






1.1 简介
MySQL是一种关联数据库管理系统,关联数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
1.2 安装
在ubuntu下:
apt-get install mysql-server mysql-client libmysqlclient-dev
要记得密码,会用得着
1.3 mysql数据类型
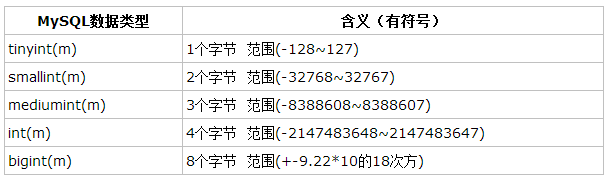
(1)整形
(2)浮点型

设一个字段定义为float(5,3),如果插入一个数123.45678,实际数据库里存的是123.457,但总个数还以实际为准,即6位。
(3)定点数
浮点型在数据库中存放的是近似值,而定点类型在数据库中存放的是精确值。
decimal(m,d) 参数m<65 是总个数,d<30且 d<m 是小数位
(4)字符串
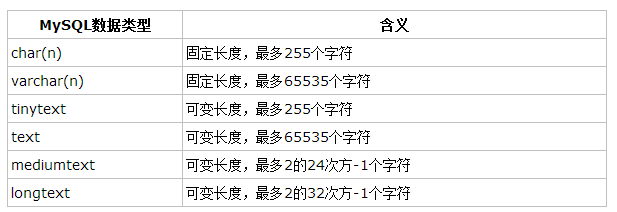
-
char和varchar:
1.char(n) 若存入字符数小于n,则以空格补于其后,查询之时再将空格去掉。所以char类型存储的字符串末尾不能有空格,varchar不限于此。2.char(n) 固定长度,char(4)不管是存入几个字符,都将占用4个字节,varchar是存入的实际字符数+1个字节(n<=255)或2个字节(n>255),所以varchar(4),存入3个字符将占用4个字节。
3.char类型的字符串检索速度要比varchar类型的快。
-
varchar和text:
1.varchar可指定n,text不能指定,内部存储varchar是存入的实际字符数+1个字节(n<=255)或2个字节(n>255),text是实际字符数+2个字节。2.text类型不能有默认值。
3.varchar可直接创建索引,text创建索引要指定前多少个字符。varchar查询速度快于text,在都创建索引的情况下,text的索引似乎不起作用
(5)二进制数据
- BLOB和text存储方式不同,TEXT以文本方式存储,英文存储区分大小写,而Blob是以二进制方式存储,不分大小写。
- BLOB存储的数据只能整体读出。
- TEXT可以指定字符集,BLOB不用指定字符集。
(6)日期时间类型

若定义一个字段为timestamp,这个字段里的时间数据会随其他字段修改的时候自动刷新,所以这个数据类型的字段可以存放这条记录最后被修改的时间。
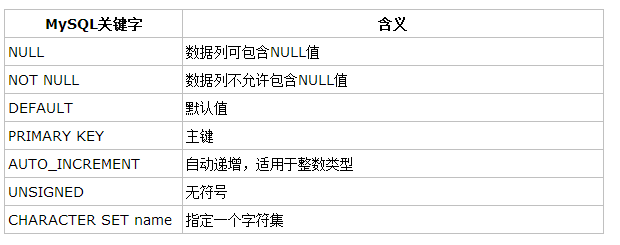
(7)数据类型的属性
1.4 mysql的基本操作
(1)登录MySQL
mysql -u root -p
登录上去了:
(2)查看所有数据库
show databases;
结果如下(默认只有红线的这四个):
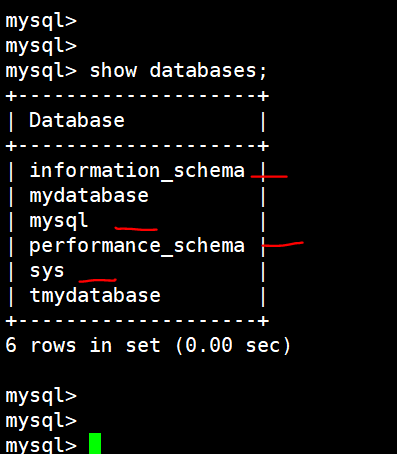
(3)使用数据库
use mysql
如果想要切换到 sys 数据库,直接use sys就行:
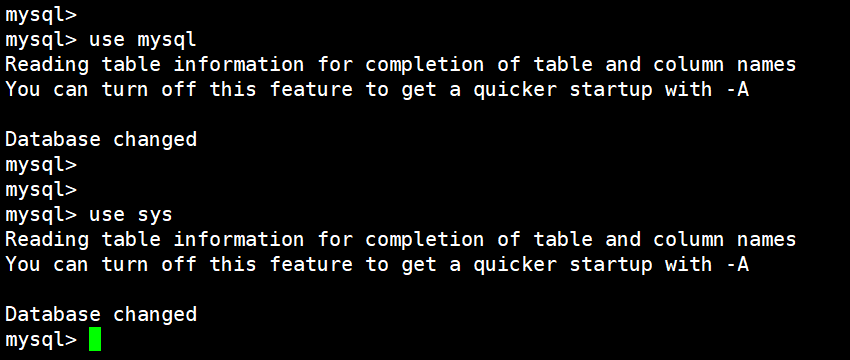
(4)查看所有表
show tables;
在 mysql 下查看所有的表:
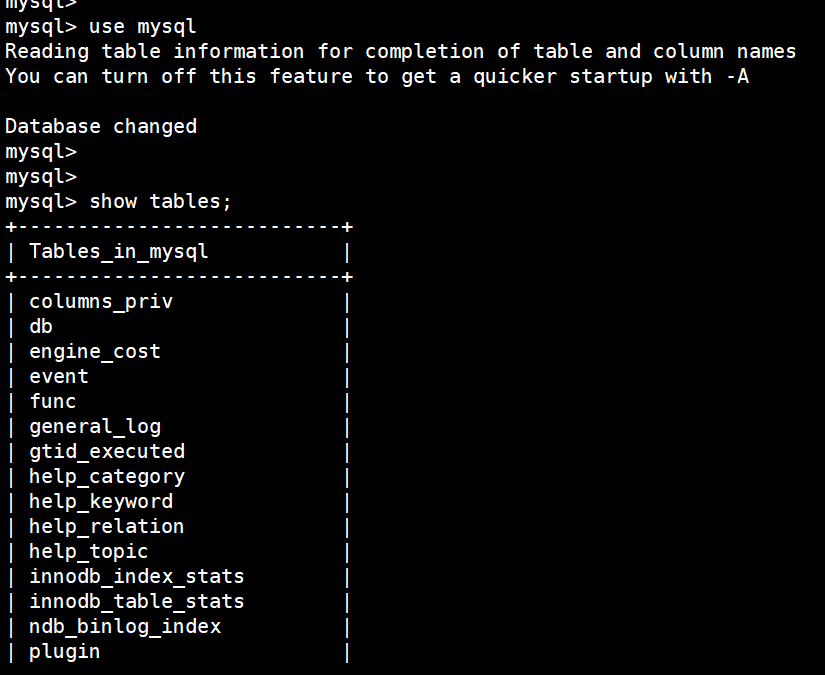
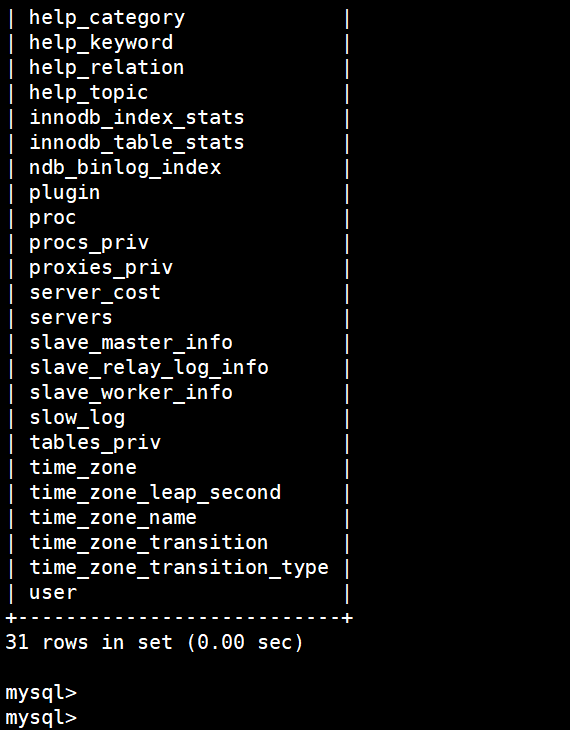
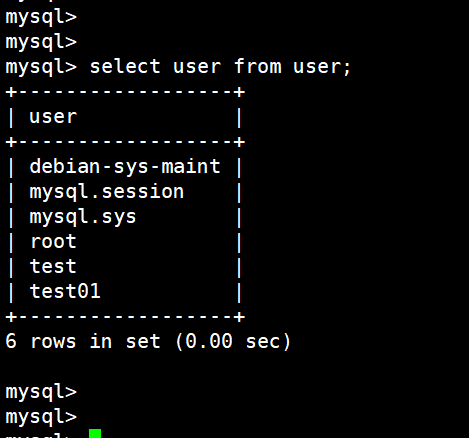
(5)查看所有用户
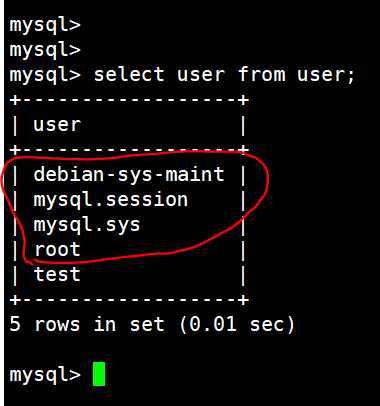
select user from user;
从 user 这张表里查看用户(默认只有前四个):
(6)创建用户
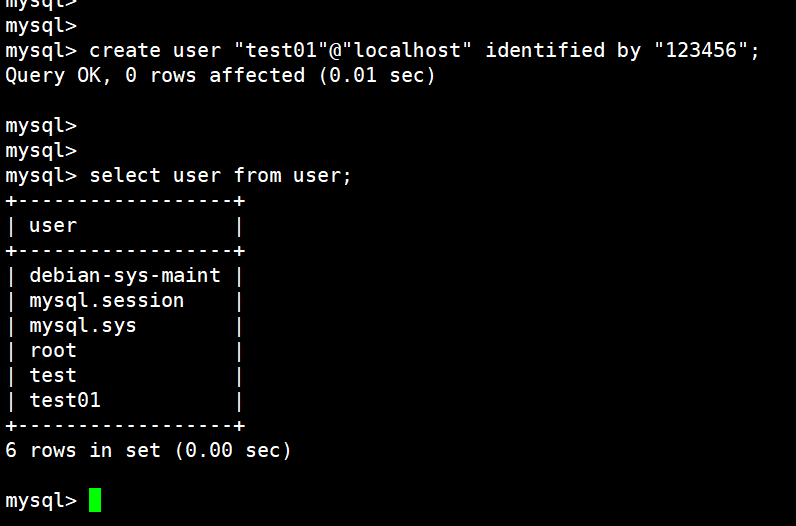
create user "test01"@"localhost" identified by "123456";
创建一个用户名为 test01,localhost表示只有本机用户才能使用, 密码是:123456
创建成功如下图所示:
(7)修改密码
set password for "test01"@"localhost" = PASSWORD("888888");
将 test01 这个用户的密码改为:888888
结果如下:

(8)授权操作
grant select on *.* to "test01"@"localhost";
对 test01 授予在所有数据库的所有表具有查询权限
结果如下:

(9)退出 mysql
exit
结果如下:
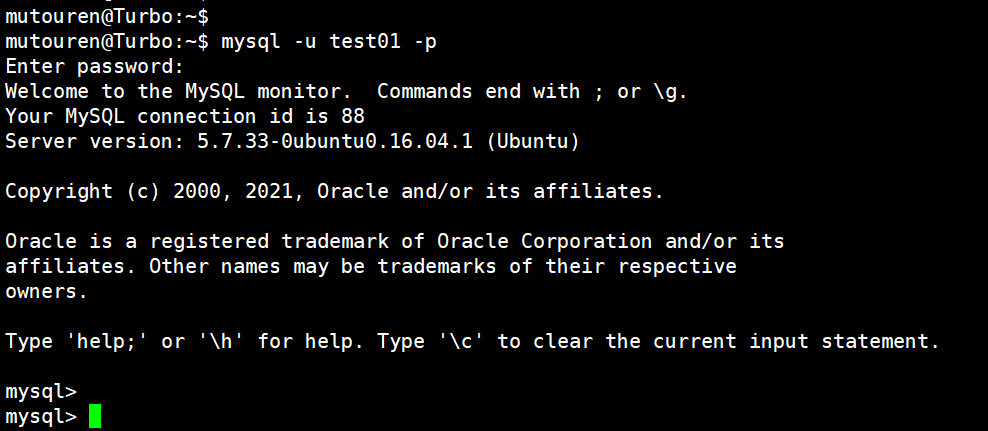
(10)再次登录自己创建的用户
mysql -u test01 -p
登录刚刚创建的用户 test01 , 输入密码,结果如下所示:
登录上之后,进入 mysql 数据库,可以 尝试 create 权限,发现不能创建,因为我们刚刚只赋予了该用户 select权限:
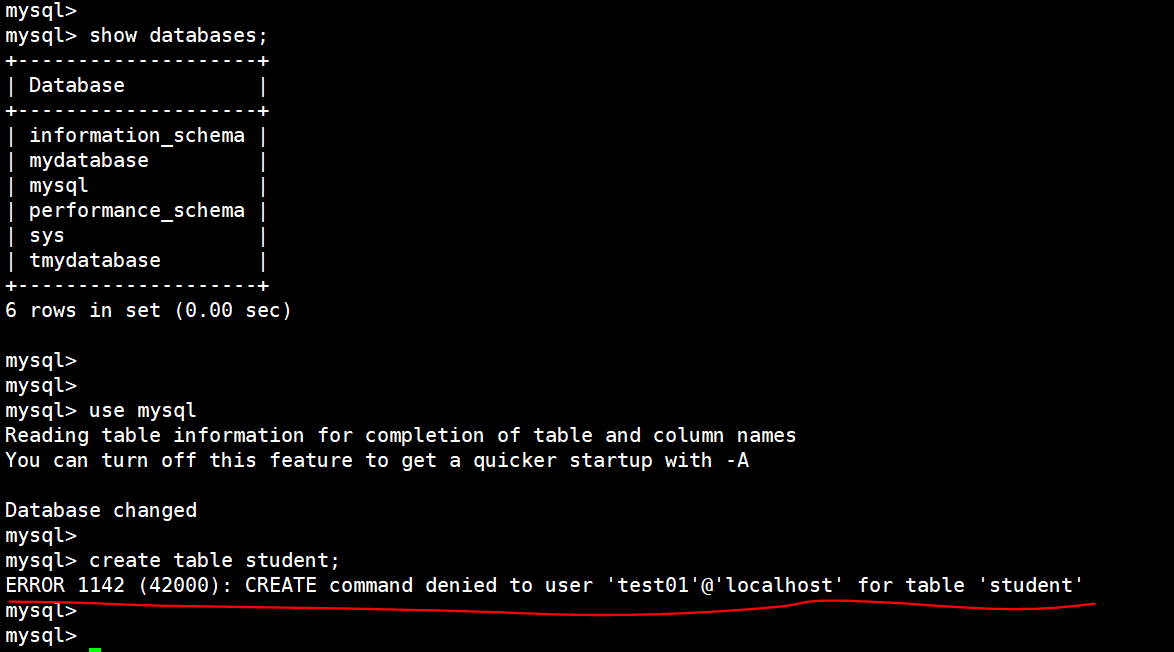
因此该用户啊具有 select的权限:
(11)给test01加上create权限
首先退出myql,利用 root 用户登录:
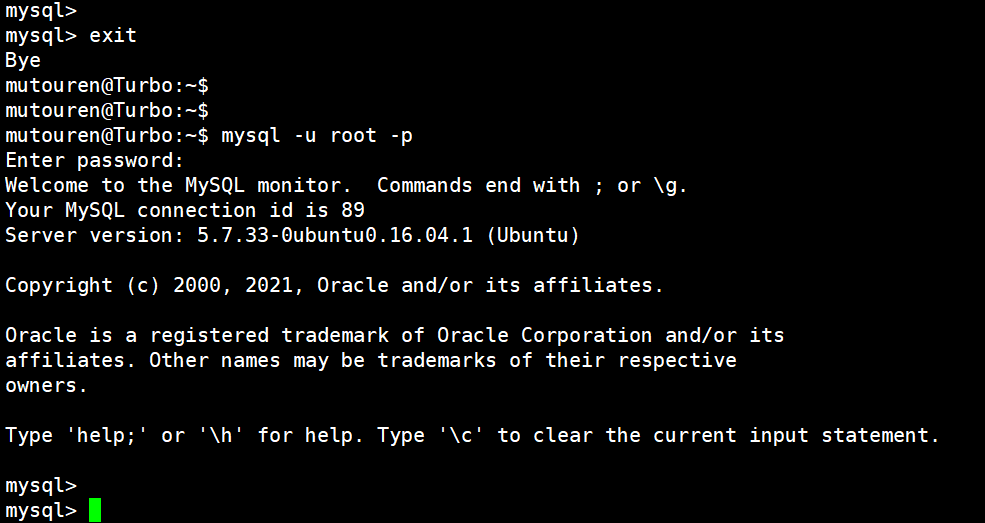
然后给 test01 用户授予 creater 的权限:
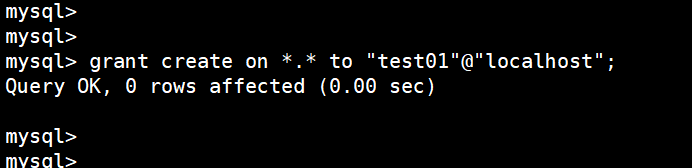
然后退出 mysql ,再用 test01 这个用户登录
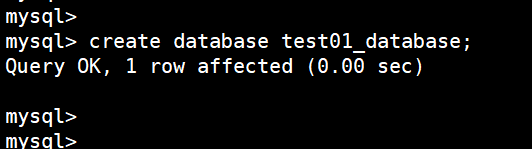
利用命令:create database test01_database;,创建一个database:
可以看到,此时 test01 这个用户具有了 create 的权限了。
(12)创建数据库
create database test01_database;
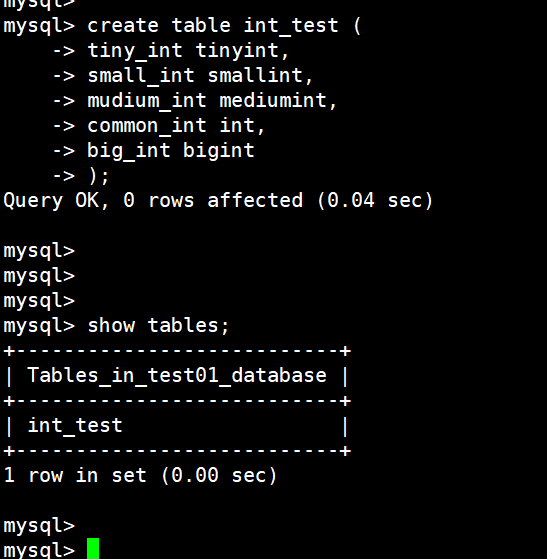
(13)创建表
create table int_test (
tiny_int tinyint,
small_int smallint,
mudium_int mediumint,
common_int int,
big_int bigint
);
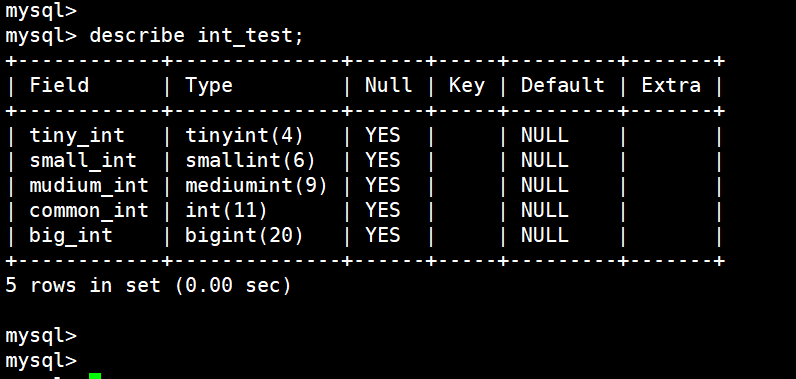
(14)显示表结构
describe int_test;
(15)插入数据
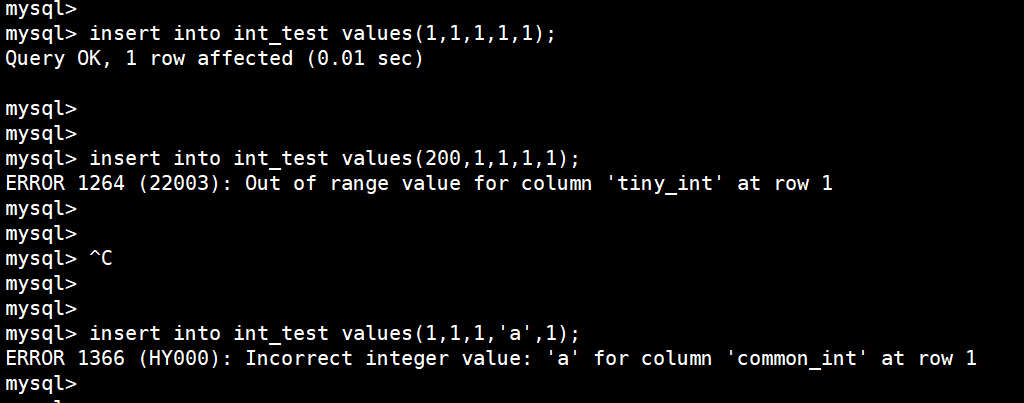
insert into int_test values(1,1,1,1,1);
insert into int_test values(200,1,1,1,1); // 会超出范围,插入失败
insert into int_test values(1,1,1,'a',1); // 插入不正确的类型数据
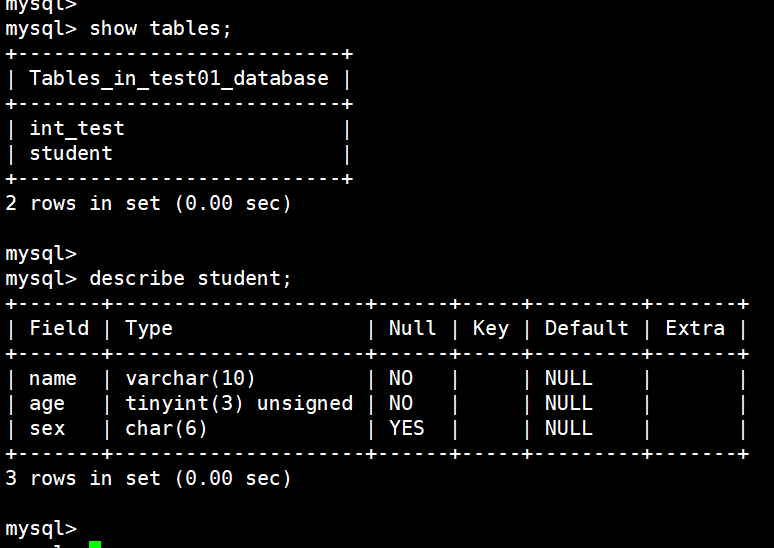
(16)创建学生表
create table student (
name varchar(10) not null,
age tinyint unsigned not null,
sex char(6)
);

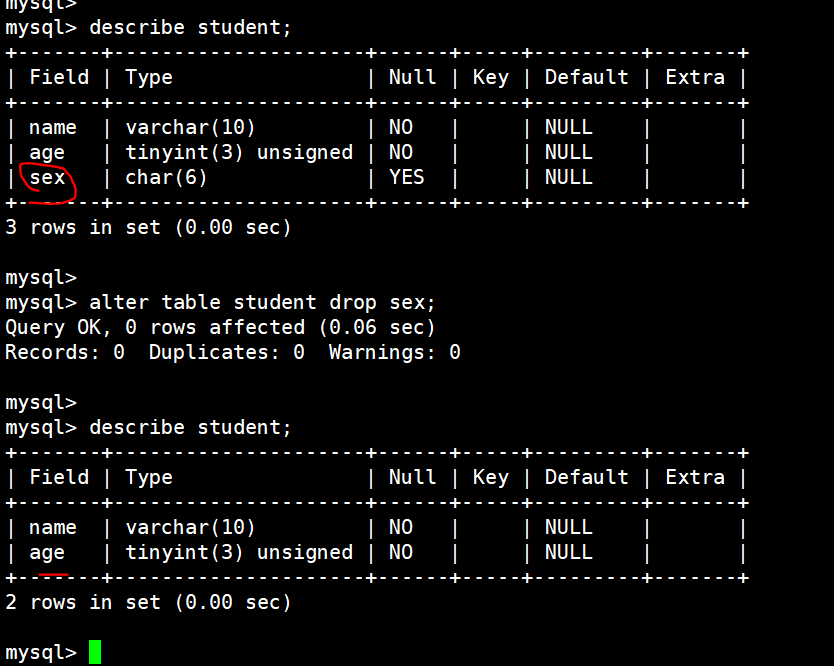
(17)修改表
把表的名字改为:stu
alter table student rename stu;
删除表中的字段,这里把 sex 这个字段给删了
alter table student drop sex;
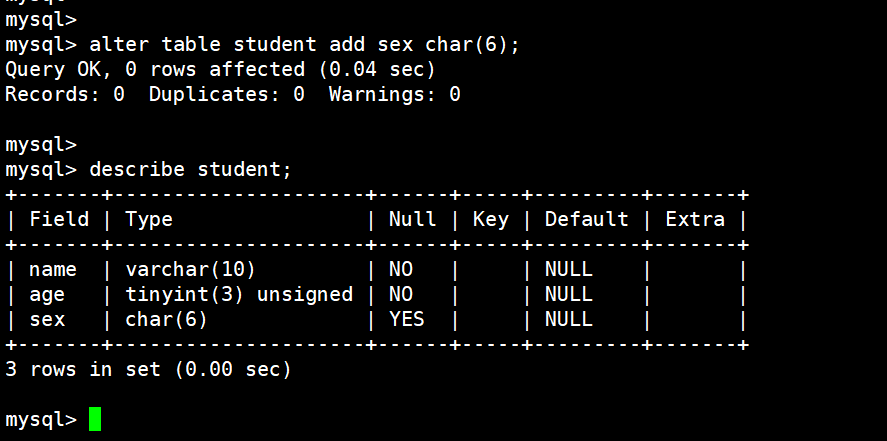
增加一个字段,这里把刚刚删除的sex又增加回来了:
alter table student add sex char(6);
增加 id 这一选项,其中unsigned表示不能为负;not null 表示不能为空;primary key 表示不能重复;auto_increment 表示id是递增的;first 表示把 id 放在最前面
alter table student add id int unsigned not null primary key auto_increment first;
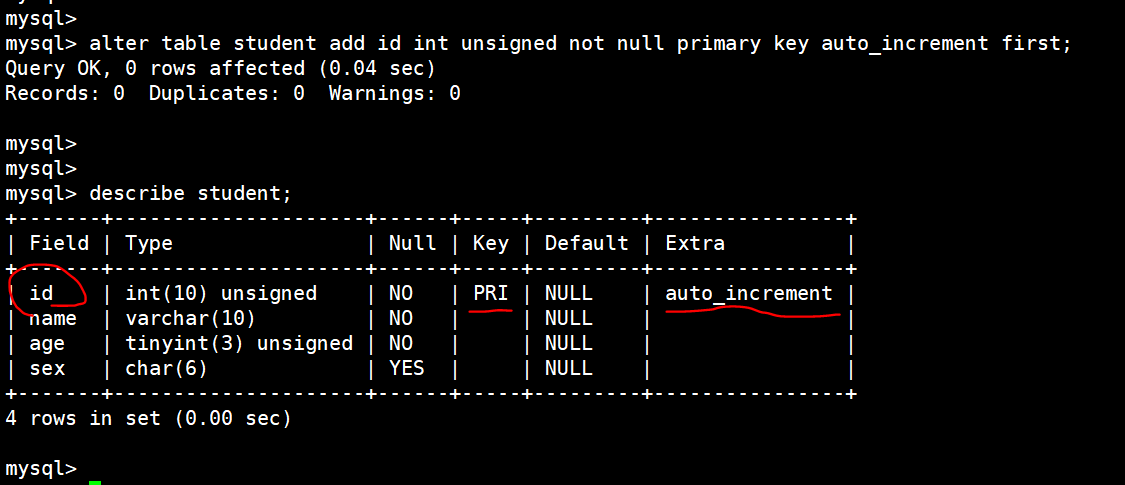
给student这个表添加生日 birth 这个选项,date表示日期类型,after name 表示放在name的后面
alter table student add birth date after name;
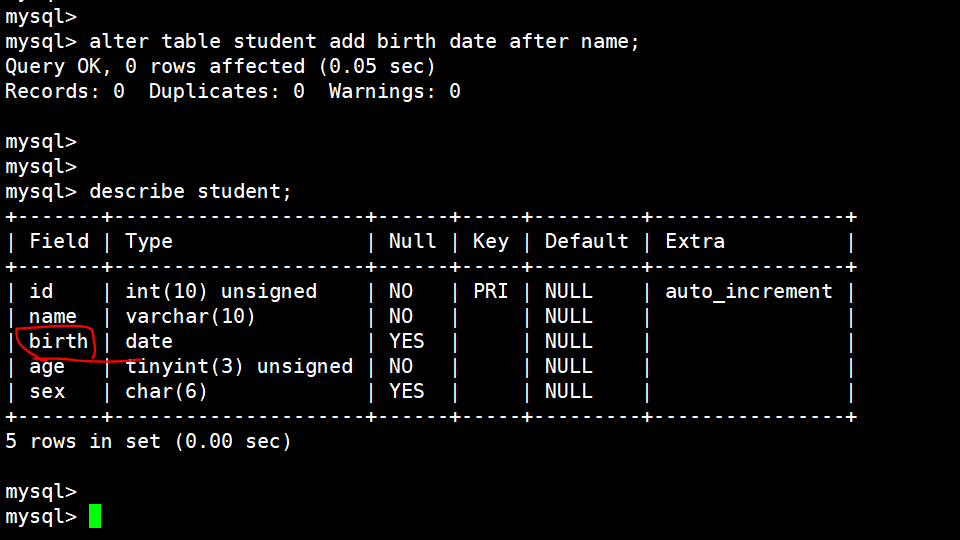
给student添加 tel 这个选项,其中 default '-'表示默认 - 填充:
alter table student add tel char(11) default '-';
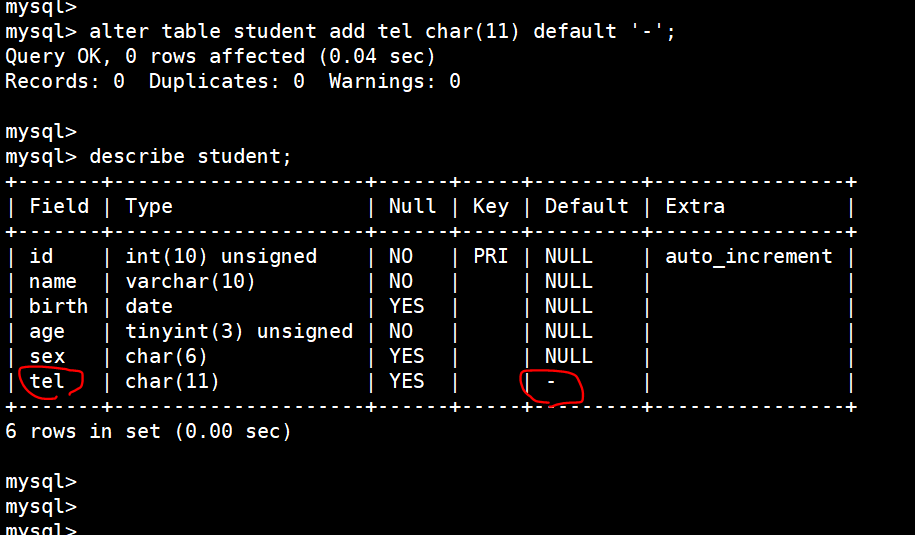
(18)插入数据
全部的项目都插入数据:
insert into student (id, name, birth, age, sex, tel) values (1000, "jack", "1998-4-24", 25, "man", "123456789");

只插入一部分数据,其中 id 由于设置了递增,所以会自动在前一个数据上加一
insert into student (name, birth, age, sex, tel) value("tom", "1990-9-9", 30, "man", "111111111");
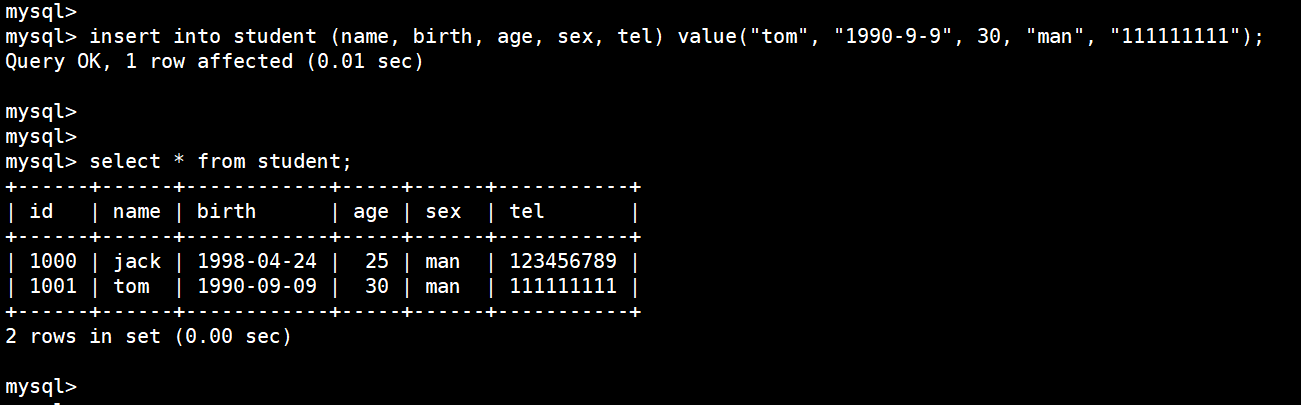
也可以同时插入多条数据:
insert into student values(1002, "rose", "1997-1-15", 22, "female", "22222222222"), (1003, "frank", "2000-7-14", 15, "male", "33333333333");
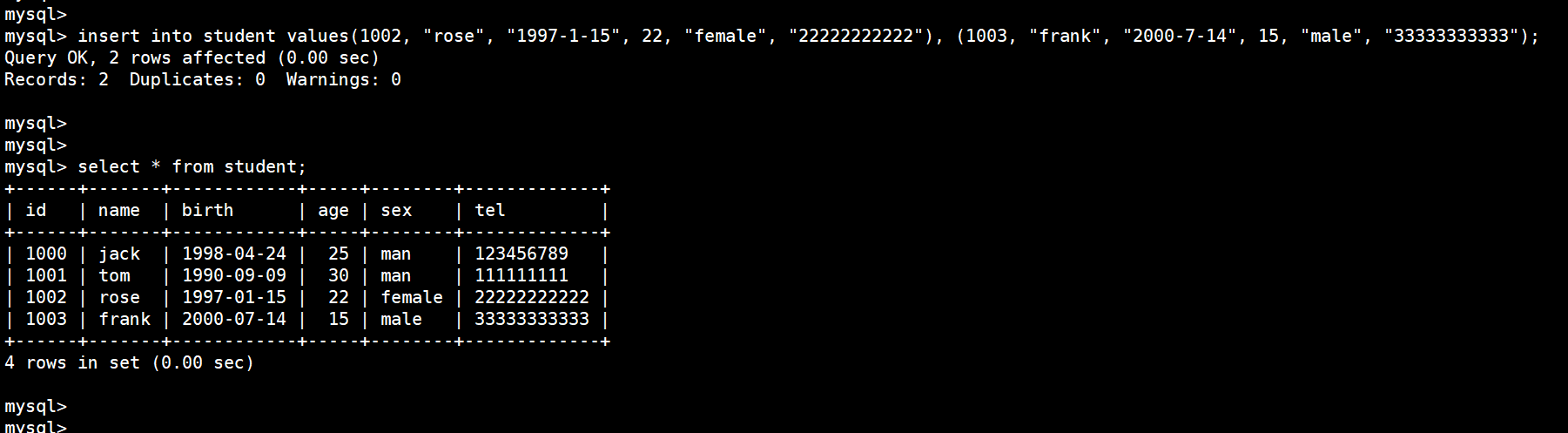
由于 tel 设置了 default ‘-’ ,所以插入时不写这个,他会自动采用默认值:
insert into student (id, name, birth, age, sex) values(1004, "aa", "1996-10-21", 24, "male");
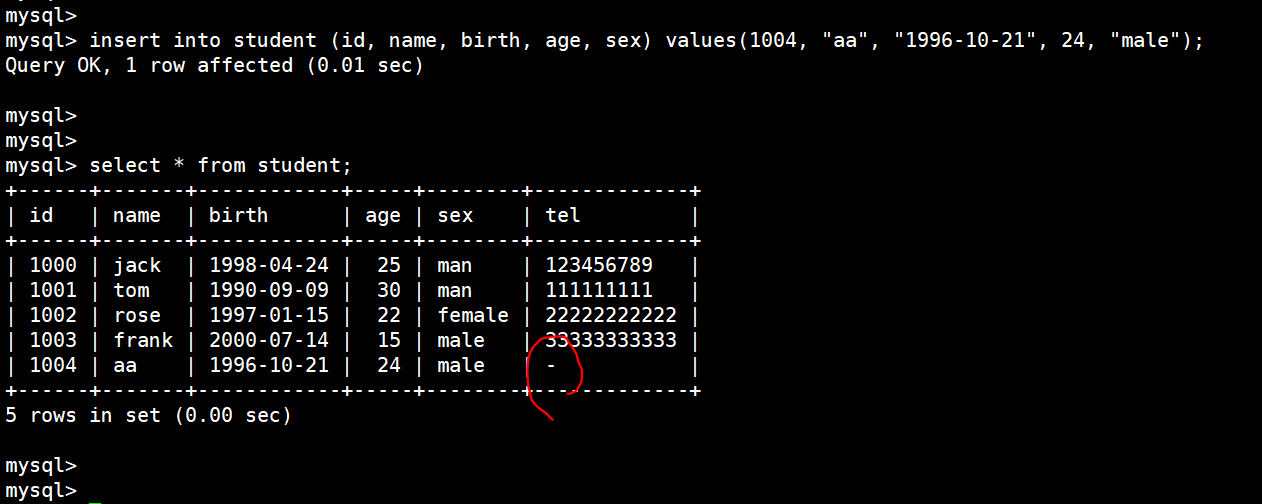
这里一开始是不支持中文的(可以看下面(20)修改字符集进行解决):
insert into student values(1005, "张三", "1992-11-11", 30, "male", "44444444444");

(19)查询数据
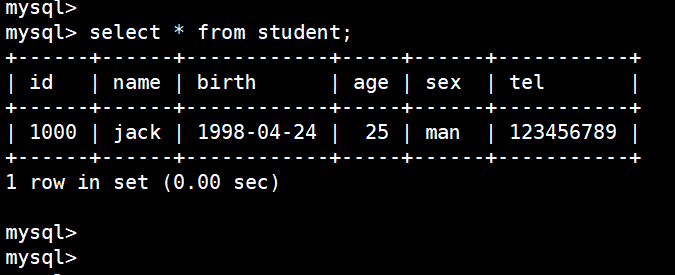
* 号查询表中所有数据:
select * from student;
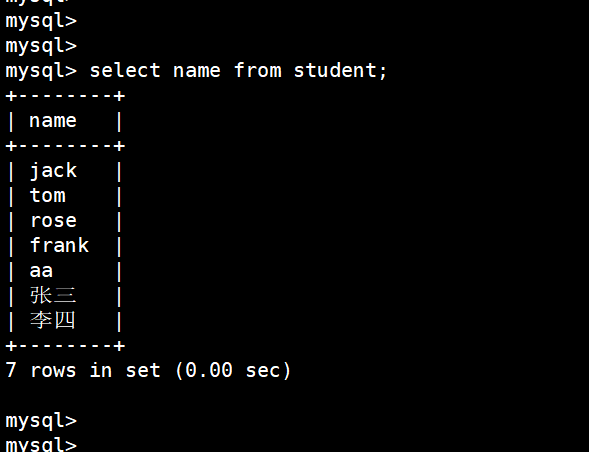
只查名字:
select name from student;
只查询 id > 1002 的人的名字:
select name from student where id > 1002;
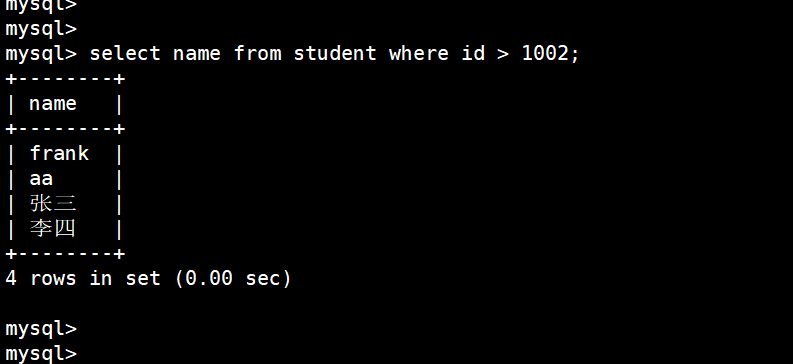
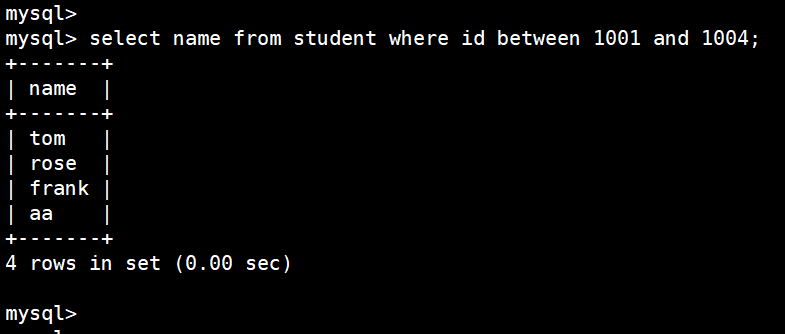
只查询 id 在1001 至 1004 之间的人的名字:
select name from student where id between 1001 and 1004;
(20)修改字符集(字符编码格式)
指定 utf8 的编码格式:
alter table student convert to character set utf8;
现在就可以用中文了
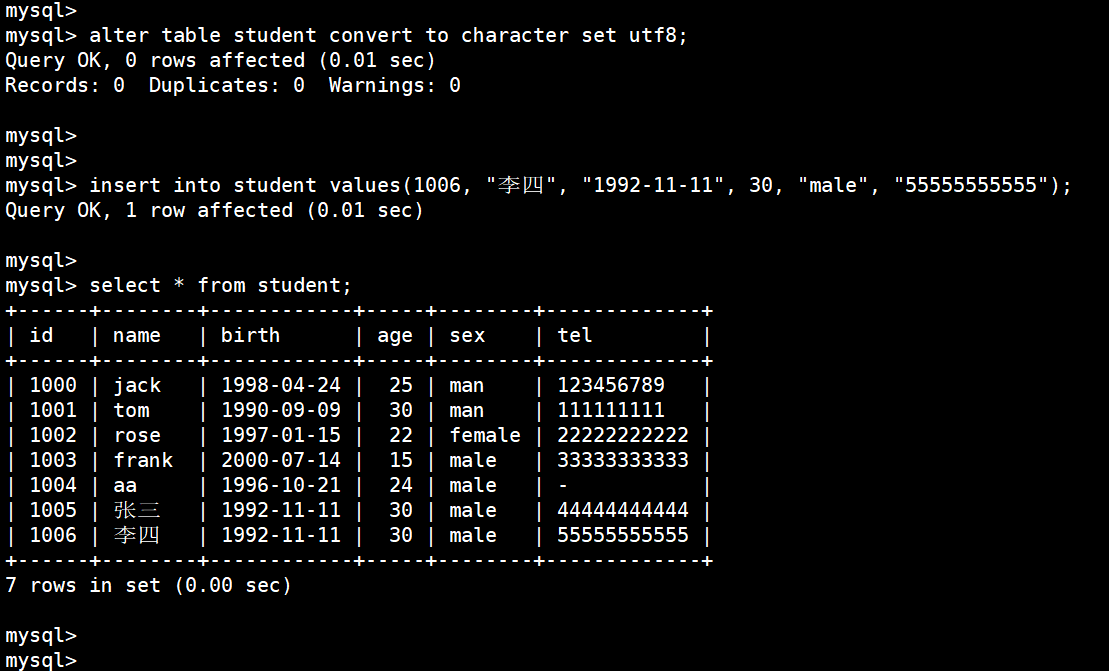
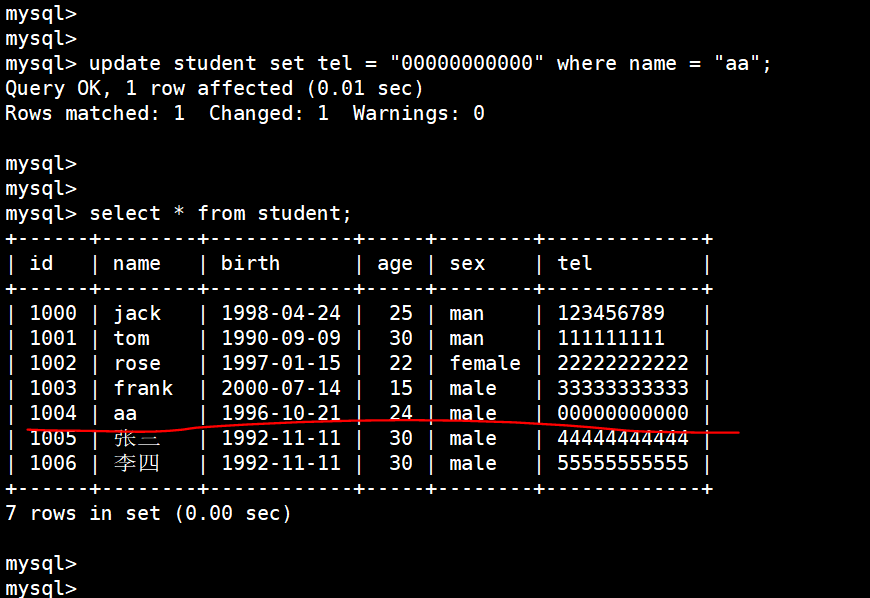
(21)修改数据
将 name 为 aa 这个人的电话改成 00000000000:
update student set tel = "00000000000" where name = "aa";
(22)删除记录
删除 id 为 1000 的这个人:
delete from student where id = 1000;
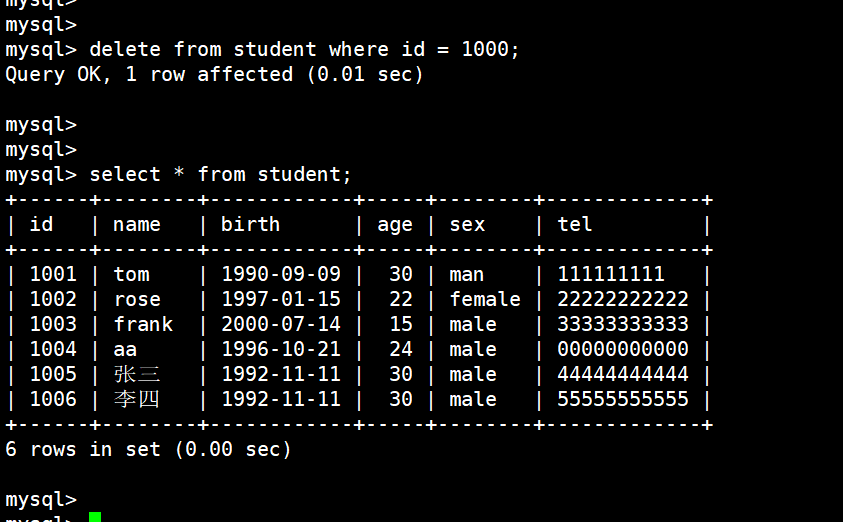
(23)删除表
drop table sutdent;
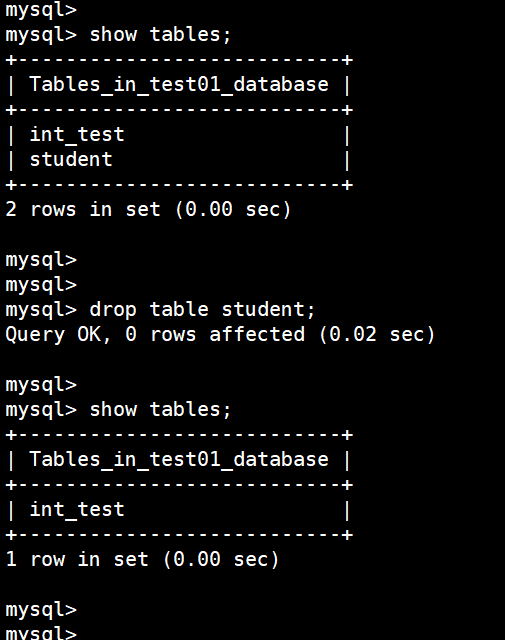
(24)删除数据库
drop database test01_database;
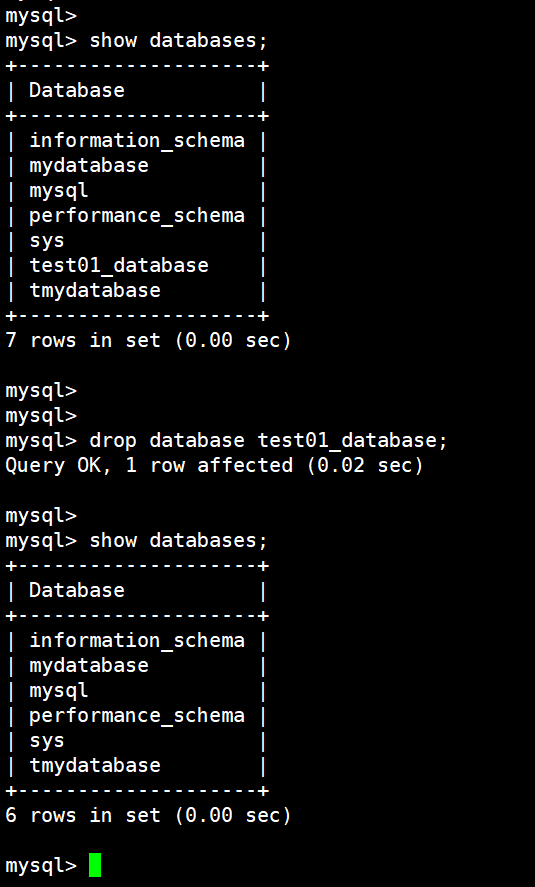
1.5 事务操作
(1)创建表
create table account (
id int unsigned not null primary key,
name varchar(20),
money int
)charset utf8;
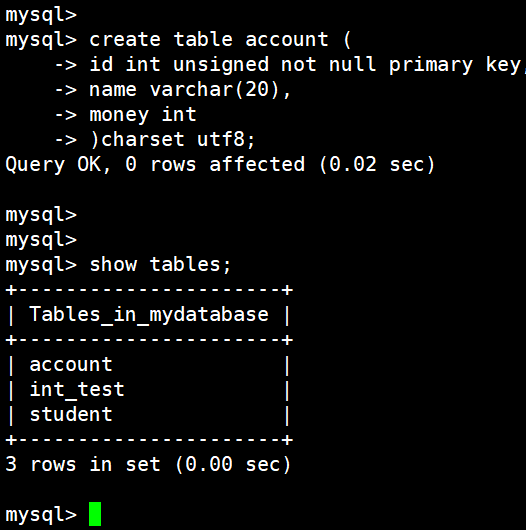
(2)插入数据
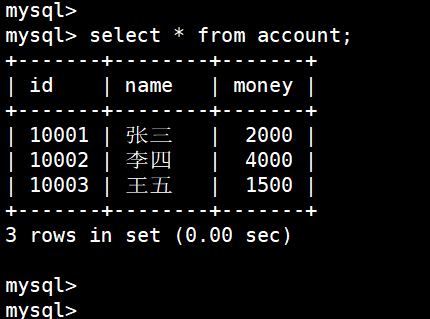
insert into account values(10001, "张三", 2000), (10002, "李四", 5000), (10003, "王五", 1000);
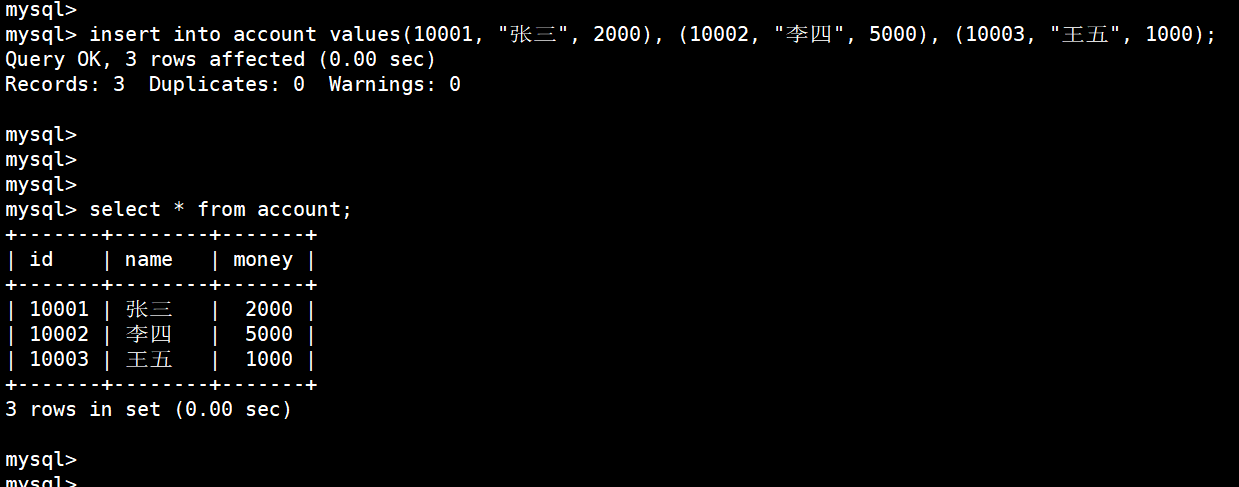
(3)李四给王五转500(但是出问题了)
李四少500
update account set money = money - 500 where id = 10002;
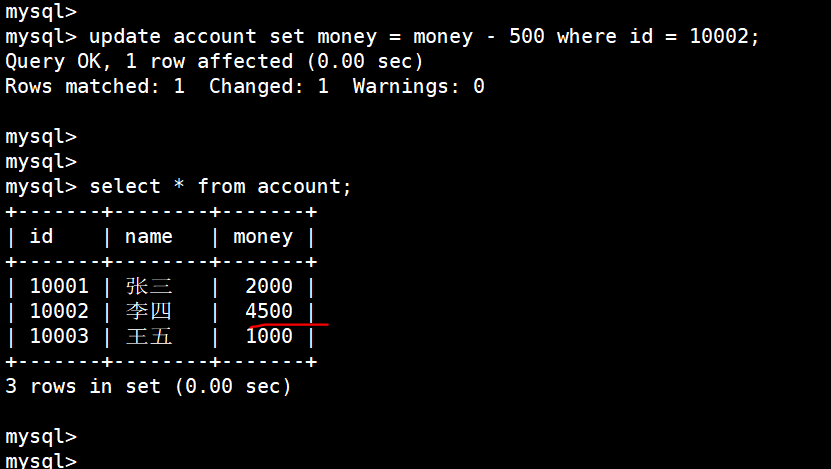
但是中途一下子停电了,再次登录 MySql 数据出错,李四的钱少了,但是王五的前没有增加(事务操作就是来解决这个问题):
(4)开启事务
start transaction;
(5)李四给王五转500,并且中途停电了
update account set money = money - 500 where id = 10002;
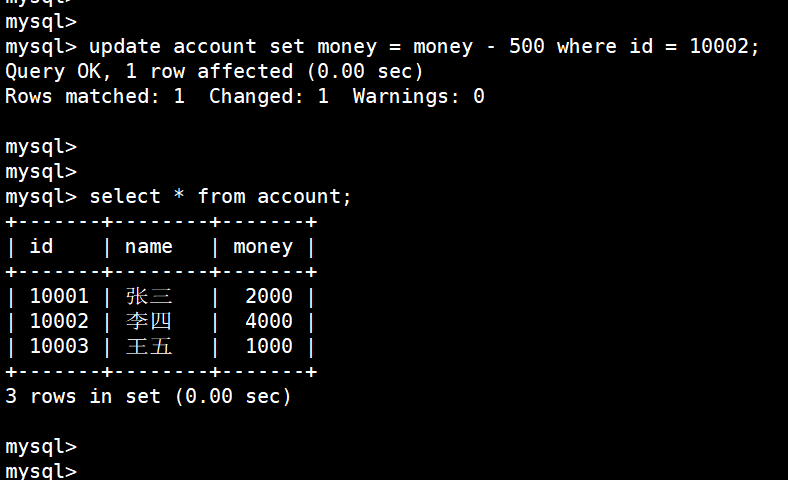
李四确实少了500,退出MySQL(停电了)重新再登录,发现李四的钱并没有少,依旧是4500:(看到的结果经过事务日志,我们看到的结果都是缓存内的)
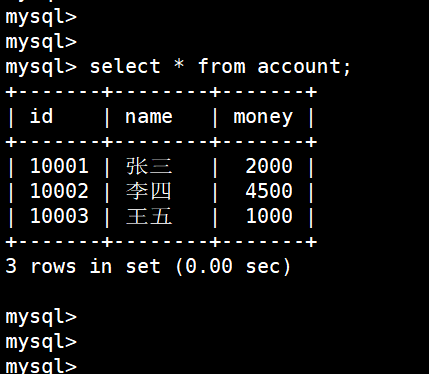
(6)王五增加500
update account set money = money + 500 where id = 10003;
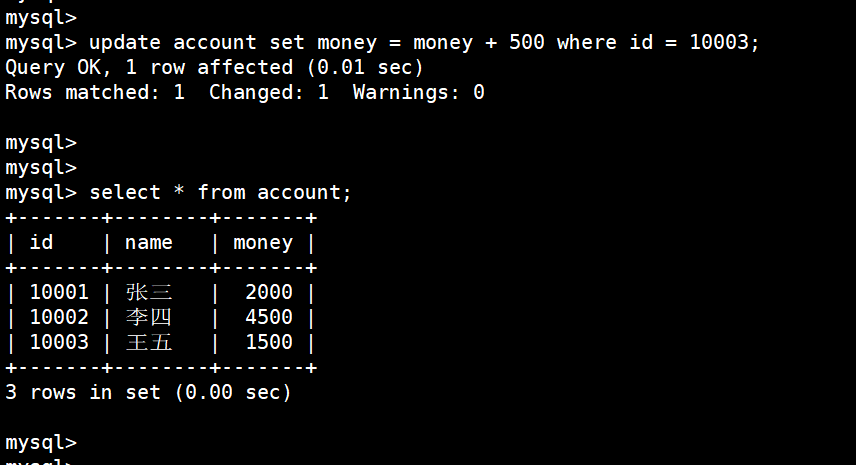
如果退出MySQL,再次登录,发现李四,王五的钱依旧没有改变:
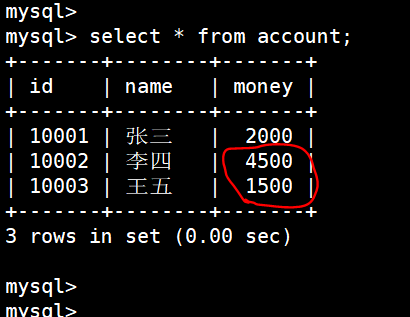
(7)提交
这样才能真正的在事务中改变值
commit;
完整的程序应该是:
start transaction;
update account set money = money - 500 where id = 10002;
update account set money = money + 500 where id = 10003;
commit;
我的理解就是:在 start transaction 之后的代码执行完后,真实数据库里面的数据并没有被改变,只有当执行了 commit 语句之后,数据库里面的数据才能真正的改变。
1.6 回滚操作
背景:如果我们一次执行100条语句,我们前面80条都是正确的,后面的语句有错误,我们可以通过回滚返回到第80条语句执行完之后的状态,而不是去到最初所有程序都没有执行的状态。
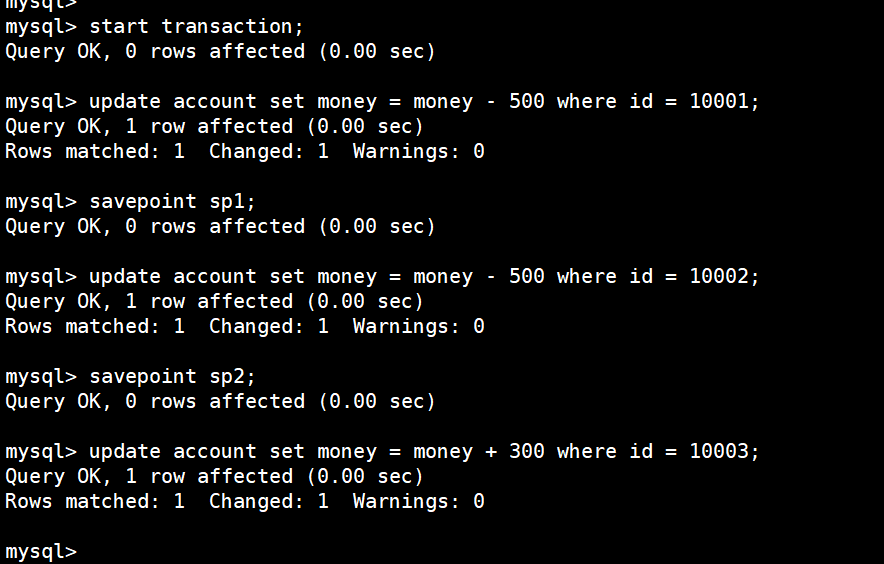
(1)开启事务
start transaction;
(2)张三转出500
update account set money = money - 500 where id = 10001;
(3)设置回滚点
savepoint sp1;
(4)李四转出500
update account set money = money - 500 where id = 10002;
(5)设置回滚点
savepoint sp2;
(6)王五增加1000
update account set money = money + 300 where id = 10003;
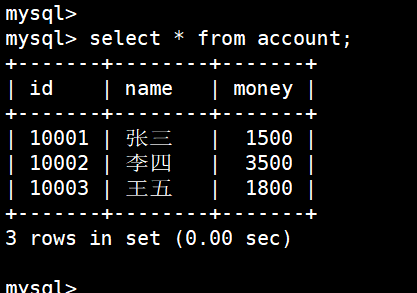
但是这里我给 王五 转钱的时候发现转错了,可以直接回滚到sp2,重新给 王五 转钱:
(7)回滚到 sp2,重新转钱
rollback to sp2;
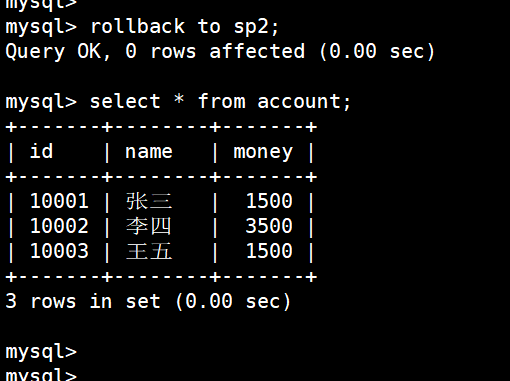
重新给王五转1000
update account set money = money + 1000 where id = 10003;
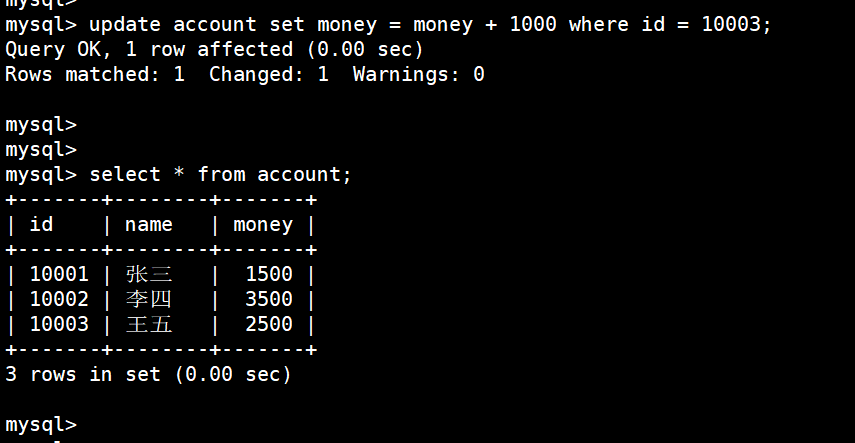
(8)最后提交
commit;
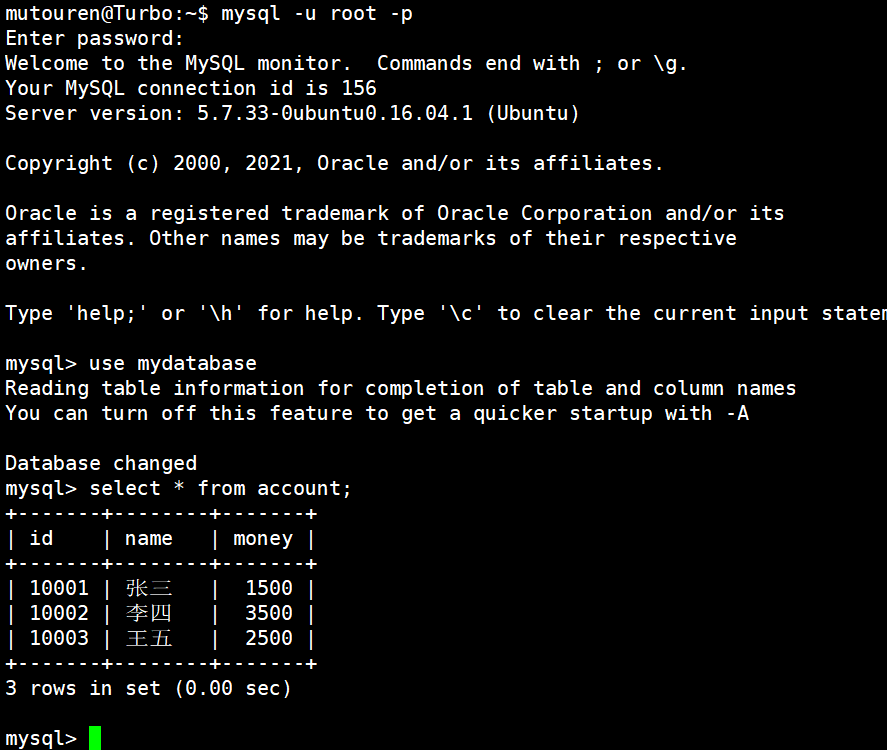
退出MySQL再重新登录,发现数据确实正确更改了:















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









