







目录
1. 引言与背景
随着大数据时代的到来,如何从海量、高维、冗余的数据中提取出有意义的结构和模式,已成为机器学习和信号处理领域的一项关键挑战。稀疏编码(Sparse Coding, SC)作为一种有效的无监督学习方法,通过寻求数据的稀疏表示,揭示其内在结构和潜在规律,为降维、特征学习、图像处理、模式识别等诸多应用提供了强有力的工具。本文将按照“引言与背景”、“稀疏编码定理”、“算法原理”、“算法实现”、“优缺点分析”、“案例应用”、“对比与其他算法”以及“结论与展望”的框架,全面剖析稀疏编码的理论基础、实现细节、实际应用以及未来发展。
2. 稀疏编码定理
稀疏编码的理论基础主要来源于稀疏信号恢复理论,其中最著名的是压缩感知(Compressed Sensing, CS)理论中的 Restricted Isometry Property (RIP) 定理和 Donoho-Tanner 相位过渡定理。RIP 定理保证了在一定条件下,稀疏信号可以通过远小于其维度的观测值准确恢复。Donoho-Tanner 定理则揭示了在不同稀疏度和测量噪声水平下,信号恢复的成功概率与恢复算法的关系。这些定理为稀疏编码的有效性和稳定性提供了坚实的数学保障。
3. 算法原理
稀疏编码的基本思想是将输入数据表示为一个过完备字典(Overcomplete Dictionary)中稀疏线性组合的形式。具体来说,给定一组输入数据,稀疏编码的目标是学习一个字典 D 和对应的稀疏系数矩阵 A,满足:
其中,字典 的列向量构成过完备基,K≫D;系数矩阵
中的每一列
对应于输入向量
在字典上的稀疏表示
,即 。学习过程通常通过以下两步迭代进行:
-
固定字典,更新系数:给定当前字典D,对每一个输入向量
,通过求解优化问题:
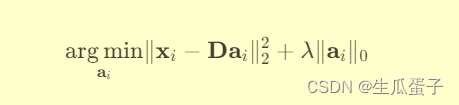
得到其稀疏系数向量
,其中
表示ℓ0 范数,即非零元素个数,λ 是正则化参数,控制稀疏度。
-
固定系数,更新字典:保持系数矩阵 A 不变,通过最小化重构误差,更新字典 D:

其中
表示 Frobenius 范数。
这两个步骤交替进行,直至收敛或达到预设的迭代次数。
4. 算法实现
在Python中,我们可以使用scikit-learn库提供的SparseCoder类来实现稀疏编码。下面是一个详细的代码示例,包括数据准备、稀疏编码模型的训练以及编码结果的查看:
1. 导入所需库
首先,导入所需的Python库,包括numpy用于处理数组和矩阵操作,以及scikit-learn中的SparseCoder类:
Python
import numpy as np
from sklearn.linear_model import SparseCoder2. 准备数据
假设我们有一组输入数据X,它们是我们希望用稀疏方式表示的样本。这里以一个简单的二维数据集为例:
Python
# 假设我们有以下10个样本,每个样本有20个特征
X = np.random.rand(10, 20)3. 构建字典
稀疏编码需要一个预先定义的字典dictionary,它通常是一个过完备的矩阵,其列向量代表基向量。这里我们简单地生成一个大小为(20, 9)的随机字典:
Python
# 创建一个大小为(20, 9)的随机字典
dictionary_size = (X.shape[1], 9) # 字典大小为(特征数, 基向量数)
dictionary = np.random.randn(*dictionary_size)4. 训练稀疏编码模型
使用SparseCoder类创建稀疏编码模型,并使用字典dictionary对输入数据X进行编码:
Python
# 创建稀疏编码器对象,指定字典和编码方法(这里使用OMP)
sparse_coder = SparseCoder(dictionary=dictionary, transform_algorithm='omp', transform_n_nonzero_coefs=5)
# 对输入数据X进行编码
sparse_codes = sparse_coder.transform(X)这里我们选择了transform_algorithm='omp',即使用Orthogonal Matching Pursuit (OMP)算法进行编码。transform_n_nonzero_coefs=5指定了每个样本的稀疏编码最多有5个非零项。
5. 查看编码结果
最后,我们可以打印或可视化编码结果,看看每个样本是如何被稀疏编码表示的:
Python
print("Original input data (samples x features):")
print(X[:2]) # 打印前两个样本
print("\nSparse codes (samples x basis vectors):")
print(sparse_codes[:2]) # 打印前两个样本的稀疏编码完整代码如下:
Python
import numpy as np
from sklearn.linear_model import SparseCoder
# 假设我们有以下10个样本,每个样本有20个特征
X = np.random.rand(10, 20)
# 创建一个大小为(20, 9)的随机字典
dictionary_size = (X.shape[1], 9) # 字典大小为(特征数, 基向量数)
dictionary = np.random.randn(*dictionary_size)
# 创建稀疏编码器对象,指定字典和编码方法(这里使用OMP)
sparse_coder = SparseCoder(dictionary=dictionary, transform_algorithm='omp', transform_n_nonzero_coefs=5)
# 对输入数据X进行编码
sparse_codes = sparse_coder.transform(X)
print("Original input data (samples x features):")
print(X[:2]) # 打印前两个样本
print("\nSparse codes (samples x basis vectors):")
print(sparse_codes[:2]) # 打印前两个样本的稀疏编码通过上述代码,我们成功实现了Python中的稀疏编码过程,包括数据准备、字典构建、稀疏编码模型训练以及编码结果查看。实际应用中,字典可能需要通过某种学习算法(如K-SVD)从数据集中自适应地学习得到,而不是像这里那样随机生成。
5. 优缺点分析
优点:
- 稀疏表示:通过寻求输入数据的稀疏表示,揭示其内在结构和关键特征。
- 特征学习:自适应学习的字典可以作为一组有效的特征基,用于后续的分类、识别等任务。
- 抗噪性:稀疏编码对噪声有一定的鲁棒性,因为稀疏表示可以忽略无关或噪声成分。
- 压缩效率:稀疏编码能够以较低的比特率有效编码数据,实现数据压缩。
缺点:
- 计算复杂度:稀疏编码的迭代优化过程可能较慢,尤其是对于大规模、高维数据。
- 稀疏度选择:正则化参数 �λ 的选择对结果影响较大,需要通过交叉验证等方式确定。
- 过完备字典学习:字典学习过程可能导致过拟合,需要适当正则化或早停策略。
- 非凸优化问题:稀疏编码涉及的 ℓ0ℓ0 范数优化问题是非凸的,可能存在多个局部最优解。
6. 案例应用
稀疏编码在众多领域有着广泛的应用:
- 图像处理:用于图像去噪、超分辨率重建、图像分类等任务,通过学习图像块的稀疏表示,提取视觉显著特征。
- 生物医学信号分析:如脑电图(EEG)、心电信号(ECG)等的特征提取和疾病诊断,通过稀疏编码揭示信号的内在结构和规律。
- 自然语言处理:应用于词向量学习、文档主题建模等领域,通过学习词汇的稀疏表示,提升模型的泛化能力和解释性。
7. 对比与其他算法
与其他无监督学习方法相比,稀疏编码有其独特之处:
- 与主成分分析(PCA)对比:PCA通过线性变换最大化数据的方差,得到低维投影;而稀疏编码寻求输入数据的稀疏表示,侧重于特征选择和稀疏性。
- 与自编码器(Autoencoder)对比:自编码器是一种深度学习模型,通过编码-解码结构学习数据的低维表示;稀疏编码则通过迭代优化求解稀疏系数和字典,更侧重于稀疏约束。
- 与K-means对比:K-means是一种聚类算法,将数据划分到K个簇中;稀疏编码通过学习字典和稀疏系数,将数据表示为字典原子的加权和,更关注数据的稀疏分解。
8. 结论与展望
稀疏编码作为一种强大的无监督学习方法,通过寻求数据的稀疏表示,揭示其内在结构和潜在规律,已在图像处理、生物医学信号分析、自然语言处理等多个领域展现出强大的应用潜力。尽管存在计算复杂度高、稀疏度选择困难等问题,但随着计算资源的提升和优化算法的发展,稀疏编码及相关扩展(如稀疏字典学习、稀疏编码神经网络等)将在未来的机器学习研究与应用中继续发挥重要作用。未来的研究方向可能包括:
- 加速算法:开发更高效的稀疏编码算法,如利用GPU并行计算、分布式计算等技术,以应对大规模、高维数据。
- 正则化策略:探索新的正则化方法,如基于结构稀疏性、分组稀疏性等,以提高模型的泛化能力和解释性。
- 理论深化:进一步研究稀疏编码的理论基础,如字典学习的收敛性、稀疏表示的唯一性等,为算法设计和应用提供更坚实的理论支撑。

















 1295
1295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









