







开放域问答的密集段落检索
摘要
开放域问答依赖于有效的段落检索去选择候选内容,传统的稀疏向量空间模型,比如 TF-IDF 恶和 BM25,确实是一个方法。
在这项工作中,我们证明了检索实际上可以单独使用密集表示来实现,其中嵌入是通过一个简单的双编码器框架从少量的问题和段落中学习到的。
在广泛的开放域 QA 数据集上进行评估时,我们的密集检索器在前 20 个段落检索准确率方面的绝对性能大大超过强大的 Lucene-BM25 系统 9%-19%,并帮助我们的端到端 QA 系统在多个开放域 QA 基准上建立新的最先进水平。
1.引言
开放域问答(QA)是一项使用大量文档集合来回答问题的任务。早期 QA 系统通常是复杂度并且由很多组件组成,而现在先进的阅读理解模型提出了一个简单的两阶段框架:
- 一个内容检索器首先选择段落的一小部分子集,他们的一些包含问题的回答,然后
- 一个机器阅读者能全文检查检索到的内容并识别正确答案
虽然将开放域 QA 减少到机器阅读 是一个非常合理的策略,但在实践中经常观察到巨大的性能下降,这表明需要改进检索。
开放域 QA 检索通常使用 TF-IDF 和 BM25 实现,使用一个倒排索引匹配关键词 并且 可以看作是用**高维稀疏向量(带权重)**表示问题和上下文。
相反,密集的、潜在的语义编码是通过设计对稀疏表示的补充。例如,由完全不同的 token 组成的同义词或释义仍然可以被映射到彼此接近的向量。考虑问题“who is the bad guy in lord of the ring?”,能被这个内容进行回答”Sala Baker is best known for portraying the villain Sauron in the Lord ofthe Rings trilogy.”
基于词条的系统检索这样的上下文是非常困难的,一个密集检索系统应该能更好用 “villain” 匹配 ”bad guy” 并且拿取正确的上下文。
说白了,就是稀疏表示难以匹配一词多义问题。
密集编码通过调节 embedding 的功能被学习,这提供了额外的灵活性以具有特定于任务的表示。
利用特殊记忆的数据结构和索引方案,可以使用最大内积搜索(MIPS)算法。
然而,人们普遍认为,学习一个好的密集向量表示需要大量的问题和上下文的 label 对。
因此,在 ORQA 之前,密集检索方法从未显示出优于 TF-IDF/BM25 的开放式 QA,ORQA 提出了一个复杂的反向完形填空任务目标,预测包含掩蔽句的块,用于额外的预训练。问题编码器和阅读者模型然后使用 QA 对一起被微调。
ORQA(Open Retrieval Question Answering)结合了开放域信息检索和深度学习技术的方法,用于解决开放域问答任务。
ORQA 的核心思想是利用大规模预训练模型来提高信息检索的质量,进而提升问答系统的准确性
尽管 ORQA 成功展示了密集检索能优于 BM25,完成了新的 SOTA,但是他有两个弱点。
- 首先,ICT(反向完形填空) 预训练计算密集型的,并且不完全清楚常规句子是目标函数中问题的良好替代物
- 第二,因为上下文编码器不是使用成对的问题和答案来微调的,所以相应的表示可能是次优的。
在这篇论文中,我们处理了这个问题:
我们能否只使用 问题段落对 或 问题答案对 训练一个更好的密集 embedding 模型?
通过利用现在标准的 BERT 预训练模型 和 双编码器架构,我们专注于使用相对较少的问题和文章对来开发正确的训练方案。
通过一系列的消融性研究,我们最终的解决方案是惊人的简单:
embedding 被优化通过**最大化问题和相关段落向量的内积,**目的是比较一批中的所有问题和段落对。
我们的密集段落检索器(DPR) 非常健壮。它不仅很大程度优于BM25,而且在开放式自然问题设置中,与 ORQA 相比,端到端 QA 的准确度也有了实质性的提高。
我们的贡献是双重的。
- 首先,我们证明了在适当的训练设置下,简单地对现有 问题-段落对 的 问题和段落编码器 进行微调就足以大大超过 BM25。我们的实证结果还表明,额外的预训练可能不需要。
- 其次,我们验证了在开放领域问答环境中,较高的检索精度确实转化为较高的端到端问答准确率。通过将现代读者模型应用于检索到的最佳段落,与几个复杂得多的系统相比,我们在开放检索设置中的多个 QA 数据集上获得了可比或更好的结果。
2.背景
本文研究的开放域QA问题可以描述如下。
给一个事实问题:”Who first voiced Meg on Family Guy?” 或 ““Where was the 8th Dalai Lama born?”,需要一个系统使用大量多样化主题的语料库来回答它。
更具体,我们假设额外的 QA 设置,其中答案被限制为出现在语料库中的一个或多个段落中的跨度。
假设我们的集合包含 D 个文档, d 1 , d 2 , … , d D d_1,d_2,…,d_D d1,d2,…,dD。我们首先分割文档的每一个为相等长度的文本段落,作为基础的检索单元,并且得到 M 个总段落在我们的语料库 C = { p 1 , p 2 , … , p M } C=\{p_1,p_2,…,p_M\} C={p1,p2,…,pM} 中,每个段落 p i p_i pi 被看作是一个 w 1 ( i ) , w 2 ( i ) , . . . , w ∣ p i ∣ ( i ) w^{(i)}_1,w^{(i)}_2,...,w^{(i)}_{|p_i|} w1(i),w2(i),...,w∣pi∣(i) 序列。给定一个问题q,任务是从其中一个段落 p i p_i pi 中找到一个可以回答这个问题的跨度 w s ( i ) , w s + 1 ( i ) , … , w e ( i ) w^{(i)}_s,w^{(i)}_{s+1},…,w^{(i)}_e ws(i),ws+1(i),…,we(i)。注意,为了覆盖各种各样的领域,语料库的大小可以很容易地从数百万个文档(例如,Wikipedia)到数十亿(例如,WEB)。
结果,任何开放域QA系统需要包括一个有效的检索器组件,这个组件可以选择一小部分的相关文本,在让阅读者去抽取回答之前。
从形式上讲,检索器 R : ( q , C ) → C F R:(q,C)→ C_F R:(q,C)→CF 是一个函数,它将问题 q 和语料库 C 作为输入,并返回一个小得多的文本过滤器集合 C F ∈ C C_F\in C CF∈C,其中 ∣ C F ∣ = k < < ∣ C ∣ |C_F| = k<<|C| ∣CF∣=k<<∣C∣ 。对于固定的 k,检索器可以在 top-k 检索准确度上孤立地进行评估,top-k 检索准确度是 C F C_F CF包含回答问题的跨度的问题的分数。
3.稠密段落检索器(DPR)
我们的工作室提升检索组件的性能在开放域 QA 领域。
3.1 总览
DPR 使用密集编码器 E P ( ⋅ ) E_P(·) EP(⋅) ,他能映射任何输入段落到 d 维向量 并且 为我们将检索的所有 M 个段落建立一个索引。
在运行时的时候,DPR 应用一个不同的编码器 E Q ( ⋅ ) E_Q(·) EQ(⋅) ,他能映射输入问题到一个 d 维向量,并且检索 k 个向量最接近问题的段落。
我们定义问题和段落的相似性的时候使用向量内积(IP):
s i m ( p , q ) = E Q ( q ) T E P ( p ) sim(p,q)=E_Q(q)^TE_P(p) sim(p,q)=EQ(q)TEP(p)
虽然存在更有性能的模型来测量问题和段落之间的相似性,例如由多层交叉注意力组成的网络,但相似性函数需要是可分解的,以便可以预先计算段落集合的表示。
大多数可分解的相似性函数是欧氏距离(L2)的一些变换。
例如,余弦是和内积相等的对于单位向量;L1 距离和 L2 距离是相等的在转移空间。
我们的消融性研究中发现其他相似性函数的执行比较(section 5.2),我们因此选择了内积函数。
编码器
尽管原则上问题和段落编码器能被实现通过任何神经网络,但是我们使用了两个独立的 BERT并且把 [CLS] 的表示作为输出,因此 d=768.
推理
在推理的时候,我们应用段落编码器 E P E_P EP 给所有的段落,并且索引化他们使用 FAISS。给定一个问题 q,我们使用他的 embedding v q = E Q ( q ) v_q=E_Q(q) vq=EQ(q) 并且 使用最接近 v q v_q vq embedding 检索 topk 段落
3.2 训练
训练编码器以便内积相似度,因为对于检索来说,一个好的排序函数是一个基本的度量学习问题(如下公式)。
s i m ( p , q ) = E Q ( q ) T E P ( p ) sim(p,q)=E_Q(q)^TE_P(p) sim(p,q)=EQ(q)TEP(p)
目标是创造一个向量空间以便相关的 问题-段落对 将有相似的距离。
让 D = { < q i , p i + , p i , 1 − , … , p i , n − > } i = 1 m D=\{<q_i,p^+_i,p^-_{i,1},…,p^-_{i,n}>\}^m_{i=1} D={<qi,pi+,pi,1−,…,pi,n−>}i=1m 成为训练数据,由 m 个实例组成。
每个实例包含一个问题 q i q_i qi 和一个相关的段落 p i + p^+_i pi+(正),和 n 个不相关的段落 p i , j − p^-_{i,j} pi,j− 。
我们优化这个损失函数使用正样本段落的负对数概率
L ( q i , p i + , p i , 1 − , … , p i , n − ) = − log e s i m ( q i , p i + ) e s i m ( q i , p i + ) + ∑ j = 1 n e s i m ( q i , p i , j − ) L(q_i,p^+_i,p^-_{i,1},…,p^-_{i,n})=-\log \frac{e^{sim(q_i,p^+_i)}}{e^{sim(q_i,p^+_i)}+\sum^n_{j=1}e^{sim(q_i,p^-_{i,j})}} L(qi,pi+,pi,1−,…,pi,n−)=−logesim(qi,pi+)+∑j=1nesim(qi,pi,j−)esim(qi,pi+)
正和负段落
对于检索问题,他通常正样本是容易获取的,但是负样本需要从非常大的池里面去挑选。
例如,与问题相关的段落可能在一个 QA 数据集中被给定,或者能使用回答发现。
所有集合中的其他段落,尽管没有明确指出,但他们默认被认为是不相关的。实际上,如何挑选负样本是非常容易忽略的,但是对于高质量的编码器可能又是决定性的。
我们考虑三个不同的负样本类型:
- 随机:来自语料库的任何随机段落
- BM25:BM25 返回的不包含答案但匹配大多数问题 token 的 top 段落;(用 BM25 选出来的,看似和答案相关,但实则不包含答案)
- Gold:正样本段落与训练集中出现的其他问题配对(将原本作为正样本的文档与其他问题配对,从而形成负样本;取一个已知正确答案的问题-文档对,然后将这个文档与其他问题组合,这样产生的新对就是负样本了)。
我们将讨论不同类型负样本段落的影响。我们的最佳模型使用来自相同小批次的 gold 段落和一个 BM25 负样本段落。
特别地,将来自同一批次的 gold 段落作为负样本重新使用可以使计算高效,同时实现很好的性能。
In-batch negatives(批次哪负样本)
假设我们有 B 个问题在一个 mini-batch 中,并且每一个都与一个 相关的 段落 相关联。
让 Q 和 P 是一个 B 的批次大小中问题和段落的 embedding矩阵( B × d B\times d B×d)
S = Q P T S=QP^T S=QPT 是一个 B × B B\times B B×B 的相似性分数矩阵,其中每行对应一个问题,与 B 段落配对。
通过这种方式,我们在每个批次中重用计算并有效地训练 B 2 ( q i , p j ) B^2(q_i,p_j) B2(qi,pj) 问题/段落对。当i = j时,任何 ( q i , p j ) (q_i,p_j) (qi,pj)对都是正例,否则为负例。
4.实验设置
4.1 wiki 数据预处理
使用英语 wiki 的开源文档的问答对。
4.2 QA 数据集
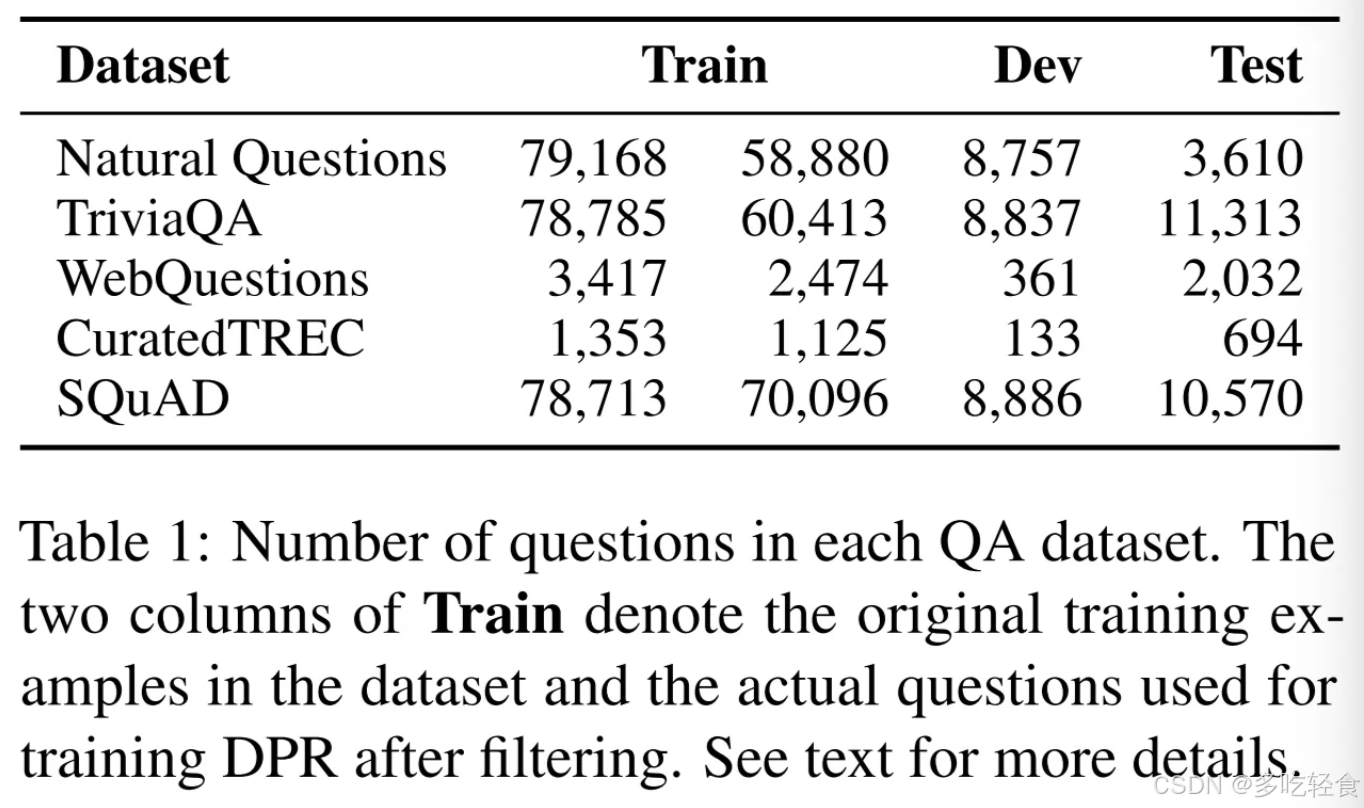
我们使用与以前工作相同的五个 Q A数据集和训练/开发/测试分割方法。
Natural Question(NQ)\TriviaQA\WebQuestions(WQ)\CuratedTREC(TREC)\SQuAD v1.1
5.实验
5.1 主要结果
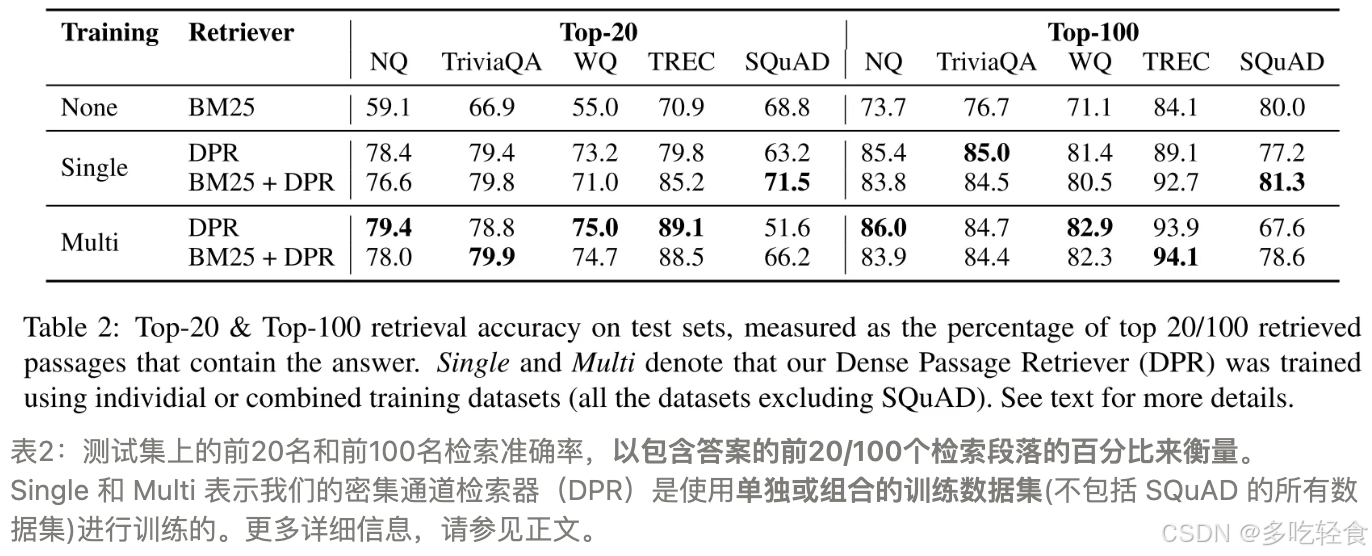
表2:测试集上的前20名和前100名检索准确率,以包含答案的前20/100个检索段落的百分比来衡量。
Single 和 Multi 表示我们的密集通道检索器(DPR)是使用单独或组合的训练数据集(不包括 SQuAD 的所有数据集)进行训练的。更多详细信息,请参见正文。
当 k 比较小的时候,DPR 会比 BM25 更好
5.2 模型训练的消融性研究
样本效率
使用一般的预训练语言模型,可以用少量的问题-段落对来训练高质量的密集检索器。添加更多的训练示例(从1 k到59 k)进一步提高了检索的准确性。
批次内负样本训练
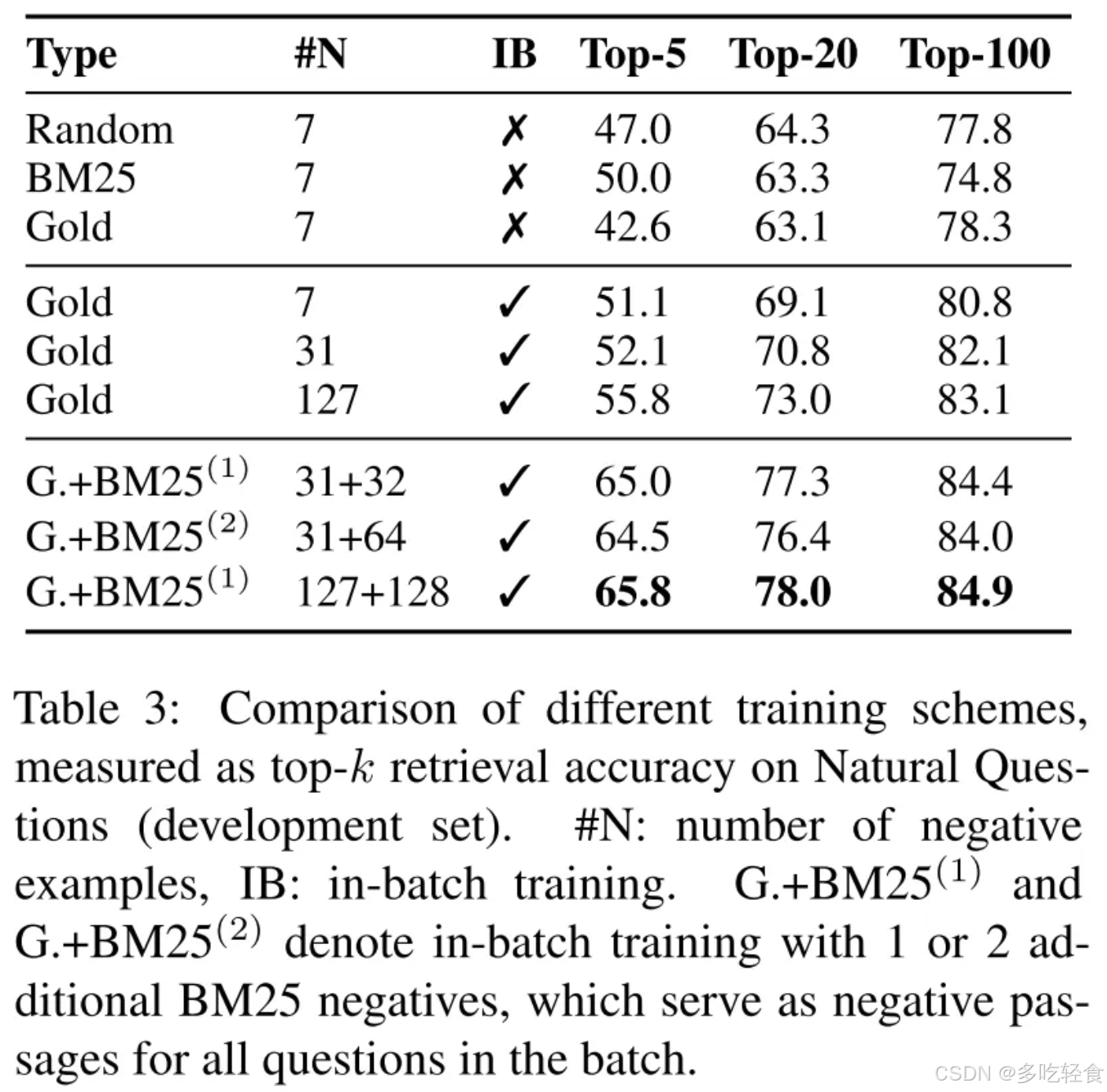
表3:不同训练方案的比较,以自然问题(开发集)上的 top-k 检索准确率衡量。
#N:反面例子的数量,
IB:批量训练。
G.+
B
M
2
5
(
1
)
BM 25^{(1)}
BM25(1) 和 G.+
B
M
2
5
(
2
)
BM 25^{(2)}
BM25(2):表示具有 1 个或 2 个额外 BM25 负样本的批内训练,其用作该批中所有问题的负样本段落。
相似度和损失函数
发现 L2 的性能与点积相当,并且两者都优于余弦。
我们还发现,除了负对数概率,用于排序的流行选项是三元组损失。

















 788
788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









