









Dense Passage Retrieval for Open-Domain Question Answering
开放域问题回答中的密集段落检索
一、开放领域问答(QA)系统在检索和阅读理解模型上的演变过程
- 2003-2012早期的QA系统很复杂并且包含多个组件
- 2017简化的两阶段框架:
1.上下文检索器首先选择一个小部分的段落,其中一些包含问题的答案,然后
2.机器阅读器可以彻底检查检索到的上下文和确定正确的答案
但在实践中经常观察到巨大的性能下降,这需要改进检索。
- 2009开放领域问答(QA)中的检索通常使用 TF-IDF 或 BM25来实现,
- 直到2019年ORQA出现之前,才显示密集检索方法优于TF-IDF / BM25进行开放领域的QA。
ORQA缺陷:ICT预训练非常计算密集,且不一定能很好地表示普通句子与问题之间的关系。上下文编码器未通过问题和答案对进行微调,因此其表示可能不是最优的。
- DPR其创新之处在于,通过直接微调问题和段落编码器(在现有问题-段落对上),无需额外的预训练,就能够大幅提高检索精度。
二、DPR的基本思想
DPR通过将语料库中的段落(passages)编码为低维向量,并构建索引,对于给定的问题,DPR利用查询向量与语料库中各段落向量的相似度,迅速找到相关段落。具体的,搜索的是这些相关段落中某个文本片段(span)。
Token 是指文本处理中的最小单位,可以是一个词、一个子词(subword)、字符,甚至是标点符号等。它是文本处理和语言模型中常见的基本单位。
三、DPR组成
两个不同的编码器:问题编码器和段落编码器
编码器使用了两种独立的BERT模型(“base”版本,并且是“uncased”即不区分大小写的版本)
四、度量相似度
4.1我们用问题向量的点积来定义问题和段落之间的相似性
![]()
4.2其他相似函数:
余弦相似性cosine:它通常与内积关系密切,特别是在单位向量的情况下,余弦相似性等同于内积。余弦相似度通过计算两个向量的夹角来衡量它们的相似性。
马氏距离:这是一种度量两个数据点之间差异的方法,考虑了数据的协方差。马氏距离可以看作是在一个变换空间中的L2距离。
L2距离(欧几里得距离):虽然在文中提到的是变换空间中的L2距离,通常L2距离是直接计算两个向量之间的欧几里得距离。
4.3其他度量相似度的模型
多层交叉注意力网络
五、训练
5.1训练目的
DPR的训练是一个度量学习问题,学习一个更好的嵌入函数,其目标是通过优化编码器,使得相似的问答对在向量空间中具有较小的距离(即更高的相似度),而不相关的段落距离较大。
5.2训练数据
![]()

5.3样本选择策略:批内负样本(In-batch negatives)


取小批次:大小为B,其中每个问题都与一个相关段落关联(qi,pi)。
已经证明,这是一种有效的策略,用于学习双编码器模型,并能够提高训练样本的数量。
5.4损失函数
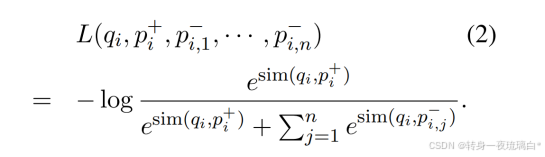

我们通过优化损失函数,使得正向段落的负对数似然最大化。该损失函数旨在最大化正样本与负样本之间的相似度差异。
六、实验:段落检索
6.1实验数据
文档集合:使用2018年12月20日的英语维基百科数据TREC、WebQuestions、TriviaQA、NQ 和 SQuAD
6.2预处理:
- 提取干净的文本部分。包括去除半结构化数据,例如表格、信息框、列表以及消歧义页面。
- 将每篇文章拆分成多个不重叠的100字文本块作为段落,作为基本的检索单元,段落前面加上该段落所在文章的标题,并加上[SEP]标记。
3.选取了五个数据集并且选择正样本
6.3 DPR模型与训练设置:
• DPR使用批内负样本训练,批大小为128,每个问题附带BM25负样本。
• 对于大数据集(NQ、TriviaQA、SQuAD)训练最多40个epoch,小数据集(TREC、WQ)最多100个epoch。
• 优化器为Adam,学习率为10⁻⁵,采用线性调度和热启动策略。
6.4与传统检索方法(BM25)的对比结果:
训练方案:
DPR在大多数数据集上top-k表现优于BM25
有时,DPR和BM25结合(BM25+DPR)可进一步提升结果。
样本效率:
仅用1,000个训练样本,DPR就能超越BM25,增加样本量进一步提高准确率。
批内负样本训练:
与传统的1-of-N训练方法相比,批内负样本训练显著提升了DPR准确率,尤其使用“困难”负样本(高BM25分数但无答案的文档)时效果最佳。
金标准文档影响:
使用自动选择的BM25文档(远程监督)作为正样本,与金标准文档相比,准确率较少,自动方法对性能影响较小。
跨数据集泛化:
在没有额外微调的情况下,DPR能在不同数据集上良好泛化,且性能仅低于微调模型3-5个百分点,远超BM25。
定性分析:
DPR与BM25的检索质量不同:BM25依赖于关键词匹配,而DPR能够更好地捕捉语义关系和词汇变体。
运行效率:
• 构建效率:DPR的密集向量索引构建时间较长,建立FAISS索引需8.5小时,而Lucene建立倒排索引仅需30分钟。
• 处理效率:使用FAISS内存索引时,DPR每秒处理995个问题,远高于BM25(Lucene建立倒排索引)的23.7个问题。
6.5相似性度量与损失函数:
• L2距离和点积表现相似,均优于余弦相似度。
• 三元组损失与负对数似然损失的比较表明,三元组损失对性能影响不大。
七、实验:问答系统
7.1端到端问答系统
结构:包含文档检索器和神经阅读器。检索器返回前k个文档,阅读器选择最相关文档并提取答案。
文档选择:通过交叉注意力机制进行排序,选择得分最高的文档中的答案跨度。
训练:从前100个检索文档中采样正负样本,优化文档选择和答案跨度的对数似然。
7.2实验结果
检索器准确性与问答准确性:较高的检索器准确性通常能提高问答准确性。DPR在大数据集(如NQ、TriviaQA)和小数据集(如WQ、TREC)上都表现良好,后者通过多数据集训练具有优势。
DPR优于ORQA和REALM:DPR通过专注于学习强大的文档检索模型,超越了ORQA和REALM,在NQ和TriviaQA上表现优秀。
消融实验:DPR通过单独训练检索器和阅读器,相比联合训练方法(EM 39.8)具有更好的效果。
延迟与吞吐量:DPR处理最多100个文档,延迟维持在20毫秒左右,推理效率高。相比之下,ORQA处理更长文档时,计算复杂度较高,推理时间较长。

















 619
619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









