







2025年广东省职业院校技能大赛“大数据应用与服务”竞赛样题二解析
文章目录
大数据应用与服务交流:982262433
一、背景描述
大数据时代背景下,教育行业正在经历深刻的变革。在传统教育模式中,教学过程往往依赖教师的经验判断,缺乏对学习者行为的深入理解和精准分析。而在线教育平台的兴起,为教育领域带来了全新的可能。通过收集和分析学习者在平台上的行为数据,如课程选择、学习进度、作业完成情况、互动参与度等,可以更准确地把握学习者的需求和学习特点。平台能够根据用户的学习轨迹、知识掌握程度、学习时长等数据,建立个性化的学习档案,为每位学习者提供更有针对性的课程推荐和学习建议。
因数据驱动的大数据时代已经到来,在线教育平台需要通过数据分析来提供更优质的教育服务。为完成在线教育平台的大数据分析工作,你所在的小组将应用大数据技术,通过Python语言以数据采集为基础,将采集的数据进行相应处理,并且进行数据标注、数据分析与可视化、通过大数据业务分析方法实现相应数据分析。运行维护数据库系统保障存储数据的安全性。通过运用相关大数据工具软件解决具体业务问题。你们作为该小组的技术人员,请按照下面任务完成本次工作。
二、模块一:平台搭建与运维
(一)任务一:大数据平台搭建
1.子任务一:基础环境准备
本任务需要使用 root 用户完成相关配置,安装 Hadoop 需要配置前置环境。命令中要求使用绝对路径,具体要求如下:
(1)配置三个节点的主机名,分别为 master、slave1、slave2,然后修改三个节点的 hosts 文件,使得三个节点之间可以通过主机名访问,在 master上将执行命令 cat /etc/hosts 的结果复制并粘贴至【提交结果.docx】中对应的任务序号下;

(3)将 /opt/software 目录下将文件 jdk-8u191-linux-x64.tar.gz 安装包解压到 /opt/module 路径中,将 JDK 解压命令复制并粘贴至【提交结果.docx】中对应的任务序号下;

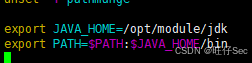
(3)在 /etc/profile 文件中配置 JDK 环境变量 JAVA_HOME 和 PATH 的值,并让配置文件立即生效,将在 master上 /etc/profile 中新增的内容复制并粘贴至【提交结果.docx】中对应的任务序号下;
(5)查看 JDK 版本,检测 JDK 是否安装成功,在 master 上将执行命令java -version 的结果复制并粘贴至【提交结果.docx】中对应的任务序号下;

(5)创建 hadoop 用户并设置密码,为 hadoop 用户添加管理员权限。在 master 上将执行命令 grep ‘hadoop’ /etc/sudoers 的结果复制并粘贴至【提交结果.docx】中对应的任务序号下;
添加以下新增用户命令配置
Useradd hadoop #新增Hadoop用户
Passwd hadoop #给Hadoop用户设置密码

(6)关闭防火墙,设置开机不自动启动防火墙,在 master 上将执行命令 systemctl status firewalld 的结果复制并粘贴至【提交结果.docx】中对应的任务序号下;

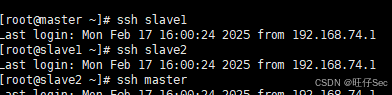
(7)配置三个节点的 SSH 免密登录,在 master 上通过 SSH 连接 slave1 和 slave2 来验证。
2.子任务二:Hadoop 完全分布式安装配置
本任务需要使用 root 用户和 hadoop 用户完成相关配置,使用三个节点完成 Hadoop 完全分布式安装配置。命令中要求使用绝对路径,具体要求如下:
(1)在 master 节点中的 /opt/software 目录下将文件 hadoop-3.3.6.tar.gz 安装包解压到 /opt/module 路径中,将 hadoop 安装包解压命令复制并粘贴至【提交结果.docx】中对应的任务序号下;

(2)在 master 节点中将解压的 Hadoop 安装目录重命名为 hadoop,并修改该目录下的所有文件的所属者为 hadoop,所属组为 hadoop,将修改所属者的完整命令复制并粘贴至【提交结果.docx】中对应的任务序号下;

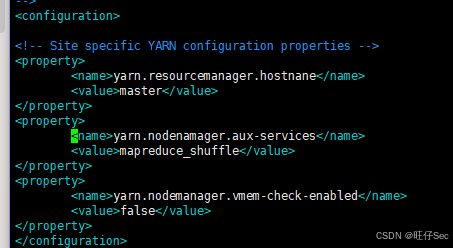
(3)在 master 节点中使用 hadoop 用户依次配置 hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、masters 和 workers 配置文件,Hadoop集群部署规划如下表,将 yarn-site.xml 文件内容复制并粘贴至【提交结果.docx】中对应的任务序号下;
| *服务器* | *master* | *slave1* | *slave2* |
|---|---|---|---|
| HDFS | NameNode | ||
| HDFS | SecondaryNameNode | ||
| HDFS | DataNode | DataNode | DataNode |
| YARN | ResourceManager | ||
| YARN | NodeManager | NodeManager | NodeManager |
| 历史日志服务器 | JobHistoryServer |
(3)在 master 节点中使用 scp 命令将配置完的 hadoop 安装目录直接拷贝至 slave1 和 slave2 节点,将完整的 scp 命令复制并粘贴至【提交结果.docx】中对应的任务序号下;


(4)在 slave1 和 slave2 节点中将 hadoop 安装目录的所有文件的所属者为 hadoop,所属组为 hadoop。


(5)在三个节点的 /etc/profile 文件中配置 Hadoop 环境变量 HADOOP_HOME 和 PATH 的值,并让配置文件立即生效,将 master 节点中 /etc/profile 文件新增的内容复制并粘贴至【提交结果.docx】中对应的任务序号下;

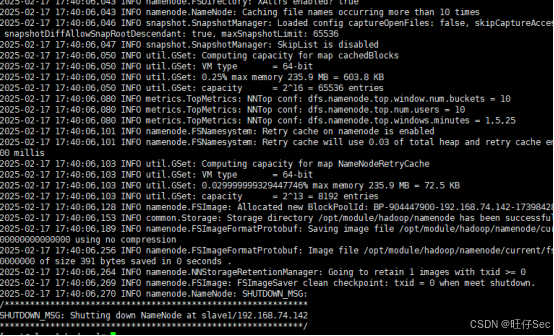
(6) 在 master 节点中初始化 Hadoop 环境 namenode,将初始化命令及初始化结果(截取初始化结果日志最后 20 行即可)粘贴至【提交结果.docx】中对应的任务序号下
(7)在 master 节点中依次启动HDFS、YARN集群和历史服务。在 master 上将执行命令 jps 的结果复制并粘贴至【提交结果.docx】中对应的任务序号下;
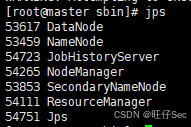
(8)在 slave1 查看 Java 进程情况。在 slave1上将执行命令 jps 的结果复制并粘贴至【提交结果.docx】中对应的任务序号下。
(二)任务二:数据库服务器的安装与运维
- 子任务一:MySQL 安装配置
本任务需要使用 rpm 工具安装 MySQL 并初始化,具体要求如下:
(1)在 master 节点中的 /opt/software 目录下将 MySQL 5.7.44 安装包解压到 /opt/module 目录下;
(2)在 master 节点中使用 rpm -ivh 安装 mysql-community-common、mysql-community-libs、mysql-community-libs-compat、mysql-community-client 和 mysql-community-server 包,将所有命令复制粘贴至【提交结果.docx】中对应的任务序号下;
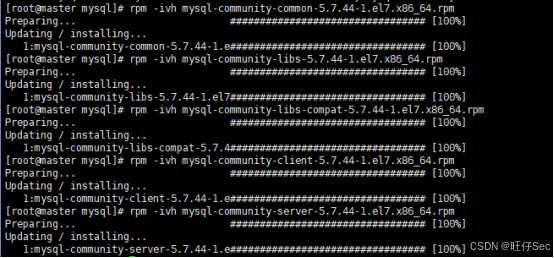
(3)在 master 节点中启动数据库系统并初始化 MySQL 数据库系统,将完整命令复制粘贴至【提交结果.docx】中对应的任务序号下。

密码是mysql_secure_installation中设置的密码 - 子任务二:MySQL 运维
本任务需要在成功安装 MySQL 的前提下,对 MySQL 进行运维操作,具体要求如下:
(1)配置服务端 MySQL 数据库的远程连接,将新增的配置内容复制粘贴至【提交结果.docx】中对应的任务序号下;

(2)配置 root 用户允许任意 IP 连接,将完整命令复制粘贴至【提交结果.docx】中对应的任务序号下;
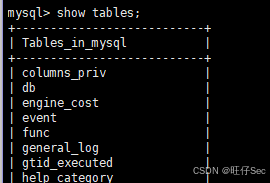
(3)通过 root 用户登录 MySQL 数据库系统,查看 mysql 库下的所有表,将完整命令及执行命令后的结果复制粘贴至【提交结果.docx】中对应的任务序号下;
(4)创建新用户 eduadmin 并设置密码,将完整命令及执行命令后的结果复制粘贴至【提交结果.docx】中对应的任务序号下;

(5)创建数据库 education 并设置正确的字符集,将完整命令及执行命令后的结果复制粘贴至【提交结果.docx】中对应的任务序号下;

(6)授予 eduadmin 用户对学习数据库的查询权限,将完整命令及执行命令后的结果复制粘贴至【提交结果.docx】中对应的任务序号下;

(7)刷新权限,将完整命令及执行命令后的结果复制粘贴至【提交结果.docx】中对应的任务序号下。

- 子任务三:数据表的创建及维护
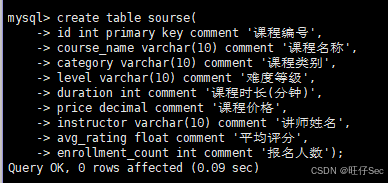
(1)根据以下数据字段在 education 数据库中创建课程表(course)。课程表字段如下:
| 字段 | 类型 | 中文含义 | 备注 |
|---|---|---|---|
| id | int | 课程编号 | 主键 |
| course_name | varchar | 课程名称 | |
| category | varchar | 课程类别 | |
| level | varchar | 难度等级 | |
| duration | int | 课程时长(分钟) | |
| price | decimal | 课程价格 | |
| instructor | varchar | 讲师姓名 | |
| avg_rating | float | 平均评分 | |
| enrollment_count | int | 报名人数 |
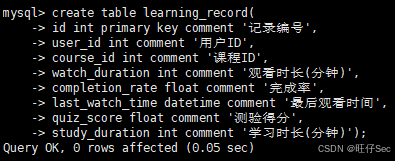
(2)根据以下数据字段在 education 数据库中创建学习记录表(learning_record)。学习记录表字段如下:
| 字段 | 类型 | 中文含义 | 备注 |
|---|---|---|---|
| id | int | 记录编号 | 主键 |
| user_id | int | 用户ID | |
| course_id | int | 课程ID | |
| watch_duration | int | 观看时长(分钟) | |
| completion_rate | float | 完成率 | |
| last_watch_time | datetime | 最后观看时间 | |
| quiz_score | float | 测验得分 | |
| study_duration | int | 学习时长(分钟) |
将这两个 SQL 建表语句分别复制粘贴至【提交结果.docx】中对应的任务序号下。
(3)编写下列 SQL 查询语句:
·查询每门课程的平均完成率
·统计每个课程类别的总报名人数
·查找观看时长超过课程时长的学习记录
将这三个 SQL 语句分别复制粘贴至【提交结果.docx】中对应的任务序号下。
三、模块二:数据获取与处理
(一)任务一:数据获取与清洗
- 子任务一:数据获取
有一份在线教育平台学习数据集:用户ID、课程ID、课程名称、课程类别、学习时长(分钟)、完成进度、最后学习时间、测验成绩、互动次数、设备类型、学习时段。
该数据已存入到 learning_data.csv 文件中,请使用 pandas 读取 learning_data.csv 并将数据集的前10行打印在 IDE 终端的截图复制粘贴至【提交结果.docx】中对应的任务序号下。 - 子任务二:使用 Python 进行数据清洗
现已从在线教育平台获取到原始数据集,为保障用户隐私和数据安全,已进行数据脱敏处理。数据脱敏是指对某些敏感信息通过脱敏规则进行数据的变形,实现敏感隐私数据的可靠保护。
请使用 pandas 库加载并分析相关数据集,根据题目规定要求使用 pandas 库实现数据处理,具体要求如下:
(1)删除学习时长为空或为0的记录,并将结果存储为 cleaned_data_c1_N.csv,N 为删除的数据条数;
(2)删除测验成绩异常(大于100分或小于0分)的记录,并将结果存储为 cleaned_data_c2_N.csv,N 为删除的数据条数;
(3)将最后学习时间格式不规范的记录进行标准化处理,并存储为 cleaned_data_c3_N.csv,N 为修改的数据条数;
(4)将完成进度超过100%的记录设置为100%,并将结果存储为 cleaned_data_c4_N.csv,N 为修改的数据条数;
(5)删除重复的学习记录,将结果存储为 cleaned_data_c5_N.csv,N 为删除的数据条数;
将该 5 个文件名截图复制粘贴至【提交结果.docx】中对应的任务序号下。
(二)任务二:数据标注
- 子任务一:学习投入度标注
使用 Python 编写脚本,根据学习时长和互动次数对学习者进行投入度分类标注。具体的分类要求如下:
(1)高度投入:每次学习时长超过60分钟且互动次数大于5次;
(2)中度投入:每次学习时长在30-60分钟之间或互动次数在3-5次之间;
(3)低度投入:每次学习时长低于30分钟且互动次数少于3次;
在数据集中新增一列"学习投入度",根据上述标准对每条学习记录进行标注,存入 engagement_level.csv 文件中。具体格式如下:
| 记录ID | 课程名称 | 学习时长(分钟) | 互动次数 | 学习投入度 |
|---|---|---|---|---|
| 1 | Python基础 | 75 | 8 | 高度投入 |
将 engagement_level.csv 打开后直接截图(不用下拉)复制粘贴至【提交结果.docx】中对应的任务序号下。
2. 子任务二:学习模式标注
使用 Python 编写脚本,根据学习时段和设备使用情况对学习者的学习模式进行标注。具体的分类要求如下:
(1)工作学习型:主要在工作日9:00-18:00期间使用PC端学习;
(2)碎片学习型:主要使用移动设备,单次学习时长较短(小于30分钟),分布在全天各个时段;
(3)夜间学习型:主要在20:00-24:00期间进行学习,设备类型不限;
(4)周末集中型:主要在周末进行长时间(超过2小时)的学习,设备类型不限;
在数据集中新增一列"学习模式",根据上述标准对每个用户的学习行为进行模式标注,存入 learning_pattern.csv 文件中。具体格式如下:
| 用户ID | 主要学习时段 | 常用设备 | 平均单次时长 | 学习模式 |
|---|---|---|---|---|
| 1001 | 21:00-23:00 | PC端 | 90分钟 | 夜间学习型 |
将 learning_pattern.csv 打开后直接截图(不用下拉)复制粘贴至【提交结果.docx】中对应的任务序号下。
(三)任务三:数据统计
- 子任务一:HDFS 文件操作
本任务需要使用 Hadoop、HDFS 命令,已安装 Hadoop 及需要配置前置环境,具体要求如下:
(1)在 HDFS 目录下新建目录 /education_data,将新建目录的完整命令粘贴至【提交结果.docx】中对应的任务序号下;
(2)修改权限,赋予目录 /education_data 最高 777 权限,将修改目录权限的完整命令粘贴至【提交结果.docx】对应的任务序号下;
(3)将本地的学习数据文件上传至 HDFS 的 /education_data 目录下,将完整命令粘贴至【提交结果.docx】中对应的任务序号下。 - 子任务二:计算输入文件中的单词数
本任务需要使用 Hadoop 默认提供的 wordcount 示例来完成课程评论的词频统计任务,具体要求如下:
(1)在 HDFS 上创建 /user/hadoop/comments 目录;
(2)将课程评论数据文件上传到 HDFS 的 /user/hadoop/comments 目录下;
(3)使用 Hadoop 中提供的 wordcount 示例对评论文本进行词频统计,并将统计结果存储到 HDFS 的 /user/hadoop/comment_stats 目录下;
(4)查看统计结果并将结果前十行截图粘贴至【提交结果.docx】中对应的任务序号下。 - 子任务三:学习行为分析
本任务需要使用 MapReduce 编程模型完成对学习者行为模式的分析,具体要求如下:
(1)编写 MapReduce 程序,根据以下规则计算学习者的连续学习天数:
·Map 阶段:将每个用户的学习记录按时间排序
·Reduce 阶段:统计每个用户的最长连续学习天数
(2)结果要求包含以下字段:用户ID、起始日期、结束日期、连续天数
(3)将分析结果存储到 HDFS 的 /user/hadoop/learning_streak 目录下
(4)查看分析结果并将前十行数据截图粘贴至【提交结果.docx】中对应的任务序号下。
四、模块三:业务分析与可视化
(一)任务一:数据分析与可视化
- 子任务一:数据分析
本任务要求使用 Python 对在线教育平台的学习数据进行深入分析,以揭示平台运营效果和学习者行为特征。参赛者需要运用 Python 的数据处理和分析库,如 Pandas 来完成以下分析任务:
(1)分析各类别课程的完课率,计算方法为:完成进度达到100%的学习者人数/课程报名总人数,并按完课率降序排列展示前三个类别;
(2)计算每个时间段(上午:6:00-12:00、下午:12:00-18:00、晚上:18:00-24:00、凌晨:0:00-6:00)的平均学习时长,找出学习参与度最高的时间段;
(3)分析不同难度等级课程的平均测验成绩,揭示课程难度设置是否合理;
(4)统计每类设备(PC端、移动端、平板端)的使用比例和平均单次学习时长,分析用户的设备使用偏好;
(5)计算课程的学习黏性(连续学习天数大于7天的用户占比),找出最具吸引力的三门课程;
将该5个统计结果在 IDE 的控制台中打印并分别截图复制粘贴至【提交结果.docx】中对应的任务序号下。 - 子任务二:数据可视化
在这个任务中,参赛者需要使用 Matplotlib 和 Seaborn 库创建专业的可视化图表,以直观地展示在线教育平台的运营情况和学习者行为特征。具体要求如下:
(1)创建多系列折线图展示一周内不同时段的学习人数变化趋势,要求:
·X轴为星期一至星期日
·Y轴为学习人数
·使用不同颜色的线条区分上午、下午、晚上三个时段
·添加图例、标题和坐标轴标签
·在关键点标注数值
(2)构建堆叠柱状图比较各课程类别在不同难度级别的分布情况,要求:
·X轴为课程类别
·Y轴为课程数量
·用不同颜色代表入门、初级、中级、高级四个难度级别
·显示各部分占比数据
·添加图例说明
将这2个可视化图表分别截图复制粘贴至【提交结果.docx】中对应的任务序号下。请确保图表具有良好的可读性,并遵循数据可视化的基本原则,如色彩协调、标签清晰、布局合理等。
(二)任务二:业务分析
在线教育平台的成功运营需要深入理解学习者行为特征和课程运营效果。本任务要求参赛者使用Python对平台数据进行深入的业务分析,发现问题并提出改进建议。
请使用 Python 对在线教育平台的数据进行如下业务分析:
(1)课程参与度分析
·计算各课程的以下指标:
o平均学习时长(分钟/课程)
o平均完课率(%)
o平均测验得分
o学习者互动率(有互动记录的学习者/总学习者)
·基于上述指标,识别最受欢迎的课程特征
(2)学习者行为分析
·分析学习时间分布,找出最佳学习时段
·计算学习者的持续性(连续学习天数)
·统计不同设备的使用偏好
(3)课程效果评估
·计算不同难度课程的通过率
·分析学习时长与测验成绩的关系
·评估课程内容的难度分布是否合理
·识别可能需要优化的课程环节
基于以上分析,请提供一份简要的运营分析报告,内容包括:
1.平台运营现状概述
o总体运营指标
o主要问题识别
o成功经验总结
2.改进建议
o课程内容优化建议
o学习体验提升建议
o用户留存策略建议
报告篇幅控制在300字以内,重点突出数据支撑的洞察和可行的改进方案。将分析报告复制粘贴至【提交结果.docx】中对应的任务序号下。
运营分析报告(提交结果):
平台运营现状概述 核心指标:课程平均完课率62%,高互动率课程(>45%)的完课率提升28%,移动端占比达73%
主要问题:难度进阶课程通过率仅41%,工作日晚间(20-22点)学习时长下降32%
成功经验:实战型课程(案例占比>50%)平均得分高于理论课19分 改进建议
课程优化:为低通过率课程(机器学习等)增加前置知识检测,拆分复杂模块为微课
体验提升:开发移动端专属互动组件,建立21:00-22:00时段学习打卡激励
留存策略:基于持续性分级(连续学习>7天用户占29%),设计阶梯式勋章奖励体系



















 971
971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











