







原文链接:Coherent Semantic Attention for Image Inpainting (ICCV 2019). Hongyu Liu, Bin Jiang, Yi Xiao, Chao Yang [Paper][Code]
本文创新点:提出 coherent semantic attention (CSA) layer,保证修复区域和已知区域的语义一致性,使用Consistency loss对CSA进行训练,同时设计了特征块判别器(feature patch discriminator),实现更好的预测。
网络结构
网络主要分为两个部分:粗修复网络和细修复网络。
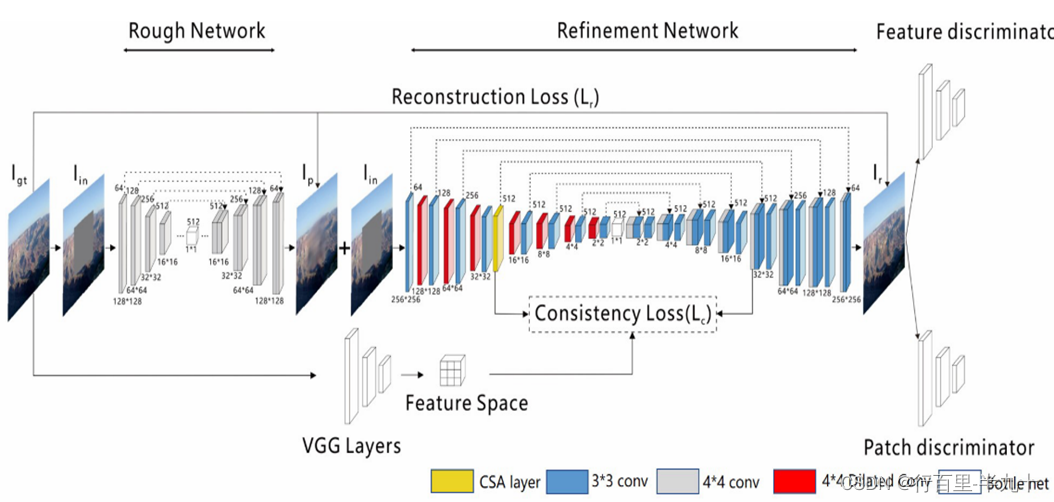
其中,![]() 为粗略预测图像,
为粗略预测图像,![]() 为最终输出图像。
为最终输出图像。
Coherent Semantic Attention(CSA)
CSA的主要思想:生成的patch不仅要考虑与已知区域的相似关系,还要考虑与上一次生成patch之间的关系。
Coherent Semantic Attention layer分为两个阶段:Search and Generate。
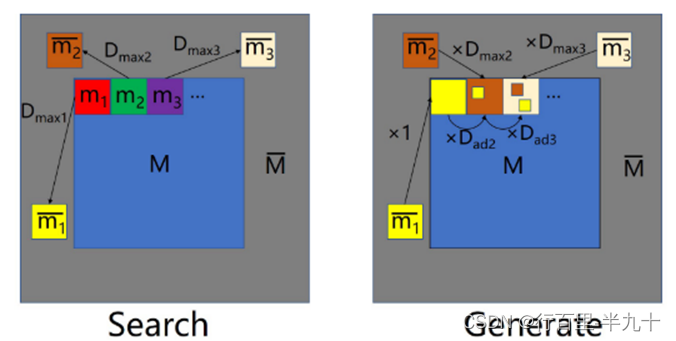
其中M是缺失区域,![]() 为已知区域。
为已知区域。

![]() 代表两个相邻生成的patch之间的相似性,
代表两个相邻生成的patch之间的相似性,![]() 代表缺失区域和已知区域之间最相似的patch。
代表缺失区域和已知区域之间最相似的patch。
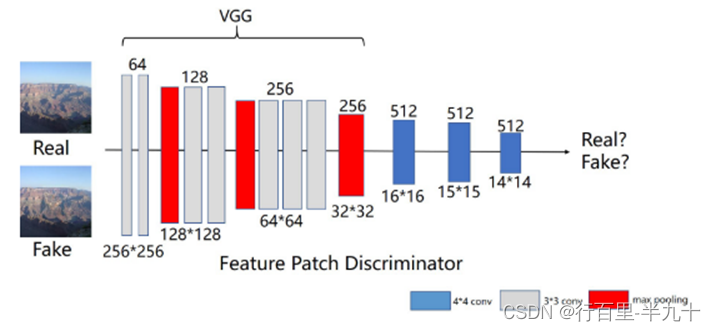
Feature Patch Discriminator
本文还提出了特征块判别器,通过特征真假图片进行判别。
损失函数
Consistency loss
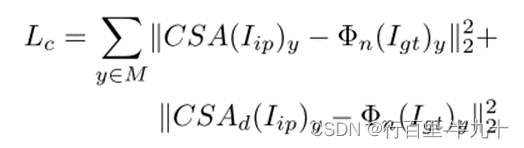
其中![]() 是VGG16所选层的激活图,
是VGG16所选层的激活图,![]() 是CSA层之后的特征,
是CSA层之后的特征,![]() 是解码器中对应的特征。
是解码器中对应的特征。
对抗损失

重构损失

总体损失
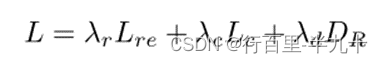















 1350
1350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









