







- Context-Aware Image Inpainting with Learned Semantic Priors (IJCAI 2021). Wendong Zhang, Junwei Zhu, Ying Tai, Yunbo Wang, Wenqing Chu, Bingbing Ni, Chengjie Wang, Xiaokang Yang [Paper] [Code]
本文创新点:
- 使用预训练的多标签分类模型H,对语义编码器进行监督;
- 使用空间自适应归一化模块(SPADE)对特征进行融合。
网络结构

Image Encoding
图像编码器采用两个下采样层提取图像特征,
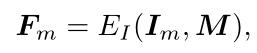
其中,![]()
Semantic Priors Learning
该模块的目标是在预先训练的深层神经网络的监督下,学习受损图像的语义先验。利用在开放图像数据集上预训练的多标签分类模型H,并使用不对称损失(ASL)来提供监督。
首先对输入图像上采样以保留更多的局部结构,然后将上采样后的图像![]() 作为多标签分类模型H的输入,提取的特征图
作为多标签分类模型H的输入,提取的特征图![]() 作为语义先验的监督:
作为语义先验的监督:

语义编码器Es 由3个下采样层和5个残差块构成,输入为上采样后的图像和掩码,输出为语义先验![]()

然后使用1*1卷积进行通道变换,得到![]()
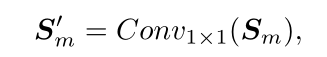
最后用重构损失进行监督,

Context-Aware Image Inpainting
由于图像特征Fm和学习的语义先验Sm关注图像内容的不同方面,直接将这些特征拼接起来进行特征融合,不仅会干扰可见区域的局部纹理,还会影响相应编码器的学习过程。
作者使用空间自适应归一化模块(SPADE) 进行特征融合,首先用实例归一化对输入图像特征Fm进行归一化。然后,从语义先验Sm中学习两组不同的参数,对图像特征Fm进行空间像素仿射变换:

最后,利用融合后的特征生成修复图像
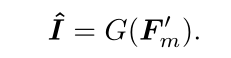
损失函数
损失函数由重构损失、对抗损失以及先验损失三个部分构成。

















 1154
1154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









