







1. Hive 数据存储格式(数据压缩)
1.1 Hive 数据压缩
| 数据压缩优点 | 数据压缩缺点 |
|---|---|
| 减少存储磁盘空间,降低单节点的磁盘 IO | 需要花费额外的时间和CPU(core)资源对数据进行压缩和解压缩 |
| 数据传输占用的带宽更少,因此可以加快数据在 Hadoop 集群流动的速度,减少网络传输带宽 |
| 压缩格式 | 压缩格式所在的类 |
|---|---|
| Zlib | org.apache.hadoop.io.compress.DefaultCodec |
| Gzip | org.apache.hadoop.io.compress.GzipCodec |
| Bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| Lzo | com.hadoop.compression.lzo.LzoCodec |
| Lz4 | org.apache.hadoop.io.compress.Lz4Codec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
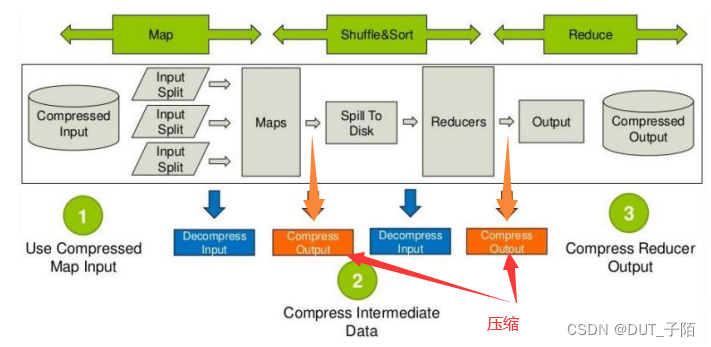
压缩分析:
mapreduce 哪些过程可以设置压缩?
- 进入map 前的数据可以压缩,然后解压处理
- map 处理完成后的输出可以压缩,这样可以减少网络 I/O(reduce 通常和 map 不在同一节点上)
- reduce 拷贝压缩的数据后进行解压,reduce 处理完成后的数据可以压缩存储在 hdfs 上,以减少磁盘占用量
1.2 Hive 开启数据压缩
- 开启 hive 中间传输数据压缩功能
-- 1 开启 hive中间传输数据压缩功能 set hive.exec.compress.intermediate=true; -- 2 开启 mapreduce中 map输出压缩功能 set mapreduce.map.output.compress=true; -- 3 设置 mapreduce中 map输出数据的压缩方式 set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec; - 开启 Reduce 输出阶段压缩
-- 1 开启 hive最终输出数据压缩功能 set hive.exec.compress.output=true; -- 2 开启 mapreduce最终输出数据压缩 set mapreduce.output.fileoutputformat.compress=true; -- 3 设置 mapreduce最终数据输出压缩方式 set mapreduce.output.fileoutputformat.compress.codec= org.apache.hadoop.io.compress.SnappyCodec; -- 4 设置 mapreduce最终数据输出压缩为块压缩 set mapreduce.output.fileoutputformat.compress.type=BLOCK;
1.3 数据存储格式——行式存储
| 优点: | 缺点: |
|---|---|
| 按行存储数据,相关数据保存在一起,符合面向对象的思维,一行数据就是一条记录 | 读取时按行读取,在查询只涉及某几个列时,会读取大量不必要的数据,数据量较大时比较影响性能 |
| 按行存储适合进行 insert/update操作 | 由于每一行中,列的数据类型不一致,导致不容易获得一个极高的压缩比,空间利用率不高 |
| 不是所有的列都适合作为索引 |
1.4 数据存储格式——列式存储
| 优点: | 缺点: |
|---|---|
| 只查询涉及到的列,不会查询所有列,避免不必要的列查询 | insert/update 操作极其麻烦或者极不方便 |
| 高效的压缩率,节省储存空间,节省计算内存和 CPU | 不适合扫描小量的数据 |
| 任何列都可以作为索引 |
1.5 存储文件格式
-
Text File
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合 Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive 不会对数据进行切分,从而无法对数据进行并行操作。 -
RCFile


-
ORC File

indexData:某些列的索引数据
rowData :真正的数据存储
StripFooter:stripe 的元数据信息

-
Parquet File



存储文件的压缩比总结:ORC > Parquet > textFile
1.6 文件压缩
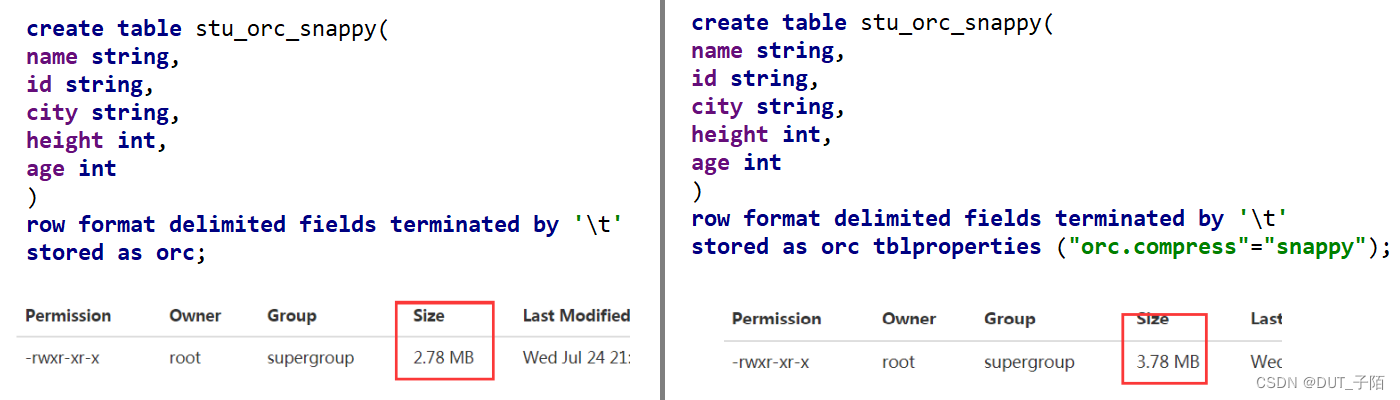
在大数据中使用 ORC存储方式。上面导入数据后的大小前者为比 Snappy 压缩的还小。原因是 orc 存储文件默认采用 ZLIB 压缩。比 snappy 压缩的小。在实际的项目开发当中,hive 表的数据存储格式一般选择:orc 或 parquet压缩方式一般选择 snappy。
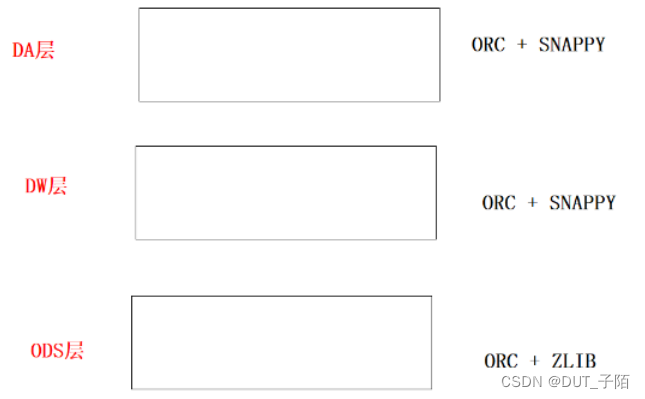
1.7 HIve 分层的常见压缩方式
2. Hive 调优(上)
2.1 Fetch 抓取机制
Hive 中对某些情况的查询可以不必使用 MapReduce 计算,如全局查找、字段查找、limit 查找。
在 hive-default.xml.template 文件中 hive.fetch.task.conversion设置成 none,所有查询语句都会执行MR,设置为more(默认值)时,全局查找、字段查找、limit 查找都不会执行MR。
set hive.fetch.task.conversion=none;
set hive.fetch.task.conversion=more; -- 默认值
2.2 mapreduce 本地模式
mapreduce 程序除了可以提交到 yarn 执行之外,还可以使用本地模拟环境运行,此时就不是分布式执行的程序,但是针对小文件小数据处理特别有效果。
用户可以通过设置 hive.exec.mode.local.auto 的值为 true,来让 Hive 在适当的时候自动启动这个优化。
set hive.exec.mode.local.auto=false; -- 默认值
set hive.exec.mode.local.auto=true;
hive 自动根据下面三个条件判断是否启动本地模式:
--1. 输入数据量小于这个值时采用local的方式
-- 设置local mr的最大输入数据量
set hive.exec.mode.local.auto.inputbytes.max=51234560; --默认为134217728,即128M
--2.输入文件个数小于这个值时采用local的方式
-- 设置local mr的最大输入文件个数
set hive.exec.mode.local.auto.input.files.max=10; --默认为4
--3. 需要的reduce个数为1或者0时采用local的方式
2.3 严格模式
严格模式,防止用户执行那些可能意向不到的不好的影响的查询, 即如果出现低效率的SQL,则会被终止执行。
set hive.mapred.mode = strict; --开启严格模式
set hive.mapred.mode = nostrict; --开启非严格模式
2、在以下情况下,你写的SQL会被终止
1)对于分区表,在where语句中必须含有分区字段作为过滤条件来限制范围,否则不允许执行
2)对于使用了order by语句的查询,要求必须使用limit语句
3)限制笛卡尔积的查询
2.4 并行执行机制
-
并行执行
Hive 会将一个查询语句转化成一个或者多个阶段,Hive默认一次只能执行一个阶段。在某些不存在依赖可以并行执行的阶段,可以开启并行执行,让这些阶段同时执行,提高执行效率。如多表的union。--打开任务并行执行 set hive.exec.parallel=true; --同一个sql允许最大并行度,默认为8。 set hive.exec.parallel.thread.number=16; -
并行编译:
默认情况下, 如果hive有多个会话窗口, 而且多个窗口都在提交SQL, 此时hive默认只能对一个会话的SQL进行编译, 其他会话的SQL需要等待, 这样效率相对比较低-- 开启并行编译的操作,默认为false set hive.driver.parallel.compilation=true; -- 设置最大同时编译几个会话的SQL,若设置为 0 或者 负值 为无限制 set hive.driver.parallel.compilation.global.limit;
2.5 小文件合并的操作
文件系统角度:当HDFS中小文件过多后,会导致整个HDFS的存储容量下降。每一个小文件都会有一个元数据,而元数据是存储在NameNode的内存中,一旦内存满了,即使DataNode还有空间,也无法存储。
MR角度: 当小文件过多,读取数据时,会产生大量文件的切片,导致有多个MapTask的执行,而每个MapTask处理数据量都比较少,导致资源浪费、执行时间较长。MapTask过多而资源不够时,多出的map只能串行化执行。
--开启map端的小文件合并操作,默认为true
set hive.merge.mapfiles=true
--开启reduce端的小文件合并操作,默认为false
set hive.merge.mapredfiles=true
--设置合并后的文件最大值
set hive.merge.size.per.task
--当输出文件平均大小小于此值时,启动一个独立的MR任务进行文件merge,默认值为16M
set hive.merge.smallfiles.avgsize
2.6 group by 优化 (数据倾斜)【重要】
当进行 group by 的时候,Map 阶段同一 Key 数据分发给一个reduce,当一个 key 数据过大时会发生数据倾斜。
-
map端聚合: 并不是所有的聚合操作都需要在 Reduce 端完成,很多聚合操作都可以先在 Map 端进行部分聚合,最后在 Reduce 端得出最终结果,Map端join是为了解决Reduce数据倾斜
-
负载均衡:使用两次MapReduce,第一个MapReduce是数据随机分散到不同的Reduce,第二个MapReduce实现真正的聚合
--是否在Map端进行聚合,默认为True
set hive.map.aggr = true;
--在Map端进行聚合操作的条目数目(阈值)
set hive.groupby.mapaggr.checkinterval = 100000;
--有数据倾斜的时候进行负载均衡(默认是false)
set hive.groupby.skewindata = true;
2.7 SQL去重【重要】
在HiveSQL中如果要去重,不要使用distinct关键字,因为该关键字在去重时只能使用一个Reduce将所有数据汇总在一起一个一个的进行比较去重,效率极低.。在实际应用中去重推荐两种方式:
- group by 去重
select deptno,count(*) from emp group by deptno; - 开窗函数 去重
with t as ( select *,row_number() over (partition by deptno order by ** ) as rk from emp ) select deptno from t where rk = 1;
2.8 其他优化
-
矢量化查询(批量化) :
开启了矢量化查询工作,hive执行引擎在读取数据时候,会采用批量化读取。即一次性读取1024条数据进行统一的处理工作,从而减少读取的次数(减少磁盘IO次数),提升效率。【表的存储格式必须为 ORC】--开启了矢量化查询的工作 set hive.vectorized.execution.enabled=true; 默认值为true -
读取零拷贝:
在读取数据的时候, 能少读一点 尽量少读一些(没用的数据尽量不读)。-- 开启读取零拷贝,默认中为false set hive.exec.orc.zerocopy=true; -
关联优化器:
如果多个MR之间的操作的数据都是一样的, 同样shuffle操作也是一样的, 此时可以共享shuffle-- 开启 关联优化器 set hive.optimize.correlation=true;
3. Hive 调优(下)【join数据倾斜】
3.1 大小表join
简单来说就是map端进行join,避免reducer处理时出现的数据倾斜。 Map端join就是将Join操作现在Map端完成一部分,然后再将join后每一个局部结果在Reduce完成整体的join(比如多对多join)。
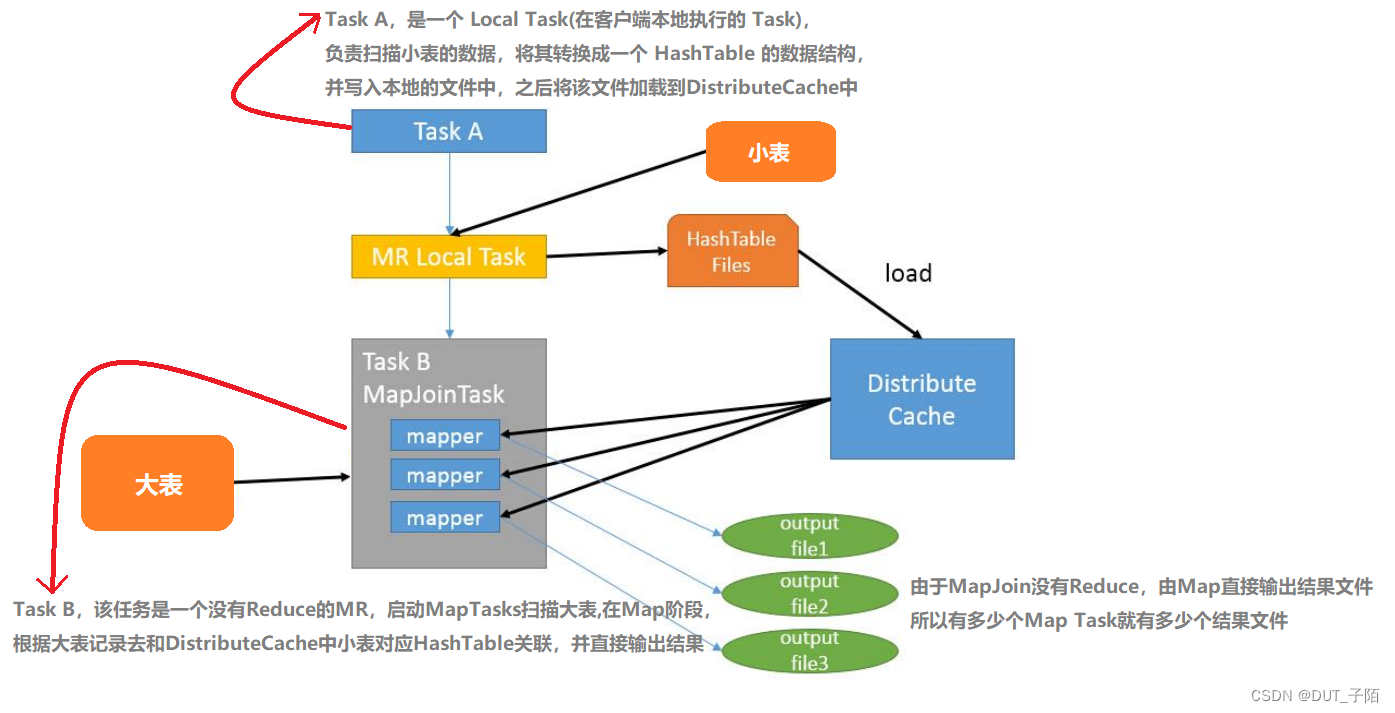
-- 开启 mapjoin 参数设置:
-- 1.设置自动选择 mapjoin
set hive.auto.convert.join = true; # 默认为 true
-- 2. 大表小表的阈值设置:
set hive.mapjoin.smalltable.filesize= 512000000; # 字节为单位 默认20971520
只要根据业务把握住小表的阈值标准即可,hive 会自动帮我们完成 mapjoin,提高执行的效率
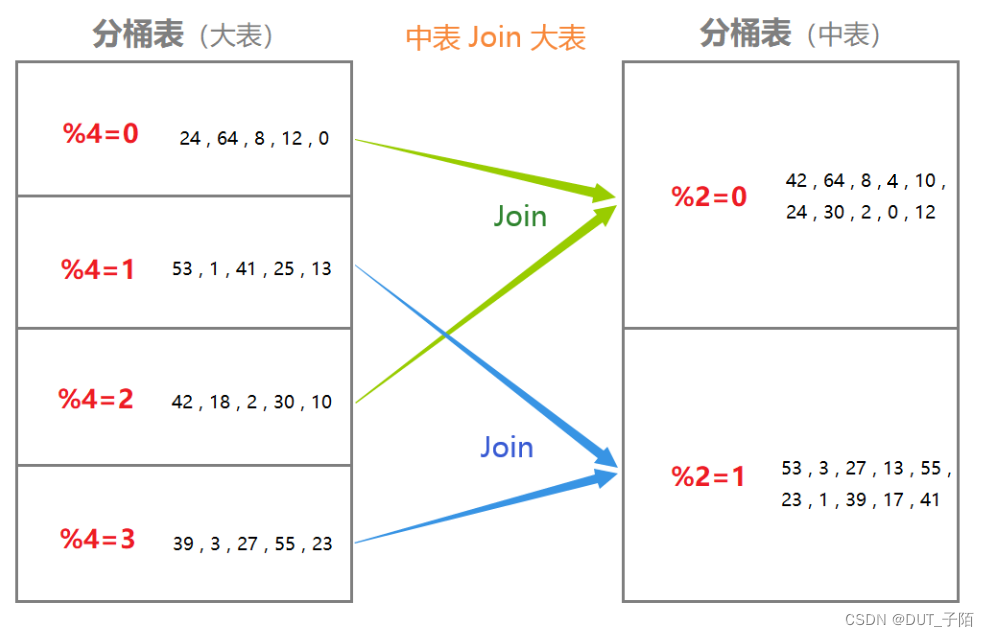
3.2 中表join大表
如果中型表能对数据提前过滤, 过滤后变成小表, 满足了Map Join条件,那么就按上述的方式优化。否则则用Bucket Map Join 进行优化。
条件如下:
- Join两个表必须是分桶表,且一个表的分桶数量是另一个表的分桶数量的整倍数(即建表时需要建分桶表)
- 分桶列必须是 Join条件的列
- 开启Bucket Map Join 支持
-- 开启Bucket Map Join
set hive.optimize.bucketmapjoin = true;
3.3大表join大表
-
空 key 过滤:某些 key 对应的数据太多,而相同 key 对应的数据都会发送到相同的 reducer 上,从而导致内存不够,而这些异常的key对应的字段为空
-- 空 key 过滤 select * from tableA a join tableB b on a.id = b.id; select * from (select * from tableA where id is not null) a join tableB b on a.id = b.id; -
空 key 转换:某个 key 为空对应的数据很多,但是相应的数据不是异常数据,必须要包含在 join 的结果中,通过 hive 的 rand 函数,随记的给每一个为空的 id 赋上一个随机值,这样就不会造成数据倾斜
select * from tableA a join tableB b on a.id = b.id; select * from tableA a join tableB b on case when a.id is null then concat('hive',rand()) else a.id = b.id; -
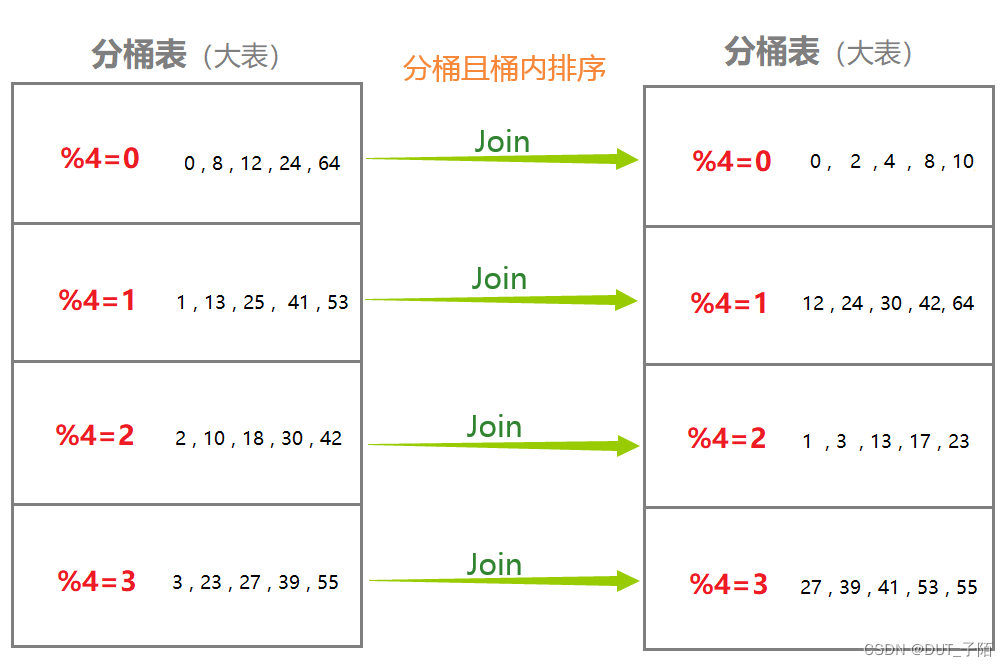
SMB(Sort Merge Bucket) : 排序分桶优化。
使用条件:
- 两个表必须都是分桶表,且两个表的分桶的数量是一致的(即建表时需要建)
- 分桶列必须是 Join条件列 , 同时必须保证按照分桶字段列进行排序操作
- 开启SMB Map Join 支持
select * from tableA a join tableB b on a.id = b.id; select * from tableA a join tableB b on case when a.id is null then concat('hive',rand()) else a.id = b.id; -- 开启Bucket Map Join set hive.optimize.bucketmapjoin = true; -- 开启 SMB Join支持 set hive.auto.convert.sortmerge.join=true; set hive.auto.convert.sortmerge.join.noconditionaltask=true; set hive.optimize.bucketmapjoin.sortedmerge = true; -- 开启自动尝试使用SMB Join set hive.optimize.bucketmapjoin.sortedmerge = true -- 开启强制排序 set hive.enforce.sorting=true;
3.4 Join数据倾斜另一种解决方案
将产生倾斜的kv数据,从当前这个MR移植出去, 单独找一个MR来处理,处理后,与之前MR的进行结果汇总。
-
编译期处理方案:
在创建表的时候,如果可以预知到后续插入到这个表中,哪些key的值会产生倾斜,就在建表时,将其提前设置好即可。在后续运行的时候, 程序会自动将设置的key的值数据单独找一个MR来进行处理。处理完后,再与原来的MR进行union all的合并操作-- 开启编译期处理方案 set hive.optimize.skewjoin.compiletime=true; --建表 create table list_bucket_single (key string, value string) -- 倾斜的字段和需要拆分的key值 skewed by (key) on (1,5,6) -- 为倾斜值创建子目录单独存放 [stored as directories]; -
运行期处理方案:
在执行MR时, 动态统计每一个key出现的重复的数量, 当这个重复的数量达到一定阈值后, 认为该key的数据存在数据倾斜, 自动将其剔除, 交给一个单独的MR进行处理, 等二者MR处理完成后, 将结果union all 合并在一起。适用于: 并不清楚那个key容易产生倾斜, 此时可以交由系统来动态检测set hive.optimize.skewjoin=true; -- 此参考在实际生产环境中, 需要进行调整在合理的值 set hive.skewjoin.key=100000; -
union all 阶段
不管是运行期,还是编译期的join倾斜处理,都会运行多个MR,最终将多个MR的结果,通过union all进行汇总,union all也是单独需要一个MR来运行。可以让每一个MR在运行完成后, 直接将结果输出到临时目的地, 默认是输出到临时文件目录下, 通过union all合并到最终目的地set hive.optimize.union.remove=true;
在实际生产环境中,两种方式都会使用。一般来说, 会将两个都开启, 编译期的明确在编译期将其设置好, 编译期不清楚, 通过运行期动态捕获。

















 1220
1220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









