







(1)Which of the following do you typically see as you move to deeper layer in a ConvNet?
[A]
n
H
n_H
nH and
n
W
n_W
nW decrease, while
n
C
n_C
nC increases.
[B]
n
H
n_H
nH and
n
W
n_W
nW decrease, while
n
C
n_C
nC also decreases.
[C]
n
H
n_H
nH and
n
W
n_W
nW increases, while
n
C
n_C
nC also increases.
[D]
n
H
n_H
nH and
n
W
n_W
nW increases, while
n
C
n_C
nC decreases.
答案:A
解析:典型的卷积网络结构如下。
LeNet-5网络结构如下: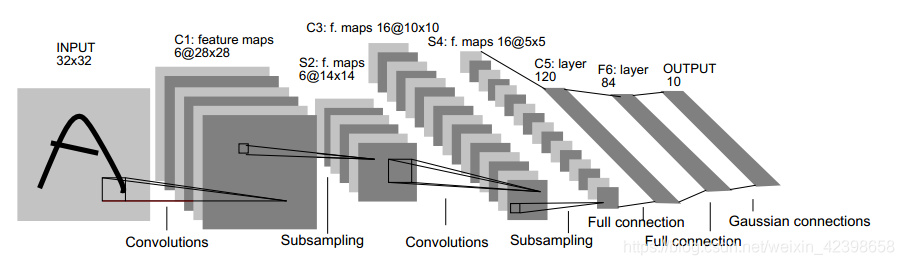
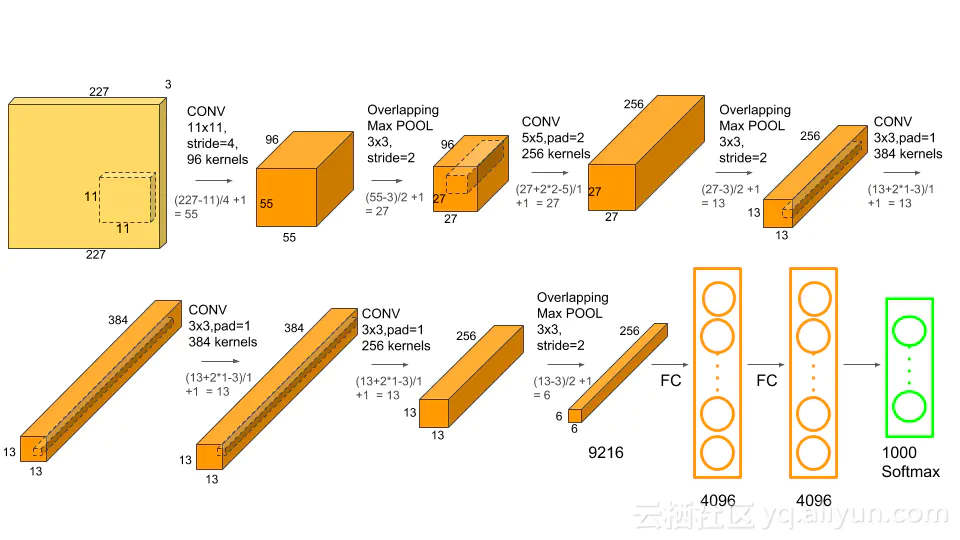
AlexNet网络结构如下:
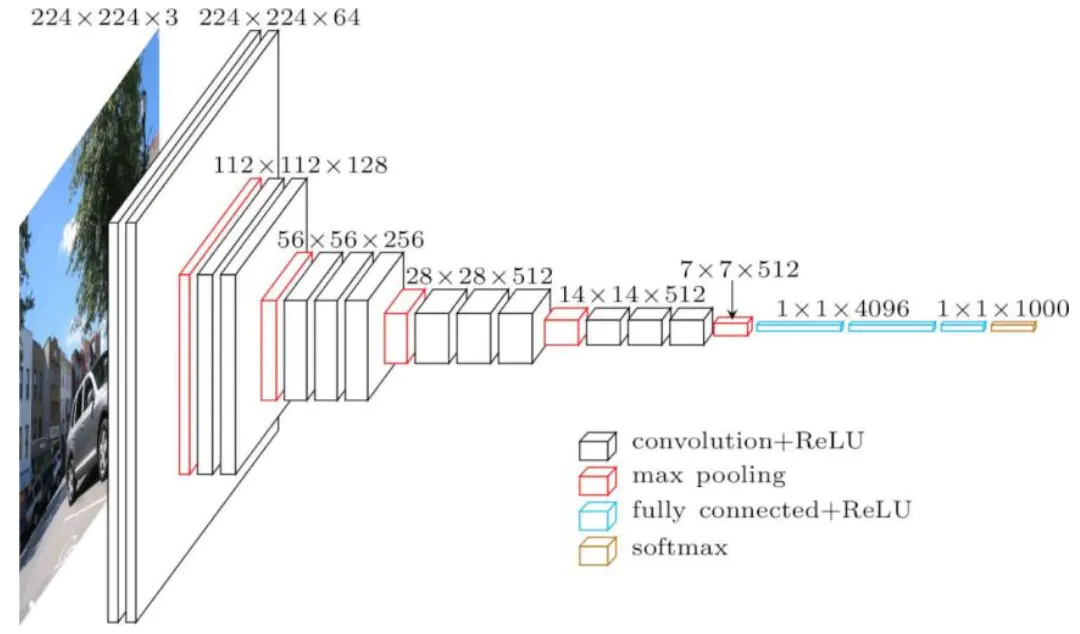
VGG-16网络结构如下:
(2)Which of the following do you typically see in a ConvNet? (Check
all that apply.)
[A]Multiple CONV layers followed by a POOL layer.
[B]Multiple POOL layers followed by a CONV layer.
[C]FC layers in the last few layers.
[D]FC layers in the first few layers.
答案:A,C
解析:典型的卷积网络结构如上题所示
(3)In order to be able to build very deep networks, we usually only use pooling layers to downsize the height/width of the activation volumes while convolutions are used with “valid” padding. Otherwise, we would downsize the input of the model too quickly.
[A]True
[B]False
答案:B
解析:构建比较深的网络,卷积层一般用"same" padding 。如果用"valid" padding 的话每一次卷积操作都会使 height/width 缩小
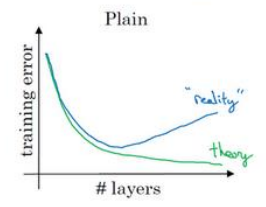
(4)Training a deeper network (for example, adding additional layers to the network) allows the network to fit more complex functions and thus almost always results in lower training error. For this question, assume we’re referring to “plain” networks.
[A]True
[B]False
答案:B
解析:对于普通的网络,理论上随着网络深度的加深,应该训练的越来越好;但是实际情况随着网络深度的加深,训练误差会先减少然后增多。
(5)The following equation captures the computation in a ResNet block. What goes into the two blanks above?
a
[
l
+
2
]
=
g
(
W
[
l
+
2
]
g
(
W
[
l
+
1
]
a
[
l
]
+
b
[
l
+
1
]
)
+
b
[
l
+
2
]
+
_
_
_
_
_
_
_
)
+
_
_
_
_
_
_
_
a^{[l+2]}=g(W^{[l+2]}g(W^{[l+1]}a^{[l]}+b^{[l+1]})+b^{[l+2]}+\_\_\_\_\_\_\_)+\_\_\_\_\_\_\_
a[l+2]=g(W[l+2]g(W[l+1]a[l]+b[l+1])+b[l+2]+_______)+_______
[A]
z
[
l
]
z^{[l]}
z[l] and
a
[
l
]
a^{[l]}
a[l], respectively
[B]
a
[
l
]
a^{[l]}
a[l] and 0, respectively
[C]
0
0
0 and
a
[
l
]
a^{[l]}
a[l], respectively
[D]
0
0
0 and
z
[
l
+
1
]
z^{[l+1]}
z[l+1], respectively
答案:B
解析:
a
[
l
+
2
]
=
g
(
z
[
l
+
2
]
+
a
[
l
]
)
=
g
(
W
[
l
+
2
]
a
[
l
+
1
]
+
b
[
l
+
2
]
+
a
[
l
]
)
=
g
(
W
[
l
+
2
]
g
(
z
[
l
+
1
]
)
+
b
[
l
+
2
]
+
a
[
l
]
)
=
g
(
W
[
l
+
2
]
g
(
W
[
l
+
1
]
a
[
l
]
+
b
[
l
+
1
]
)
+
b
[
l
+
2
]
+
a
[
l
]
)
\begin{aligned} a^{[ l+2 ]}&=g( z^{[ l+2 ]}+a^{[ l ]} ) \\ &=g( W^{[ l+2 ]}a^{[ l+1 ]}+b^{[ l+2 ]}+a^{[ l ]} ) \\ &=g( W^{[ l+2 ]}g( z^{[ l+1 ]} ) +b^{[ l+2 ]}+a^{[ l ]} ) \\ &=g( W^{[ l+2 ]}g( W^{[ l+1 ]}a^{[ l ]}+b^{[ l+1 ]} ) +b^{[ l+2 ]}+a^{[ l ]} ) \end{aligned}
a[l+2]=g(z[l+2]+a[l])=g(W[l+2]a[l+1]+b[l+2]+a[l])=g(W[l+2]g(z[l+1])+b[l+2]+a[l])=g(W[l+2]g(W[l+1]a[l]+b[l+1])+b[l+2]+a[l])
(6)Which ones of the following statements on Residual Networks are true?(Check all that apply.)
[A]A ResNet with
L
L
L layers would have on the order of
L
2
L^2
L2 skip connections in total.
[B]The skip-connection makes it easy for the network to learn an identity mapping between the input and the output within the ResNet block.
[C]Using a skip-connection helps the gradient to backpropagate and thus helps you to train deeper networks.
[D]The skip-connections compute a complex non-linear function of the input to pass to a deeper layer in the network.
答案:B,C
解析:
在残差网络中 skip connections 的数量不会大于层数,故A错。注意和 DenseNet 区分。下面展示了两种常见的残差网络块。
如下图所示,skip-connections是直接短接过去,而没有进行计算。
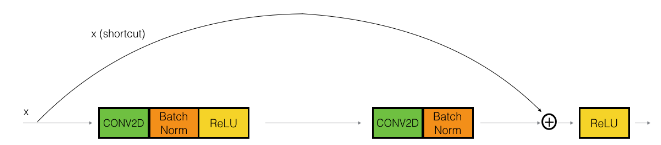
即使是下图所示形式,CONV2D层只是用于调整维度,而没有进行非线性计算。

故D错。
(7)Suppose you have an input volume of dimension 64x64x16. How many parameters would a single 1x1 convolutional filter have (including the bias)?
[A] 2
[B] 17
[C] 1
[D] 4097
答案:B
解析:filter的维度为1x1x16,再加上1个bias,总参数个数为17 。
(8)Suppose you have an input volume of dimension
n
H
×
n
W
×
n
C
n_H\times n_W\times n_C
nH×nW×nC . Which of the following statements you agree with? (Assume that “1x1 convolutional layer” below always uses a stride of 1 and no padding.)
[A]You can use a 1x1 convolutional layer to reduce
n
H
n_H
nH,
n
W
n_W
nW, and
n
C
n_C
nC.
[B]You can use a pooling layer to reduce
n
H
n_H
nH,
n
W
n_W
nW, and
n
C
n_C
nC.
[C]You can use a pooling layer to reduce
n
H
n_H
nH,
n
W
n_W
nW, but not
n
C
n_C
nC.
[D]You can use a 1x1 convolutional layer to reduce
n
C
n_C
nC but not
n
H
n_H
nH,
n
W
n_W
nW.
答案:C,D
(9)Which ones of the following statements on Inception Network are true? (Check all that apply.)
[A]Making an inception network deeper (by stacking more inception blocks together) should not hurt training set performance.
[B]A single inception block allows the network to use a combination of 1x1, 3x3, 5x5 convolutions and pooling.
[C]Inception networks incorporates a variety of network architectures (similar to dropout, which randomly chooses a network architecture on each step) and thus has a similar regularizing effect as dropout.
[D]Inception blocks usually use 1x1 convolutions to reduce the input data volume’s size before applying 3x3 and 5x5 convolutions.
答案:B,D
解析:参考GoogLeNet,为防止中间梯度消失,采用了辅助分类器,如图所示:
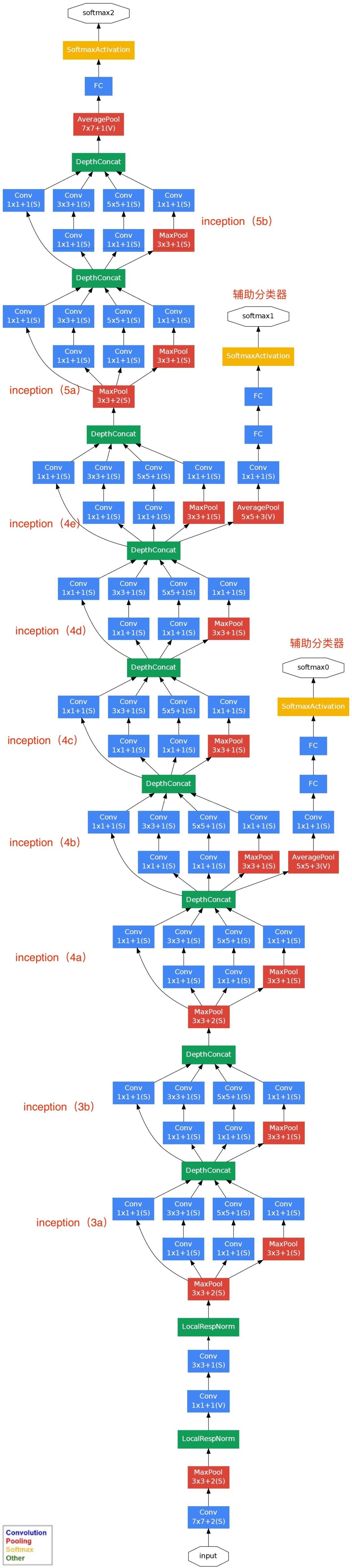
故A错。
Inception networks 不模仿dropout 随机选择网络结构,而是将这些网络结构堆叠起来,如图所示:
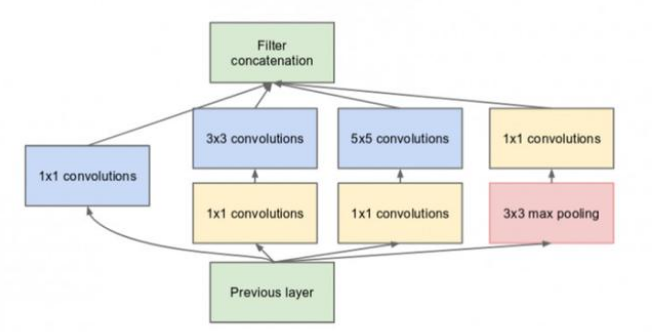
故C错。
(10)Which of the following are common reasons for using open-source implementations of ConvNets (both the model and/or weights)? (Check all that apply)
[A]Parameters trained for one computer vision task are often useful as pretraining for other computer vision tasks.
[B]The same techniques for winning computer vision competitions, such as using multiple crops at test time, are widely used in practical deployments (or production system deployments) of ConvNets.
[C]It is a convenient way to get working an implementation of a complex ConvNet architecture.
[D]A model trained for one computer vision task can usually be used to perform data augmentation even for a different computer vision task.
答案:A,C
解析:竞赛的一些技巧不适用于实际环境,因为太耗费算力资源,故B错。
一个训练好的计算机视觉任务模型可以通过迁移学习用于另一个任务,而不是数据增强,故D错。














 421
421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









