







在很长一段时间里,研究人员都是手动设计神经网络的架构。神经网络架构的设计空间非常大,它包括#layers、#channel width、#branches、kernel sizes、input resolutions。因此,手动调整这些参数非常困难。而神经架构搜索,NAS,可以帮助研究人员在多种效率和精度指标限制下,自动调整这些参数。

因此,在本文,我们学习Once for All (OFA),这种方法可以大大降低为不同设备专门设计NN架构的成本。OFA训练了一个大型的超级网络,它包含了设计空间内的所有子网络。如果我们直接从超级网络中提取子网络,与从头开始训练相比,它们可以达到类似的精度水平。而且,OFA支持直接部署,不需要重新训练。
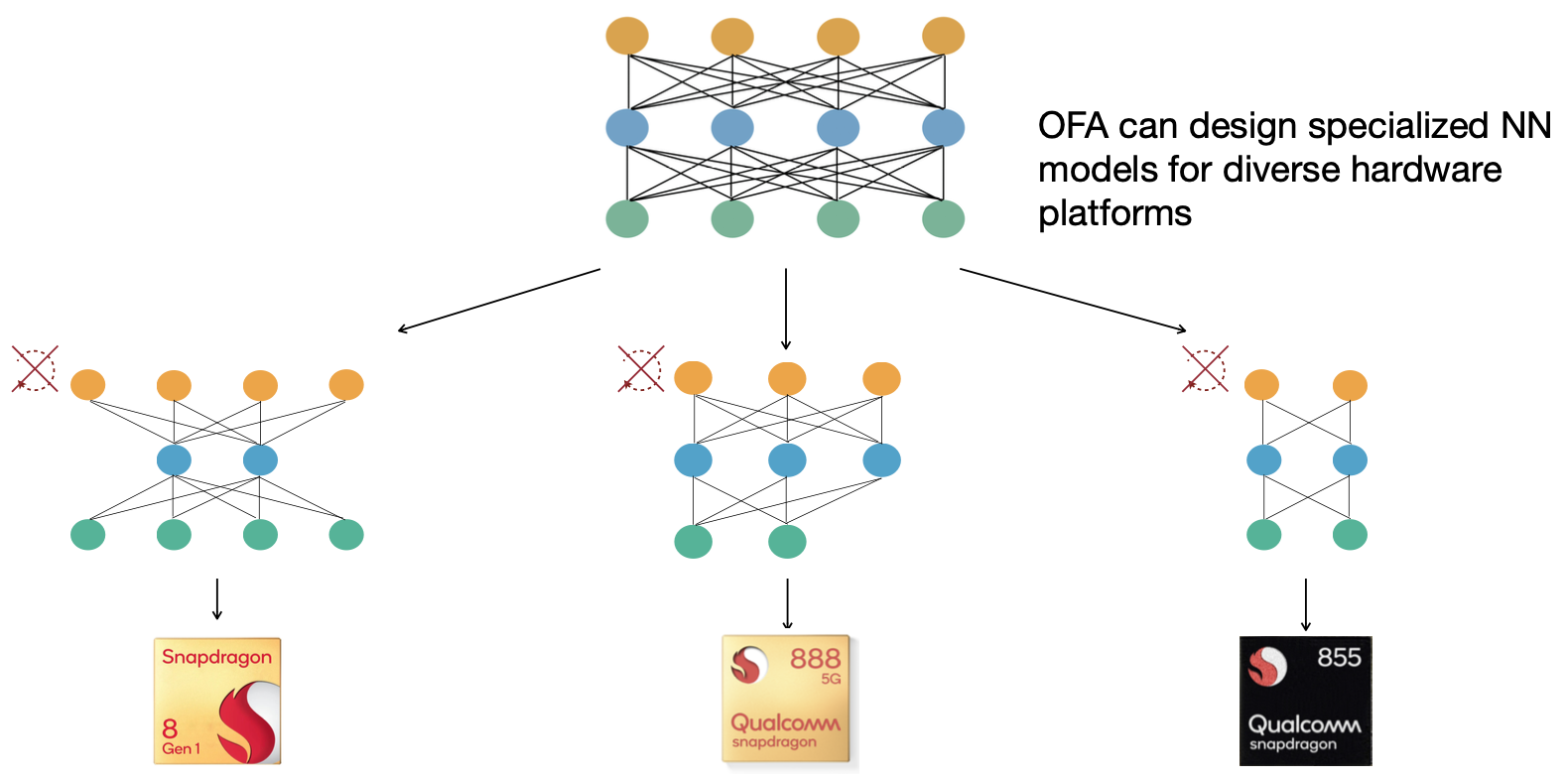
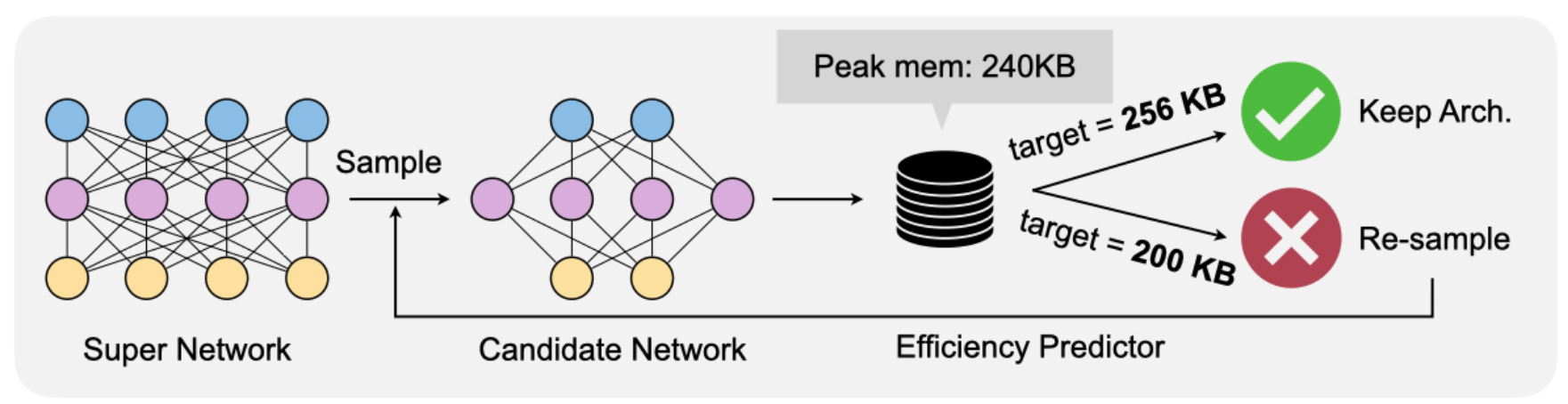
此外,OFA引入了准确率和效率预测器,以进一步降低架构搜索过程中的评估成本。从直观上看,一个子网络的准确性需要在整个保持验证集上运行推理,这在ImageNet上可能需要1分钟左右。而OFA事先收集了大量的(架构,准确率)对,并训练了一个回归模型来预测搜索时的准确率,这大大降低了每个子网络评估准确率的成本,从1分钟降低到1秒以内,这就是准确率预测器。效率预测器也是类似的做法。

问题描述
假设once-for-all network的权重为 W o W_o Wo,架构为 a r c h i arch_i archi,则
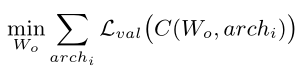
其中
C
(
W
o
,
a
r
c
h
i
)
C(Wo, archi)
C(Wo,archi)表示选择方案,即从网络权重
W
o
W_o
Wo中选择部分,形成具有架构配置
a
r
c
h
i
arch_i
archi的子网络。整体训练目标是优化
W
o
W_o
Wo,使子网络的准确率与单独训练具有相同架构的网络的准确率保持相同水平。
训练 once-for-all network
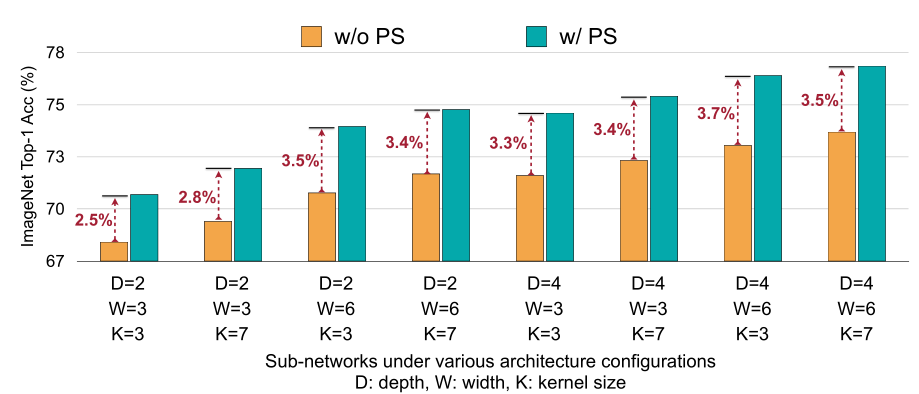
渐进式收缩(Progressive Shrinking, PS),即训练的顺序是从大到小。首先,训练最大的network(resolution, kernel size, depth, width等全设为最大)。接着,对于较小的子网络,它们与较大的子网络共享权重。因此,PS允许用训练良好的大型子网络的最重要权重来初始化小型子网络,这加快了训练过程。

具体来说,在训练了最大的网络后,我们首先支持弹性内核大小,每层可以从{3,5,7}中选择,深度和宽度保持最大值。然后依次支持弹性深度和弹性宽度。在整个训练过程中,分辨率是有弹性的,这是通过对每批训练数据采样不同的图像大小来实现的。此外,在训练最大的神经网络后使用知识蒸馏技术。

弹性卷积核大小 Elastic Kernel Size
从一个7x7卷积核提取中心部分,可以得到一个5x5的核,也可以是一个3x3的核。因此,卷积核大小变得有弹性。但是,对于提取出来的子卷积核,权值可能需要有不同的分布。因此,在共享核权值时,引入卷积核变换矩阵,在不同的layer用不同的变换矩阵,同一层内会share同样的kernel变换矩阵。

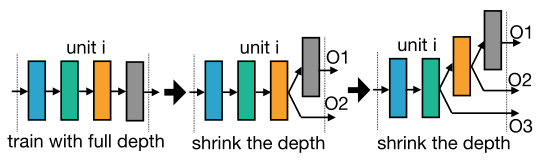
弹性深度 Elastic Depth
和传统NAS差不多,就是保留前D个layer,跳过后面的layer。
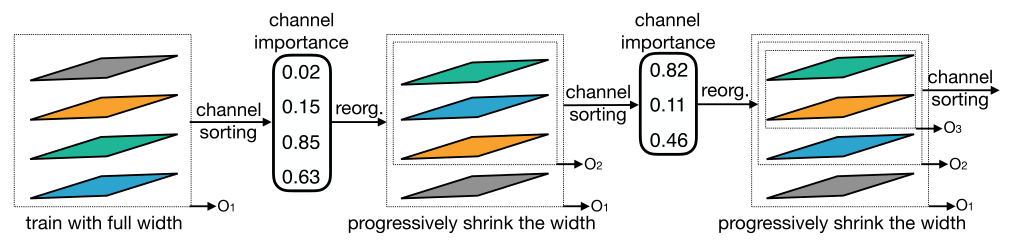
弹性宽度 Elastic Width
宽度是指通道的数量,根据“Channel Importance”来选择最“Important”的几个layer和更小的网络share。基于channel权重的L1范数来计算“importance score”,L1范数越大,越重要。
部署 Deployment
训练完一个once-for-all network后,下一个阶段是为给定的部署场景派生专门的子网络。目标是在优化准确率的同时,搜索得到一个满足目标硬件的效率约束的神经网络。
建立了neural-network-twins模型,预测给定神经网络架构的latency和accuracy,为模型质量提供快速反馈。它通过用预测的latency和accuracy代替测量的latency和accuracy,来消除重复搜索成本。
具体来说,随机采样具有不同架构和不同输入大小 的子网络,然后使用原始训练集中采样的验证图像上测量它们的准确性。此外,在每个目标硬件平台上构建了一个latency lookup table,以预测latency。
部署实现
我们使用MCUNetV2,以OFA的方式训练。MCUNetV2是一个为资源受限的微控制器定制的神经网络。
我们使用VWW数据集,这是一个图像二分类(图像中是否有人物)的数据集,是从Microsoft COCO中取样得到的。

import argparse
import json
from PIL import Image
from tqdm import tqdm
import copy
import math
import numpy as np
import os
import random
import torch
from torch import nn
from torchvision import datasets, transforms
from mcunet.tinynas.search.accuracy_predictor import (
AccuracyDataset,
MCUNetArchEncoder,
)
from mcunet.tinynas.elastic_nn.networks.ofa_mcunets import OFAMCUNets
from mcunet.utils.mcunet_eval_helper import calib_bn, validate
from mcunet.utils.arch_visualization_helper import draw_arch
%matplotlib inline
from matplotlib import pyplot as plt
import warnings
warnings.filterwarnings('ignore')
def build_val_data_loader(data_dir, resolution, batch_size=128, split=0):
# split = 0: real val set, split = 1: holdout validation set
assert split in [0, 1]
normalize = transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
kwargs = {"num_workers": min(8, os.cpu_count()), "pin_memory": False}
val_transform = transforms.Compose(
[
transforms.Resize(
(resolution, resolution)
), # if center crop, the person might be excluded
transforms.ToTensor(),
normalize,
]
)
val_dataset = datasets.ImageFolder(data_dir, transform=val_transform)
val_dataset = torch.utils.data.Subset(
val_dataset, list(range(len(val_dataset)))[split::2]
)
val_loader = torch.utils.data.DataLoader(
val_dataset, batch_size=batch_size, shuffle=False, **kwargs
)
return val_loader
OFAMCUNets超级网络是由MCUNetV2设计空间中的
>
1
0
19
>10^{19}
>1019子网组成。这些子网由具有不同的kernel sizes(3、5、7)和expand ratios(3、4、6)的inverted MobileNet blocks组成。OFA超级网络还允许elastic depths(base depth to base_depth + 2)。最后,超级网络支持global channel scaling(由width_mult_list指定,0.5
×
\times
×、0.75
×
\times
×或1.0
×
\times
×)。我们导入训练好的once-for-all network模型参数,接下来的部分是关于如何部署该网络。
device = "cuda:0"
ofa_network = OFAMCUNets(
n_classes=2,
bn_param=(0.1, 1e-3),
dropout_rate=0.0,
base_stage_width="mcunet384",
width_mult_list=[0.5, 0.75, 1.0],
ks_list=[3, 5, 7],
expand_ratio_list=[3, 4, 6],
depth_list=[0, 1, 2],
base_depth=[1, 2, 2, 2, 2],
fuse_blk1=True,
se_stages=[False, [False, True, True, True], True, True, True, False],
)
ofa_network.load_state_dict(
torch.load("vww_supernet.pth", map_location="cpu")["state_dict"], strict=True
)
ofa_network = ofa_network.to(device)
首先,定义一个辅助函数evaluate_sub_network,测试从超级网络直接提取的子网络的准确率。
from mcunet.utils.pytorch_utils import count_peak_activation_size, count_net_flops, count_parameters
def evaluate_sub_network(ofa_network, cfg, image_size=None):
if "image_size" in cfg:
image_size = cfg["image_size"]
batch_size = 128
# step 1. sample the active subnet with the given config.
ofa_network.set_active_subnet(**cfg)
# step 2. extract the subnet with corresponding weights.
subnet = ofa_network.get_active_subnet().to(device)
# step 3. calculate the efficiency stats of the subnet.
peak_memory = count_peak_activation_size(subnet, (1, 3, image_size, image_size))
macs = count_net_flops(subnet, (1, 3, image_size, image_size))
params = count_parameters(subnet)
# step 4. perform BN parameter re-calibration.
calib_bn(subnet, data_dir, batch_size, image_size)
# step 5. define the validation dataloader.
val_loader = build_val_data_loader(data_dir, image_size, batch_size)
# step 6. validate the accuracy.
acc = validate(subnet, val_loader)
return acc, peak_memory, macs, params
def visualize_subnet(cfg):
draw_arch(cfg["ks"], cfg["e"], cfg["d"], cfg["image_size"], out_name="viz/subnet")
im = Image.open("viz/subnet.png")
im = im.rotate(90, expand=1)
fig = plt.figure(figsize=(im.size[0] / 250, im.size[1] / 250))
plt.axis("off")
plt.imshow(im)
plt.show()
现在,让我们将一些子网可视化,并在VWW数据集上对其进行评估!
请注意,我们假设图像的分辨率固定为96。你可以随意修改分辨率的大小,探索输入分辨率的作用。同样的,你可以改变sample_function方法的参数sample_active_subnet来控制采样过程。
image_size = 96
cfg = ofa_network.sample_active_subnet(sample_function=random.choice, image_size=image_size)
acc, _, _, params = evaluate_sub_network(ofa_network, cfg)
visualize_subnet(cfg)
print(f"The accuracy of the sampled subnet: #params={params/1e6: .1f}M, accuracy={acc: .1f}%.")
largest_cfg = ofa_network.sample_active_subnet(sample_function=max, image_size=image_size)
acc, _, _, params = evaluate_sub_network(ofa_network, largest_cfg)
visualize_subnet(largest_cfg)
print(f"The largest subnet: #params={params/1e6: .1f}M, accuracy={acc: .1f}%.")
smallest_cfg = ofa_network.sample_active_subnet(sample_function=min, image_size=image_size)
acc, peak_memory, macs, params = evaluate_sub_network(ofa_network, smallest_cfg)
visualize_subnet(smallest_cfg)
print(f"The smallest subnet: #params={params/1e6: .1f}M, accuracy={acc: .1f}%.")



efficiency predictor
对于效率预测器,我们构建一个hook-based analytical model,来计算给定网络的#MACs和peak memory consumption。
具体来说,我们定义一个名为 "分析性效率预测器 "的类。这个类中有两个主要的函数:get_efficiency和satisfy_constraint。get_efficiency接收subnet configuration并返回给定子网的#MACs和peak memory consumption。这里,我们假设#MACs的单位是百万,peak memory consumption的单位是KB。我们用count_net_flops来获得网络的#MACs,用count_peak_activation_size来获得activation size of the network。
class AnalyticalEfficiencyPredictor:
def __init__(self, net):
self.net = net
def get_efficiency(self, spec: dict):
self.net.set_active_subnet(**spec)
subnet = self.net.get_active_subnet()
if torch.cuda.is_available():
subnet = subnet.cuda()
data_shape = (1, 3, spec["image_size"], spec["image_size"])
macs = count_net_flops(subnet, data_shape)
peak_memory = count_peak_activation_size(subnet, data_shape)
return dict(millionMACs=macs / 1e6, KBPeakMemory=peak_memory / 1024)
def satisfy_constraint(self, measured: dict, target: dict):
for key in measured:
# if the constraint is not specified, we just continue
if key not in target:
continue
# if we exceed the constraint, just return false.
if measured[key] > target[key]:
return False
# no constraint violated, return true.
return True
efficiency_predictor = AnalyticalEfficiencyPredictor(ofa_network)
image_size = 96
# Print out the efficiency of the smallest subnet.
smallest_cfg = ofa_network.sample_active_subnet(sample_function=min, image_size=image_size)
eff_smallest = efficiency_predictor.get_efficiency(smallest_cfg)
# Print out the efficiency of the largest subnet.
largest_cfg = ofa_network.sample_active_subnet(sample_function=max, image_size=image_size)
eff_largest = efficiency_predictor.get_efficiency(largest_cfg)
print("Efficiency stats of the smallest subnet:", eff_smallest)
print("Efficiency stats of the largest subnet:", eff_largest)

accuracy predictor
由于accuracy predictor是一个MLP, sub-network必须被编码成一个的vector。我们使用MCUNetArchEncoder,来进行从sub-network architecture到binary vector的转换。
image_size_list = [96, 112, 128, 144, 160]
arch_encoder = MCUNetArchEncoder(
image_size_list=image_size_list,
base_depth=ofa_network.base_depth,
depth_list=ofa_network.depth_list,
expand_list=ofa_network.expand_ratio_list,
width_mult_list=ofa_network.width_mult_list,
)
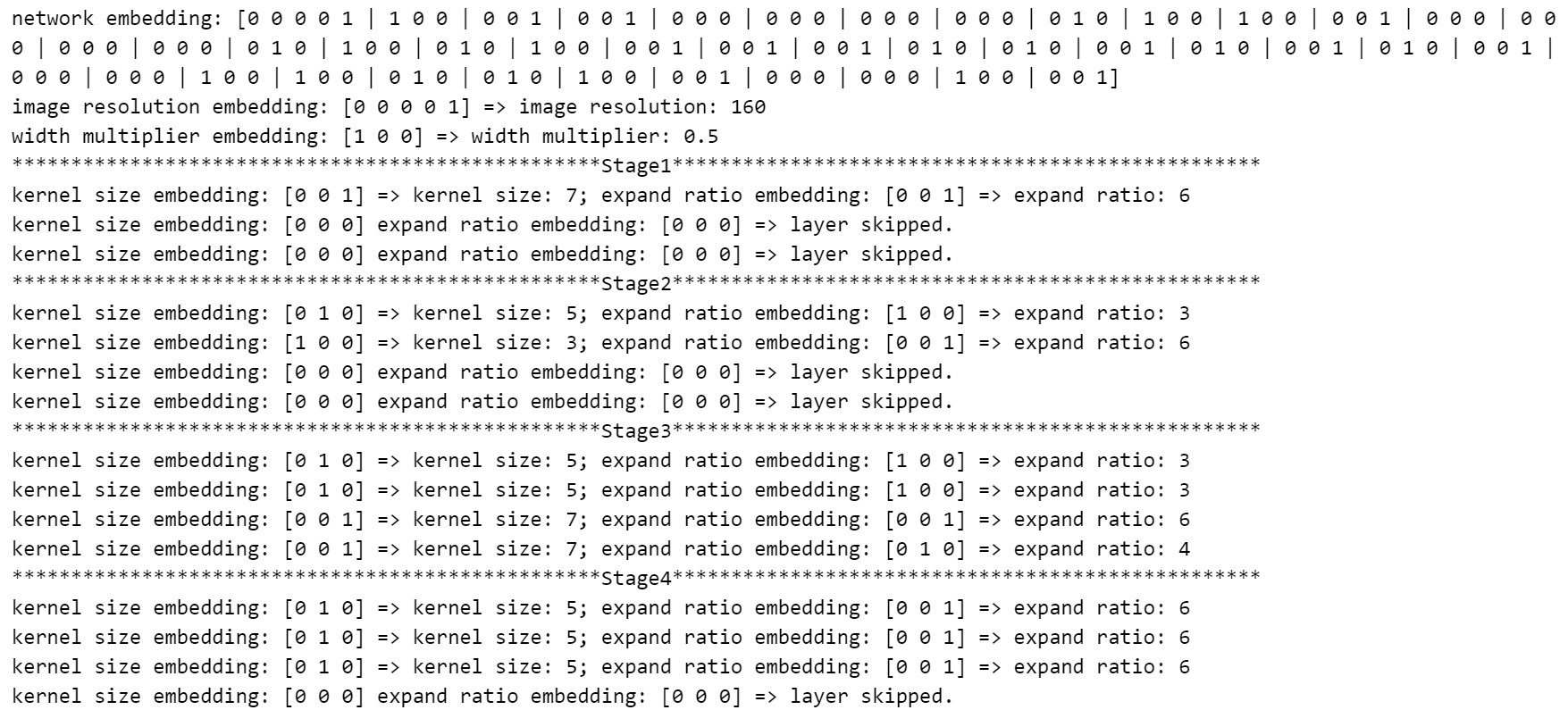
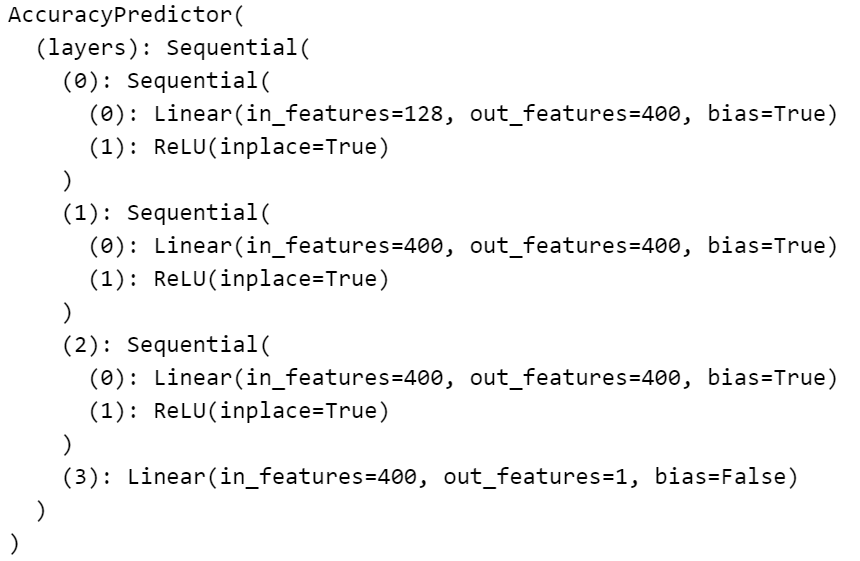
这是一个多层感知(MLP)网络,输入层为(arch_encoder.n_dim, hidden_size),每个中间层为(hidden_size, hidden_size),输出层为(hidden_size, 1)。为了简单起见,我们将层数固定为3。
class AccuracyPredictor(nn.Module):
def __init__(
self,
arch_encoder,
hidden_size=400,
n_layers=3,
checkpoint_path=None,
device="cuda:0",
):
super(AccuracyPredictor, self).__init__()
self.arch_encoder = arch_encoder
self.hidden_size = hidden_size
self.n_layers = n_layers
self.device = device
layers = []
# Let's build an MLP with n_layers layers.
# Each layer (nn.Linear) has hidden_size channels and
# uses nn.ReLU as the activation function.
for i in range(self.n_layers):
layers.append(
nn.Sequential(
nn.Linear(
self.arch_encoder.n_dim if i == 0 else self.hidden_size,
self.hidden_size,
),
nn.ReLU(inplace=True),
)
)
layers.append(nn.Linear(self.hidden_size, 1, bias=False))
self.layers = nn.Sequential(*layers)
self.base_acc = nn.Parameter(
torch.zeros(1, device=self.device), requires_grad=False
)
if checkpoint_path is not None and os.path.exists(checkpoint_path):
checkpoint = torch.load(checkpoint_path, map_location="cpu")
if "state_dict" in checkpoint:
checkpoint = checkpoint["state_dict"]
self.load_state_dict(checkpoint)
print("Loaded checkpoint from %s" % checkpoint_path)
self.layers = self.layers.to(self.device)
def forward(self, x):
y = self.layers(x).squeeze()
return y + self.base_acc
def predict_acc(self, arch_dict_list):
X = [self.arch_encoder.arch2feature(arch_dict) for arch_dict in arch_dict_list]
X = torch.tensor(np.array(X)).float().to(self.device)
return self.forward(X)
os.makedirs("pretrained", exist_ok=True)
acc_pred_checkpoint_path = (
f"pretrained/{ofa_network.__class__.__name__}_acc_predictor.pth"
)
acc_predictor = AccuracyPredictor(
arch_encoder,
hidden_size=400,
n_layers=3,
checkpoint_path=None,
device=device,
)
print(acc_predictor)
训练accuracy predictor
acc_dataset = AccuracyDataset("acc_datasets")
train_loader, valid_loader, base_acc = acc_dataset.build_acc_data_loader(
arch_encoder=arch_encoder
)
print(f"The basic accuracy (mean accuracy of all subnets within the dataset is: {(base_acc * 100): .1f}%.")
criterion = torch.nn.L1Loss().to(device)
optimizer = torch.optim.Adam(acc_predictor.parameters())
# the default value is zero
acc_predictor.base_acc.data += base_acc
for epoch in tqdm(range(10)):
acc_predictor.train()
for (data, label) in tqdm(train_loader, desc="Epoch%d" % (epoch + 1), position=0, leave=True):
# step 1. Move the data and labels to device (cuda:0).
data = data.to(device)
label = label.to(device)
# step 2. Run forward pass.
pred = acc_predictor(data)
# step 3. Calculate the loss.
loss = criterion(pred, label)
# step 4. Perform the backward pass.
optimizer.zero_grad()
loss.backward()
optimizer.step()
acc_predictor.eval()
with torch.no_grad():
with tqdm(total=len(valid_loader), desc="Val", position=0, leave=True) as t:
for (data, label) in valid_loader:
# step 1. Move the data and labels to device (cuda:0).
data = data.to(device)
label = label.to(device)
# step 2. Run forward pass.
pred = acc_predictor(data)
# step 3. Calculate the loss.
loss = criterion(pred, label)
t.set_postfix({"loss": loss.item()})
t.update(1)
if not os.path.exists(acc_pred_checkpoint_path):
torch.save(acc_predictor.cpu().state_dict(), acc_pred_checkpoint_path)
在验证集上评估accuracy predictor
predicted_accuracies = []
ground_truth_accuracies = []
acc_predictor = acc_predictor.to("cuda:0")
acc_predictor.eval()
with torch.no_grad():
with tqdm(total=len(valid_loader), desc="Val") as t:
for (data, label) in valid_loader:
data = data.to(device)
label = label.to(device)
pred = acc_predictor(data)
predicted_accuracies += pred.cpu().numpy().tolist()
ground_truth_accuracies += label.cpu().numpy().tolist()
if len(predicted_accuracies) > 200:
break
plt.scatter(predicted_accuracies, ground_truth_accuracies)
# draw y = x
min_acc, max_acc = min(predicted_accuracies), max(predicted_accuracies)
plt.plot([min_acc, max_acc], [min_acc, max_acc], c="red", linewidth=2)
plt.xlabel("Predicted accuracy")
plt.ylabel("Measured accuracy")
plt.title("Correlation between predicted accuracy and real accuracy")

Neural Architecture Search
Random Searcher
class RandomSearcher:
def __init__(self, efficiency_predictor, accuracy_predictor):
self.efficiency_predictor = efficiency_predictor
self.accuracy_predictor = accuracy_predictor
def random_valid_sample(self, constraint):
# randomly sample subnets until finding one that satisfies the constraint
while True:
sample = self.accuracy_predictor.arch_encoder.random_sample_arch()
efficiency = self.efficiency_predictor.get_efficiency(sample)
if self.efficiency_predictor.satisfy_constraint(efficiency, constraint):
return sample, efficiency
def run_search(self, constraint, n_subnets=100):
subnet_pool = []
# sample subnets
for _ in tqdm(range(n_subnets)):
sample, efficiency = self.random_valid_sample(constraint)
subnet_pool.append(sample)
# predict the accuracy of subnets
accs = self.accuracy_predictor.predict_acc(subnet_pool)
# get the index of the best subnet
best_idx = accs.argmax()
# return the best subnet
return accs[best_idx], subnet_pool[best_idx]
def search_and_measure_acc(agent, constraint, **kwargs):
# call the search function
best_info = agent.run_search(constraint=constraint, **kwargs)
# get searched subnet
ofa_network.set_active_subnet(**best_info[1])
subnet = ofa_network.get_active_subnet().to(device)
# calibrate bn
calib_bn(subnet, data_dir, 128, best_info[1]["image_size"])
# build val loader
val_loader = build_val_data_loader(data_dir, best_info[1]["image_size"], 128)
# measure accuracy
acc = validate(subnet, val_loader)
# print best_info
print(f"Accuracy of the selected subnet: {acc}")
# visualize model architecture
visualize_subnet(best_info[1])
return acc, subnet
random.seed(1)
np.random.seed(1)
nas_agent = RandomSearcher(efficiency_predictor, acc_predictor)
# MACs-constrained search
subnets_rs_macs = {}
for millonMACs in [50, 100]:
search_constraint = dict(millonMACs=millonMACs)
print(f"Random search with constraint: MACs <= {millonMACs}M")
subnets_rs_macs[millonMACs] = search_and_measure_acc(nas_agent, search_constraint, n_subnets=300)
# memory-constrained search
subnets_rs_memory = {}
for KBPeakMemory in [256, 512]:
search_constraint = dict(KBPeakMemory=KBPeakMemory)
print(f"Random search with constraint: Peak memory <= {KBPeakMemory}KB")
subnets_rs_memory[KBPeakMemory] = search_and_measure_acc(nas_agent, search_constraint, n_subnets=300)


Evolution Searcher

class EvolutionSearcher:
def __init__(self, efficiency_predictor, accuracy_predictor, **kwargs):
self.efficiency_predictor = efficiency_predictor
self.accuracy_predictor = accuracy_predictor
# evolution hyper-parameters
self.arch_mutate_prob = kwargs.get("arch_mutate_prob", 0.1)
self.resolution_mutate_prob = kwargs.get("resolution_mutate_prob", 0.5)
self.population_size = kwargs.get("population_size", 100)
self.max_time_budget = kwargs.get("max_time_budget", 500)
self.parent_ratio = kwargs.get("parent_ratio", 0.25)
self.mutation_ratio = kwargs.get("mutation_ratio", 0.5)
def update_hyper_params(self, new_param_dict):
self.__dict__.update(new_param_dict)
def random_valid_sample(self, constraint):
# randomly sample subnets until finding one that satisfies the constraint
while True:
sample = self.accuracy_predictor.arch_encoder.random_sample_arch()
efficiency = self.efficiency_predictor.get_efficiency(sample)
if self.efficiency_predictor.satisfy_constraint(efficiency, constraint):
return sample, efficiency
def mutate_sample(self, sample, constraint):
while True:
new_sample = copy.deepcopy(sample)
self.accuracy_predictor.arch_encoder.mutate_resolution(new_sample, self.resolution_mutate_prob)
self.accuracy_predictor.arch_encoder.mutate_width(new_sample, self.arch_mutate_prob)
self.accuracy_predictor.arch_encoder.mutate_arch(new_sample, self.arch_mutate_prob)
efficiency = self.efficiency_predictor.get_efficiency(new_sample)
if self.efficiency_predictor.satisfy_constraint(efficiency, constraint):
return new_sample, efficiency
def crossover_sample(self, sample1, sample2, constraint):
while True:
new_sample = copy.deepcopy(sample1)
for key in new_sample.keys():
if not isinstance(new_sample[key], list):
# randomly choose the value from sample1[key] and sample2[key], random.choice
new_sample[key] = random.choice([sample1[key], sample2[key]])
else:
for i in range(len(new_sample[key])):
new_sample[key][i] = random.choice([sample1[key][i], sample2[key][i]])
efficiency = self.efficiency_predictor.get_efficiency(new_sample)
if self.efficiency_predictor.satisfy_constraint(efficiency, constraint):
return new_sample, efficiency
def run_search(self, constraint, **kwargs):
self.update_hyper_params(kwargs)
mutation_numbers = int(round(self.mutation_ratio * self.population_size))
parents_size = int(round(self.parent_ratio * self.population_size))
best_valids = [-100]
population = [] # (acc, sample) tuples
child_pool = []
best_info = None
# generate random population
for _ in range(self.population_size):
sample, efficiency = self.random_valid_sample(constraint)
child_pool.append(sample)
accs = self.accuracy_predictor.predict_acc(child_pool)
for i in range(self.population_size):
population.append((accs[i].item(), child_pool[i]))
# evolving the population
with tqdm(total=self.max_time_budget) as t:
for i in range(self.max_time_budget):
# sort the population according to the acc (descending order)
population = sorted(population, key=lambda x: x[0], reverse=True)
# keep topK samples in the population, K = parents_size
# the others are discarded.
population = population[:parents_size]
# update best info
acc = population[0][0]
if acc > best_valids[-1]:
best_valids.append(acc)
best_info = population[0]
else:
best_valids.append(best_valids[-1])
child_pool = []
for j in range(mutation_numbers):
# randomly choose a sample
par_sample = population[np.random.randint(parents_size)][1]
# mutate this sample
new_sample, efficiency = self.mutate_sample(par_sample, constraint)
child_pool.append(new_sample)
for j in range(self.population_size - mutation_numbers):
# randomly choose two samples
par_sample1 = population[np.random.randint(parents_size)][1]
par_sample2 = population[np.random.randint(parents_size)][1]
# crossover
new_sample, efficiency = self.crossover_sample(
par_sample1, par_sample2, constraint
)
child_pool.append(new_sample)
# predict accuracy with the accuracy predictor
accs = self.accuracy_predictor.predict_acc(child_pool)
for j in range(self.population_size):
population.append((accs[j].item(), child_pool[j]))
t.update(1)
return best_info
random.seed(1)
np.random.seed(1)
evo_params = {
'arch_mutate_prob': 0.1, # The probability of architecture mutation in evolutionary search
'resolution_mutate_prob': 0.1, # The probability of resolution mutation in evolutionary search
'population_size': 10, # The size of the population
'max_time_budget': 10,
'parent_ratio': 0.1,
'mutation_ratio': 0.1,
}
nas_agent = EvolutionSearcher(efficiency_predictor, acc_predictor, **evo_params)
# MACs-constrained search
subnets_evo_macs = {}
for millonMACs in [50, 100]:
search_constraint = dict(millionMACs=millonMACs)
print(f"Evolutionary search with constraint: MACs <= {millonMACs}M")
subnets_evo_macs[millonMACs] = search_and_measure_acc(nas_agent, search_constraint)
# memory-constrained search
subnets_evo_memory = {}
for KBPeakMemory in [256, 512]:
search_constraint = dict(KBPeakMemory=KBPeakMemory)
print(f"Evolutionary search with constraint: Peak memory <= {KBPeakMemory}KB")
subnets_evo_memory[KBPeakMemory] = search_and_measure_acc(nas_agent, search_constraint)


根据实际需求来使用进化搜索
250 KB, 60M MACs
random.seed(1)
np.random.seed(1)
evo_params = {
'arch_mutate_prob': 0.1, # The probability of architecture mutation in evolutionary search
'resolution_mutate_prob': 0.5, # The probability of resolution mutation in evolutionary search
'population_size': 50, # The size of the population
'max_time_budget': 20,
'parent_ratio': 0.25,
'mutation_ratio': 0.3,
}
nas_agent = EvolutionSearcher(efficiency_predictor, acc_predictor, **evo_params)
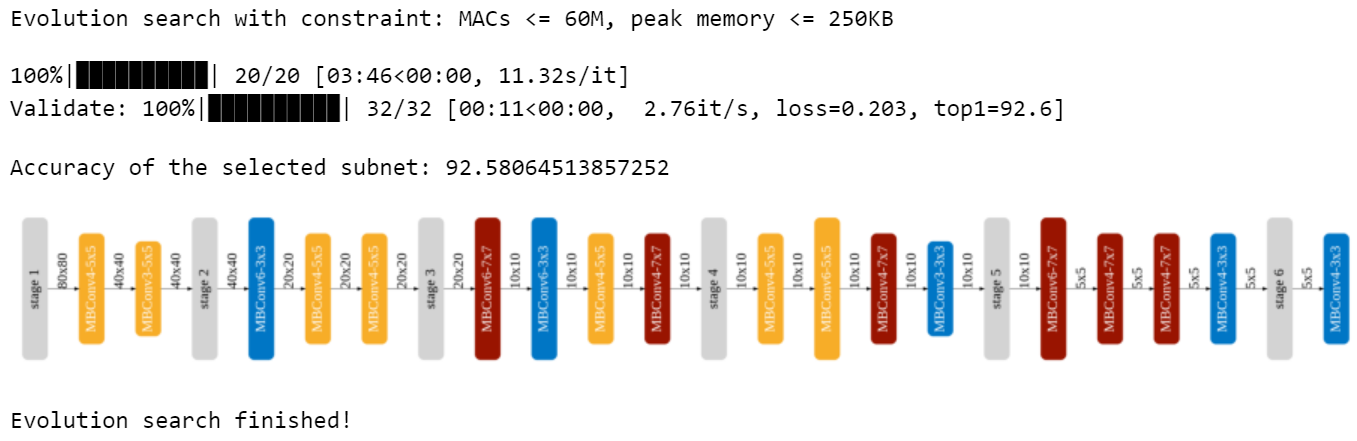
(millionMACs, KBPeakMemory) = [60, 250]
print(f"Evolution search with constraint: MACs <= {millionMACs}M, peak memory <= {KBPeakMemory}KB")
search_and_measure_acc(nas_agent, dict(millionMACs=millionMACs, KBPeakMemory=KBPeakMemory))
print("Evolution search finished!")
















 343
343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









