










Adaptive Graph Encoder for Attributed Graph Embedding(属性图嵌入的自适应图编码器)
文章目录
1. 来源
2020__KDD__论文地址
2. 动机
近年来,基于图卷积网络(GCNs)的方法在属性图分析中取得了很大的进展。然而,现有的基于GCN的方法有三个主要的缺点。
-
首先,实验表明,图卷积滤波器和权值矩阵的纠缠会损害其性能和鲁棒性。
-
其次,论文证明了这些方法中的图卷积滤波器是广义拉普拉斯平滑滤波器的特殊情况,但它们没有保持最优的低通特性。
-
最后,现有算法的训练目标通常是恢复邻接矩阵或特征矩阵,这些矩阵并不总是与现实应用相一致。
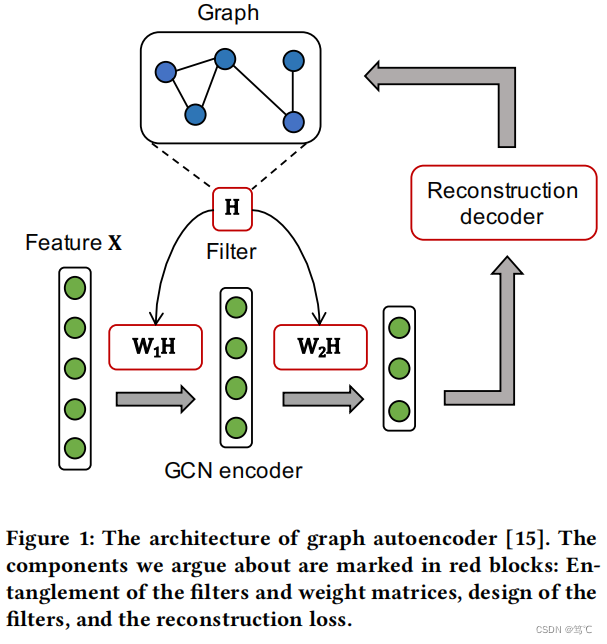
图1. 传统的GAE
为了解决这些问题,论文提出了自适应图编码器(AGE),一种新的归属图嵌入框架。AGE由两个模块组成: (1)为了更好地缓解节点特征中的高频噪声,AGE首先采用了精心设计的拉普拉斯平滑滤波器。(2) AGE采用了一种自适应编码器,迭代地加强过滤后的特征,以获得更好的节点嵌入。
3. 模型框架
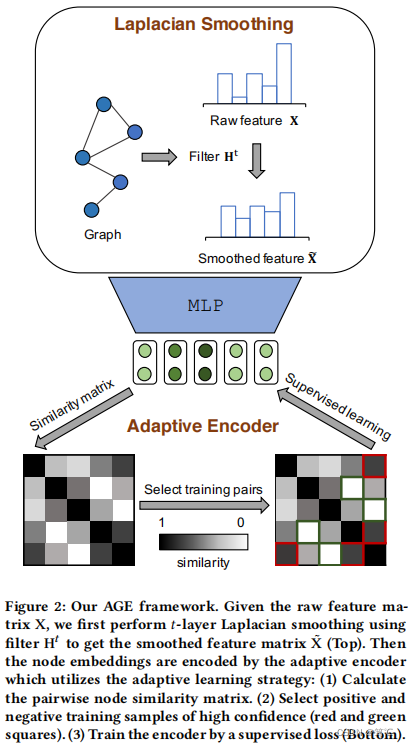
图2. 论文提出的AGE
4. 方法介绍
4.1 总览
AGE的模型框架如图2所示。它由两部分组成:一个拉普拉斯平滑滤波器和一个自适应编码器。
- 拉普拉斯平滑滤波器:设计的滤波器 H H H作为低通滤波器,对特征矩阵 X X X的高频分量进行去噪,将平滑的特征矩阵 X ~ \tilde{X} X~作为自适应编码器的输入。
- 自适应编码器:为了获得更具代表性的节点嵌入,该模块通过自适应选择高度相似或不相似的节点对来构建一个训练集。然后以一种有监督的方式训练编码器。
训练过程结束后,将学习到的节点嵌入矩阵 Z Z Z 用于下游任务。
4.2 拉普拉斯平滑滤波器
图学习的基本假设是,图上相邻的节点应该是相似的,因此在图域上的节点特征应该是平滑的。本节首先解释了平滑的意思;然后给出了广义拉普拉斯平滑滤波器的定义,并证明了它是一个平滑算子;最后回答了如何设计一个最优的拉普拉斯平滑滤波器。
4.2.1 平滑信号分析
从图信号处理的角度来解释平滑开始。以
x
∈
R
n
x\in R^n
x∈Rn 作为图上的信号,节点
i
i
i 的信号就是一个标量,也就是
x
i
x_i
xi。滤波矩阵为
H
H
H,为了测量图信号
x
x
x的平滑度,可以计算出图的拉普拉斯算子
L
L
L (
L
=
D
−
A
L = D - A
L=D−A)和
x
x
x 上的瑞利商:
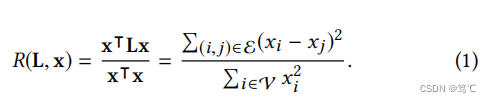
这个商实际上是
x
x
x的标准化方差分数。如上所述,平滑信号应该在相邻节点上分配相似的值。因此,瑞利商越低,则图上的信号越平滑。
考虑图拉普拉斯 L = U Λ U − 1 L=UΛU^{−1} L=UΛU−1的特征分解,其中 U ∈ R n × n U \in R^{n\times n} U∈Rn×n包含特征向量, Λ = d i a g ( λ 1 , λ 2 , ⋅ ⋅ ⋅ , λ n ) Λ = diag(λ1,λ2,···,λn) Λ=diag(λ1,λ2,⋅⋅⋅,λn)是特征值的对角矩阵。随后可以给出了特征向量 u i ∈ U u_i \in U ui∈U的光滑性:
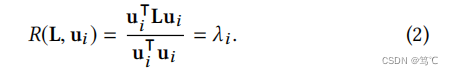
上式表示较平滑的特征向量与较小的特征值相关联,即频率较低。因此,基于等式基于
L
L
L分解信号
x
x
x基于公式(1)和(2):
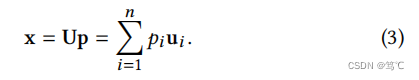
其中
p
i
p_i
pi是特征向量
u
i
u_i
ui的系数。那么
x
x
x的平滑度就变成了:
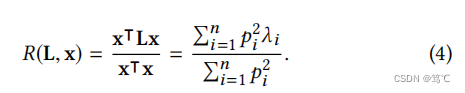
因此,为了获得更平滑的信号,滤波器的目标是:在保留低频分量的同时,滤掉高频分量。由于其高计算效率和令人信服的性能,拉普拉斯平滑滤波器经常被用于这一目的(保留低频分量的同时,滤掉高频分量)。
4.2.2 广义拉普拉斯平滑滤波器
广义拉普拉斯平滑滤波器定义为:

其中
k
k
k是实值的。采用
H
H
H作为滤波器矩阵,滤波后的信号
x
~
\tilde{x}
x~ 被表示为:
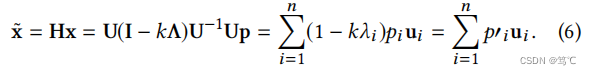
因此,为了实现低通滤波,频率响应函数
1
−
k
λ
1−kλ
1−kλ 应该是一个递减和非负函数。叠加
t
t
t 次拉普拉斯平滑滤波器,将滤波后的特征矩阵
X
~
\tilde X
X~表示为:

注意,该过滤器是不含有参数的。
4.2.3 k的选择
在实践中,使用重整化技巧
A
~
=
I
+
A
\tilde A=I+A
A~=I+A,采用对称归一化图拉普拉斯矩阵:
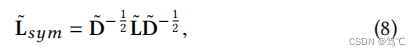
其中,
D
~
\tilde D
D~和
L
~
\tilde L
L~是与
A
~
\tilde A
A~对应的次矩阵和拉普拉斯矩阵。然后,过滤器就变成了:

注意,如果设置k = 1,过滤器将成为GCN过滤器。
为了选择最优 k,需要仔细发现特征值 Λ ~ \tilde Λ Λ~的分布(由 L ~ s y m = U ~ Λ ~ U ~ − 1 \tilde Lsym=\tilde U \tilde Λ \tilde U^{−1} L~sym=U~Λ~U~−1分解得到)。
x
~
\tilde x
x~的平滑度是:
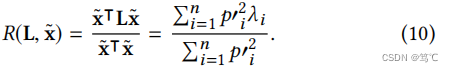
因此,
p
′
i
2
{p'} ^{2}_i
p′i2应该随着
λ
i
λ_i
λi 的增加而减少。将最大特征值表示为λmax。理论上,如果k > 1/λmax,滤波器在(1/k,λmax ]区间内不是低通,因为
p
′
i
2
{p'} ^{2}_i
p′i2 在这个区间内增加;否则,如果k < 1/λmax,滤波器不能全部去噪高频组件。因此,k = 1/λmax 是最优选择。
已有论文证明了拉普拉斯特征值的范围在0~2之间,因此GCN滤波器在(1,2]区间内不是低通的。一些工作相应地选择了k = 1/2。然而,论文的实验表明,在重整化后,最大特征值λmax将缩小到3/2左右,这使得1/2也不是最优的。在实验中,论文计算每个数据集的λmax,并设置k = 1/λmax。
4.3 自适应编码器
通过 t t t 层拉普拉斯平滑过滤,输出特征更平滑,保持丰富的属性信息。
为了从平滑的特征中学习更好的节点嵌入,需要找到一个合适的无监督优化目标。为此,模型设法利用了受深度自适应学习启发的成对节点相似性。对于属性图嵌入任务,两个节点之间的关系至关重要,这要求训练目标是合适的相似度度量。基于GAE的方法通常选择邻接矩阵作为节点对的真实标签。但是,认为邻接矩阵只记录了一跳结构信息,这是不够的。同时,解决了平滑特征或训练嵌入的相似性更准确,因为它们将结构和特征结合在一起。为此,自适应地选择高相似度的节点对作为正训练样本,而低相似度的节点对作为负训练样本。
给定过滤后的节点特征
X
~
\tilde{X}
X~,节点嵌入由线性编码器
f
f
f 进行编码:
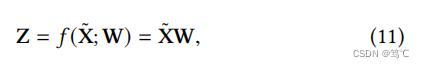
其中,W是权重矩阵。然后,通过最小-最大标量器扩展嵌入到[0,1]区间,以减少方差。为了度量节点的成对相似度,利用余弦函数来实现的相似度度量。相似度矩阵 S 被计算为:

4.3.1 训练样本选择
在计算相似矩阵后,对相似序列按降序排列。这里 r i j r_{ij} rij是节点对 ( v i , v j ) (vi, vj) (vi,vj)的秩。然后将正样本的最大秩设为 r p o s r_{pos} rpos,将负样本的最小秩设为 r n e g r_{neg} rneg。因此,为节点对 ( v i , v j ) (vi, vj) (vi,vj)生成的标签为:
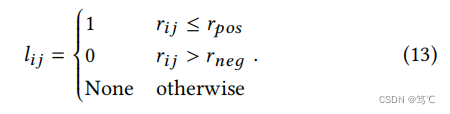
这样,就构造了一个具有
r
p
o
s
r_{pos}
rpos正样本和
n
2
−
r
n
e
g
n^2 - r_{neg}
n2−rneg负样本的训练集。特别地,第一次构造了训练集,由于编码器没有被训练,直接使用平滑的特征来初始化S:

在构建训练集后,可以以有监督的方式训练编码器。在现实世界的图中,总是有更多的不同节点对比正对,所以在训练集中选择了更多的
r
p
o
s
r_{pos}
rpos负样本。为了平衡正/负样本,模型在每个epoch随机选择
r
p
o
s
r_{pos}
rpos负样本。平衡训练集用
O
\mathcal{O}
O 表示,对应地,的交叉熵损失如下:
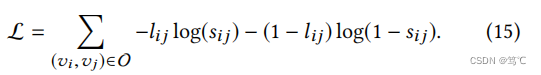
4.3.2 阈值更新
受相关工作启发,为
r
p
o
s
r_{pos}
rpos和
r
n
e
g
r_{neg}
rneg设计了一个特定的更新策略来控制训练集的大小。在训练过程开始时,选择更多的样本为编码器寻找粗糙的聚类模式。在此之后,保留具有更高置信度的样本进行训练,迫使编码器捕获细化的模式。在实践中,随着训练过程的进行,
r
p
o
s
r_{pos}
rpos减少,而
r
n
e
g
r_{neg}
rneg呈线性增加。将初始阈值设置为
r
p
o
s
s
t
r^{st}_{pos}
rposst和
r
n
e
g
s
t
r^{st}_{neg}
rnegst,最终阈值设置为
r
p
o
s
e
d
r^{ed}_{pos}
rposed和
r
n
e
g
e
d
r^{ed}_{neg}
rneged。有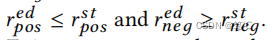
。假设阈值被更新为T次,将更新策略表示为:
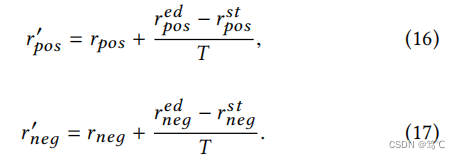
随着训练过程的进行,每次阈值更新时,都会重建训练集并保存嵌入。对于节点聚类,模型对保存嵌入的相似矩阵进行谱聚类,利用戴维斯堡丁索引(DBI)选择最佳时期,在没有标签信息的情况下测量聚类质量。对于链路预测,在验证集上选择执行得最好的epoch。
5. 实验
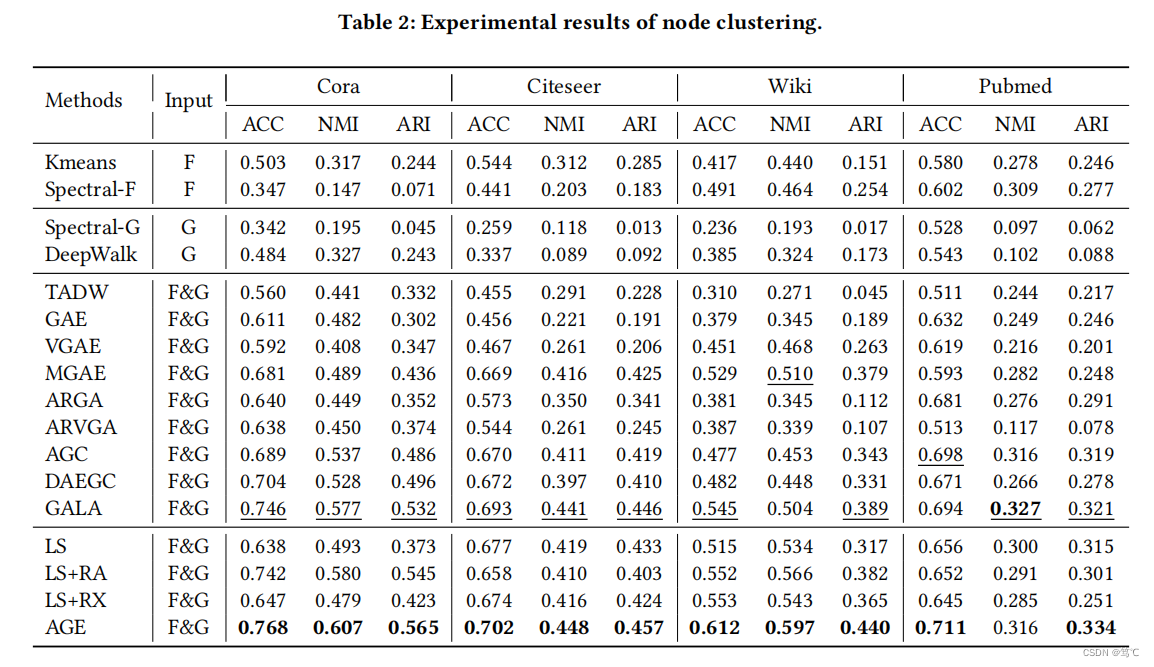
5.1 节点聚类
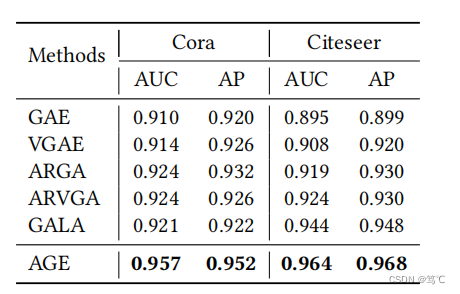
5.2 链路预测
6. 总结
论文提出了一个统一的无监督图表示学习模型。从图信号平滑的角度研究了图的卷积运算,并设计了一种保持最优去噪特性的非参数拉普拉斯平滑滤波器来滤波高频噪声。在编码器部分,发现自适应学习更适合于嵌入。在标准基准测试上的实验表明,论文的模型已经优于最先进的基线算法。
















 1211
1211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











