[5]-[7]和多进程融合[8]在内的鲁棒图像比较技术。
 。
。
VPR中对代表性位置图像的需求也导致了诸如投票[9]、经验映射[10]、[11]、内存压缩[12]和域转换[13]等技术的发展,以管理参考图像。这些方法大多数是基于学习的,并确定参考图像在训练期间的效用,以选择存储或学习。然而,在训练过程中,确定参考图像的实用性具有内在的挑战性,因为它最终取决于影响查询时间地点外观相似性的因素。令人惊讶的是,自从深度学习的VPR图像描述符(如[2],[7],[14]-[17])的兴起以来,很少有方法寻求解决这一挑战。
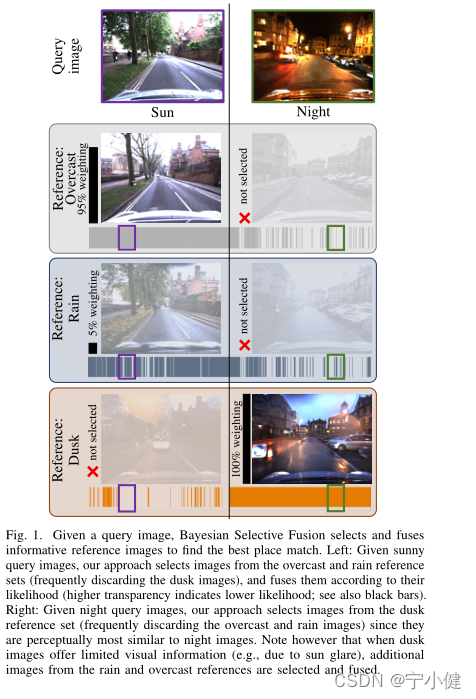
最近,[18]在具有挑战性的VPR场景中使用事件摄像机实现了最先进的性能,使用深度学习图像描述符的无训练融合方法。虽然达到了最先进的性能,但[18]方法在给定的位置融合了所有的参考图像。这种完全的融合可能是不必要的,甚至会适得其反,特别是在动态视觉环境中,查询图像可能来自截然不同的条件——例如,在灯光闪烁的室内,或在云和雨遮挡阳光的室外。在本文中,我们提出了一种新的方法来智能融合信息丰富的参考图像,以避免不必要或适得其反的融合。
本文的主要贡献有:
1)提出了一种新的基于贝叶斯选择性融合的单图像VPR方法,该方法能够智能地选择信息丰富的参考图像,并利用贝叶斯数据融合对参考图像进行融合。
2)一种新的无需训练的概率VPR的可能性,它对潜在的描述符是不可知的。
3)将我们的方法的最先进的性能与最先进的[18]方法和一套其他融合和非融合方法进行比较。
我们的方法补充了现有的VPR技术(例如序列匹配),提供了一种动态的、无需训练的、描述符不可知的和概率的方法,可以从多个(同一位置)参考图像中挖掘信息。本文的结构如下:第二部分介绍相关工作;第三节描述了我们提出的贝叶斯选择融合方法;第四部分报告了我们的实验设置;第五节给出了实验结果;第六节总结并对今后的工作提出建议。
PART2:相关工作
我们首先回顾了VPR的概率方法和位置匹配前适应图像视觉条件的方法。然后,我们将概述以前的方法如何融合多组参考图像。
A. 概率和图像自适应方法
可以证明,场景识别的最著名的概率方法是FAB-MAP[19]。FAB-MAP的主要创新之一是明确地解释感知混叠,这样高度相似但不明确的观测结果收到的是同一地点的低概率;一个词袋观察的生成模型实现了这一点。对FAB-MAP进行了多种扩展,包括里程计信息和图像序列[20],[21]的合并。
虽然FAB-MAP依赖于局部图像特征,但Lowry等人[22]提出了全图像描述符的概率模型,在感知变化较大的环境中具有更强的鲁棒性。Ramos et al.[23]提出了一个用于地点识别的贝叶斯框架,该框架利用每个地点的5-9个训练图像,然后可以从以前看不见的视角识别一个地点。最近,Oyebode等人[24]提出了一个贝叶斯框架,该框架利用预先训练的物体检测器纯粹基于物体类别来识别室内场所,这与视觉场所分类[25]的概念有关,即预测一个场所的语义类别。
Dubios等人[26]利用贝叶斯滤波对序列图像之间的依赖性进行建模。类似的概率时间序列建模也在[6]和[27]中进行了研究,使用了基于蒙特卡罗的算法,该算法在多个数据集上实现了最先进的性能。与这些使用序列来临时融合位置信息的方法不同,我们的VPR方法对单个查询图像进行操作,并融合多个参考图像。
我们的工作也与预处理查询图像以匹配参考图像条件的方法有关(反之亦然)。例如,Pepperell等人的[28]和最近的领域翻译方法(cf.[13])通过天空移除或夜间图像翻译将查询图像转换为与参考图像相同的视觉条件(也参见[29],[1,第VII-A节]和其中的参考文献)。然而,这些方法仍然提出了一个问题:对于给定的查询图像,哪些参考图像和翻译是最好的。例如,夜间转换隐含地假设查询图像是在夜间捕获的,这是不必要的,并且会降低白天查询图像的性能。
B.参考图像融合
Kosecka et al.[9]用一组具有代表性的观点描述室内场所,然后使用最大投票方案找到最可能的参考图像。Carlevaris-Bianco和Eustice[30]通过学习代表性观点之间的时间可观性关系,提出了对该方法的扩展。类似地,Johns和Yang[31]的方法学习特征共现统计,这样每个地方都使用一组共现特征来描述。这使得在一天中不同时间拍摄的图像能够进行可靠的匹配。
当机器人长时间运行时,通常会随着时间的推移更新环境模型。Biber和Duckett同时使用多个时间尺度来表示环境,因此旧的记忆褪色的速度取决于[32]所使用的特定时间尺度。对于每个地方,都选择具有最高对数似然的时间尺度。机器人导航中一个更复杂的方法是在长期记忆中只存储持久配置,这样动态对象就不会成为地图[33]的一部分。另一种方法是使用核心集[12]来大幅压缩表示某个位置的图像。这些核心集随后被用于在实时[34]中检测环路闭包。
使用所谓的体验地图[10]已经取得了令人印象深刻的结果。在同一个地方积累的多种体验,允许适应由于光线、天气条件和结构变化而改变的外观。在定位时间,机器人可以使用概率框架预测最合适的经验。选择最合适的经验结果,不仅减少了计算时间,而且大大降低了失败率。Doan等人采用了类似的方法。[11]可以在相同的位置积累额外的经验,同时避免了计算和存储的无限增长。Vysotska和Stachniss[7]匹配数据关联图中的位置,该关联图可以包含多个引用遍历的图像。
对包含多种环境表示的方法的进一步引用可以在第vib .2节的Lowry等人[1]关于视觉场所识别的调查中找到。虽然我们的方法旨在利用多个参考遍历的互补性,但Hausler等人提出的多进程融合方法将应用于同一输入图像的多个互补图像处理方法的预测融合在一起。这也与[35]有关,在[35]中,只需使用100个训练样本,查询和引用遍历之间的外观更改就可以在一定程度上被删除。与[35]不同,我们的方法是免费培训。我们的方法也与[17]有关,其中研究了顺序条件的变化;但是,只使用一个引用集。
PART3:方法
在本节中,我们将介绍新的贝叶斯选择融合方法。我们首先回顾了基于描述子距离的单图像VPR的公式和解决方案,包括最先进的融合方法[18]。我们利用这一公式和描述子距离的性质提出了一种选择参考图像的新策略和一种融合它们的新贝叶斯方法,以及一种用于概率VPR的新似然函数。
A.问题公式与最小值原则
设X是一个未知的位置,机器人在该位置捕获查询图像IX,并提取相应的图像描述符向量zX∈RNz,维数为Nz(例如,使用NetVLAD[2])。设X属于集合X ={1,…, N}个可能的位置。机器人可以在不同的视觉外观条件下访问X区域,获取该区域以往访问时的参考图像。这些参考图像存储在总共M个参考集中,每个参考集的索引由标量u∈{1,…每个参考集u∈u包含(最多)来自X中每个位置的一幅图像(以及相关的图像描述符)。设Iui和zui∈RNz表示位置i∈X对应的参考集u∈u的像和对应的描述符。给定参考集u∈u,机器人可以计算出查询图像IX的描述符zX与描述符zui之间的距离d: RNz × RNz 7→R≥0,距离为X中每个位置i从参考集u处开始。我们收集向量中对应于参考集合u的距离
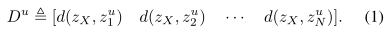
我们用Dui表示Du的第i个分量,即Dui≡d(zX, zui),为了不失一般性,我们考虑d(zX, zui)的欧氏距离(也可以用其他距离度量)。VPR问题是从部分或全部参考集u中使用向量Du来推断位置X。目前绝大多数VPR方法都依赖于最小值原则(或最佳匹配策略)[6],[22]。该原则断言,匹配ˆX的最佳位置对应于每个引用集中描述符的最小距离,即:
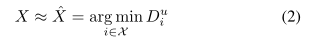
对于任意u∈u,[18]的最小集合距离法是最近提出的一种基于最小值原理的最先进的方法,融合了来自多个参考集的信息。在这种最小集合距离方法中,通过最小化所有参考集上描述符距离向量Du的平均值(相当于总数)来找到匹配ˆX的位置,即:
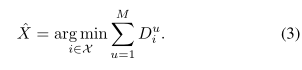
显然,基于最小值原则的VPR方法在使描述符距离最小化的位置不是真实位置时表现最差——例如,当在不同的外观条件下捕获查询和参考图像时,可能会出现这种情况。虽然它们的鲁棒性可以通过融合在各种外观条件下捕获的参考集,使用加法或平均(如式(3))来提高,但这些操作隐含地假设所有参考集提供同等有用的信息。我们假设参考集对于不同的查询图像具有不同的效用,并且这种效用具有内在的不确定性。为此,我们提出了一种新的贝叶斯选择性融合方法:1)基于最小值原则选择信息参考集;2)利用贝叶斯融合方法对所选参考集进行融合处理最小值原理保持的不确定性。
我们假设参考集对于不同的查询图像具有不同的效用,并且这种效用具有内在的不确定性。为此,我们提出了一种新的贝叶斯选择性融合方法:1)基于最小值原则选择信息参考集;2)利用贝叶斯融合方法对所选参考集进行融合处理最小值原理保持的不确定性。
B.建议的数据集选择
给定所有参考集u∈u的距离向量Du,我们选择一个参考集的变量子集,定义为:
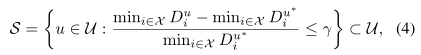
用它来计算位置决定。集合S是在最小值原则下首先选择“最佳”参考集形成的,即包含这样的最小距离的参考集u∗
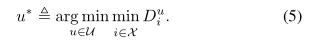
所有引用集u∈最小描述符距离迷你∈X酒后驾车在一小部分γ> 0距离最小描述符的迷你∈X Du参考集u∗∗我也添加到美国我们的参考集选择方法像局外人拒绝与参数γ控制拒绝引用集和最小描述符从u与“最佳”参考设置u∗相比的离群值距离。
C.提出贝叶斯融合
给定描述子距离向量DS, {Du: u∈S}与所选参考集S之间的距离,X上的贝叶斯信念P (X |ds)由贝叶斯规则给出:
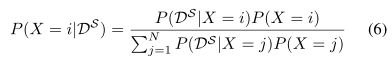
对于i∈X。机器人有其位置的任何先验知识(例如产生的运动模型或以前的地方匹配)是注册通过先验概率分布P (X)在没有任何先验知识的情况下,这是作为统一的(即P (X = i) = N−1我∈X)。可能性P (DS |x)使我们能够将所选参考文献S中的位置信息进行新的融合。
为了使式(6)中的新型融合操作显式(且可伸缩),请注意,描述子距离Dui仅是给定X(以及IX和zX)之后的参考图像描述子zui的函数。因此,给定X,来自不同参考集的向量Du是条件独立的,似然P (DS|X)化简为乘积
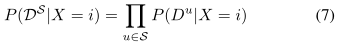
对于i∈X,其中P (Du|X)是单个(个体)参考集u∈s的可能性。构建单一参考可能性P (Du|X)比构建联合可能性P (DS|X)更容易,也更可扩展,我们将在下一小节中讨论。在这里,我们注意到,由于Eq.(7)中的可能性P (DS |x)具有乘积形式,而Eq.(6)中的分母只是为了标准化,我们可以将Eq.(6)简单地重写为:
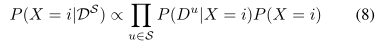
对于i∈X。采用我们的方法,机器人的位置识别决策为ˆX,则为贝叶斯信念最大值(未归一化)的位置,即:
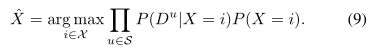
没有地方识别决定如果信仰不能超过一个阈值h > 0,这平衡认识到错误的地方(小h)与失踪的真实的地方(大型h)。我们接下来描述小说高效建设单一参考可能P (Du | X)用于Eq。(9)。
D.提出的无训练单一参考似然
要构造单参考似然P (Du|X),请注意,根据定义它们是距离的联合似然,即P (Du b| X)≡P (Du1,…DuN | X)。还要注意的是,为了使Dui的效用相等,它们的(边际)分布应该只取决于X和i的位置是否匹配,而不取决于X和i的特定位置。因此,模型给出的距离酒后驾车是条件独立的X和分布式根据(边际)分布P(酒后驾车| X 6 = i)当X不匹配我的地方和不同的(边际)分布P(酒后驾车| X = i)当X比赛的地方。(联合)可能性的任何地方我后观察向量Du参考集u是如此观察个体距离后的(边际)可能性的乘积,即:
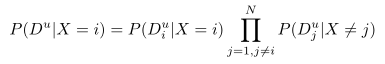
对于i∈X。同样地,我们可以把这种可能性写成
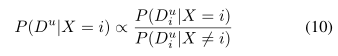
对于i∈X。这里,比例常数Cu,QN j= 1p (Duj |X 6= j)对于所有i∈X都是常数,这使我们可以在我们的方法中简单地忽略它(参见Eq.(9))。位置匹配和非位置匹配概率P (Dui |X = i)和P (Dui |X 6= i)之前是通过对(整体图像)描述符的训练构建的(cf.[1],[22])。这些方法可以直接用于评估Eq.(10),但我们提出了一种基于最小值原则的概率编码的替代训练免费方法(Eq.(2))。对于给定的参考集u,我们将位置匹配可能性P (Dui |X = i)建模为与Du中描述符距离大于Dui的位置数量成正比,即:
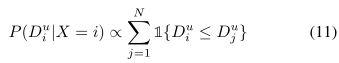
其中指示函数1{Dui≤Duj}在Dui≤Duj时取值为1,否则为0。同样,比例常数与i无关,可以忽略。我们模型non-place-match可能性P(酒后驾车| X 6 = i)回忆,描述符的分布距离是独立的,因此大多数杜向量中的元素实现的描述符距离X 6 =我。由于计算效率计算µ均值和方差σ2 Du的元素,我们简单地将非地点匹配似然模型化为P (Dui |X 6= i) = N (Dui;µ,σ2)(接受Du中的一个元素i对应于X = i时,会产生一定的偏差)。
E.贝叶斯选择融合综述
综上所述,我们提出的方法首先根据式(4)选择参考集,然后利用式(11)和我们的非地点匹配似然的高斯构造计算式(10)给出的单参考似然,最后通过式(9)的最大化来宣布一个地点识别决策。
PART4:实验
在本节中,我们将描述用于评估方法的数据集、方法、指标和参数。
A.数据集
我们使用两个广泛使用的、已建立的基准数据集。Nordland数据集[36]包含挪威一列火车在春、夏、秋、冬四季行驶728公里的四段录音。我们从这些视频中(20:00到1:40:00)每秒钟提取一幅图像,并像文献中通常做的那样,手动移除隧道和列车静止或以低于15公里/小时的速度行驶的区域(基于可用的GPS信息)。这导致每个赛季总共有3000帧。由于其中一个视频中的第i帧与其他视频中的第i帧完全对应,我们通过将查询遍历帧号与参考遍历帧号匹配来找到ground-truth对应,并允许±2帧的ground-truth容忍。Nordland数据集在文献中得到了广泛的应用,如[4],[8],[35]。
Oxford RobotCar数据集[37]包含了在一天的不同时间和不同天气条件下通过Oxford的一致路线的100多次遍历。最近,厘米精度的地面真相注释(基于后期处理的GPS、IMU和GNSS基站记录)可用于这些遍历的一个子集[38]。我们选取了5个相同route1的遍历,并对它们进行下采样,使i和i + 1之间的空间间隔规则为1米,结果是3350帧。我们使用前左立体声摄像机记录的图像。与Nordland数据集类似,牛津RobotCar数据集在文献中被广泛使用,如[4],[8]。与[4]一样,我们使用±10米的地面真值公差。
我们为从数据集中提取的图像计算了NetVLAD[2]描述符。在[2]和as成为后续研究的标准(cf.[4],[18])之后,通过PCA将描述符减少到4096个成分。除了一个比较研究(章节V -F)外,我们在所有的实验中都对zX和zui使用这些NetVLAD描述符,对此我们也计算了4096-d DenseVLAD[3]描述符。
B.基线法、融合法和单参照法
我们使用最先进的[18]最小集合距离方法(也见式(3))作为基线融合方法,与我们提出的贝叶斯选择融合方法进行比较。这些融合方法使用的参考集构成删除查询遍历后相关数据集上的剩余遍历(即,如果查询是Nordland Summer,则参考集是Winter, Fall和Spring)。我们还实现了标准的单引用NetVLAD(参见式(2))和我们的贝叶斯方法的单引用集版本(即M = 1)。这些单引用方法是根据它们的参考集进行标记的(例如,仅给定一个Nordland spring reference,NetVLAD称为NetVLAD Spring,单引用贝叶斯方法称为贝叶斯Spring或简称Spring)。
C .性能指标
我们使用精度-召回(PR)曲线报告VPR性能(我们提出的方法的阈值h扫过)。精度定义为正确的位置匹配与总位置匹配数量的比值,而召回定义为正确的位置匹配与可能的真实匹配总数的比值。我们的数据集对每个查询图像都有真正的匹配。在一些实验中,我们也报告了PR曲线下的面积(AUC)作为汇总统计。在[14]-[16]中,AUC作为100%查全率的代理(这与SLAM有直接关系),用于比较单图像VPR方法,因为许多方法不能提供100%查全率。
D.参数:选择参考集γ的分数
我们的方法依赖于单个参数γ(见式(4))。根据我们的经验,γ∈[0.04,0.1]的值在Nordland和Oxford数据集上提供了合理的性能。为了说明这种不敏感性,我们在所有的实验中使用一个固定的γ = 0.04,注意到可以通过调谐γ获得改进。
PART5:实验结果
在本节中,我们通过六个实验评估我们的方法及其参考选择和贝叶斯方面,包括对最先进技术的比较和扩展。在V -A节中,我们首先将贝叶斯VPR的新免训练可能性与NetVLAD进行比较,以检验其性能。在章节V -B和V -C中,我们将我们的贝叶斯选择融合方法与[18]和NetVLAD的最先进的融合方法进行了比较(NetVLAD提供了性能最好的参考集)。在第V -D节中,我们展示了在一个极端外观变化的场景中我们的方法。最后,在章节V -E和V -F中,我们证明了我们的方法也可以利用序列匹配(即SeqSLAM[5])和替代图像描述符(即DenseVLAD[3])。
A.单参考方法比较
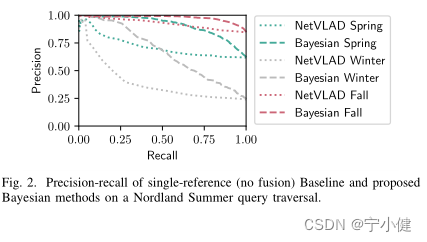
图2显示了贝叶斯方法与我们新的无训练单参考似然比NetVLAD的性能更好,对于来自Nordland夏季遍历的查询图像给出相同的参考集。当两者表现最好时(秋季参考),贝叶斯方法提供了5.5%(相对)的AUC比NetVLAD的改进,当两者表现最差时(冬季参考),提高了70%。图2激发了(选择性)融合的使用,因为这些方法的性能强烈依赖于它们所提供的参考图像。因此,我们现在专注于评估贝叶斯选择融合方法的性能。
B.贝叶斯选择性融合与基线融合
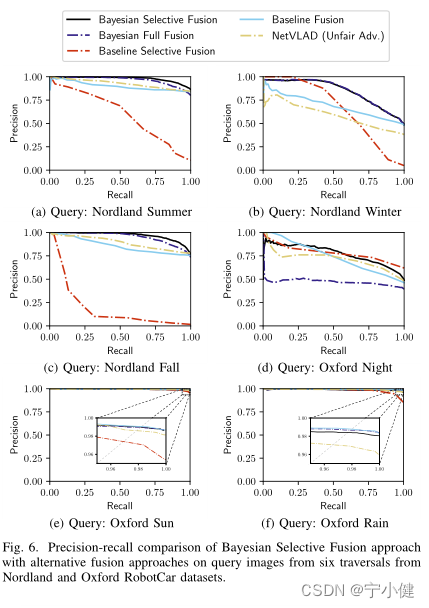
接下来,我们将贝叶斯选择性融合方法与最先进的融合方法18和NetVLAD(不公平地)进行比较,给出了每次遍历的最佳性能参考。图3和图4显示,我们的方法在Nordland夏季和冬季查询遍历上比基线方法有很大的优势,我们的方法的auc为0.97和0.84,而基线方法的auc为0.89和0.68(分别增加了9%和24%)。我们的方法在较容易的牛津太阳穿越上的表现略低于基线融合方法(AUC为0.995,而非0.997),但在较困难的牛津夜穿越上的表现优于基线融合方法,AUC为0.77,而非0.74(增加4%)。
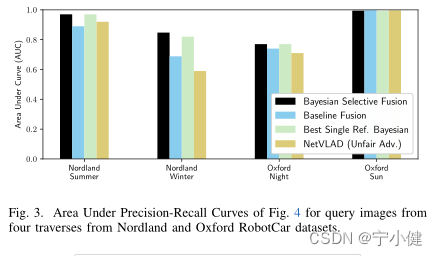
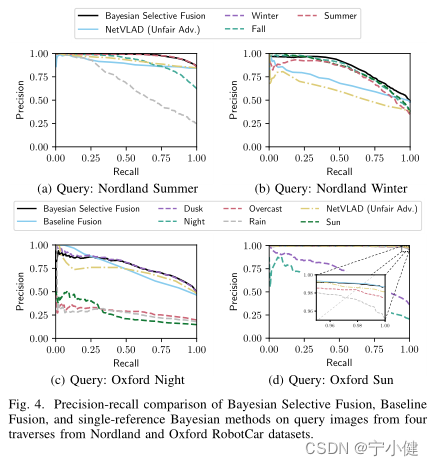
我们的方法可以选择信息参考集(如图1所示),因为它比单参考贝叶斯方法具有相同或更好的性能。如图4(b)所示,在Nordland Winter,我们方法的AUC比单参考贝叶斯方法的平均AUC高5%,最好的方法的AUC高3%。最后,除了最简单的情况外,我们的方法在所有情况下都优于NetVLAD(即,Oxford Sun的AUC的绝对差异小于0.003);AUC的提高范围从牛津夜的8.5%到更困难的诺德兰冬季的25%。图10显示了我们的方法的正确匹配和NetVLAD的错误匹配的例子。
C.与其他融合方法的比较
我们现在进行一项消融式研究,以检验我们的方法在使用和不使用贝叶斯融合和/或参考集选择时的性能。我们考虑了一种忽略参考文献选择的贝叶斯完全融合方法;和,基于公式(3)的基线融合方法的基线选择性融合方法,仅使用选定的参考集s。我们还考虑在每次遍历中给出最佳参考的NetVLAD(有利地)
D.极端的外观变化
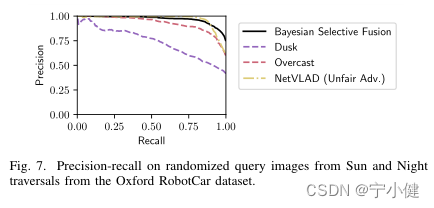
我们的参考集选择方法部分是由于VPR系统需要适应地方的视觉外观可以动态变化和不可预测的情况,如室内闪烁的灯光。在本研究中,我们考虑这样一个场景,即Oxford数据集中每个地方的查询图像都是从Sun或Night遍历中随机(以等概率)绘制的。
我们提出的方法在随机的Sun/Night查询遍历上的性能如图7所示,以及在独立的Oxford Sun和Night遍历上表现最好的Dusk和Overcast单参考贝叶斯方法的性能。考虑到最佳参考集(overcast)的优势,我们还将NetVLAD与它一起再次考虑。从图7中,我们可以看到贝叶斯选择融合在召回率大于0.9的情况下优于单参考方法和(优势的)NetVLAD,并且AUC比(优势的)NetVLAD、Overcast和Dusk分别提高了1.0%、6.6%和29%。
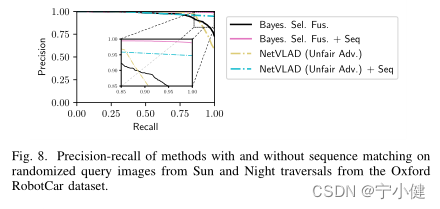
E .序列匹配
序列匹配技术通常与单图像位置匹配技术相结合,用于具有挑战性的环境下的VPR。从图8可以看出,我们的方法与现有序列长度为5的序列匹配方法(SeqSLAM[5])相结合,提高了我们之前研究中随机查询的性能。尽管NetVLAD已有最佳参考集的先验知识,但该算法的性能优于与相同序列匹配方法集成的NetVLAD。
F.其他图像描述符
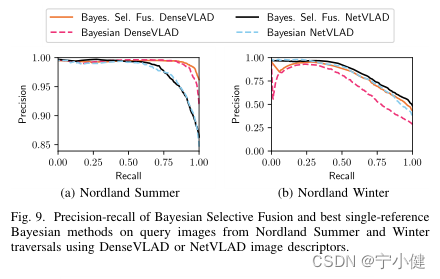
在我们之前的研究中,我们使用NetVLAD[2]描述符。图9显示了使用DenseVLAD[3]描述符而不是NetVLAD描述符重复我们在Section V -B中对Nordland夏季和冬季遍历查询的研究的结果。我们发现,与最好的单引用贝叶斯方法相比,我们的方法无需进行任何修改、参数调优或培训,就可以获得类似的性能增益。

G.计算时间和缩放
在i7-8750H CPU上,对于M = 3和N = 3000的位置,我们的方法平均为0.0224s(参考选择0.000s,融合0.0222s)。复杂度与参考文献的数量M是线性的,然而,昂贵的贝叶斯操作(Eq.(9)和Eq.(10))与S中选择的参考集的数量线性缩放。
PART6:结论
视觉位置识别依赖于将查询图像与之前捕获和存储的参考图像进行比较。令人惊讶的是,对多个相同位置的参考图像的存储和利用最近几乎没有引起人们的注意,使用最先进的方法,要么试图在不考虑查询时间条件的情况下先验确定参考图像的用途,要么融合所有可用的参考图像,这可能是不必要的和适得其反的。在本文中,我们提出了贝叶斯选择融合作为一种新的方法来动态确定和利用参考图像在查询时的效用。我们已经证明,在具有挑战性的基准数据集上,我们的方法可以超越最先进技术的性能,包括具有(优势)最佳参考图像先验知识的最先进的单参考方法。我们还表明,我们的方法是描述符不可知的,可以与标准技术(包括序列匹配)结合使用,以实现最先进的性能。
我们目前的工作可以在几个方面进行扩展,包括使用贝叶斯选择融合和最近提出的Delta描述符[4]、局部描述符、以及通过Eq.(6)中的先验进行概率序列匹配。我们还对在查询图像和参考图像之间存在较大视点变化的情况下评估我们的方法感兴趣,但目前受到现有数据集提供的参考集太少的限制。此外,探索参考集选择方法的洞察力,以确定应该收集哪些额外的参考集,或者可以丢弃哪些参考集,以最小化存储需求,这将是有趣的。最后,我们相信,我们的研究有助于更好地理解如何在一个无需训练的贝叶斯设置中利用深层图像描述符的信息,打开了结合参考集融合使用时间贝叶斯滤波的可能性,并进一步开发了信息理论技术在视觉位置识别中的应用。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









