









机器学习:监督学习的分类问题
开源的鸢尾花分类的iris 数据集作为输入。iris数据集的中文名是安德森鸢尾花卉数据集,英文全称是 Andersori’s Iris data seto,它包含150个样本,是用来给花做分类的数据集,
每个样本包含了萼片长、萼片宽度、花瓣长度和花瓣宽度4个特征(注:机器学习领域自变量叫特征,因变量叫标签),放在前4列作为输人的特征矩阵。每行的最后一个数据是类别信息,包括3种,即山鸢尾、变色亨尾和维吉尼亚鸢尾。
#获取鸢尾花数据集
from sklearn.datasets import load_iris
# 1.获取鸢尾花数据集
iris = load_iris()
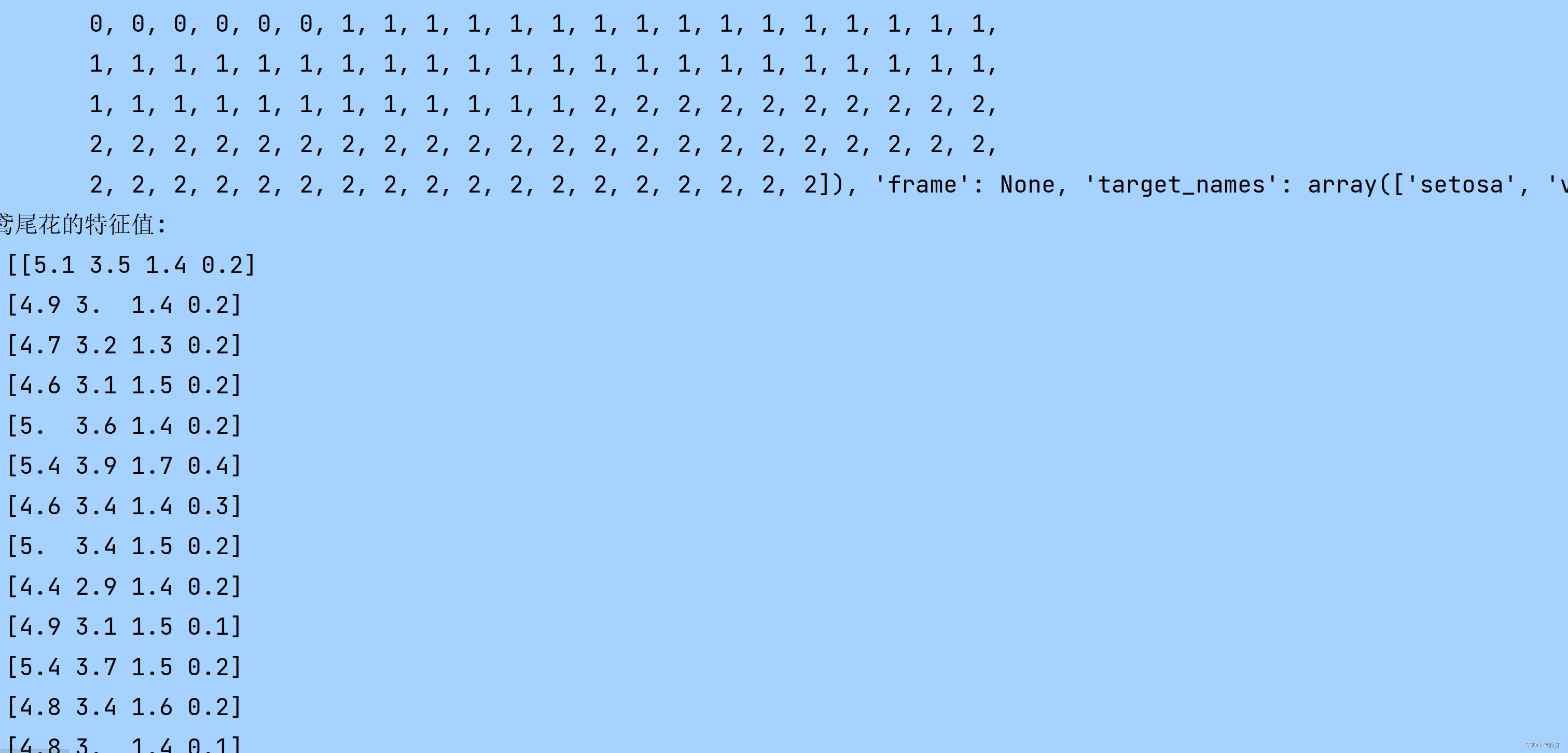
print("鸢尾花数据集的返回值:\n", iris) #返回值所有数据
print("鸢尾花的特征值:\n", iris["data"])
print("鸢尾花的样本标签:\n", iris.target)
print("鸢尾花的种类:\n", iris.feature_names)
print("鸢尾特征名称:\n", iris.target_names)
print("鸢尾花的描述:\n", iris.DESCR
输出:
其中load_iris()函数:
‘data’:鸢尾花的四个特征矩阵,里面是花萼长度、花萼宽度、花瓣长度、花瓣宽度的测量数据;
‘target’:样本的标签(每个样本对应的类别,一共3类,分别用‘0’,‘1’,‘2’表示),是一个一维数组;
‘target_names’:花的种类,包括 ‘setosa’, ‘versicolor’ ,'virginica’这3类;
‘DESCR’:是一篇说明文档,对该数据集进行了一个简要的说明
‘feature_names’:特征的名称,包括花萼长度、花萼宽度、花瓣长度、花瓣宽度;
‘filename’:该数据集的文件名(带绝对路径)
# -*- coding: UTF-8 -*-
#加载数据集
from sklearn.datasets import load_iris
iris = load_iris()
# 定义特征矩阵x和响应向量y
X = iris.data
y = iris.target
# 将数据分为训练集和测试集
from sklearn.model_selection import train_test_split
#train_test_split函数可按照用户设定的比例,随机将样本集合划分为训练集和测试集,并返回划分好的训练集和测试集数据。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=1)
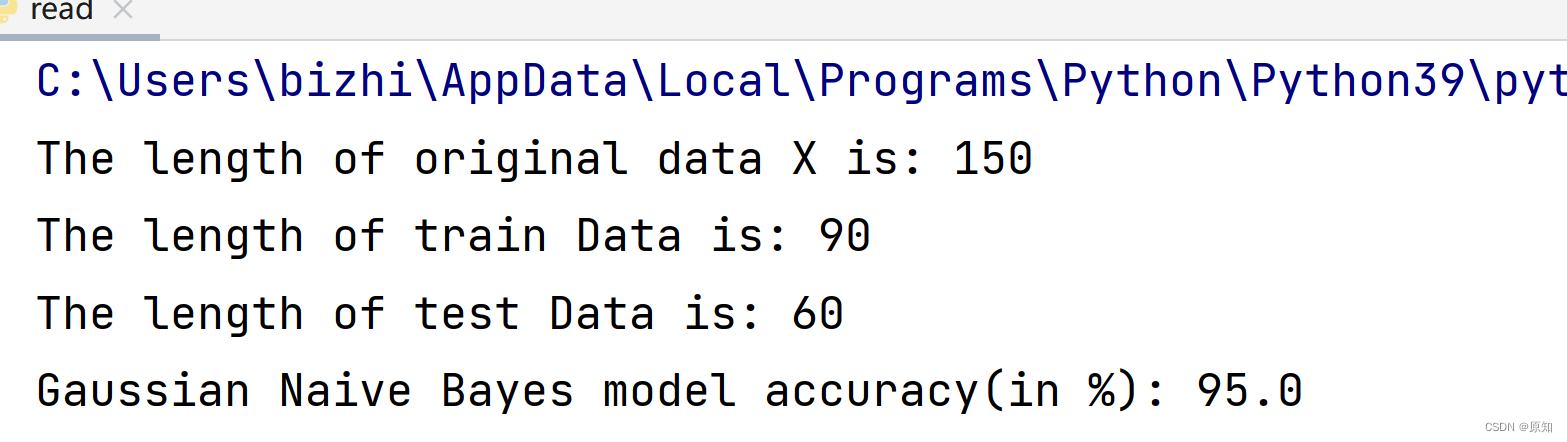
print("The length of original data X is:", X.shape[0])
print("The length of train Data is:", X_train.shape[0])
print("The length of test Data is:", X_test.shape[0])
# 进行机器学习训练train数据集
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB()
gnb.fit(X_train, y_train)
# making predictions on the testing set
#通过前一步训练结果进而对测试集进行预测
y_pred = gnb.predict(X_test)
# comparing actual response values (y_test) with predicted response values (y_pred)
from sklearn import metrics
print("Gaussian Naive Bayes model accuracy(in %):", metrics.accuracy_score(y_test, y_pred)*100)
输出:
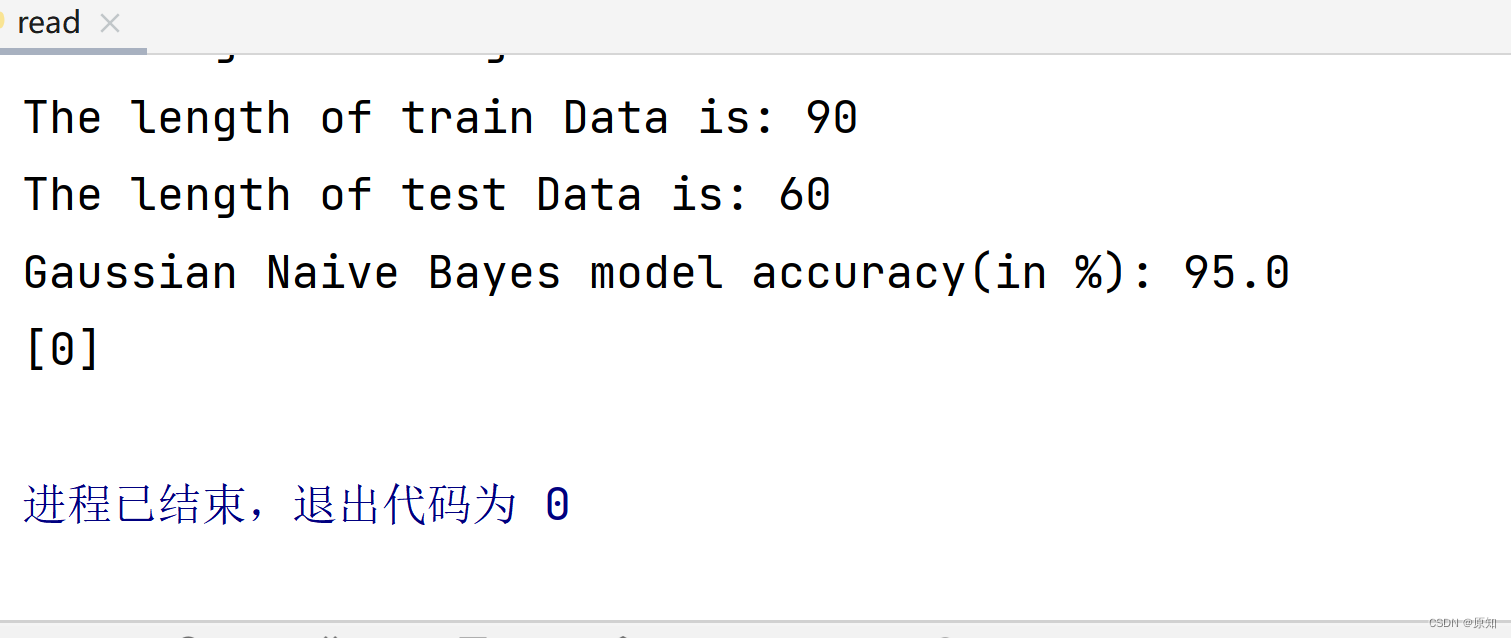
如果在现实生活中,我们看见一朵鸢尾花,可以将数据带入这个训练好的模型中,在上一个代码中加上:
y_1=gnb.predict([[5,3,1,0.2]])
print(y_1)
输出:















 9467
9467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









