



 文章描述了一个在使用8张GPU进行分布式并行运行时遇到的NCCL错误,通过逐步排除法确定问题不在单个GPU,而是可能与IB网卡有关。设置环境变量NCCL_IB_DISABLE=1后,问题得到解决。
文章描述了一个在使用8张GPU进行分布式并行运行时遇到的NCCL错误,通过逐步排除法确定问题不在单个GPU,而是可能与IB网卡有关。设置环境变量NCCL_IB_DISABLE=1后,问题得到解决。
报错:
[E ProcessGroupNCCL.cpp:390] Some NCCL operations have failed or timed out. Due to the asynchronous nature of CUDA kernels, subsequent GPU operations might run on corrupted/incomplete data. To avoid this inconsistency, we are taking the entire process down.
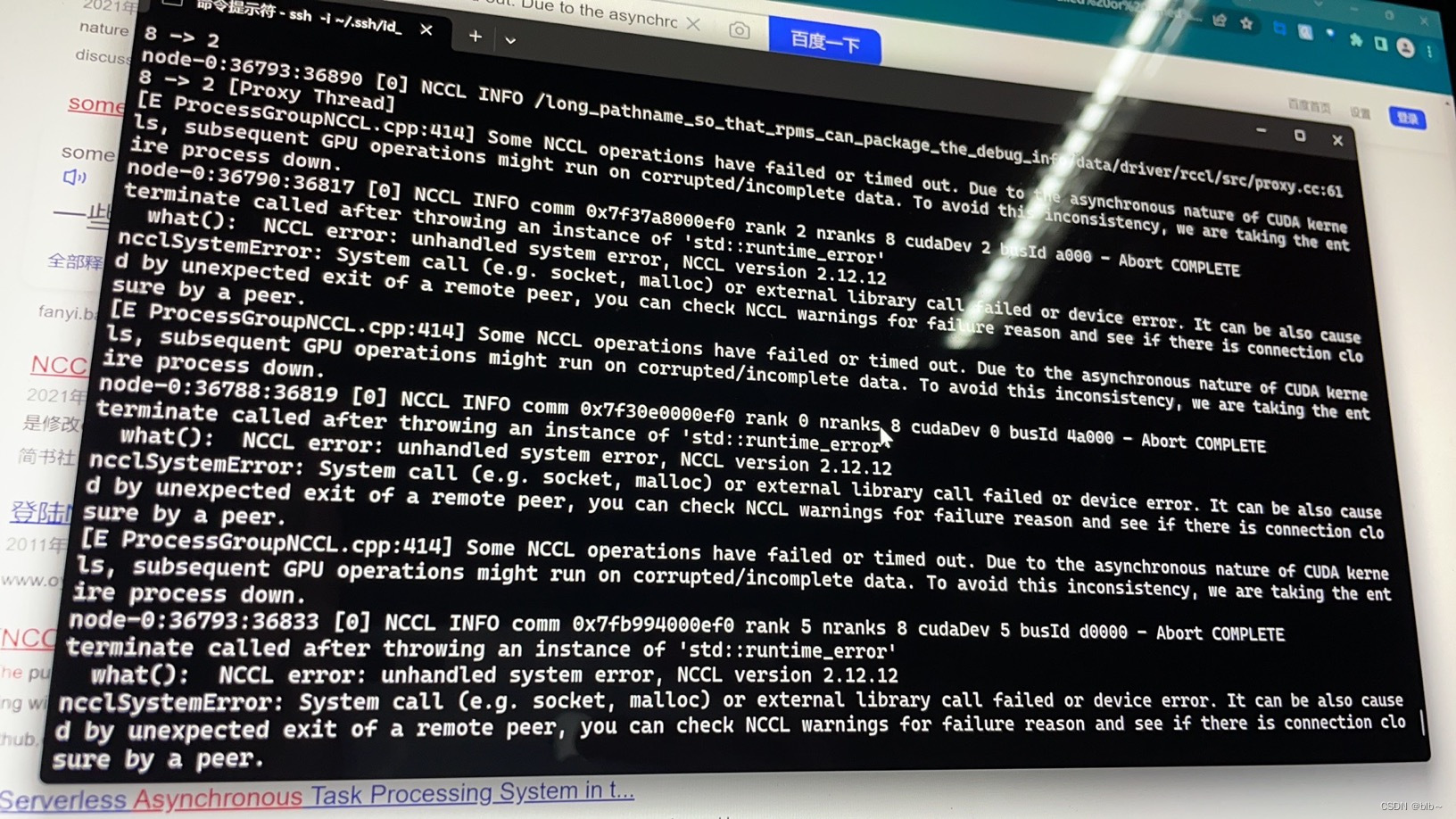
目前是用8张卡分布式并行运行,解决这种问题的思路是:
1、首先先看1张卡能不能跑通,以此来排除代码本身问题
2、第二步是看是不是某一张卡出现了问题,过程是分别设置0、1卡,0、1、2、3卡,0、1、2、3、4、5卡,0、1、2、3、4、5、6卡,我的实验中这些都没问题,但是0、1、2、3、4、5、6、7就有问题了,所以怀疑是7卡有问题,然后试了一下1、2、3、4、5、6、7卡跑,也没问题,所以怀疑是0卡和7卡之间有冲突,然后试了一下0、7卡,也没有问题。所以问题不是在某一张卡上
3、可能是IB网卡的问题,于是把IB网卡的传输取消:
export NCCL_IB_DISABLE=1
代码运行成功,问题解决。

















 1277
1277







 到【灌水乐园】发言
到【灌水乐园】发言







