






目录
1. 神经网络训练
这一步一般在python上训练,大家可以根据自己的习惯和喜好,用tensorflow或者pytorch也行。本文以pytorch为例说明模型的环境搭建和训练。
1.1 pytorch环境搭建
这一步比较基础,有很多相关的资料,此处简单介绍安装流程:
①在个人电脑下载安装anaconda,官网:https://www.anaconda.com/download
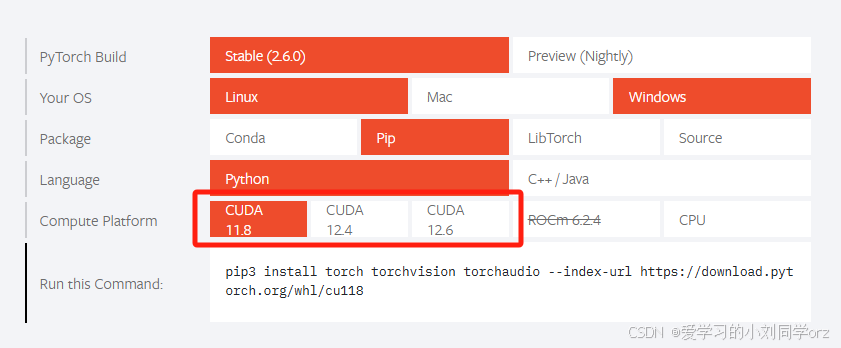
②从pytorch官网下载pytorch:PyTorch
此处有个坑要注意,如果大家准备用显卡进行训练的话最好先把电脑/服务器的显卡驱动给升级到最新,可以在控制台输入
nvidia -smi来查看自己电脑目前显卡的cuda版本
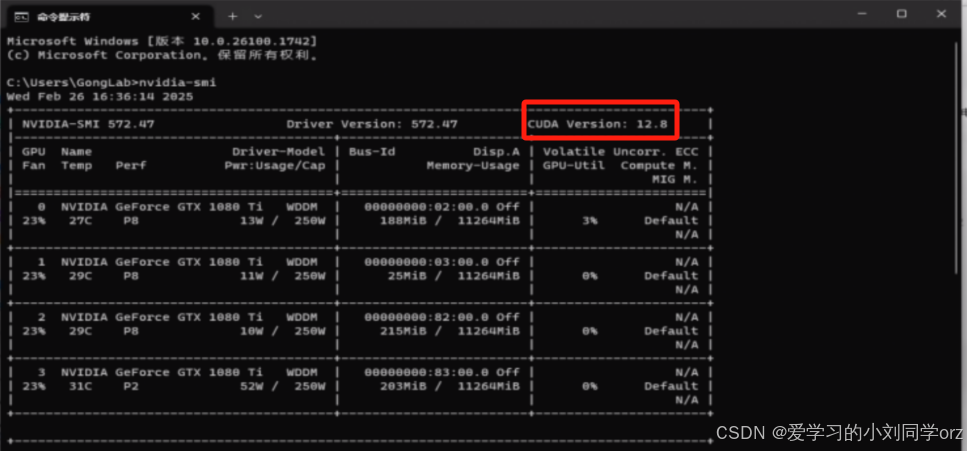
如博主的这台工作站cuda版本是12.8,CUDA版本可以向下兼容,因此大家可以根据自己需求在pytorch官网下载低于自己电脑cuda版本的pytorch就行:
1.2 网络搭建和模型训练
这里我推荐大家一个Github上的开源项目,博主是参考该开源项目的框架搭建的模型,而且这个项目配置好了Tensorboard,可以在训练的过程中可视化模型训练效果:
这个开源项目是非官方的CRN语音增强模型实现,如果大家对原文感兴趣可以去谷歌学术搜索“A Convolutional Recurrent Neural Network for Real-Time Speech Enhancement”
具体怎么搭建网络包括模型训练大家自己去理解上面的开源项目就行,其实也很简单,开源大佬的代码风格和结构都很容易懂。以下附上博主自己训练网络的结构:
import torch
import torch.nn as nn
class LstmWin(nn.Module):
"""
Input: [batch size, channels=1, T, n_fft]
Output: [batch size, T, n_fft]
"""
def __init__(self):
super(LstmWin, self).__init__()
# LSTM
self.lstm_layer_1 = nn.LSTM(input_size=129, hidden_size=200, num_layers=1, batch_first=True)
self.lstm_layer_2 = nn.LSTM(input_size=200, hidden_size=200, num_layers=1, batch_first=True)
# FC
self.fc_layer = nn.Sequential(
nn.Linear(200, 129), # 第一个全连接层
nn.ReLU(), # 激活函数
nn.Linear(129, 129), # 第二个全连接层
nn.Sigmoid()
)
def forward(self, x): # x = [B,129,16] 每一帧129个fft点,并且有16帧数据
self.lstm_layer_1.flatten_parameters()
self.lstm_layer_2.flatten_parameters() # 展平参数进行训练优化
x = x.squeeze(axis=1) # [B,1,F,T] => [B,F,T] 为了适应rknn的模型转换,要求一定要有4个维度的输入
lstm_in = x.permute(0, 2, 1) # [B,F,T] => [B,T,F]
lstm_out_1, _ = self.lstm_layer_1(lstm_in) # [2, 200, 1024]
lstm_out_2, _ = self.lstm_layer_2(lstm_out_1)
fc_out = self.fc_layer(lstm_out_2)
fc_out = fc_out.permute(0, 2, 1) # [B,T,F] => [B,F,T]
return fc_out
if __name__ == '__main__':
layer = LstmWin()
a = torch.rand(32, 129, 200)
print(layer(a).shape)
如果大家用的是上面博主推荐的开源训练框架,那么可以通过以下指令来可视化训练过程:
tensorboard --logdir=<directory_name>TensorBoard的可视化效果:
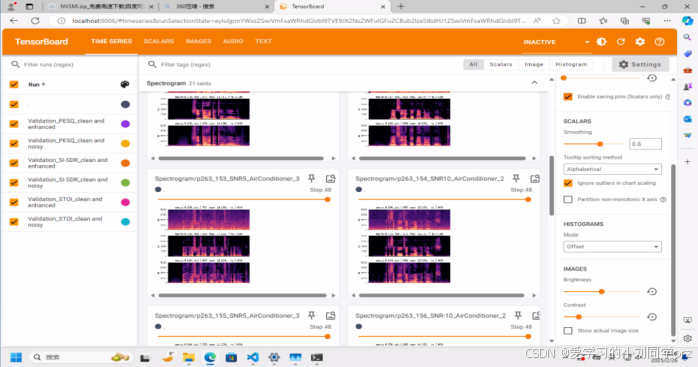
具体显示什么内容大家可以自己在代码中更改,关于TensorBoard的教程也很多,此处不再赘述。
2. 网络模型转换
RKNN模型的转换如下图:
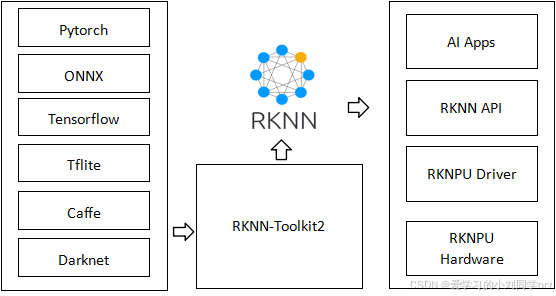
你可以直接把左边的所有模型直接转成RKNN可以运行的模型,博主在模型转换这一步还是先按照经典的思路,把Pytorch模型转换成了通用的ONNX格式再进一步转换。
2.1 Pytorch格式网络转换成ONNX网络
如果大家用的是博主上面推荐的框架,输出的应该是.tar包含所有信息的一个字典结构数据,通过以下代码转成Pytorch的.pth模型:
import torch
from DeepFIR_RKNN.RKNN_BN_Test.DeepFIR_RKNN_Test import LstmWin
# 加载检查点
Tar_Path = 'DeepFIR_RKNN\\RKNN_BN_Test\\best_model.tar'
PTH_Path = 'DeepFIR_RKNN\\RKNN_BN_Test\\DeepFIR_RKNN_BN.pth'
model_checkpoint = torch.load(Tar_Path, weights_only=False) # 现在不会报错
model_static_dict = model_checkpoint["model"]
# 实例化模型(需确保参数与训练时一致)
model = LstmWin() # 替换为你的实际参数
model.load_state_dict(model_static_dict) # 加载参数
torch.save(model.state_dict(), PTH_Path)上面导入模型的代码大家自己换成自己文件路径内容就行。
转换成.pth格式模型后通过以下代码转换成ONNX模型:
import torch
from DeepFIR_RKNN.RKNN_BN_Test.DeepFIR_RKNN_Test import LstmWin
# 实例化模型(参数必须与训练时一致)
model = LstmWin() # 替换为实际参数
PTH_Path = 'DeepFIR_RKNN\\RKNN_BN_Test\\DeepFIR_RKNN_BN.pth'
ONNX_path = 'DeepFIR_RKNN\\RKNN_BN_Test\\DeepFIR_RKNN_BN.onnx'
# 加载模型参数
model.load_state_dict(torch.load(PTH_Path))
model.eval() # 切换到推理模式(关闭Dropout/BatchNorm等训练层)
# 假设输入是(batch_size, sequence_length, input_size)
dummy_input = torch.randn(1, 1, 41, 16) # 固定长度16
torch.onnx.export(
model,
dummy_input,
ONNX_path,
input_names=["input"], # 输入名称(自定义,用于部署时识别)
output_names=["output"], # 输出名称(自定义)
opset_version=13 # 根据需求选择ONNX算子版本(推荐≥11)
)
import onnx
import onnxruntime as ort
# 检查模型格式是否正确
onnx_model = onnx.load(ONNX_path)
onnx.checker.check_model(onnx_model)
# 使用ONNX Runtime推理测试
ort_session = ort.InferenceSession(ONNX_path)
output = ort_session.run(
None,
{"input": dummy_input.numpy()} # 输入需转为numpy数组
)
print(output[0].shape) # 检查输出形状是否符合预期同时,推荐大家一个开源的工具Netron,可以直接拖拽.ONNX文件可视化网络结构:Netron

比如博主训练好的模型结构打开后:

跟预计的一样没有问题。
2.2 ONNX格式模型转换为RKNN模型
这一步非常关键,请大家一定按照接下来的步骤一步一步来:
博主购买的是Orangepi 5 Ultra开发板,如果大家买的是其他型号的本质上也一样,都可以按照以下教程进行,以下把“开发板”统称“板载”。
2.2.1 安装一个Linux系统
直接在你自己的板载安装Linux系统(安装一个虚拟机并在虚拟机上安装Linux系统),此处博主建议直接在自己的板载实现ONNX到RKNN的转换,这对于后续的推理验证也是比较方便的。
板载Linux系统的安装请大家根据自己购买开发板厂商那的开源项目安装,此处大家情况不尽相同此处不赘述。
大家如果不习惯全部用指令操作Linux系统,可以下载一个Nomachine工具来远程可视化的操作板载Linux系统。
2.2.2 下载并配置RKNN-Tollkit2环境
到瑞芯微的官方github开源的RKNN-Tollkit2项目上下载:airockchip/rknn-toolkit2
把这个项目下载到2.2.1步骤的Linux系统上:
瑞芯微把说明文档都放到了rknn-toolkit2master/doc下面了,大家可以多读读官方文档,对工具包的API有更清晰的理解。
以下说明具体的环境配置:
①大家先通过以下指令检查自己安装的Linux的Ubuntu版本:
lsb_release -a
博主的Ubuntu版本是22.04.5,参考官方文档,对应的python版本应该是3.10/3.11:
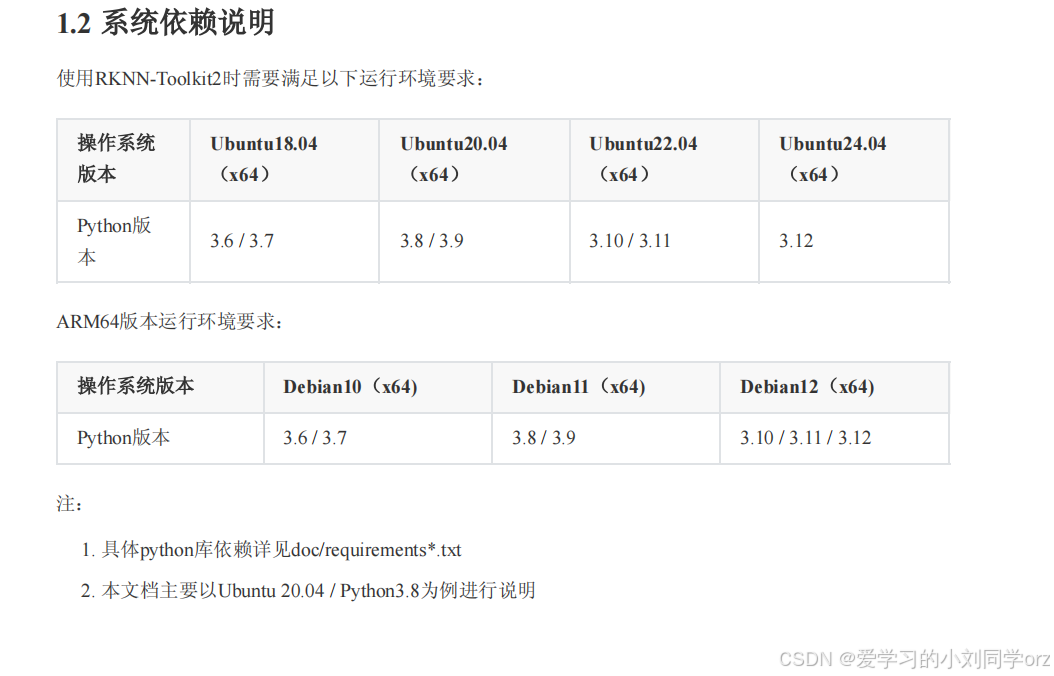
②在Linux上安装miniconda,用miniconda安装好3.10/3.11版本的python。
③在控制台中把目录转到rknn工具包的库地址:
cd /home/orangepi/rknn-toolkit2-master/rknn-toolkit2/packages/arm64/在这个目录下安装运行的库:
pip install -r arm64_requirements_cp310.txt注意:安装的cpxx版本要和自己的python版本对应
然后再安装:
pip install rknn_toolkit2-2.3.0-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl注意到官方文档的内容:
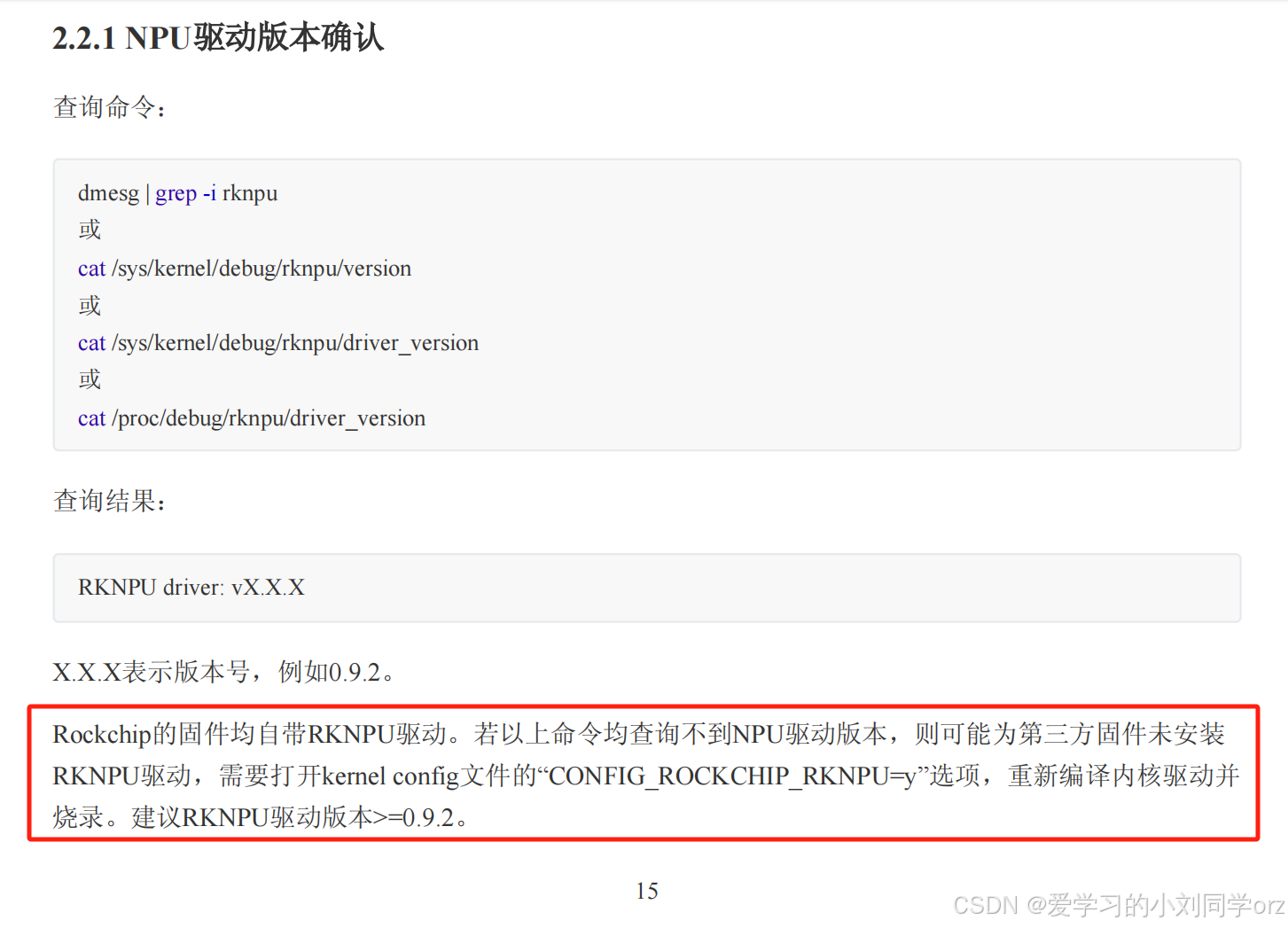
如果大家根据以上步骤完成安装后可以通过上面的命令查看安装的NPU驱动版本。
2.2.3 把训练好的ONNX模型转换为RKNN模型
推荐大家使用FileZilla工具,可以很方便把个人电脑的文件传到板载系统上。
①把上面所述训练好的ONNX模型传到板载Linux系统上
②修改RKNN-Toolkit2目录下的例程来生成RKNN模型:
这里大家情况都不相同,博主贴上关键的代码脚本(根据rknn-toolkit2/examples/onnx/resnet50v2这个脚本改的):
if __name__ == '__main__':
# Create RKNN object
rknn = RKNN(verbose=True)
if not os.path.exists(ONNX_MODEL):
print('Dosent exists ONNX_MODEL')
# pre-process config
print('--> config model')
rknn.config(mean_values=None, std_values=None,
target_platform='rk3588')
print('done')
# Load model
print('--> Loading model')
ret = rknn.load_onnx(model=ONNX_MODEL)
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=False) # No quantization
if ret != 0:
print('Build model failed!')
exit(ret)
print('done')
# Export rknn model
print('--> Export rknn model')
ret = rknn.export_rknn(RKNN_MODEL)
if ret != 0:
print('Export rknn model failed!')
exit(ret)
print('done')
# Init runtime environment
print('--> Init runtime environment')
ret = rknn.init_runtime() # target = 'rk3588'
if ret != 0:
print('Init runtime environment failed!')
exit(ret)
print('done')
# Inference
print('--> Running model')其中很关键的,大家要把config中的平台改成自己的硬件平台:
rknn.config(mean_values=None, std_values=None,
target_platform='rk3588')运行完上面的代码后可以转换出RKNN模型,可以先进行模拟运行(不在NPU上运行)验证转换RKNN模型的准确性:
ret = rknn.init_runtime()这个API的输入是空的话默认就是模拟运行
博主训练完的模型在同样样本跑的结果前后对比(博主的网络是进行音频去噪)
在原pytorch模型上的去噪前后对比:
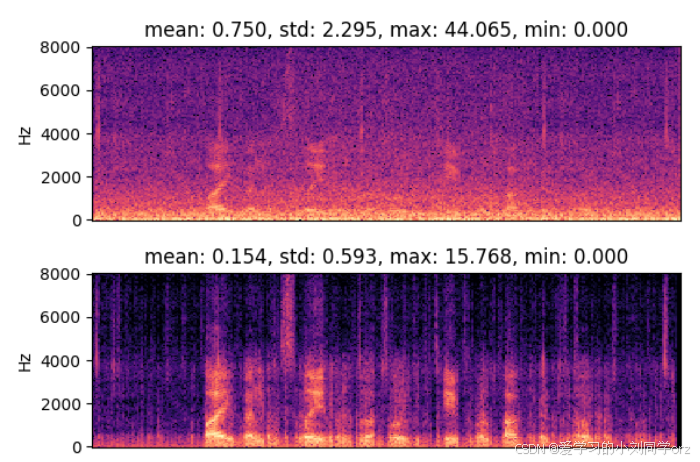
上图是带噪语音,下图是经过模型去噪后的结果。
转换成RKNN模型模拟处理的结果:
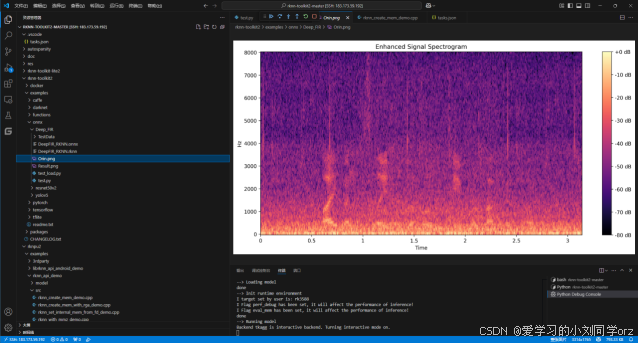
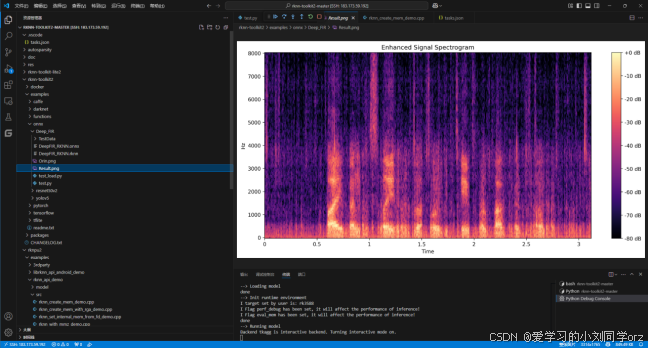
可以看到两者的处理结果基本一致。
3. python上的模型部署
通过以下代码加载rknn模型并且进行板载推理:
if __name__ == '__main__':
# Create RKNN object
rknn = RKNN(verbose=True)
# pre-process config
print('--> config model')
rknn.config(mean_values=None, std_values=None,
target_platform='rk3588')
print('done')
# Load model
print('--> Loading model')
ret = rknn.load_rknn(RKNN_MODEL)
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
# Init runtime environment
print('--> Init runtime environment')
ret = rknn.init_runtime(target = 'rk3588',perf_debug = True,eval_mem=True) #target = 'rk3588',target = 'rk3588',core_mask = RKNN.NPU_CORE_AUTO
if ret != 0:
print('Init runtime environment failed!')
exit(ret)
print('done')
这里有个困扰了博主非常久的坑,运行这一步的时候代码一直会报错:
ret = rknn.init_runtime(target = 'rk3588',perf_debug = True,eval_mem=True)报错内容:

这里提示说到板载的librknnrt太低,而加载的模型版本很新,导致无法适配。官方文档似乎没有对librknnrt的版本更新进行说明librknnrt.so是板载runtime的运行库,如果不适配会导致NPU运行失败并报错。
此处的解决方法:
到下载的rknn-toolkit2工程目录:
/home/orangepi/rknn-toolkit2-master/rknpu2/runtime/Linux/librknn_api/aarch64/到这个目录下找到最新的librknnrt.so文件:
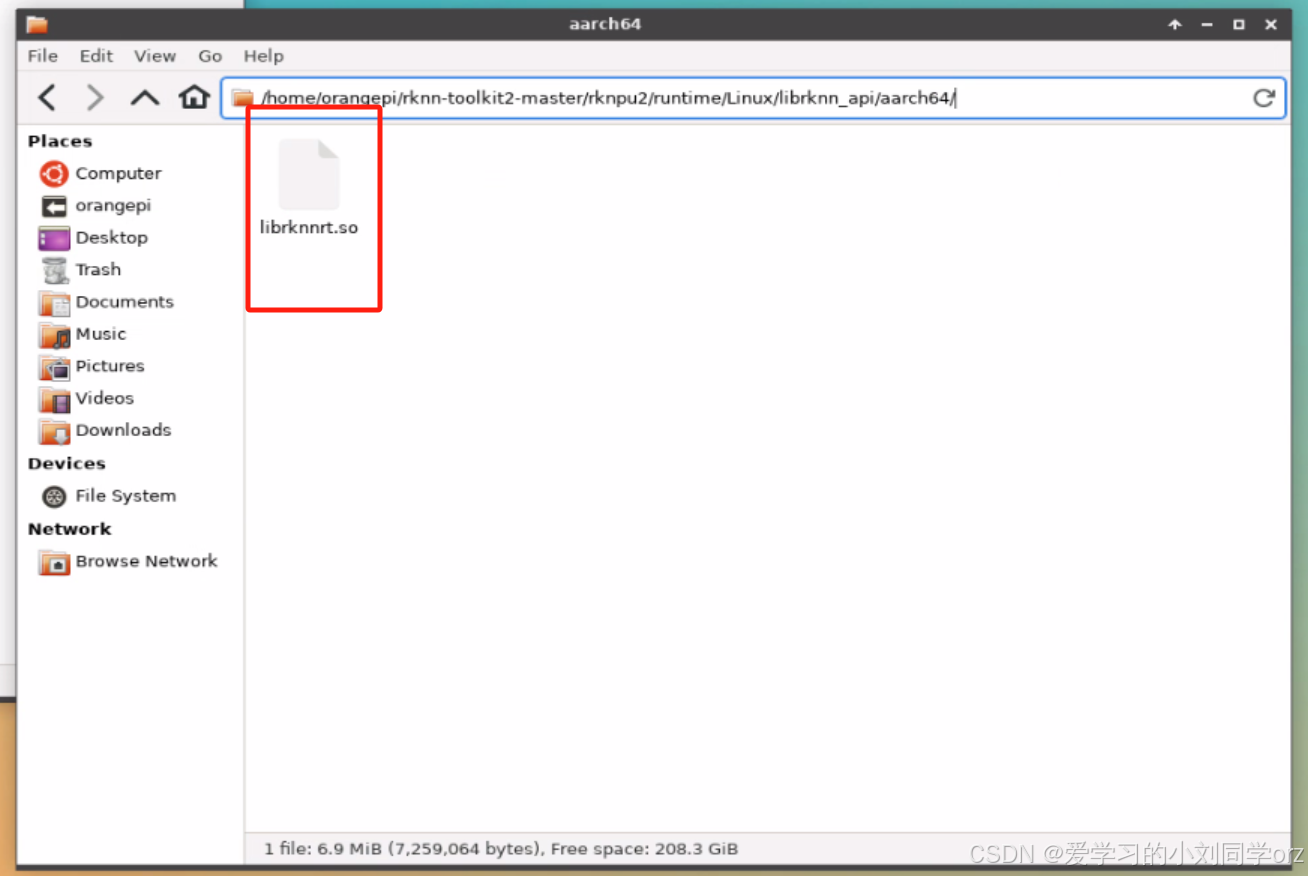
把这个文件替换
/usr/lib64/librknnrt.so替换完后就完成所有环境的搭建了,再运行一次以上代码就发现结果正常了。

















 843
843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









