







数据下载的地址
机器学习的概述
机器学习按实现方法可以分为监督学习和无监督学习,按问题类型可以分为回归问题和分类问题
监督学习
监督学习就是给一组输入变量和输出变量,用机器来学习和计算输入和输出的函数关系,实现以后任给一个输入预测其输出
其中输入变量又叫特征(feature),输出变量又叫标签(label),一组输入输出叫做样本

回归问题和分类问题

回归问题:输出变量取有限个离散值,预测一个连续值输出
分类问题:输出变量为连续型变量,预测一个离散值输出
无监督学习
无监督学习就是只有输入变量没有输出变量,用计算机分析输入变量中隐藏的规律
无监督学习常用于分类和降维,LDA模型

数据预处理DataProcessing
e.g任务目标:通过下列数据预测某人会不会购买商品
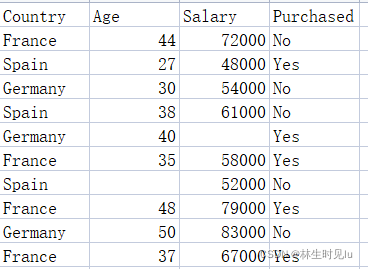
数据集常见的问题
- 缺失数据——解决方法:用当前列的平均值代替缺失的数据
- 分类数据——将不同类别的非数字数据转化为数字数据,使得其可以用方程表示出来
- 将文本数据转化为数字数据时遇到的问题:文本数据中数据没有数值的区分,但转化为数字数据后不同数据间有数字大小的不同,即无形中对数据进行了排序——解决方法:虚拟编码,增加变量的维度
- 不同类数据的数量级不同,需要将不同数量级的数据缩放到同一个数量级里,这就是特征缩放
数据预处理的方法
- 创建自变量的矩阵和因变量的向量
- **处理缺失数据:**运用sklearn.impute库中的Simpleimputer类处理缺失数据
- **处理分类数据:**用sklearn.processing中的LabelEncoder类处理只有两种(如true和false)数据类型的文本类分类数据,用OneHotDecoder类处理多种(多种国家,地区)数据类型的文本类分类数据
- 将数据分为测试集和训练集:运用sklearn.model_selection库中的train_test_split类将数据分为训练集和测试集
- 数据的特征缩放:
- Standardisation:类似于正态分布转化为标准正态分布,将数据转化到0~1范围内
- Normalisation:类似于均匀分布,将数据转化为长度比,也是0~1范围

数据预处理代码
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.impute import SimpleImputer as Imputer
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.compose import ColumnTransformer
dataset = pd.read_csv("Data.csv")
x = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 3].values
imputer = Imputer(missing_values=np.nan, strategy='mean')
imputer = imputer.fit(x[:, 1:3])
x[:, 1:3] = imputer.transform(x[:, 1:3])
# 用虚拟变量将文本数据x转化为三维数字数据
ct = ColumnTransformer([('one_hot_encoder', OneHotEncoder(), [0])], remainder='passthrough')
x = ct.fit_transform(x)
# 用LabelEncoder方法将文本数据y转化为一维数字数据
labelencoder_y = LabelEncoder();
y = labelencoder_y.fit_transform(y)
# 将数据划分为训练集和测试集
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)
# 数据的特征缩放
from sklearn.preprocessing import StandardScaler
sc_x = StandardScaler()
x_train = sc_x.fit_transform(x_train)
x_test = sc_x.transform(x_test)















 3898
3898











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









