






nvidia英伟达认证
1 介绍
这是我们学校高性能计算的课程任务,最后会得到这样一个证书。

要完成这个认证,一共有三个任务,前面两个任务就自己慢慢学慢慢看就行,第三个任务有个小测试。
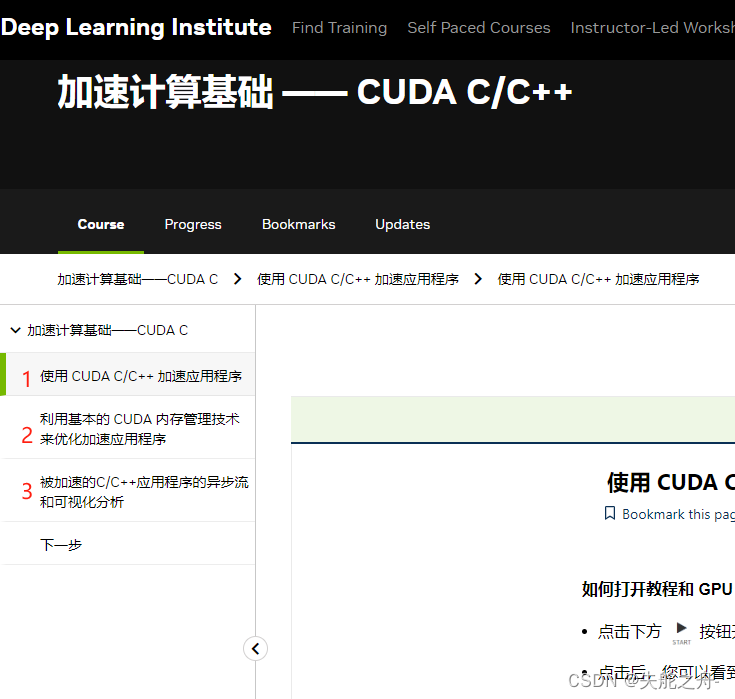
2 完成任务1和任务2
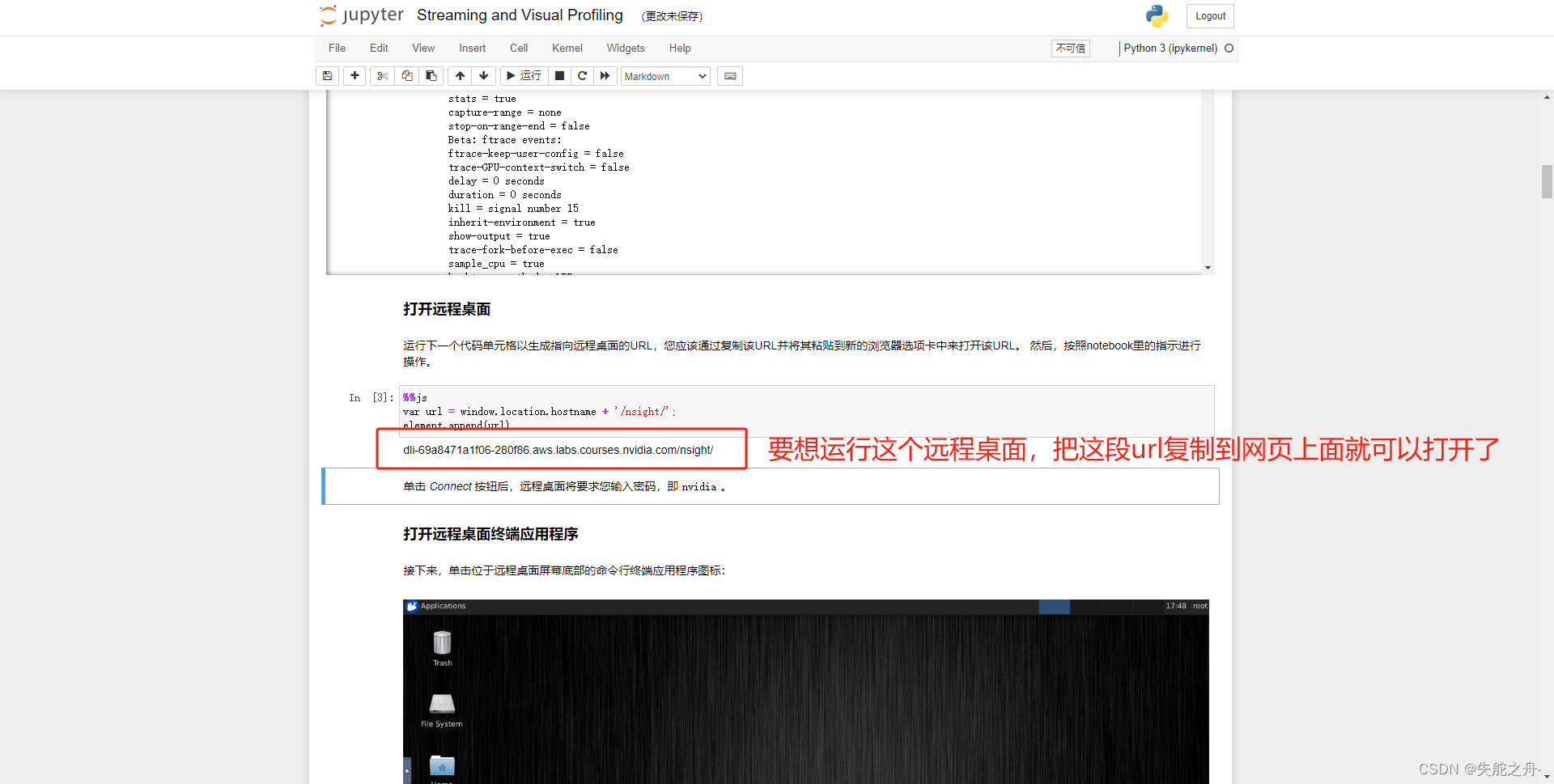
图片看不清楚的话,双击就会放大。
点击start开始
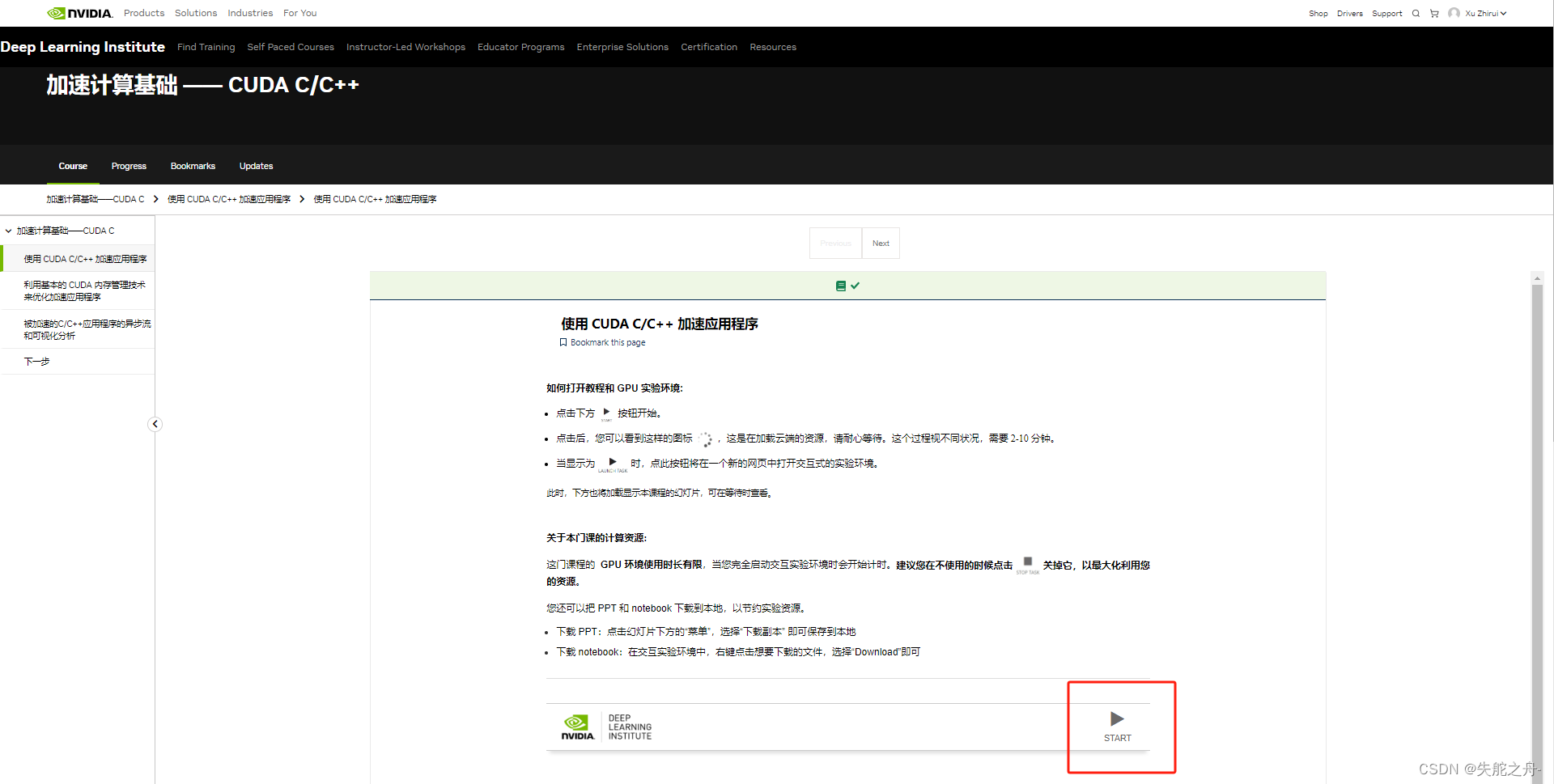

打开之后就是jupyter notebook
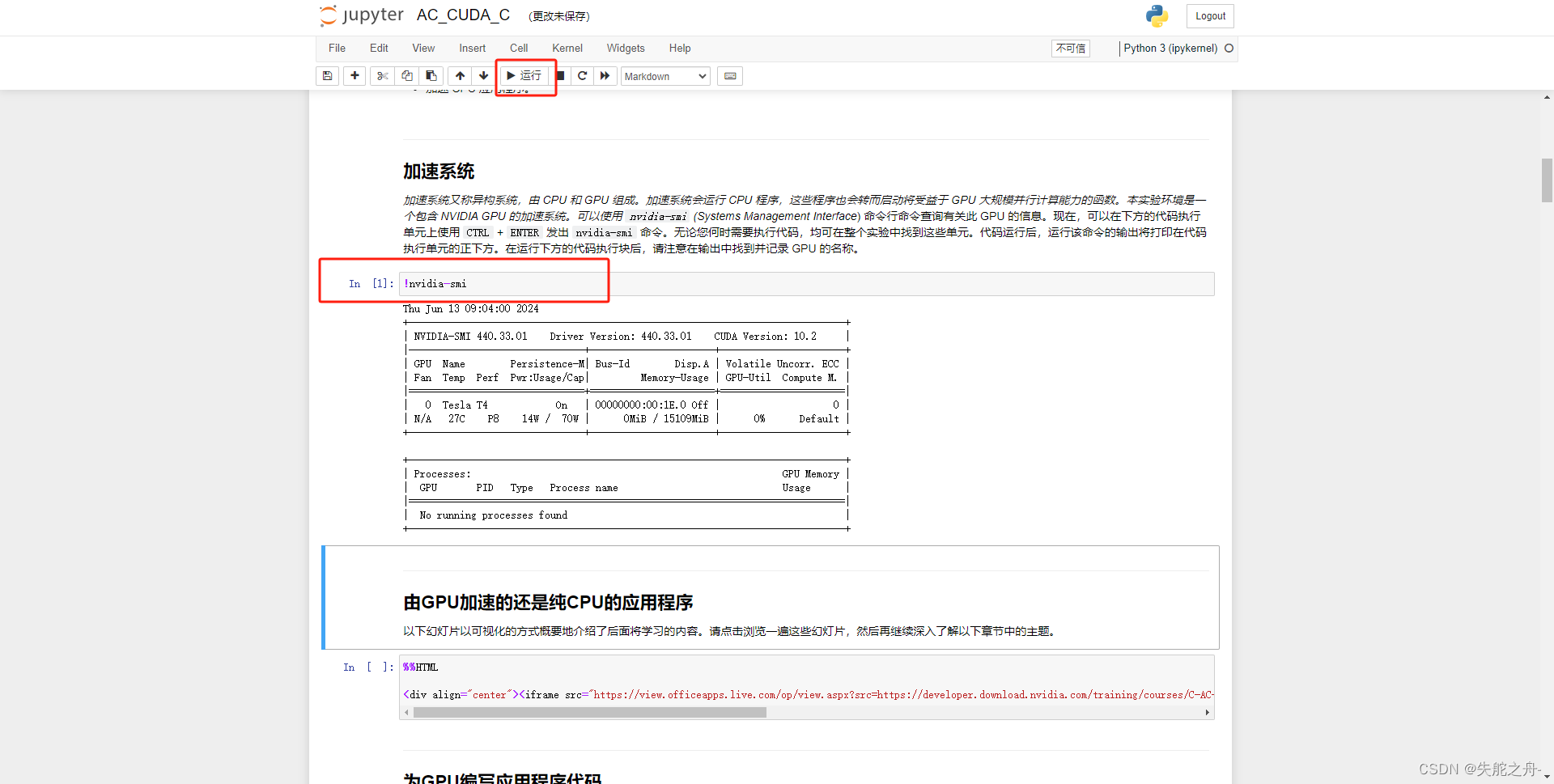
接下来一个个运行,自己认真学习即可,做完就点stop task,任务二也是这样。
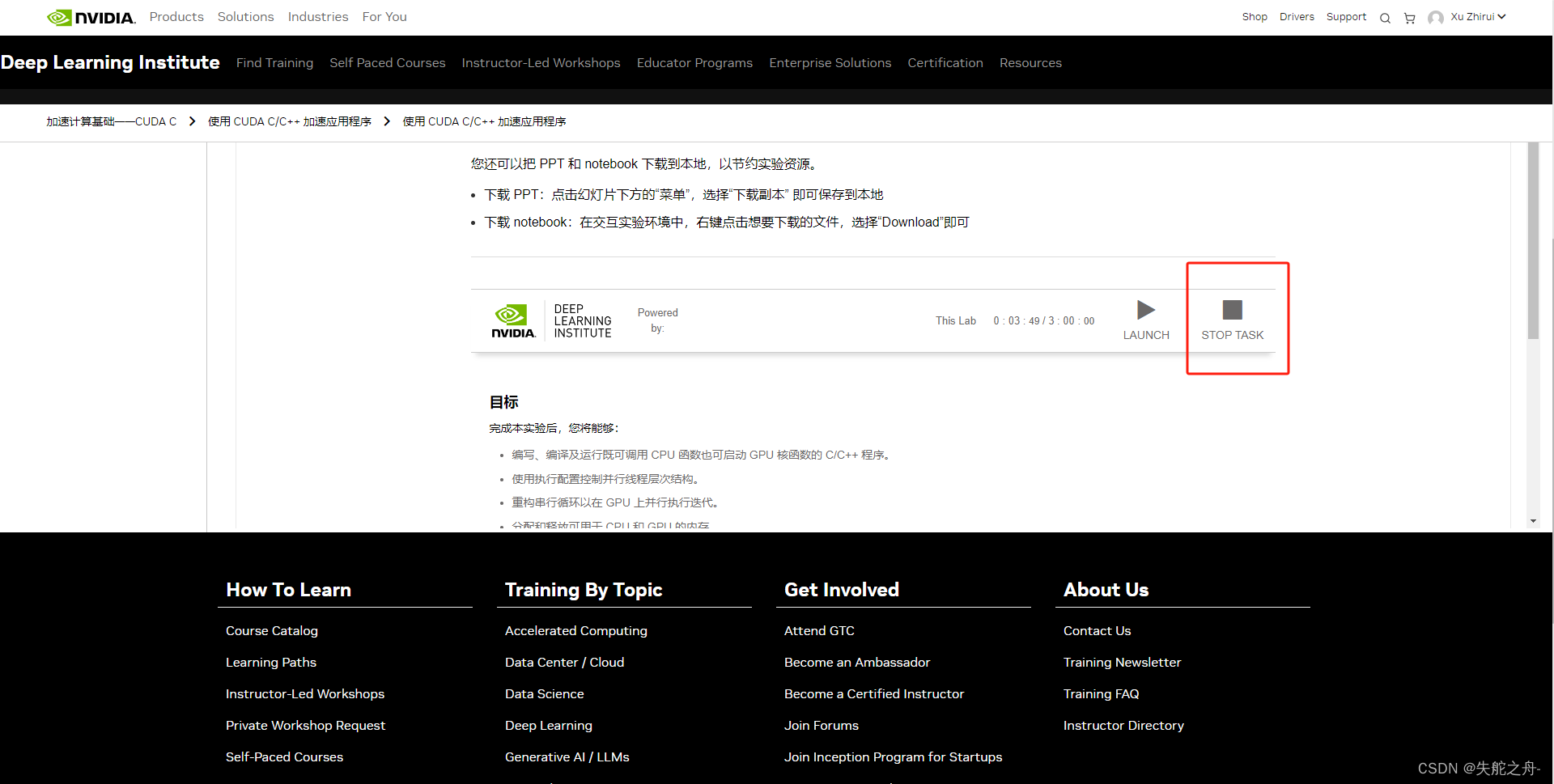
3 完成任务3
前面都是一步步运行
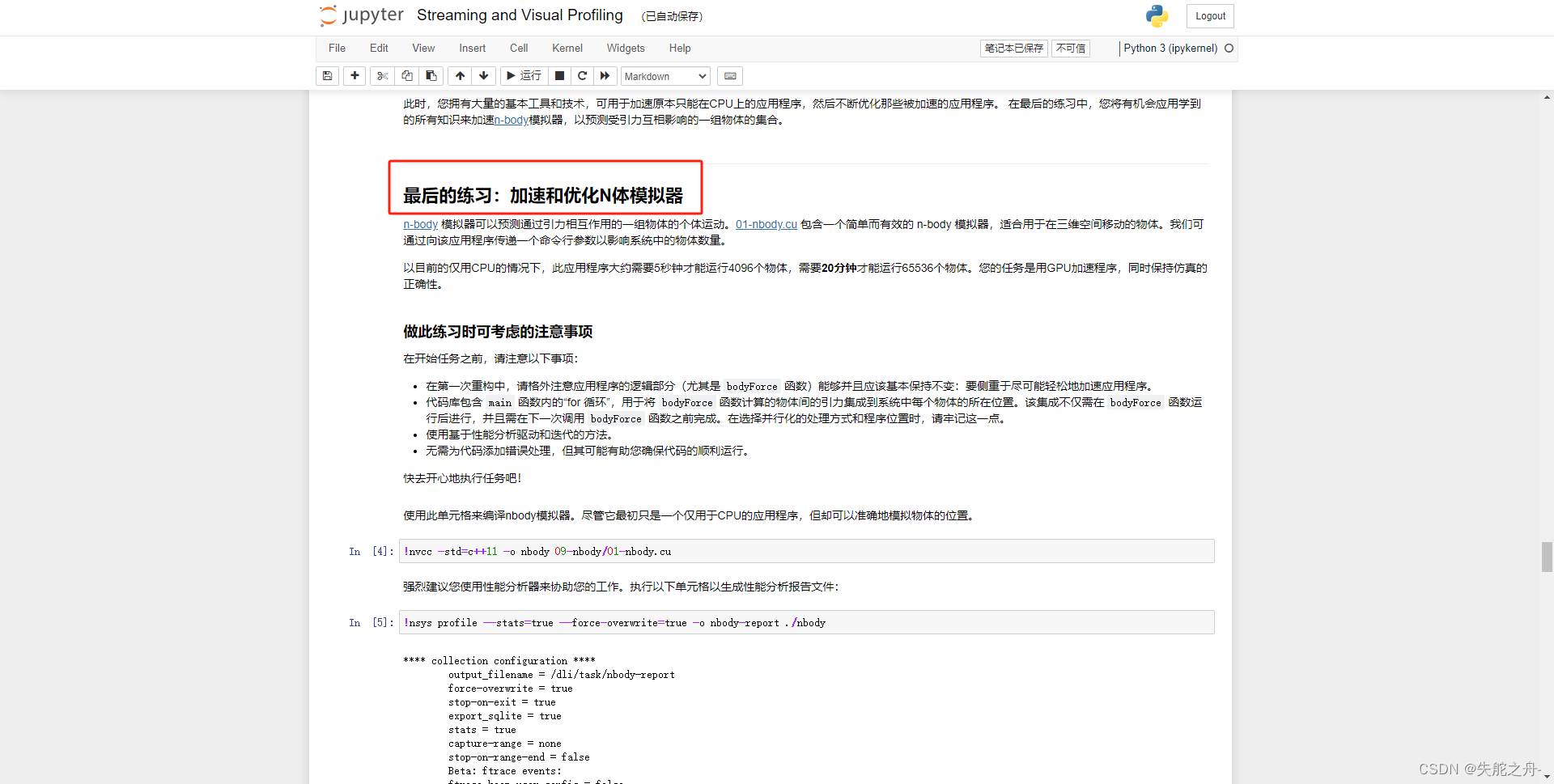
一直到最后的练习:加速和优化N体模拟器
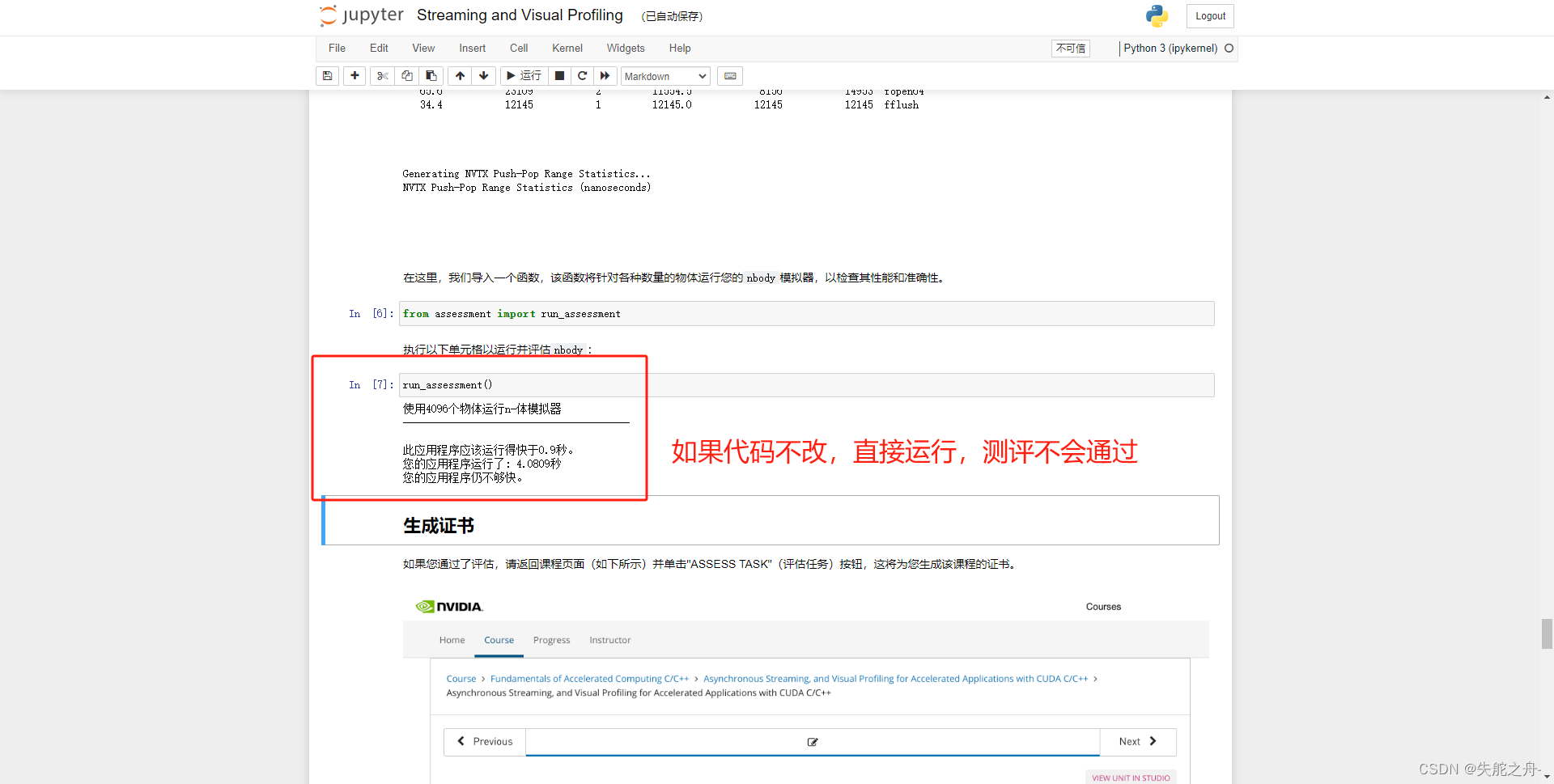
3.1 代码
#include <math.h>
#include <stdio.h>
#include <stdlib.h>
#include "timer.h"
#include "files.h"
#define SOFTENING 1e-9f
/*
* Each body contains x, y, and z coordinate positions,
* as well as velocities in the x, y, and z directions.
*/
typedef struct { float x, y, z, vx, vy, vz; } Body;
/*
* Calculate the gravitational impact of all bodies in the system
* on all others.
*/
__global__ void bodyForce(Body *p, float dt, int n) {
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i+=stride) {
float Fx = 0.0f; float Fy = 0.0f; float Fz = 0.0f;
for (int j = 0; j < n; j++) {
float dx = p[j].x - p[i].x;
float dy = p[j].y - p[i].y;
float dz = p[j].z - p[i].z;
float distSqr = dx*dx + dy*dy + dz*dz + SOFTENING;
float invDist = rsqrtf(distSqr);
float invDist3 = invDist * invDist * invDist;
Fx += dx * invDist3; Fy += dy * invDist3; Fz += dz * invDist3;
}
p[i].vx += dt*Fx; p[i].vy += dt*Fy; p[i].vz += dt*Fz;
}
}
int main(const int argc, const char** argv) {
int deviceId;
int numberOfSMs;
cudaGetDevice(&deviceId);
cudaDeviceGetAttribute(&numberOfSMs, cudaDevAttrMultiProcessorCount, deviceId);
// The assessment will test against both 2<11 and 2<15.
// Feel free to pass the command line argument 15 when you gernate ./nbody report files
int nBodies = 2<<11;
if (argc > 1) nBodies = 2<<atoi(argv[1]);
// The assessment will pass hidden initialized values to check for correctness.
// You should not make changes to these files, or else the assessment will not work.
const char * initialized_values;
const char * solution_values;
if (nBodies == 2<<11) {
initialized_values = "files/initialized_4096";
solution_values = "files/solution_4096";
} else { // nBodies == 2<<15
initialized_values = "files/initialized_65536";
solution_values = "files/solution_65536";
}
if (argc > 2) initialized_values = argv[2];
if (argc > 3) solution_values = argv[3];
const float dt = 0.01f; // Time step
const int nIters = 10; // Simulation iterations
int bytes = nBodies * sizeof(Body);
float *buf;
cudaMallocManaged(&buf, bytes);
Body *p = (Body*)buf;
cudaMemPrefetchAsync(p, bytes, deviceId);
read_values_from_file(initialized_values, buf, bytes);
double totalTime = 0.0;
/*
* This simulation will run for 10 cycles of time, calculating gravitational
* interaction amongst bodies, and adjusting their positions to reflect.
*/
for (int iter = 0; iter < nIters; iter++) {
StartTimer();
/*
* You will likely wish to refactor the work being done in `bodyForce`,
* and potentially the work to integrate the positions.
*/
cudaStream_t stream;
cudaStreamCreate(&stream);
int blocknum = nBodies/512;
bodyForce<<<blocknum,512,0,stream>>>(p, dt, nBodies); // compute interbody forces
cudaStreamDestroy(stream);
/*
* This position integration cannot occur until this round of `bodyForce` has completed.
* Also, the next round of `bodyForce` cannot begin until the integration is complete.
*/
cudaDeviceSynchronize();
//cudaMemPrefetchAsync(p, bytes, cudaCpuDeviceId);
for (int i = 0 ; i < nBodies; i++) { // integrate position
p[i].x += p[i].vx*dt;
p[i].y += p[i].vy*dt;
p[i].z += p[i].vz*dt;
}
const double tElapsed = GetTimer() / 1000.0;
totalTime += tElapsed;
}
double avgTime = totalTime / (double)(nIters);
float billionsOfOpsPerSecond = 1e-9 * nBodies * nBodies / avgTime;
write_values_to_file(solution_values, buf, bytes);
// You will likely enjoy watching this value grow as you accelerate the application,
// but beware that a failure to correctly synchronize the device might result in
// unrealistically high values.
printf("%0.3f Billion Interactions / second", billionsOfOpsPerSecond);
free(buf);
}
test_xzr
复制这段代码,打开01-nbody.cu
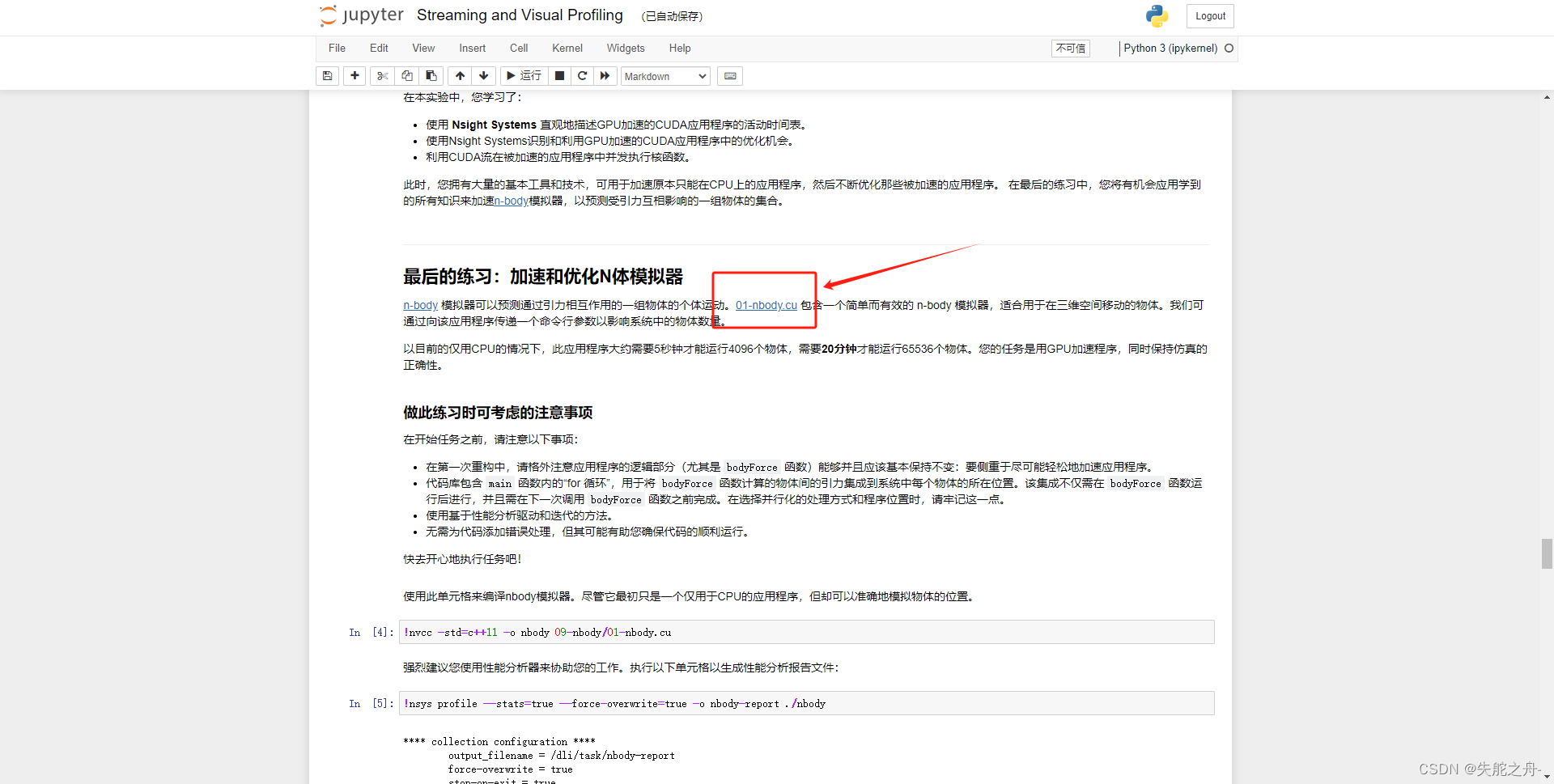
替换这个cuda文件,ctrl+s保存
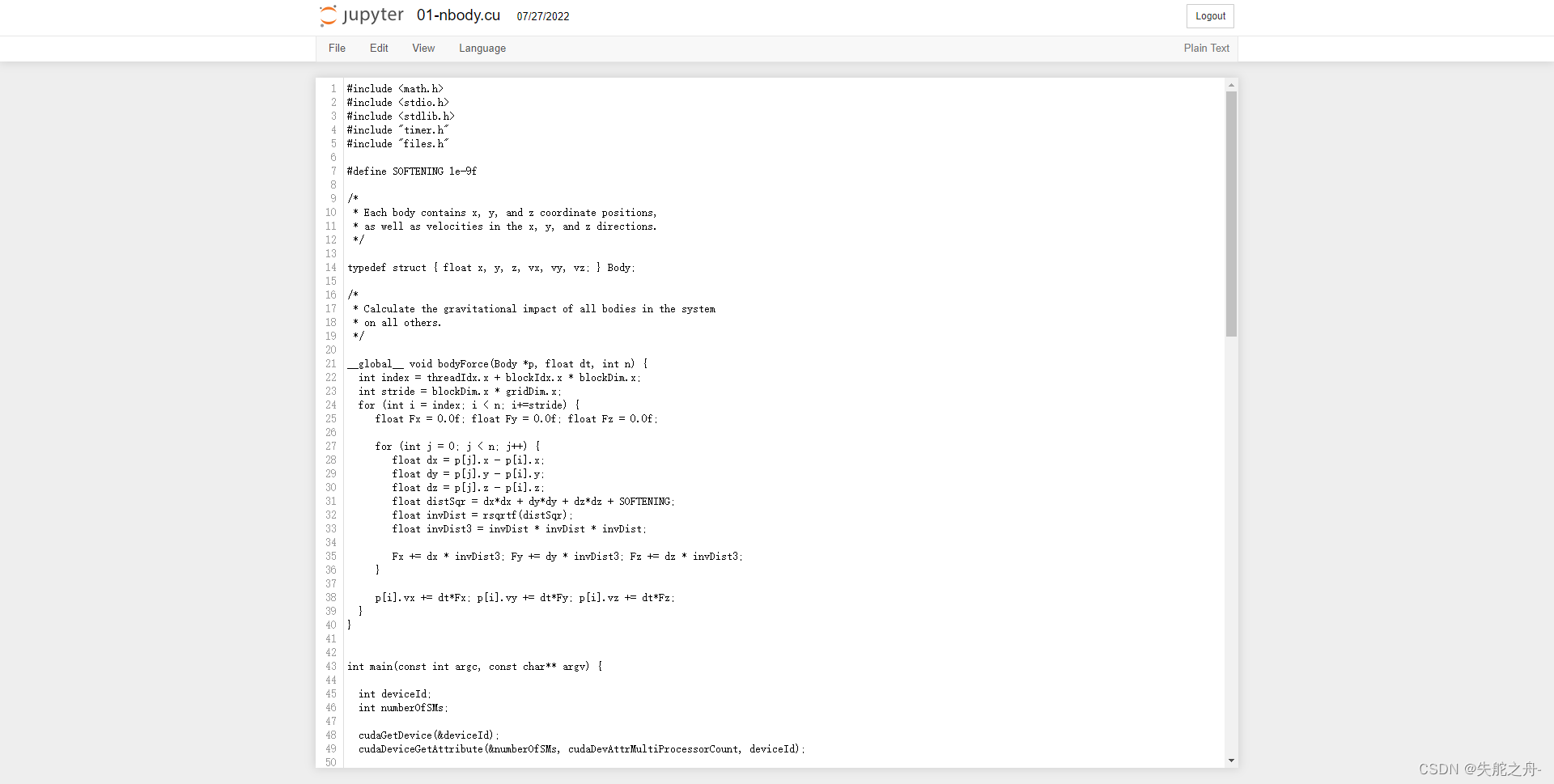
再次运行即可
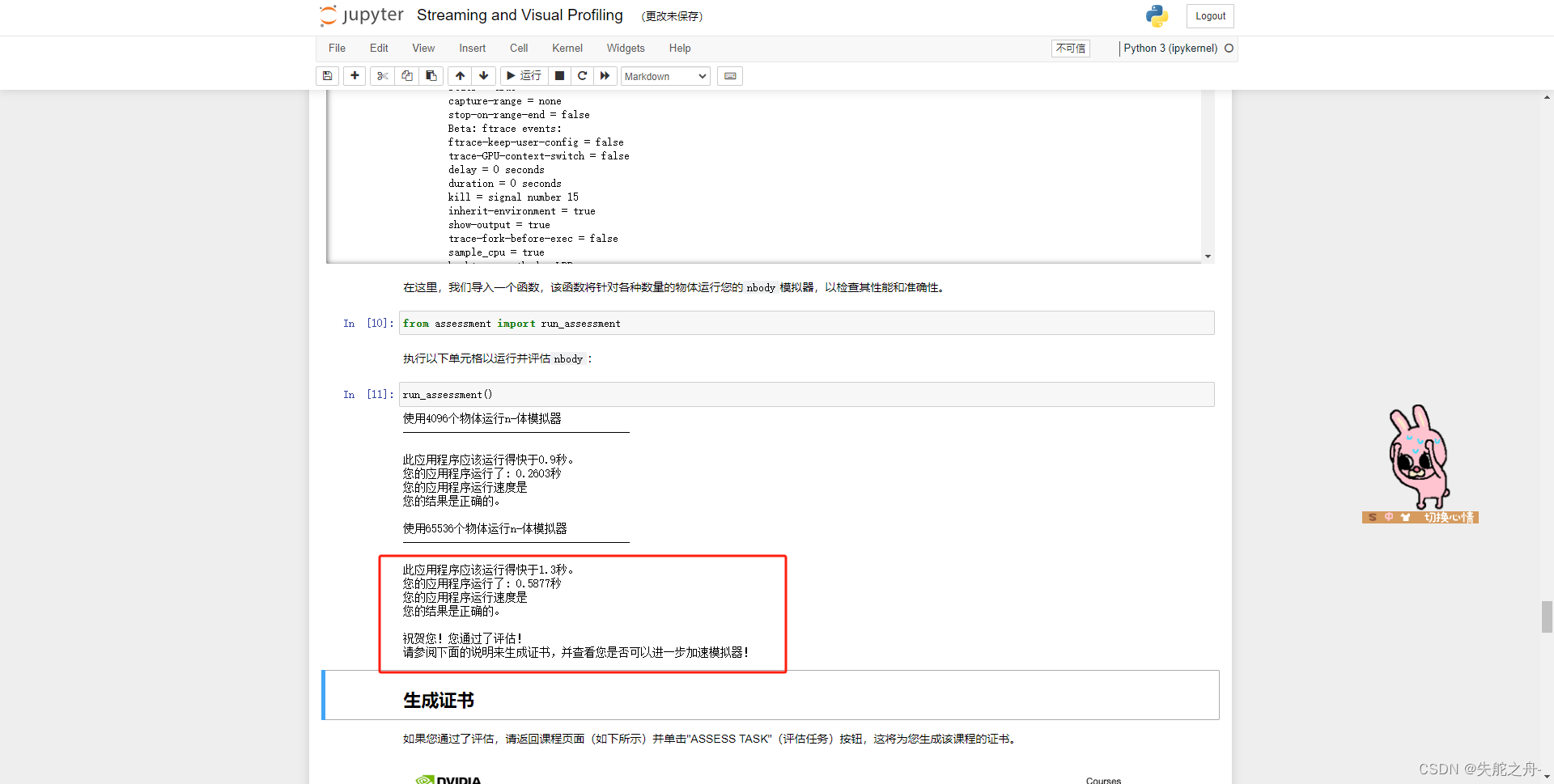
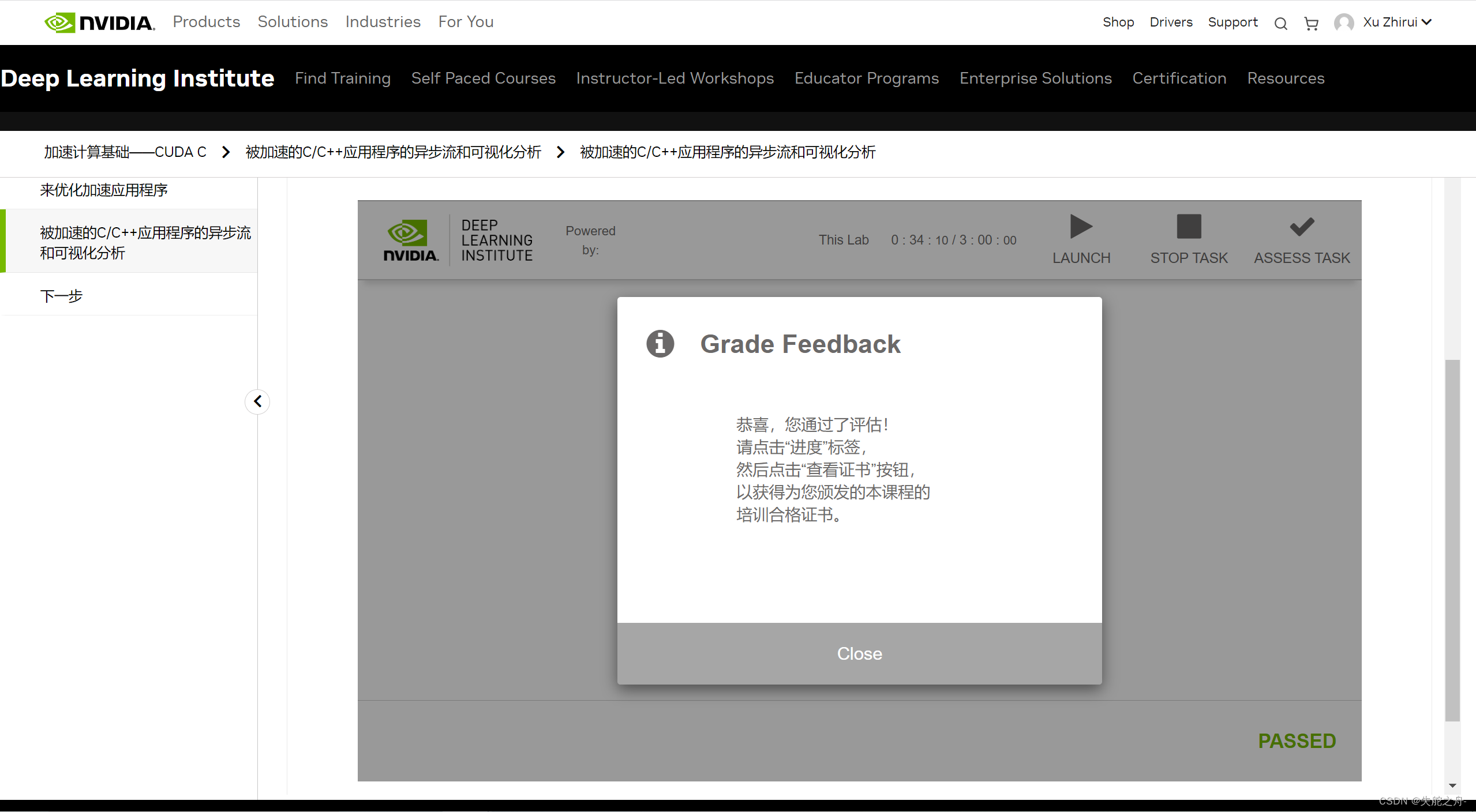
大功告成~


















 1693
1693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











