







在利用深度学习进行目标检测时,需要自己拍数据集并转换成一张张图片进行打标签。本文分享一种基于 OpenCV 实现的视频文件转图片的工具。
源代码如下:
#include <iostream>
#include <algorithm>
#include <opencv2/opencv.hpp>
int main(int, char**) {
cv::VideoCapture video;
std::string filename="/home/workstation/Videos/runeVideo/Red_Dim.avi"; //在这里指定视频文件
video.open(filename);
cv::Mat src;
static int cnt=0;
while(video.read(src))
{
imshow("src",src);
cv::waitKey(1);
cnt++;
printf("%d\n",cnt);
}
system("mkdir pic");
printf("Input number of pictures:\n");
int a;
scanf("%d",&a);
printf("Input start number:\n");
int b;
scanf("%d",&b);
b--;
int step=cnt/a;
video.open(filename);
while(video.read(src)){
static int tick=0;
static int num=b;
if(tick<step)
{
tick++;
continue;
}
imshow("src",src);
cv::imwrite("pic/"+std::to_string(++num)+".jpg",src);
cv::waitKey(1);
tick=0;
}
return 0;
}
功能说明:输入期望生成的图片数和起始命名,则会根据读入的视频等间距生成数量与期望值大致相同的图片。例如,输入300 和 100,则会生成大概300张图片,并命名为 100.jpg, 101.jpg, …
执行效果:
运行后,首先会将原视频播放一遍,并显示帧数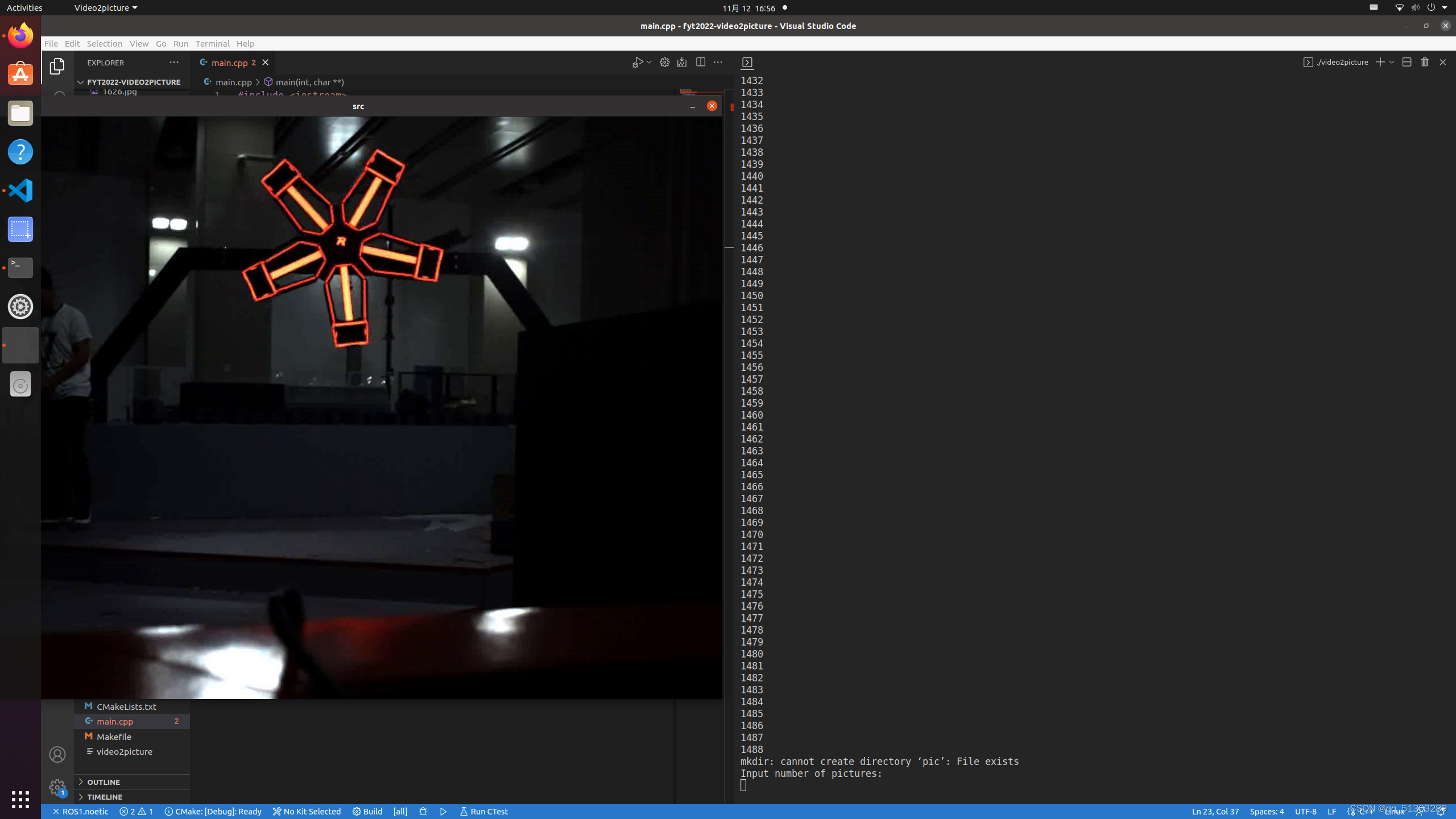
之后输入期望图片数量和起始点,即可开始转换:
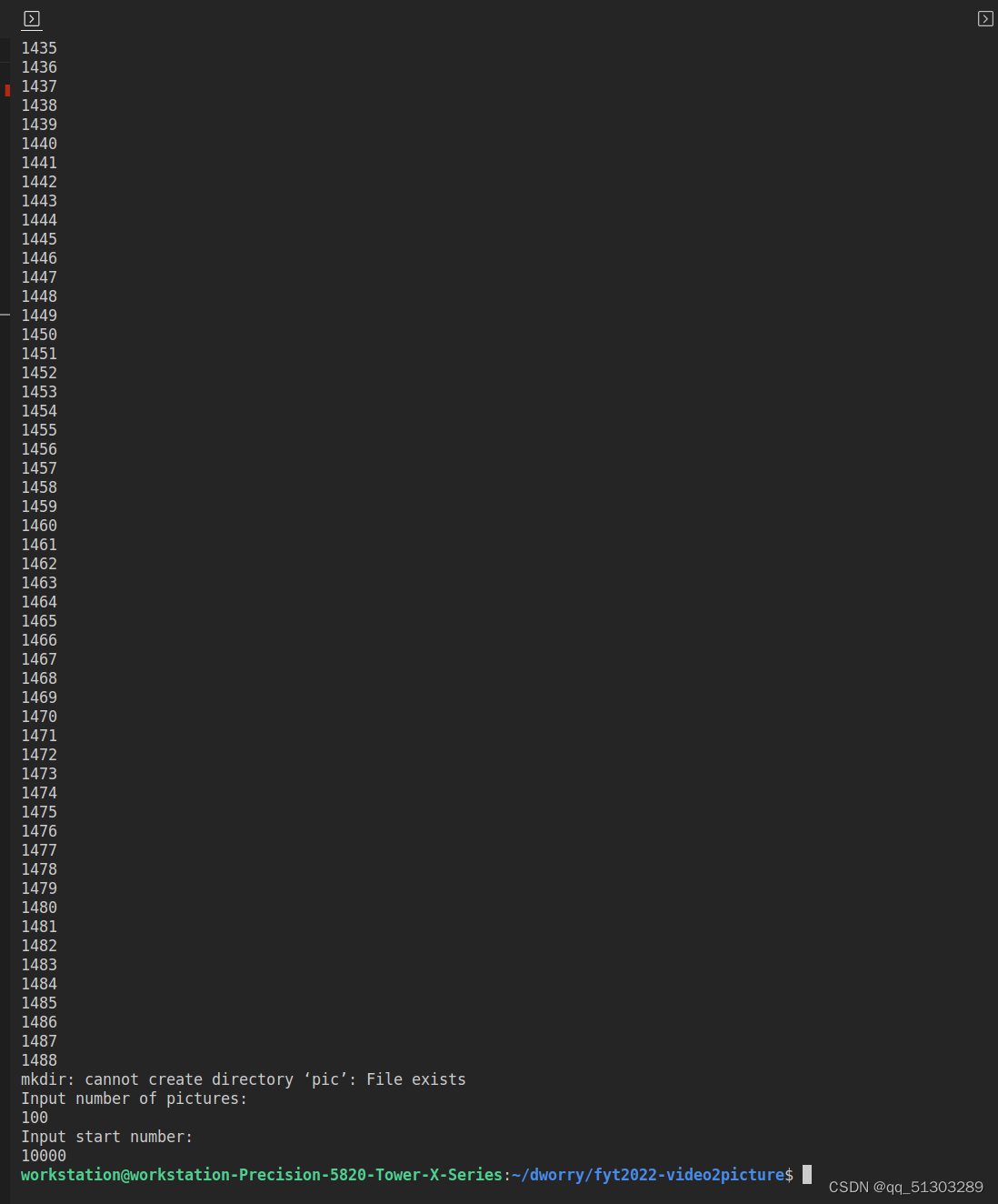
转换完成,生成的图片如下:
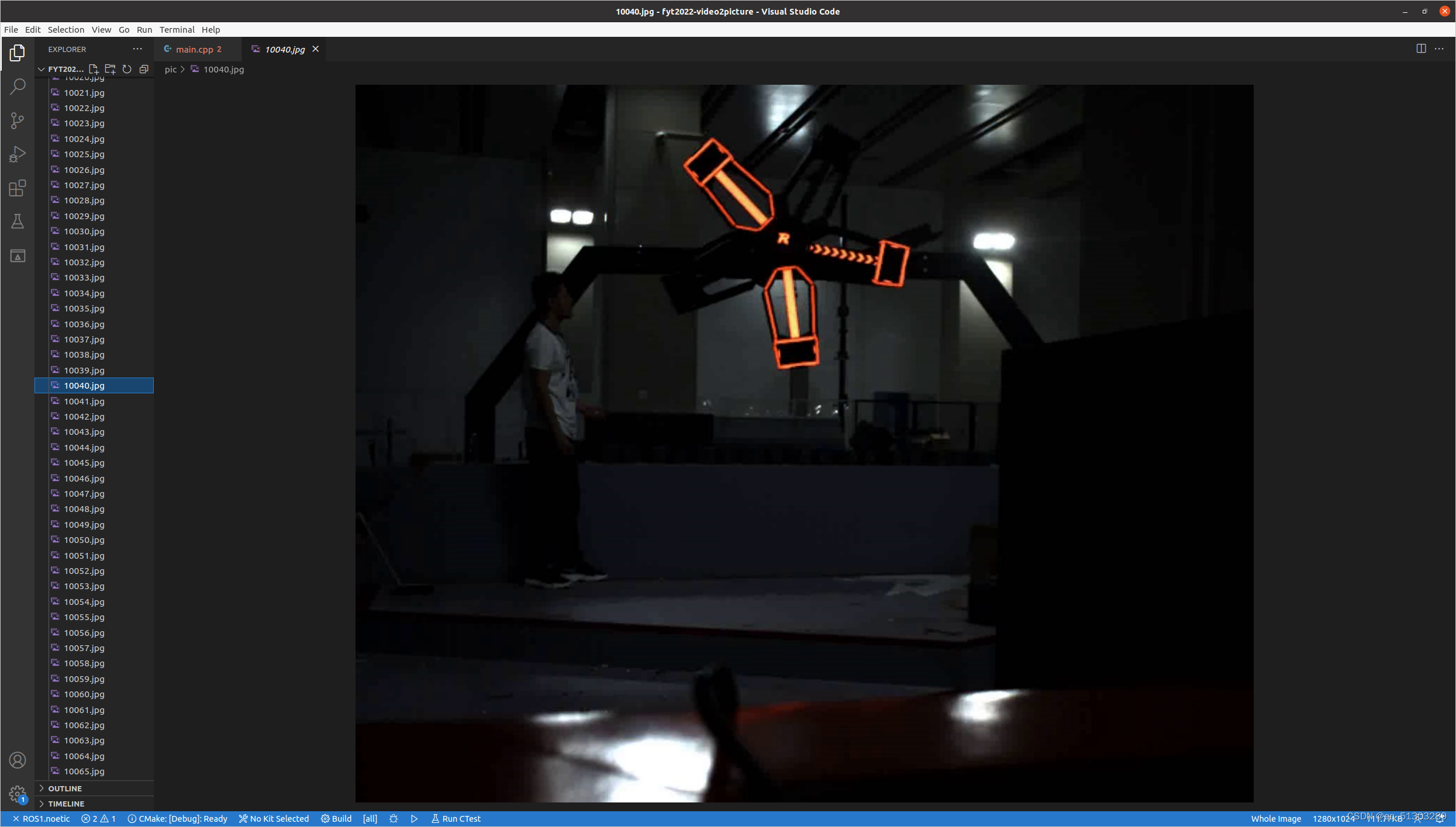

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









