







记录一下自己看BiseNet代码的过程
到目前只看了主要结构部分的代码 随便记录一下
class ConvBNReLU(nn.Module):
def __init__(self, in_chan, out_chan, ks=3, stride=1, padding=1, *args, **kwargs):
super(ConvBNReLU, self).__init__()
self.conv = nn.Conv2d(in_chan,
out_chan,
kernel_size = ks,
stride = stride,
padding = padding,
bias = False)
self.bn = nn.BatchNorm2d(out_chan)
self.init_weight()
def forward(self, x):
x = self.conv(x)
x = F.relu(self.bn(x))
return x
这一部分是先定义了一个卷积函数,就是对输入的x做卷积,bn,relu,后面要频繁用到。
先来看比较简单的一部分。

这是一个注意力细化模块
class AttentionRefinementModule(nn.Module):
def __init__(self, in_chan, out_chan, *args, **kwargs):
super(AttentionRefinementModule, self).__init__()
self.conv = ConvBNReLU(in_chan, out_chan, ks=3, stride=1, padding=1)
self.conv_atten = nn.Conv2d(out_chan, out_chan, kernel_size= 1, bias=False)
self.bn_atten = nn.BatchNorm2d(out_chan)
self.sigmoid_atten = nn.Sigmoid()
self.init_weight()
def forward(self, x):
feat = self.conv(x)
atten = F.avg_pool2d(feat, feat.size()[2:])
atten = self.conv_atten(atten)
atten = self.bn_atten(atten)
atten = self.sigmoid_atten(atten)
out = torch.mul(feat, atten)#atten是一个数字
return out
这里刚开始看没有注意细节,atten在经过全局平均池化后,每个通道变成了一个数字。
测试

池化之后,又做了一开始定义的convBNRELU,一个数字怎么做卷积呢,卷积核为3,步长为1,padding=1,没有偏置值,那么经过卷积后,每个通道仍然是一个数字。再经过bn,sigmoi。也就是输入的x经过一次convBNRELU,每个通道都乘以一个参数。
接下来是空间路径模块
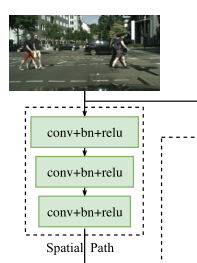
这个模块也比较简单,就是三个一样的卷积,bn,relu操作,看一下代码。
class SpatialPath(nn.Module):
def __init__(self, *args, **kwargs):
super(SpatialPath, self).__init__()
self.conv1 = ConvBNReLU(3, 64, ks=7, stride=2, padding=3)
self.conv2 = ConvBNReLU(64, 64, ks=3, stride=2, padding=1)
self.conv3 = ConvBNReLU(64, 64, ks=3, stride=2, padding=1)#三层
self.conv_out = ConvBNReLU(64, 128, ks=1, stride=1, padding=0)
self.init_weight()
def forward(self, x):
feat = self.conv1(x)
feat = self.conv2(feat)
feat = self.conv3(feat)
feat = self.conv_out(feat)
return feat
这里有个小疑问,文章里说经过三个步长为2的卷积,很明显就是前三步,但是最后还用了一个卷积。这个待议。
然后是上下文信息模块,这个模块的代码相对复杂一些。

最上面是原图的输入,来和代码一起解读一下。
class ContextPath(nn.Module):
def __init__(self, *args, **kwargs):
super(ContextPath, self).__init__()
self.resnet = Resnet18()
self.arm16 = AttentionRefinementModule(256, 128)
self.arm32 = AttentionRefinementModule(512, 128)
self.conv_head32 = ConvBNReLU(128, 128, ks=3, stride=1, padding=1)
self.conv_head16 = ConvBNReLU(128, 128, ks=3, stride=1, padding=1)
self.conv_avg = ConvBNReLU(512, 128, ks= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 669
669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









