






DETR
2d目标检测
算法思路
DETR开创性地将目标检测视作一种集合预测任务,直接预测固定数量的边界框的集合,不需要anchor,不需要nms。
DETR用transformer架构处理目标检测任务,用全局注意力机制建模图像特征的空间关系,相较于传统的CNN操作,增加了对于长距离依赖的捕捉能力。
算法流程
-
特征提取:
- 经过backbone提取图像特征,生成图像特征图;
- 对特征图的行和列使用正弦位置编码,每种位置编码的维度为128维,然后把两种位置编码按照行列组合拼接,再加到对应位置的特征上。
-
transformer encoder
- 将特征图展平为一列序列,记得添加位置编码;
- 通过多层transformer encoder进行全局特征交互(每个特征图的像素作为query,key和value),每层包含多头自注意力(Multi-Head Self-Attention)和前馈网络(FFN)。
-
transformer decoder
- 首先输入固定数量的object queries (object queries的数量和特征图像素不一定相同),每个查询相当于是一个预测目标的anchor,query初始化维随机的learning embedding,同时添加位置编码(也是随机初始化的)。 这些query不像sparsebev中的query一样有显示的位置信息(bounding box或者reference point),而是抽象的可学习向量。
- object queries之间进行自注意力交互,让不同的 Object Queries 交换信息,避免彼此预测相同的目标,提高检测的多样性。
- object queries和encoder输出的特征(图像每个特征图像素的特征)进行交叉注意力交互,逐步refine每个query的特征。
-
匈牙利匹配
用于将预测框与真实框进行最优匹配。
Deformable DETR
2d目标检测
算法思路
将动态采样引入注意力机制,让每个query仅关注少量动态预测的采样点,而非整张图像。可以减小计算复杂度,避免冗余关注,节约计算资源。
提出了deformable attention,主要在图像特征进一步编码,和object query从图像中学习特征这两个阶段使用了deformable attention。
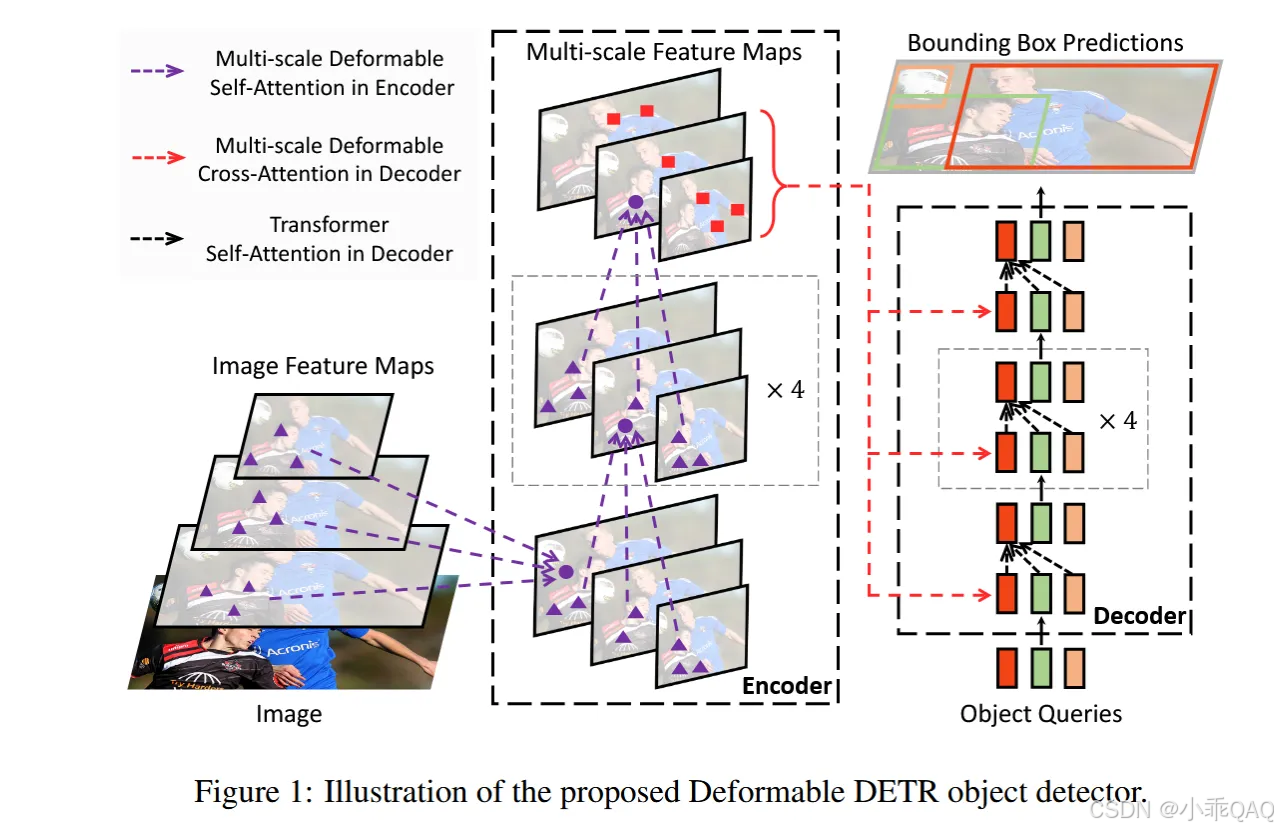
算法流程
-
图像初步特征提取:
用CNN对输入图像进行初步特征提取,得到多尺度特征图;
-
Deformable Transformer Encoder:
-
encoder阶段,query是特征图的每个特征像素(特征token),它们还显示地拥有一个2D参考点坐标属性,这个坐标值直接由它们在特征图上的索引来确定。由于有多尺度特征,所以以下操作都是对每个尺度的特征图单独进行的,输出也保持多尺度特征图的格式。
-
对于每一个query,将其动态地生成一系列采样点偏移(比如把query特征输入一个网络来生成偏移量),采样点偏移与其对应的2D参考点坐标相加,可以得到采样点的坐标。采样点和query位于同一张特征图上,所以在encoder中进行的是Deformable self attention。 (采样点在不同的attention head中,可能是不同的位置,因为采样点偏移在不同的head中是独立预测的)
-
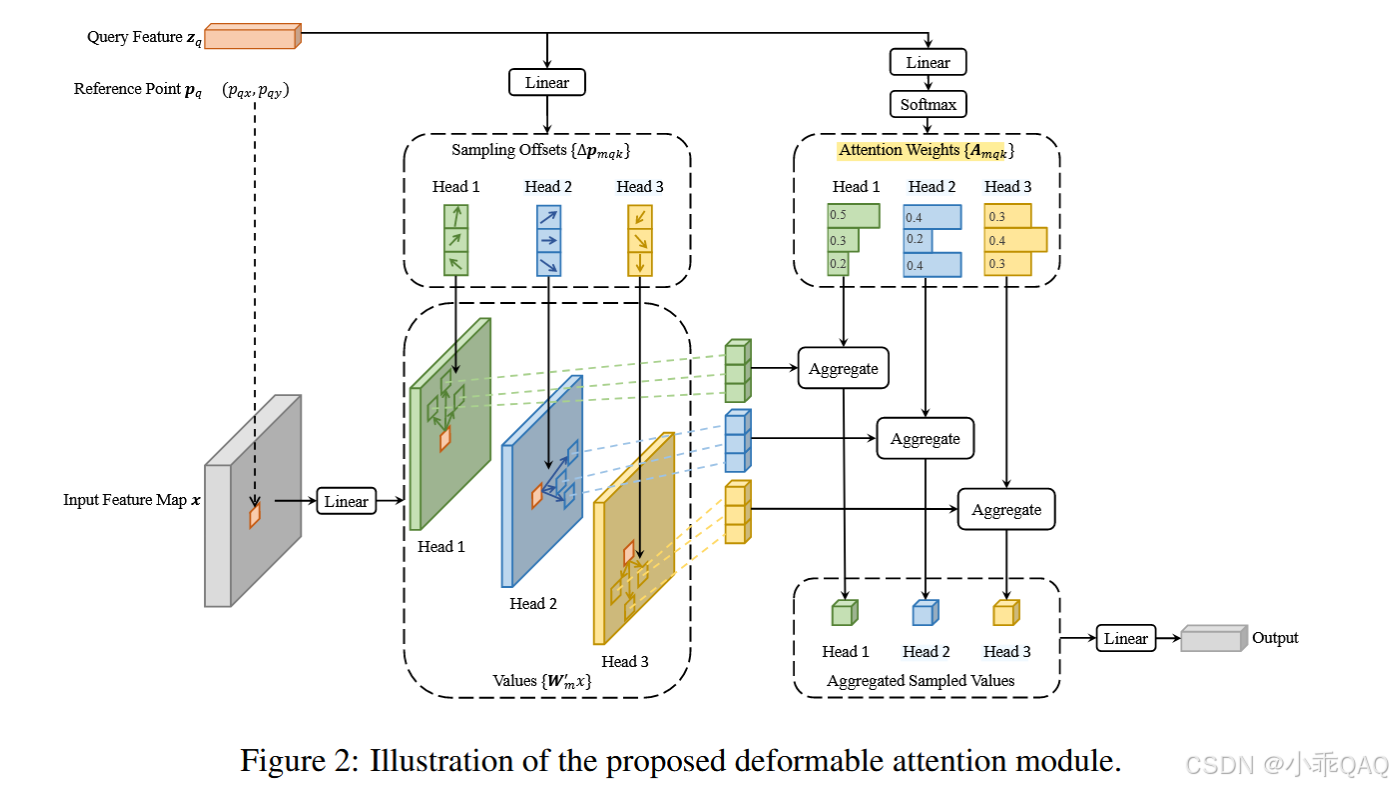
采样这些采样点位置的特征作为value,执行figure2中展示的deformable attention交互操作。即,query动态地(经过linear和softmax)生成和采样点个数相同的attention 分数,再用attention分数和采样点特征value加权求和,作为更新的query的特征。
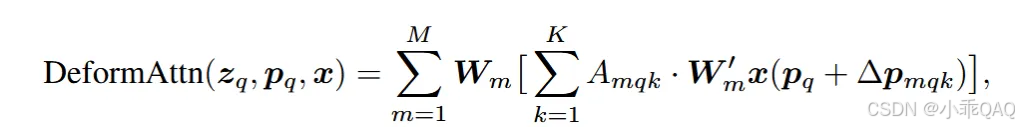
这是deformable attention的公式,K表示采样点个数,M表示注意力的头的个数。Wm和Wm‘是作用于不同注意力头的变换矩阵,是为了给模型加入更多的可变性,增强泛化能力。A是attention分数,x是采样。
-
经过多层encoder layer的特征编码,得到输入图像的高级多尺度特征表示,将其输入decoder和object query交互,最终生成检测结果。
-
-
Deformable Transformer Decoder:
-
decoder阶段,引入了object query,它们也有2D参考点坐标属性,但是该属性通过将object query输入一个前馈网络(类似于回归head)来预测得到。 由于object query需要同时与多个尺度的图像特征交互,所以设计了多尺度deformable attention来融合多尺度信息。
-
在decoder中,object queries先在相互之间进行传统的self attention交互,建模不同目标之间的关系;
-
然后object queries和encoder中输出的图像高级多尺度特征进行Multi-scale Deformable Cross Attention交互,用图像特征信息更新object query的特征表示。
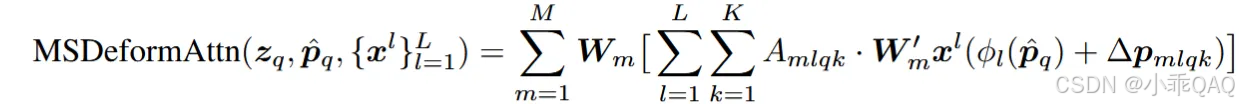
相较于deformable attention的公式,这个多尺度deformable attention增加了一个在特征图层数L维度上求和的公式。采样点在不同head、不同特征图层是独立获取的。
更新的object query特征为:该query在所有注意力head中,所有层的特征图上,所有采样点处采样到的图像特征的加权求和。权重由attention分数A确定,同时也受不同head的变换矩阵Wm和Wm‘影响。
-
一些思考
- 与transformer中提出的attention不同,deformable attention不“将输入向量经过变换矩阵获得Q,K,然后用它们的乘积来计算attention分数”,而是直接“让query向量经过线性层和softmax来计算attention分数”。
- 输入图像特征作为query时,它的2d参考点属性是直接由它在特征图中的索引位置来获取的;object query时,它的参考点属性是用前馈网络回归query特征来获得的(DETR3D同理)。
DETR3D
3d目标检测
算法流程
- backbone+neck(resnet和fpn)提取多尺度图像特征;
【detr3d中没有transformer encoder部分,是decoder only的架构,以下是decoder结构】
-
初始化一系列object queries,它们具有query特征这一个属性;query对应着一个3D参考点(目标物体3d bbox的中心点),这个参考点的具体位置是将query特征解码(输入一个神经网络)后获得的,可以说query特征隐式地编码了参考点的位置。
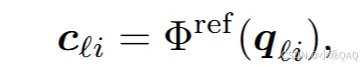
Cli是3d bbox的center,qli是query特征
-
将query参考点投影到多视角图像的多尺度特征图上,用双线性插值法采样投影点的图像特征。一个参考点可能被投影到多张图像特征图上,同时也可能超出某些图像特征图的边界范围。通过设置一个bool值σ(如果参考点被投影到这张图像上,则σ=1,反之,σ=0),可以更方便地计算。最终得到的图像采样特征是,参考点所投影到的所有特征图(多视角、多尺度)采样特征的加权平均。
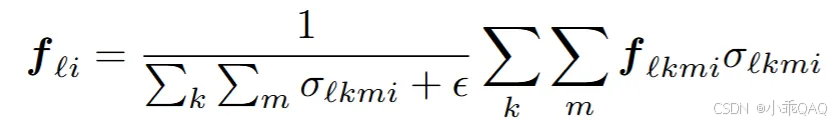
ε是一个很小的值,用来防止除以0(即参考点没有被投影到任何特征图上的情况)
-
更新query特征,将当前的query特征和参考点采样到的图像特征相加。(没有用到cross attention)
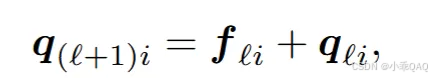
-
所有query之间进行多头自注意力交互。
-
将最后一层decoder layer输出的query特征送入回归头和分类头得到目标检测结果。

















 1964
1964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









