







前言
我愿为表征学习 & 多模态专吹一篇简短的blog。万物皆可向量! 万物皆可表征!神奇!!!(只记了关键code)
正文
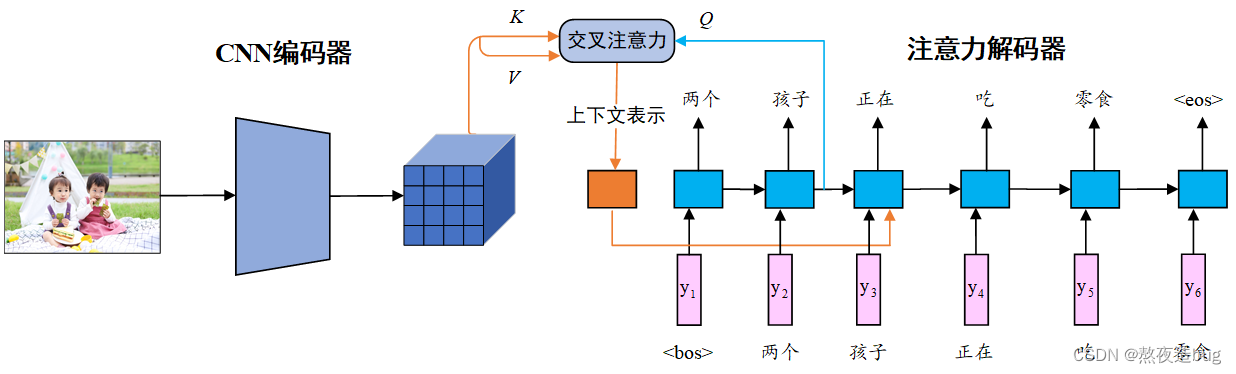
ARCTIC模型是一个典型的基于注意力的编解码模型,其编码器为图像网格表示提取器,解码器为循环神经网络。解码器在每生成一个词时,都利用注意力机制考虑当前生成的词和图像中的哪些网格更相关。
关键代码(表征学习/迁移学习/预训练模型)
ARCTIC原始模型使用在ImageNet数据集上预训练过的分类模型VGG19作为图像编码器,VGG19最后一个卷积层作为网格表示提取层。而我们这里使用ResNet-101作为图像编码器,并将其最后一个非全连接层作为网格表示提取层。图像表征学习代码如下:
"""
1. 这个 ImageEncoder 类可以用于提取图像的中间特征表示。
这些特征可以用于各种下游任务,如图像-文本匹配、图像标注等。
通过选择性地微调(finetuning)模型参数,可以在迁移学习的场景中利用预训练模型的知识。
2. 保留 resnet101 模型的卷积层部分(除最后两层之外的所有层),并根据 finetuned 参数的值决定这些层的参数是否在后续的训练中更新。
如果 finetuned=True,则这些层的参数将被更新;如果 finetuned=False,则这些层的参数将保持冻结,不再更新。
"""
from paddle.vision import models
import paddle.nn as nn
class ImageEncoder(nn.Layer):
def __init__(self, finetuned=True):
super(ImageEncoder, self).__init__()
model = model.resnet101(pretrained=True)
self.grid_representation_extractor = nn.Sequential(*(list(model.children())[:-2]))
for param in self.grid_representation_extractor.parameters():
param.requires_grad = finetuned
def forward(self, images):
out = self.grid_representation_extractor(images)
return out
后记
Link 1 https://blog.csdn.net/qq_51175703/article/details/136901379?spm=1001.2014.3001.5501
Link 2 https://blog.csdn.net/qq_41185868/article/details/135877268
更多的多模态相关正马不停蹄赶工中......

















 1413
1413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









