







 本文详细介绍了编码器解码器模型在处理不定长序列中的应用,涉及Transformer架构、注意力机制、残差连接、多头注意力、RNN以及预训练和微调的概念。通过实例和原理阐述,帮助读者理解这些关键的IT技术在深度学习中的作用。
本文详细介绍了编码器解码器模型在处理不定长序列中的应用,涉及Transformer架构、注意力机制、残差连接、多头注意力、RNN以及预训练和微调的概念。通过实例和原理阐述,帮助读者理解这些关键的IT技术在深度学习中的作用。
狂补基础知识
编码器解码器
当输入和输出都是不定长序列时,我们可以使用编码器—解码器(encoder-decoder)[1] 或者seq2seq模型
这两个模型本质上都用到了两个循环神经网络,分别叫做编码器和解码器。编码器用来分析输入序列,解码器用来生成输出序列。
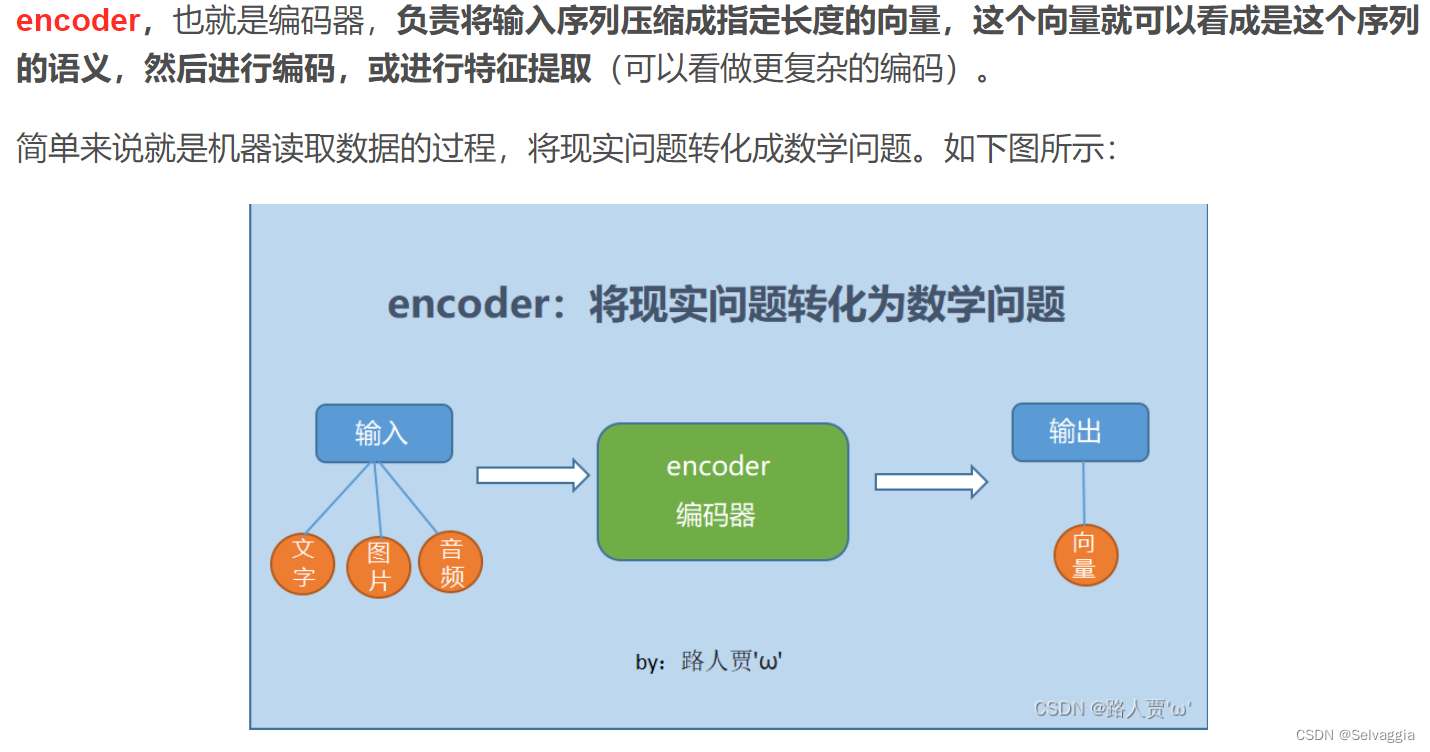
编码器的作用是把一个不定长的输入序列变换成一个定长的背景变量 c ,并在该背景变量中编码输入序列信息。编码器可以使用循环神经网络。
transformer
考虑到RNN(或者LSTM、GRU等)的计算限制是顺序的,也就是说RNN相关算法只能从左向右依次计算或者从右向左依次计算
编码器的输出会作为解码器的输入
Feed Forward Neural Network
Feed Forward Neural Network全连接有两层dense,第一层的激活函数是ReLU(或者其更平滑的版本Gaussian Error Linear Unit-gelu),第二层是一个线性激活函数,如果multi-head输出表示为Z,则FFN可以表示为:

qkv
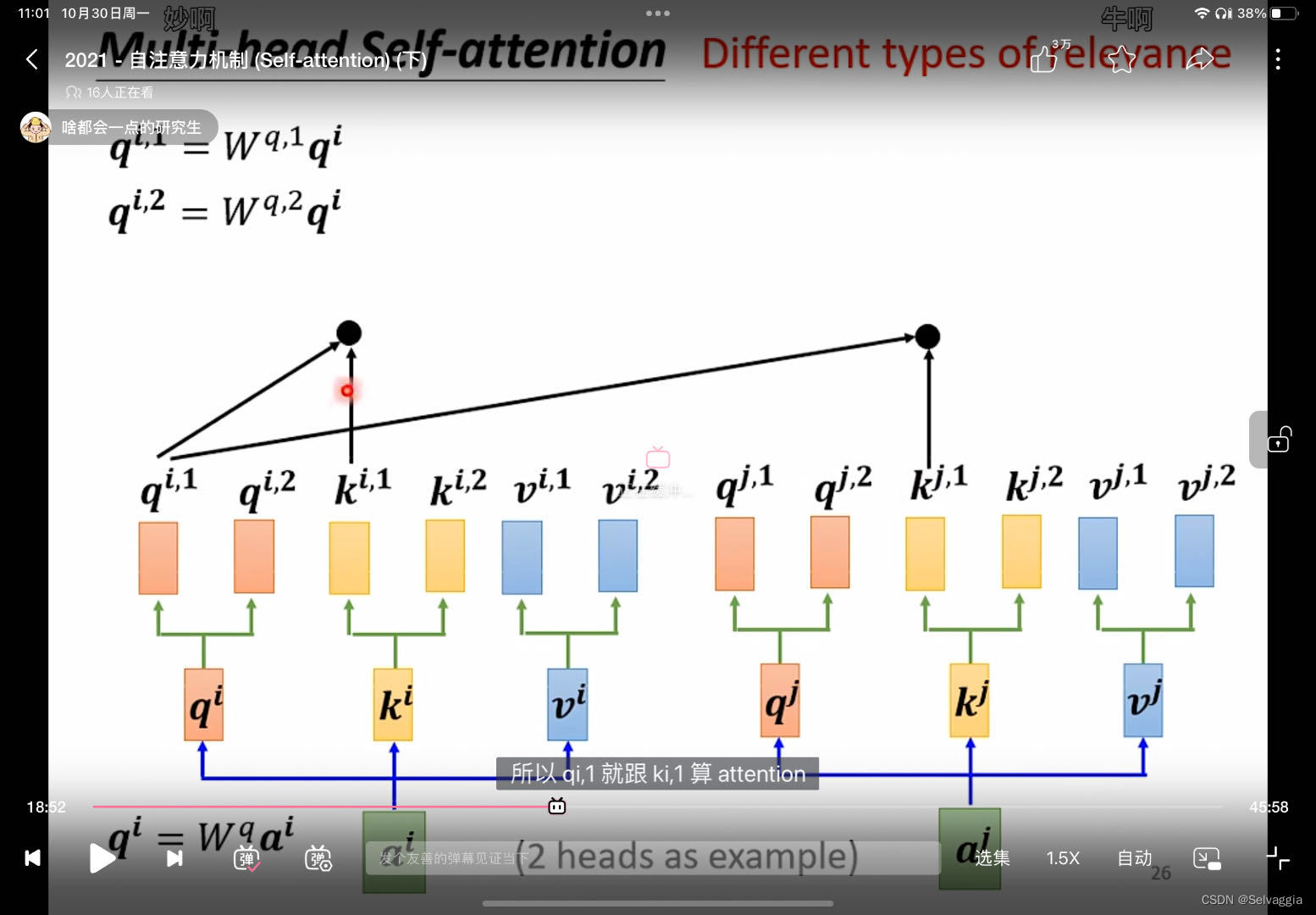
在我们的注意力层中,我们采用三个输入向量,即查询(Q)、键(K)和值(V)。简单的说:查询就像在浏览器上搜索的内容,浏览器会返回一组要匹配的页面它们就是是键,而我们得到真正需要的结果是值。对于句子中的给定词(Q),对于它中的其他词(K),我们得到它(V)对另一个词的相关性和依赖性。这种自我注意过程使用 Q、K 和 V 的 不同权重矩阵(多头)进行了多次计算。因此就是多头注意层,作为多头注意力层的结果,我们得到了多个注意力矩阵。
v的加权和
q和k更相近,k对应的v的加权就更大
权重对应着给的query和 v对应的k 的相似度
kv不变,query变,权重的分配会改变
不同的相似函数导致不同的注意力版本,dot product
output=value的加权和,权重=每个value对应的key和查询的query的相似度计算而来
value是一个单词自身的强度,value的权重是这个单词在某个句子中受环境影响的强度
残差连接
Residual connection(残差连接)是一种在深度神经网络中广泛应用的技术,旨在解决深度神经网络训练过程中的梯度消失和梯度爆炸等问题。
在传统的深度神经网络中,信息需要从一个层传递到下一个层,这个过程中会存在信息的损失。而在残差连接中,模型在每一层中都添加了一个跨层连接,将该层输入与输出相加,从而保留更多的信息。这个跨层连接可以看作是从输入到输出的一条shortcut(捷径)。
残差连接的公式可以表示为: y = f ( x ) + x y = f(x) + x y=f(x)+x,其中 x x x表示该层的输入, f ( x ) f(x) f(x)表示该层的输出, y y y表示残差连接后的输出。在前向传播时, x x x和 f ( x ) f(x) f(x)的和作为该层的输出,直接输入到下一层中进行处理;在反向传播时,残差连接使得梯度可以更容易地回传到前面的层,加速了模型的收敛。
残差连接被广泛应用于深度神经网络中,如ResNet、DenseNet等,取得了在图像分类、目标检测等任务中的优异表现。
什么是residual connection?
残差连接俗称 shortcut,是通过将输入信号与输出信号直接相加,来确保网络在训练时获得“跳层”的能力。具体来说,残差连接在构建神经网络时,将前层的输出直接作为后层的输入之一,将网络中处于两个卷积层之间的其他层称为残差块。
将输入数据直接添加到网络某一层输出之上。这种设计使得信息可以更自由地流动,并且保留了原始输入数据中的细节和语义信息。 使信息更容易传播到后面的层次,避免了信息丢失。跳跃连接通常会通过求和操作或拼接操作来实现。

以图像分类任务为例,假设我们使用卷积神经网络进行特征提取,在每个卷积层后面都加入一个池化层来减小特征图尺寸。然而,池化操作可能导致信息损失。通过添加一个跳跃连接,将原始输入直接与最后一个池化层输出相加或拼接起来,可以保留原始图像中更多的细节和语义信息。
残差网络
残差网络(Residual Network),也被称为ResNet,是一种深度神经网络架构,旨在解决梯度消失和训练困难的问题。它的核心思想是通过引入残差块(residual blocks)来构建网络,并通过跳跃连接将输入直接添加到层输出上。
具体而言,在每个块或子模块内部,输入被加到该块子模块计算后得到的输出上,并且这两者尺寸必须相同。然后再将此结果送入下一个块/子模块进行处理。
其实ResNet的反向传播和训练过程与其他神经网络相似,只是引入了残差连接 (多计算了一步,具体步骤还是如下
前向传播:将输入数据通过网络从前到后进行前向传播。每个残差块中包含了多个卷积层、批归一化层和激活函数等操作。捷径连接将输入直接添加到主路径输出上。
损失计算:在最后一个残差块或全局池化层之后,将得到的特征图作为输入并进行适当的降维操作(例如平均池化)。然后,利用分类器(如全连接层)对提取到的特征进行分类,并计算预测结果与真实标签之间的损失。(似乎都是这样,利用ResNet提取特征,迁移学习后进行分类)
反向传播:根据损失值,在整个网络中执行反向传播来计算梯度。这样可以确定每个参数对于使损失最小化所起到的作用大小,并且梯度会沿着网络方向回溯以更新权重。
权重更新:使用优化算法(如随机梯度下降SGD)根据计算出来的梯度来更新所有网络参数(包括主路径和跳跃连接中使用到节点的参数)。其实只是多计算更新了捷径这里多出来的参数并没有多算参数跳跃连接只是添加将数据添加到后面的神经元,总体参数并没有变化。
迭代训练:重复执行前向传播、损失计算、反向传播和权重更新等步骤,直到达到预设的迭代次数或满足停止条件为止。每个迭代周期称为一个epoch。
【深度学习 | ResNet核心思想】残差连接 & 跳跃连接:让信息自由流动的神奇之道
Cross-Attention
Self -Attention、Multi-Head Attention、Cross-Attention
预训练和微调
pre-training和 fine-tuning 在论文中很常见,初看并不理解其意思,查阅caoqi95分享的文章后才有所明白。
什么是预训练和微调?
你需要搭建一个网络模型来完成一个特定的图像分类的任务。首先,你需要随机初始化参数,然后开始训练网络,不断调整直到网络的损失越来越小。在训练的过程中,一开始初始化的参数会不断变化。当你觉得结果很满意的时候,你就可以将训练模型的参数保存下来,以便训练好的模型可以在下次执行类似任务时获得较好的结果。这个过程就是 pre-training。
之后,你又接收到一个类似的图像分类的任务。这时候,你可以 直接使用之前保存下来的模型的参数来作为这一任务的初始化参数,然后在训练的过程中,依据结果不断进行一些修改。这时候,你使用的就是一个 pre-trained 模型,而过程就是 fine-tuning。
所以,预训练 就是指预先训练的一个模型或者指预先训练模型的过程;微调 就是指将预训练过的模型作用于自己的数据集,并使参数适应自己数据集的过程。
预训练和微调的作用?
在 CNN 领域中,实际上,很少人自己从头训练一个 CNN 网络。主要原因是自己很小的概率会拥有足够大的数据集,基本是几百或者几千张,不像 ImageNet 有 120 万张图片这样的规模。拥有的数据集不够大,而又想使用很好的模型的话,很容易会造成过拟合。
所以,**一般的操作都是在一个大型的数据集上(ImageNet)训练一个模型,然后使用该模型作为类似任务的初始化或者特征提取器。**比如 VGG,Inception 等模型都提供了自己的训练参数,以便人们可以拿来微调。这样既节省了时间和计算资源,又能很快的达到较好的效果。
这篇文章更加详细地对预训练和微调的应用进行了分析:深度学习笔记(一):模型微调fine-tune
多头注意力机制
多头
一开始从视频中学的,是本来`
X
∗
W
=
Q
,
再
Q
∗
W
0
=
Q
0
,
Q
∗
W
1
=
Q
1
X*W=Q , 再Q*W0=Q0 ,Q*W1=Q1
X∗W=Q,再Q∗W0=Q0,Q∗W1=Q1
确实是繁琐了一些,可以直接
X
∗
W
0
=
Q
0
,
X
∗
W
1
=
Q
1
X*W0=Q0 ,X*W1=Q1
X∗W0=Q0,X∗W1=Q1(很多博客就是这样介绍的)

【Transformer系列(2)】注意力机制、自注意力机制、多头注意力机制、通道注意力机制、空间注意力机制超详细讲解

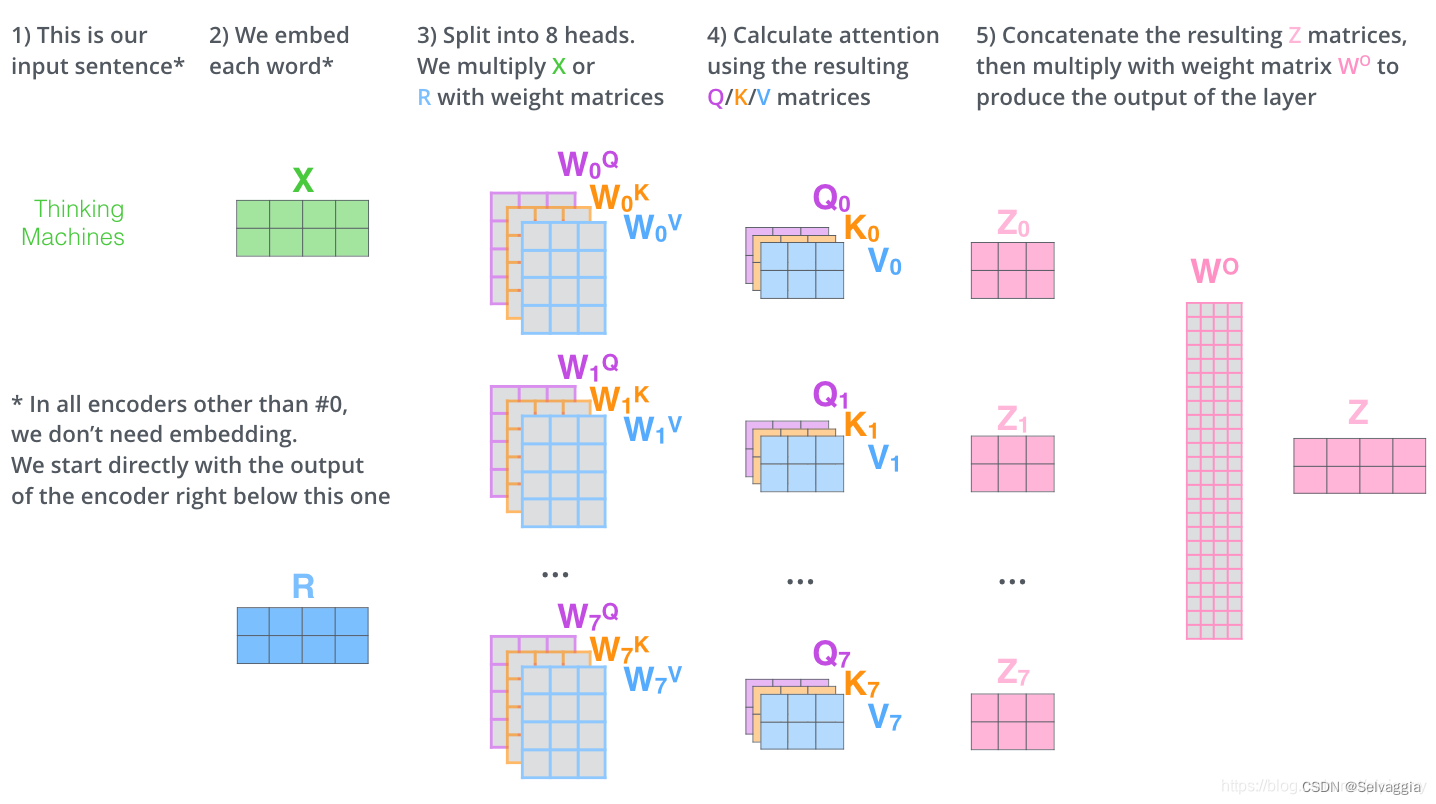
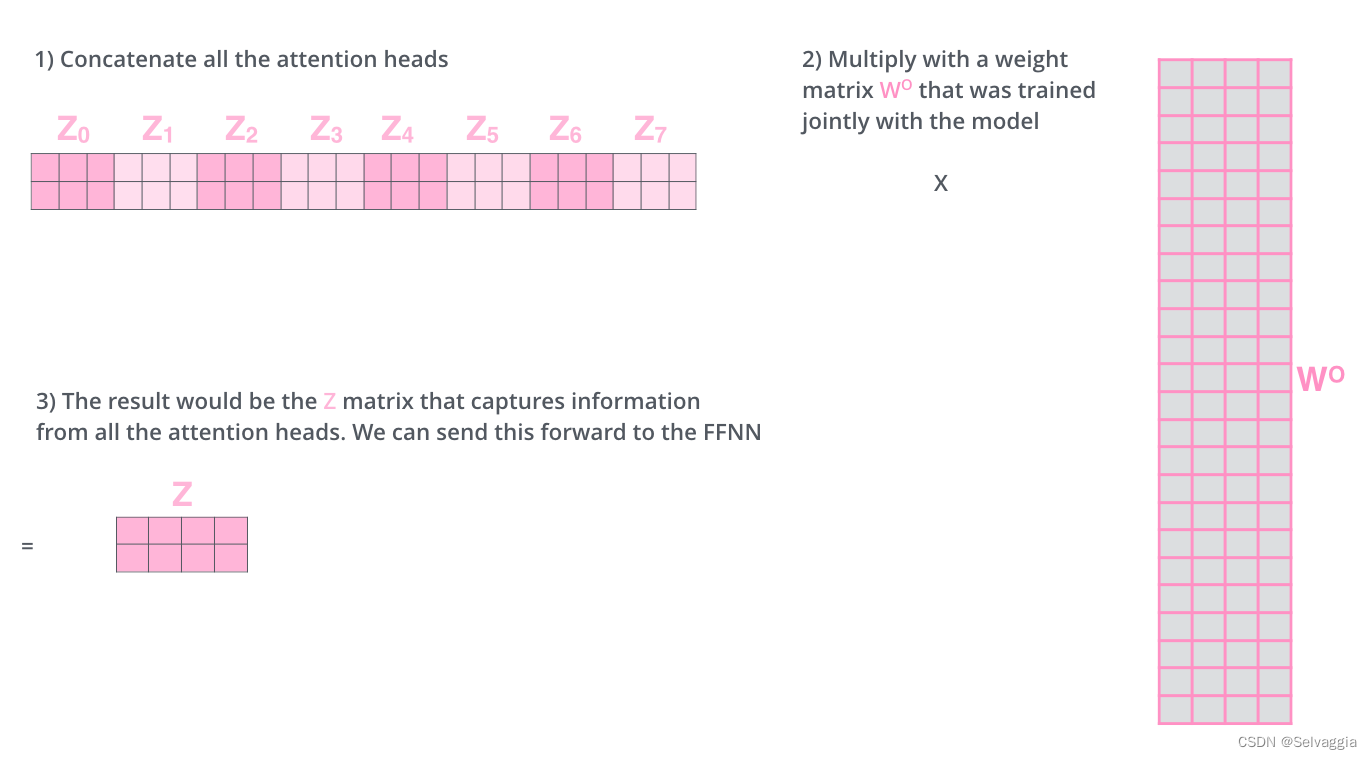
线性降维(多头注意力的h个结果向量降维回原始向量维度)
将这h个注意力汇聚的输出拼接在一起, 并且通过另一个可以学习的线性投影进行变换, 以产生最终输出。 这种设计被称为多头注意力(multihead attention)。


线性降维-笔记(1)
RNN
将神经网络模型训练好之后,在输入层给定一个x,通过网络之后就能够在输出层得到特定的y,那么既然有了这么强大的模型,为什么还需要RNN(循环神经网络)呢?
为什么需要RNN(循环神经网络)
他们都只能单独的取处理一个个的输入,前一个输入和后一个输入是完全没有关系的。但是,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。
举个例子判断 一个句子里面每个单词的词性,可以直接给定每个单词及其对应的词性这种标注,但是一句话中一个词的词性,显然会取决于前文的内容,即需要前文序列信息

我们现在这样来理解,如果把上面有W的那个带箭头的圈去掉,它就变成了最普通的全连接神经网络。x是一个向量,它表示输入层的值(这里面没有画出来表示神经元节点的圆圈);s是一个向量,它表示隐藏层的值(这里隐藏层面画了一个节点,你也可以想象这一层其实是多个节点,节点数与向量s的维度相同);
U是输入层到隐藏层的权重矩阵,o也是一个向量,它表示输出层的值;V是隐藏层到输出层的权重矩阵。
那么,现在我们来看看W是什么。循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵 W就是隐藏层上一次的值作为这一次的输入的权重。
hidden layer的output会存到蓝色方块里去(memory cell,图中的W)
首先memory cell要有起始值,0
把hidden layer的output存起来,下个时间点读进来
还有一种RNN,把经过所有hidden layer最终得到的output存起来
bidirectional RNN
可以先同时train一个正向的RNN和一个逆向的RNN
把正逆两个RNN 对应的同一个hidden layer的值拿出来
看的范围比较广
上述,随时存进memory ,随时读出来















 18万+
18万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









