







今天介绍的论文题目是 LEOPARD: Identifying Vulnerable Code for Vulnerability Assessment Through Program Metrics.
通过程序度量去识别用于漏洞评估的易受攻击代码。这篇论文来自2019年的icse(PDF) LEOPARD: Identifying Vulnerable Code for Vulnerability Assessment through Program Metrics (researchgate.net)
https://www.researchgate.net/publication/330775284_LEOPARD_Identifying_Vulnerable_Code_for_Vulnerability_Assessment_through_Program_Metrics

一、首先了解一下背景
- 软件漏洞的危害性毋庸置疑,2021年4月份,软件单元测试统计工具codecov受到攻击,被植入恶意代码用于窃取软件的密钥密码等凭证,导致了数百个客户的网站被访问,影响了全球2.9万名客户。从1999年到2020年,windows平台提交漏洞,总计7272个,而2020年是1999年的7.1倍。毫无疑问,随着软件逐渐深入我们的生活,软件漏洞对我们的生活影响也越来越大。
- 安全专家通常使用模糊化、符号执行以及人工审计的方式来寻找漏洞。但是由于只有少数漏洞分散在庞大的代码库中,所以漏洞搜索实际上是非常具有挑战性的任务,想要在庞大的代码这种搜索出漏洞,无异于大海捞针。所以人们开始寄希望于识别代码库中的潜在易受攻击代码,从而缩小安全专家们审查的范围
- 现有的自动识别技术主要分两类:基于度量和基于模式的方法来识别易受攻击攻击代码,也就是 metric based and pattern based methods.
- 基于度量的技术,其灵感来自于错误预测。利用机器学习来预测易受攻击的代码。安全专家通常会使用一些指标。比如复杂性,开发人员活动指标等。去预测易受攻击的代码;
- 而基于模式的技术,则利用已知漏洞的形式通过静态分析来识别其潜在的易受攻击代码。这种模式是基于特定类型的漏洞语法和语义抽象。比如缺少对关键位置对象的安全检查
- 但是他们都有各自的缺陷,一方面,基于度量的技术主要是为单个应用程序或者几个相同类型的应用程序而设计的,所以他们不能具有很好的普适性;
- 另一方面,基于度量和基于模式的技术,大多需要大量的关于脆弱性的先验知识,特别是在一些基于度量的技术中,有效的机器学习需要大量已知的漏洞。但是非易受攻击代码和易受攻击代码之间数量的不平衡。严重阻碍了机器学习的适用性。并且由于他需要学习已知的漏洞,所以他们不能识别新的漏洞。
二、论文提出了一个漏洞识别框架,命名为leopard。用于识别C和c++应用程序中的潜在易受攻击函数。
相比于我们之前提到的方法,Leopard可以通用于不同类型的程序,而且轻量级可以支持大规模应用程序的分析。更重要的是,它不需要任何已知漏洞的先验知识。
- 我们将leopard的设计为漏洞评估的预备步骤,而不是直接指出漏洞。
- 论文使用这个框架在11个不同类型的真实项目上评估了框架的有效性。得到了良好的结果。
三、介绍整个框架的实现思路
- 首先我们能看到这个图就是leopard的工作流程,它的核心步骤分为两步Functionbining和function ranking,根据不同的程序度量对他进行装箱和排序。
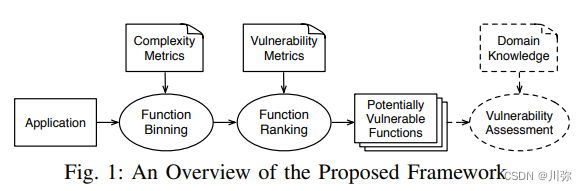
- 在我们拿到一个application,一个应用后,首先根据它的复杂性度量对它进行装箱,就是把相同复杂性的函数分到一个箱里,然后分完之后再使用脆弱性度量,对于每个箱中的功能进行排名,以便将每个箱中的顶级功能识别为潜在漏洞,然后输出潜在的易受攻击函数。再由专家用他们的领域知识对于漏洞进行评价。
- 首先,这个流程有什么优势,因为它只使用了简单的装箱和排序,使它可以满足我们通用性和轻量级的设计原则。第二,这两个指标是可以进行拓展的,也就满足了可拓展性的原则。
- 其次,我们为什么要先进行装箱,再进行排序?是因为我们想要识别所有复杂性的漏洞,不想遗漏低复杂性的易受攻击函数,这个在后面会有更详细的阐述。
- 那么这两个步骤到底具体是怎么做的呢?我们现在来深入的看一下他的两个核心步骤:
- 第1个装箱步骤这个步骤的效果就是使得每个箱中都有不同的复杂度,目的是我们希望识别所有复杂性的易受攻击函数,而避免遗漏低复杂性的易受攻击函数。
- 那么我们根据什么标准去装箱呢?就是复杂性度量。复杂性度量从两个维度上来捕捉函数的复杂度,第一就是函数本身的圈复杂度;第二是函数的循环结构。
- 圈复杂度又叫条件复杂度,顾名思义是用来衡量一个模块判定结构的复杂程度。可以理解为就是在控制流图中,覆盖所有可能情况的最少的路径的条数。
- 他有一个非常简单的计算方法,叫做点边计算法,也就是一个模块的圈复杂度等于控制流程图的路径数量减去节点的数量再加2,比如我们看下面这个例子:在这两个控制流图中,在正常顺序的圈复杂度是它的一条路径减掉两个结点,再加2=1。if else结构的圈复杂度是4条路径减掉4个节点再加2所以=2,(以此类推while和until的圈复杂度都是2)
- 但是圈复杂度主要是衡量判断结构的复杂程度,所以我们又使用了C2到C4来反映循环导致的复杂性。包括循环的数量。嵌套循环的数量以及循环的最大嵌套级别。这些指标越高,所要考虑的路径就越多或者越长。
- 最后计算一个函数的复杂性度量,我们就把它这些指标得分全部加起来,然后把具有相同分数的函数分组到同一个箱中。我们不会确定某一个范围,而就是相同的复杂程度分到一个箱中,因为一个合适的范围的大小很难确定,这个在后面的评估中也可以证明。
四、步骤二:function ranking
在第2部中我们使用一个新的度量指标,对于每一个箱中的函数进行排序,并确保每个箱最上面是易受攻击函数。因为C和C++程序中大多数关键类型的漏洞都是因为内存管理错误,或是对某些敏感变量缺少检查,比如指针。这篇论文引用了一些文献认为。上述类型原因所导致的漏洞可以占到所有漏洞的70%以上。我们也就根据这些指标去确定一个函数的脆弱性度量。
- 下面这张表就是脆弱性度量的具体标准。
- 你可以看到分成三部分:VD1依赖度量表示了一个函数与其他函数的依赖关系,它里面的参数有:参数变量的数量和作为调用者的函数的参数变量数量;VD2指针度量包括:指针算术的数量、指针算术中使用的变量的数量和变量涉及的最大指针算术;VD3则是指控制结构相关的脆弱性指标。控制结构度量(V6-V11)捕获高度耦合和依赖的控制结构(如if和while)的漏洞,即嵌套控制结构对的数量、控制结构的最大嵌套级别、依赖于控制或数据的控制结构的最大数量、没有显式else语句的if结构的数量,以及依赖数据的控制结构中涉及的变量的数量。
- 我们用一个计算斐波那契数列的例子(图2)来解释上述指标。有两对嵌套控制结构,if分别在第7行,第8行,for在第12行。显然最大嵌套级别为2,外层结构类似于第7行。依赖控制的控制结构最多为3个,包括7和8,以及12。依赖数据的控制结构最多为4个,因为所有4个控制结构中的条件都对变量n进行检查。所有3个if语句都没有else语句。在控制结构的谓词中涉及两个变量,即n和i。
- 实际上,谓词中使用的变量越多,在健全检查中出错的可能性就越大。这些指标越高,程序员就越难以在漏洞查找过程中就越难以触及函数的深层部分。独立的if结构可能会在隐式的else分支上丢失检查。
- 接下来我们来看一下对于这个框架的评估
- 第一列给出项目版本,第二列报告源代码行,第三列列出每个项目中的函数总数。最后三列报告了我们研究中排除的易受攻击功能、CVE(常见漏洞披露)和使用本框架找出的CVE的数量。在整个实验中,我们总共研究了26886k行代码和60多万个函数,使我们的研究规模大,结果可靠。
- 我们适用我们已经获得数据进行三个问题的研究,首先第1个问题是为什么装箱操作要在排取操作之前。第二是这个方法是否比其他的方法更有效率,三是我们使用的这些度量标准的敏感度是多少?也就是说,这些度量标准的设置是否合理?是否可以增加或者减少让程序变得更轻量级?
- 首先,为什么装箱操作要在排序之前?
- 我们来看这个图,横坐标表示这个函数的复杂性得分,纵坐标表示这个函数的脆弱性得分,其中红色标注的是真实的易受攻击函数,蓝色的是那些非易受攻击函数,我们来看这些函数和我们设置标准之间的关系。
- 我们从图中的3a,3g和3j发现,如果我们基于复杂性度量或脆弱性度量直接对函数进行排序。我们会总是偏爱的一些高复杂度而且高脆弱性的函数,而错过那些具有低复杂度而脆弱的函数。
- 如果首先根据复杂分数对函数进行装箱,然后再根据脆弱性分数进行排序,我们就可以有效的识别所有复杂级别的潜在脆弱函数。
- 然后我们来看一下这个方法的有效性
- 横轴表示你确定某个百分比的函数易受攻击时,纵轴表示会有多少真实的易受攻击函数被覆盖。
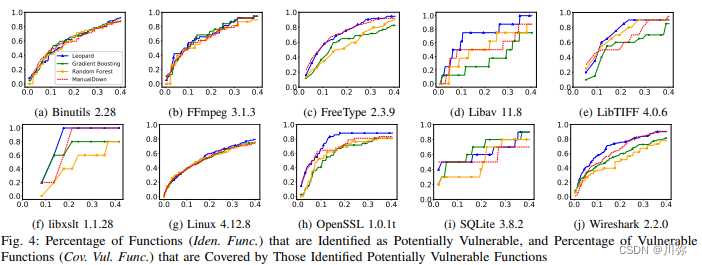
- 当识别5%、10%、15%、20%、25%和30%的功能为易受攻击功能,我们可以覆盖 29%、49%、64%、74%、78%和 85% 的易受攻击功能。这意味着通过将一小部分功能识别为易受攻击的,我们就可以覆盖了大部分易受攻击的功能,这可以大大缩小安全专家的评估量。
- 我们还可以观察到,当设置5%~20%的为易受攻击函数的时候,平均的漏洞覆盖率有明显提高,但是再增加则边际效应递减,提高效果不太明显
- 这张图则是和其他方法比较时,比其他三种方法覆盖面更广
- 在课上做报告的时候,老师对我报告提出的问题是:在这个框架在没有新的度量标准提出的情况下,是怎么优于其他的工具的?
- 我当时并没有很好的回答这个问题,回来重新看了一下原文,认为可能的原因是这样的:
- 首先我认为这种有效性的差异和度量标准是没有关系的。因为一方面他只是整合了已有的度量标准,没有提出新的度量标准,而且在测试其他三种方法的时候,使用的度量标准是完全一样的。
- 在原文中,其他三个框架是在11个项目中以其他10个项目为基础进行机器学习然后跨项目去识别第11个项目的漏洞。而因为需要评估程序的通用性,所找的程序差异很大,可能漏洞类型的差别也很大,所以机器学习不能具有很好的适用性。
- 总之,他举的三个例子都是基于机器学习的框架,机器学习往往需要大量的已知类型的漏洞,所以在新的程序中不能具有很好的适用性,而论文提出的leopard是一个更通用的框架,所以它的效果会更好一点。
- 为了评估复杂性和脆弱性指标对我们框架的敏感性,
- 我们从LEOPARD中删除了复杂性和脆弱性指标的一个维度,然后在所有项目上运行LEOPARD。
- 我们在图5中显示了复杂性度量和漏洞度量的敏感性结果。
- x轴分别表示,确定某个百分比的函数为易受攻击。y轴表示与LEOPARD相比,所有指标的召回增量。在删除一个维度的指标后,在确定一定百分比的功能时,每个项目的召回增量都用蓝色十字标记,其中正增量表示性能改进,负增量表示性能降低。红点是所有11个项目中的平均召回增量。
- 从图5中我们可以看出,基本上,当去除任何度量维度时,退化要比改进多得多。平均召回增量在5%和10%之间的一些改进实际上是由于只有少数几个项目的一些相对较大的改进。不具有普适性
- 我们能看到,最显著的退化发生在圈复杂度度量(即CD1)被移除时,最显著的平均退化发生在循环结构度量被移除时,这表明它们对我们的框架做出了重大贡献。这也证明了我们实施binning策略的必要性。
- 通过以上观察,我们可以得出结论,复杂性和脆弱性指标的所有维度都有助于LEOPARD的有效性,但复杂性指标贡献最大;虽然删除一些指标在某些程序中得到的效果很好,但是为了普适性,这些指标都是必不可少的
五、应用和拓展
- 这个框架可以很广泛的应用,
- 例如在手动审计过程中提高效率。安全专家可以只关注那些由LEOPARD识别的潜在易受攻击的功能,而不是审核所有的功能。利用他们的领域知识快速识别漏洞的根本原因,特别是对于复杂的大型功能(例如,大量的if-not-else实例,注意缺失else的逻辑以进行缺失检查。)
- 定向模糊化中,LEOPARD 生成一个潜在的易受攻击功能列表,一个带有定向灰盒模糊器的简单应用程序是将潜在易受攻击的功能设置为目标站点。通过引导模糊器专注于函数,可以快速确认潜在易受攻击的函数是真的易受攻击还是误报。
- 拓展
- 漏洞历史。一般来说,当漏洞被报告时,与漏洞相关的功能会在补丁过程中进行密集的安全评估。因此,此类信息可用于通过以下方式来细化排名:
- 比如更加重视最近打过补丁的功能,验证补丁是否已经有效地解决相关问题
- 给予低优先级给打过补丁的功能,认为这些功能已经过彻底的安全评估,不值得重新评估它。
- 领域知识。领域知识可以在优先考虑感兴趣的功能以进行进一步评估方面发挥重要作用。
- 漏洞历史。一般来说,当漏洞被报告时,与漏洞相关的功能会在补丁过程中进行密集的安全评估。因此,此类信息可用于通过以下方式来细化排名:

















 663
663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











