







| 2022 | CVPR 2022 | Bridging Global Context Interactions for High-Fidelity Image Completion [pdf] [code] |
本文创新点:
- 在粗修复阶段,提出限制性卷积块(Restrictive CNN)来提取token;
- 在细修复阶段,提出一个新颖的注意力感知层 (AAL),自适应地平衡对可见内容和生成内容的注意力。
网络结构
网络分为粗修复和细修复两个阶段。粗修复阶段主要使用限制性CNN提取token,并使用transformer获得全局信息。细修复阶段主要使用注意力感知层(ALL)自适应得平衡可见内容和生成内容的之间的注意力。
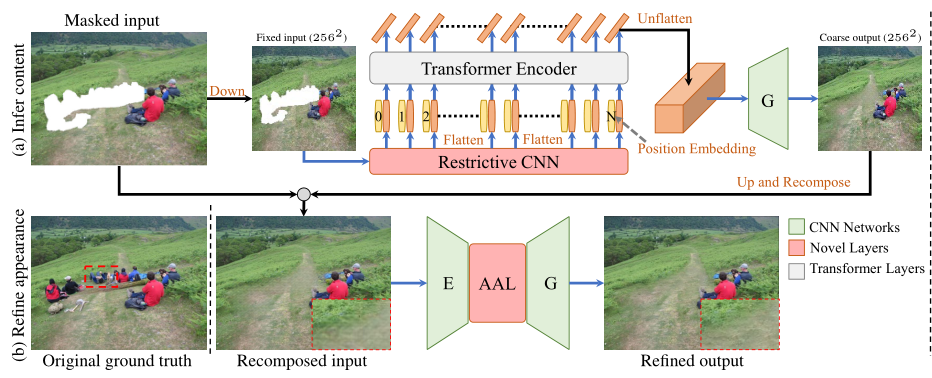
Restrictive CNN
该模块的主要作用就是提取感受野不重叠的token。
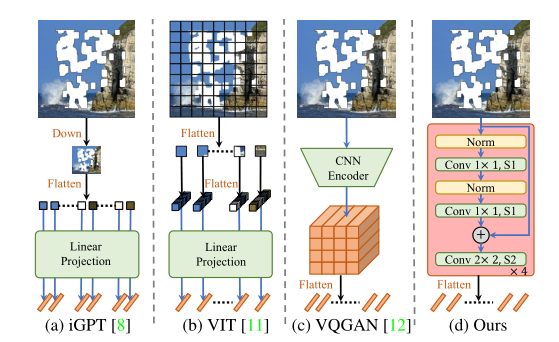
之前提取token, 要么小到一个像素(例如 iGPT ),由于大规模下采样会丢失重要的上下文细节,或者大到整个图像(例如VQGAN),受到深层卷积的影响,token之间的信息可能存在重叠。对于VIT直接把图像划分成patch作为token,《Early convolutions help transformers see better》这篇论文论述了卷积操作是比直接使用patch效果更好。
本文使用四个Restrictive CNN块来提取token。在每个块中,使用1×1 卷积和层归一化用于非线性投影,然后使用部分卷积层提取可见信息。
Attention-Aware Layer (AAL)
该模块的主要作用是从编码和解码特征中复制远程信息。核心思想是,对可见区域(已知区域)和生成区域(掩码区域)分开计算注意力。
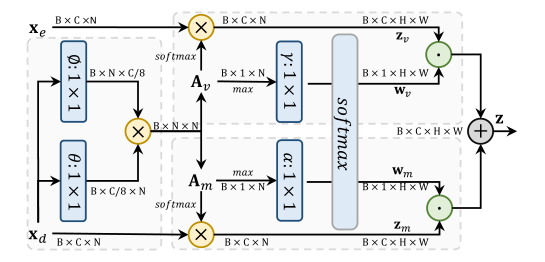
首先,计算编码特征xd元素之间的相似度,然后用过乘上mask和1-mask得到Av(可见区域的相似度)和Am(生成区域的相似度)
![]()
然后分别经过softmax与解码和编码特征相乘,
![]()
根据每个位置的最大注意力分数学习权重,使用 1×1 滤波器 γ 和 α 来调制权重的比率,使用 softmax 是确保每个空间位置的 wv+wm =1。
![]()
最终,输出z为两个特征的加权。
![]()
损失函数
两个阶段都使用重构损失、感知损失和对抗损失进行训练,
![]()
















 669
669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









