







Tensorflow分类任务
Mnist 数据集(演示)
读取 Mnist 数据集
- 使用 TensorFlow 直接获取处理 MNIST 数据
from tensorflow.examples.tutorials.mnist import input_data
#载入MNIST数据集,如果指定地址下没有下载好的数据,那么TensorFlow会自动在网站上下载数据
mnist = input_data.read_data_sets("/tensorflow_google")
# 打印训练数据大小
print("Training data size: ", mnist.train.num_examples)
# 打印验证集数据大小
print("Validating data size: ", mnist.validation.num_examples)
# 打印测试集数据大小
print("Testing data size: ", mnist.test.num_examples)
WARNING:tensorflow:From C:\user\default\AppData\Local\Temp\ipykernel_17068\2078164747.py:4: read_data_sets (from tensorflow.examples.tutorials.mnist.input_data) is deprecated and will be removed in a future version.
Instructions for updating:
Please use alternatives such as: tensorflow_datasets.load('mnist')
WARNING:tensorflow:From D:\ProgramData\Anaconda3\envs\tensorflow2.8\lib\site-packages\tensorflow\examples\tutorials\mnist\input_data.py:296: _maybe_download (from tensorflow.examples.tutorials.mnist.input_data) is deprecated and will be removed in a future version.
Instructions for updating:
Please write your own downloading logic.
WARNING:tensorflow:From D:\ProgramData\Anaconda3\envs\tensorflow2.8\lib\site-packages\tensorflow\examples\tutorials\mnist\input_data.py:299: _extract_images (from tensorflow.examples.tutorials.mnist.input_data) is deprecated and will be removed in a future version.
Instructions for updating:
Please use tf.data to implement this functionality.
Extracting /tensorflow_google\train-images-idx3-ubyte.gz
WARNING:tensorflow:From D:\ProgramData\Anaconda3\envs\tensorflow2.8\lib\site-packages\tensorflow\examples\tutorials\mnist\input_data.py:304: _extract_labels (from tensorflow.examples.tutorials.mnist.input_data) is deprecated and will be removed in a future version.
Instructions for updating:
Please use tf.data to implement this functionality.
Extracting /tensorflow_google\train-labels-idx1-ubyte.gz
Extracting /tensorflow_google\t10k-images-idx3-ubyte.gz
Extracting /tensorflow_google\t10k-labels-idx1-ubyte.gz
WARNING:tensorflow:From D:\ProgramData\Anaconda3\envs\tensorflow2.8\lib\site-packages\tensorflow\examples\tutorials\mnist\input_data.py:328: _DataSet.__init__ (from tensorflow.examples.tutorials.mnist.input_data) is deprecated and will be removed in a future version.
Instructions for updating:
Please use alternatives such as official/mnist/_DataSet.py from tensorflow/models.
Training data size: 55000
Validating data size: 5000
Testing data size: 10000
若出现 ModuleNotFoundError: No module named 'tensorflow.examples’报错,
原因:
TensorFlow包下缺少tutorials文件夹,
下载地址为:
链接:https://pan.baidu.com/s/1YCIT7pwvcb_VxJioli8r1g
提取码:5hli
将压缩包解压后放入自己的 anaconda的安装有 tensorflow的环境下面,注意可能需要创建examples文件夹
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fan2Df3D-1653055828263)(attachment:image.png)]](https://img-blog.csdnimg.cn/bd58bc740a4d41e99347af8f6ec8505d.png)
获取数据和标签的方法有很多种
# 批量获取数据和标签【使用next_batch(batch_size)】
# x_train 是数据,y_train 是对应的标签, batch_size=50000,批量读取50000张样本
x_train, y_train = mnist.train.next_batch(50000)
# 先获取数据值
# x_valid 是验证集的所有数据
x_valid = mnist.validation.images
# 再获取标签值,label=[0,0,...,0,1],是一个1*10的向量
# y_valid 是验证集所有数据的标签
y_valid = mnist.validation.labels
展示训练集中一张图像
from matplotlib import pyplot
import numpy as np
pyplot.imshow(x_train[0].reshape((28, 28)), cmap='gray')
print(x_train.shape)
(50000, 784)

![直接上传(img-1TaNyx2l-1653055828265)(attachment:image.png)]](https://img-blog.csdnimg.cn/f15e2e2905f546f181084b9e5a485884.png)
import tensorflow as tf
from tensorflow.keras import layers
model = tf.keras.Sequential()
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
# 回归问题中设置为1,是为了得到一个结果值。
# 现在设置为10个,是有十个类别,数据属于哪个类别
选择损失和评估函数时候需要选择合适的 Api 参考:https://www.tensorflow.org/api_docs/python/tf/keras/metrics/SparseCategoricalAccuracy]
一定要选择合适的损失函数
tf.losses.CategoricalCrossentropy
keras.losses.CategoricalCrossentropy
model.compile(optimizer=tf.keras.optimizers.Adam(0.005),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()])
model.fit(x_train, y_train, epochs=5, batch_size=64,
validation_data=(x_valid, y_valid))
Epoch 1/5
782/782 [==============================] - 4s 3ms/step - loss: 0.3060 - sparse_categorical_accuracy: 0.9082 - val_loss: 0.1765 - val_sparse_categorical_accuracy: 0.9452
Epoch 2/5
782/782 [==============================] - 2s 3ms/step - loss: 0.1671 - sparse_categorical_accuracy: 0.9489 - val_loss: 0.1669 - val_sparse_categorical_accuracy: 0.9502
Epoch 3/5
782/782 [==============================] - 2s 3ms/step - loss: 0.1357 - sparse_categorical_accuracy: 0.9590 - val_loss: 0.1617 - val_sparse_categorical_accuracy: 0.9562
Epoch 4/5
782/782 [==============================] - 2s 3ms/step - loss: 0.1209 - sparse_categorical_accuracy: 0.9635 - val_loss: 0.1432 - val_sparse_categorical_accuracy: 0.9582
Epoch 5/5
782/782 [==============================] - 2s 3ms/step - loss: 0.1074 - sparse_categorical_accuracy: 0.9658 - val_loss: 0.1572 - val_sparse_categorical_accuracy: 0.9542
<keras.callbacks.History at 0x1f9d571cbe0>
tf.data 模块常用函数
tensor 张量,当做是一种矩阵。咱们要处理的输入数据。
flow 流动
我们有各种矩阵,当前在流动,流动过程当中对它做各种各样的变换。
import numpy as np
input_data = np.arange(16)
input_data
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15])
# 用 tf.data.Dataset 模块,将数据统一转化为 tensor 的格式
dataset = tf.data.Dataset.from_tensor_slices(input_data)
for data in dataset:
print(data)
tf.Tensor(0, shape=(), dtype=int32)
tf.Tensor(1, shape=(), dtype=int32)
tf.Tensor(2, shape=(), dtype=int32)
tf.Tensor(3, shape=(), dtype=int32)
tf.Tensor(4, shape=(), dtype=int32)
tf.Tensor(5, shape=(), dtype=int32)
tf.Tensor(6, shape=(), dtype=int32)
tf.Tensor(7, shape=(), dtype=int32)
tf.Tensor(8, shape=(), dtype=int32)
tf.Tensor(9, shape=(), dtype=int32)
tf.Tensor(10, shape=(), dtype=int32)
tf.Tensor(11, shape=(), dtype=int32)
tf.Tensor(12, shape=(), dtype=int32)
tf.Tensor(13, shape=(), dtype=int32)
tf.Tensor(14, shape=(), dtype=int32)
tf.Tensor(15, shape=(), dtype=int32)
repeat 操作
# 复制数据
dataset = tf.data.Dataset.from_tensor_slices(input_data)
# 将数据扩展一倍
dataset = dataset.repeat(2)
for data in dataset:
print(data)
tf.Tensor(0, shape=(), dtype=int32)
tf.Tensor(1, shape=(), dtype=int32)
tf.Tensor(2, shape=(), dtype=int32)
tf.Tensor(3, shape=(), dtype=int32)
tf.Tensor(4, shape=(), dtype=int32)
tf.Tensor(5, shape=(), dtype=int32)
tf.Tensor(6, shape=(), dtype=int32)
tf.Tensor(7, shape=(), dtype=int32)
tf.Tensor(8, shape=(), dtype=int32)
tf.Tensor(9, shape=(), dtype=int32)
tf.Tensor(10, shape=(), dtype=int32)
tf.Tensor(11, shape=(), dtype=int32)
tf.Tensor(12, shape=(), dtype=int32)
tf.Tensor(13, shape=(), dtype=int32)
tf.Tensor(14, shape=(), dtype=int32)
tf.Tensor(15, shape=(), dtype=int32)
tf.Tensor(0, shape=(), dtype=int32)
tf.Tensor(1, shape=(), dtype=int32)
tf.Tensor(2, shape=(), dtype=int32)
tf.Tensor(3, shape=(), dtype=int32)
tf.Tensor(4, shape=(), dtype=int32)
tf.Tensor(5, shape=(), dtype=int32)
tf.Tensor(6, shape=(), dtype=int32)
tf.Tensor(7, shape=(), dtype=int32)
tf.Tensor(8, shape=(), dtype=int32)
tf.Tensor(9, shape=(), dtype=int32)
tf.Tensor(10, shape=(), dtype=int32)
tf.Tensor(11, shape=(), dtype=int32)
tf.Tensor(12, shape=(), dtype=int32)
tf.Tensor(13, shape=(), dtype=int32)
tf.Tensor(14, shape=(), dtype=int32)
tf.Tensor(15, shape=(), dtype=int32)
batch 操作
# 分区
dataset = tf.data.Dataset.from_tensor_slices(input_data)
# 16 * 2 / 4 = 8
dataset = dataset.repeat(2).batch(4)
for data in dataset:
print(data)
tf.Tensor([0 1 2 3], shape=(4,), dtype=int32)
tf.Tensor([4 5 6 7], shape=(4,), dtype=int32)
tf.Tensor([ 8 9 10 11], shape=(4,), dtype=int32)
tf.Tensor([12 13 14 15], shape=(4,), dtype=int32)
tf.Tensor([0 1 2 3], shape=(4,), dtype=int32)
tf.Tensor([4 5 6 7], shape=(4,), dtype=int32)
tf.Tensor([ 8 9 10 11], shape=(4,), dtype=int32)
tf.Tensor([12 13 14 15], shape=(4,), dtype=int32)
shuffle 操作
洗牌,打乱顺序。
buffer_size 构造缓存区,随机是在缓存区中取的。
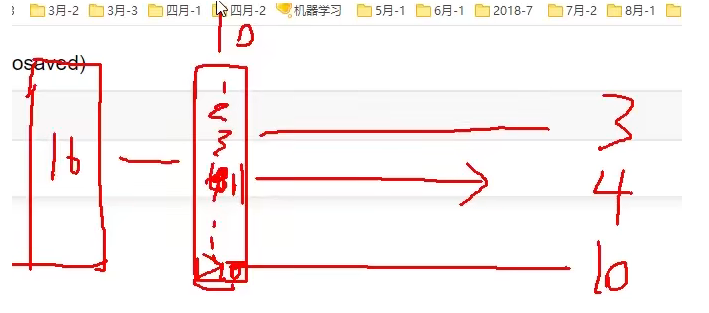
dataset = tf.data.Dataset.from_tensor_slices(input_data).shuffle(buffer_size=10).batch(4)
for data in dataset:
print(data)
tf.Tensor([ 1 9 4 11], shape=(4,), dtype=int32)
tf.Tensor([12 5 7 8], shape=(4,), dtype=int32)
tf.Tensor([ 3 0 6 13], shape=(4,), dtype=int32)
tf.Tensor([ 2 15 14 10], shape=(4,), dtype=int32)
重新训练
train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train = train.batch(32)
train = train.repeat()
valid = tf.data.Dataset.from_tensor_slices((x_valid, y_valid))
valid = valid.batch(32)
valid = valid.repeat()
model.fit(train, epochs=5, steps_per_epoch=100, validation_data=valid, validation_steps=100)
Epoch 1/5
100/100 [==============================] - 1s 6ms/step - loss: 0.1113 - sparse_categorical_accuracy: 0.9656 - val_loss: 0.1613 - val_sparse_categorical_accuracy: 0.9556
Epoch 2/5
100/100 [==============================] - 1s 6ms/step - loss: 0.1340 - sparse_categorical_accuracy: 0.9575 - val_loss: 0.2047 - val_sparse_categorical_accuracy: 0.9469
Epoch 3/5
100/100 [==============================] - 1s 6ms/step - loss: 0.1602 - sparse_categorical_accuracy: 0.9509 - val_loss: 0.1974 - val_sparse_categorical_accuracy: 0.9484
Epoch 4/5
100/100 [==============================] - 1s 5ms/step - loss: 0.1376 - sparse_categorical_accuracy: 0.9547 - val_loss: 0.1782 - val_sparse_categorical_accuracy: 0.9566
Epoch 5/5
100/100 [==============================] - 1s 5ms/step - loss: 0.1483 - sparse_categorical_accuracy: 0.9531 - val_loss: 0.1622 - val_sparse_categorical_accuracy: 0.9516
<keras.callbacks.History at 0x1f9d380e1f0>
练手的 fashion 数据集
from tensorflow import keras
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
train_images.shape
(60000, 28, 28)
len(train_labels)
60000
test_images.shape
(10000, 28, 28)
import matplotlib.pyplot as plt
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()

# 数据预处理,归一化
train_images = train_images / 255.0
test_images = test_images / 255.0
plt.figure(figsize=(10, 10))
for i in range(25):
plt.subplot(5, 5, i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()

# 第一个层将我们的数据做一个拉长,将三维数据拉成一个 784 的向量
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=10)
Epoch 1/10
1875/1875 [==============================] - 4s 2ms/step - loss: 0.1385 - accuracy: 0.9480
Epoch 2/10
1875/1875 [==============================] - 4s 2ms/step - loss: 0.1350 - accuracy: 0.9492
Epoch 3/10
1875/1875 [==============================] - 4s 2ms/step - loss: 0.1344 - accuracy: 0.9495
Epoch 4/10
1875/1875 [==============================] - 6s 3ms/step - loss: 0.1310 - accuracy: 0.9514
Epoch 5/10
1875/1875 [==============================] - 5s 3ms/step - loss: 0.1277 - accuracy: 0.9520
Epoch 6/10
1875/1875 [==============================] - 5s 3ms/step - loss: 0.1257 - accuracy: 0.9529
Epoch 7/10
1875/1875 [==============================] - 5s 2ms/step - loss: 0.1247 - accuracy: 0.9536
Epoch 8/10
1875/1875 [==============================] - 5s 2ms/step - loss: 0.1215 - accuracy: 0.9546
Epoch 9/10
1875/1875 [==============================] - 4s 2ms/step - loss: 0.1189 - accuracy: 0.9557
Epoch 10/10
1875/1875 [==============================] - 4s 2ms/step - loss: 0.1157 - accuracy: 0.9562
<keras.callbacks.History at 0x1f9d56b0c70>
评估操作
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
313/313 - 0s - loss: 0.4225 - accuracy: 0.8896 - 489ms/epoch - 2ms/step
Test accuracy: 0.8895999789237976
predictions = model.predict(test_images)
predictions.shape
# 得到10000个结果,每个结果对应10个分类的概率值
(10000, 10)
predictions[0]
array([4.0493273e-12, 3.5121753e-20, 3.0483979e-10, 1.6991046e-18,
1.4708566e-10, 2.4978764e-05, 2.4038651e-12, 1.4561019e-04,
1.0366391e-10, 9.9982941e-01], dtype=float32)
# 取最大的那一个数
np.argmax(predictions[0])
9
def plot_image(i, predictions_array, true_label, img):
predictions_array, true_label, img = predictions_array, true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{}{:2.0f}%({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
predictions_array, true_label = predictions_array, true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks()
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1, 2, 1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1, 2, 2)
plot_value_array(i, predictions[i], test_labels)
plt.show()

i = 12
plt.figure(figsize=(6, 3))
plt.subplot(1, 2, 1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1, 2, 2)
plot_value_array(i, predictions[i], test_labels)
plt.show()

保存训练好的模型
保存权重参数与网络模型
model.save('fashion_model.h5')
单独保存网络架构
config = model.to_json()
config
'{"class_name": "Sequential", "config": {"name": "sequential_1", "layers": [{"class_name": "InputLayer", "config": {"batch_input_shape": [null, 28, 28], "dtype": "float32", "sparse": false, "ragged": false, "name": "flatten_input"}}, {"class_name": "Flatten", "config": {"name": "flatten", "trainable": true, "batch_input_shape": [null, 28, 28], "dtype": "float32", "data_format": "channels_last"}}, {"class_name": "Dense", "config": {"name": "dense_3", "trainable": true, "dtype": "float32", "units": 128, "activation": "relu", "use_bias": true, "kernel_initializer": {"class_name": "GlorotUniform", "config": {"seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": null, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}}, {"class_name": "Dense", "config": {"name": "dense_4", "trainable": true, "dtype": "float32", "units": 10, "activation": "softmax", "use_bias": true, "kernel_initializer": {"class_name": "GlorotUniform", "config": {"seed": null}}, "bias_initializer": {"class_name": "Zeros", "config": {}}, "kernel_regularizer": null, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}}]}, "keras_version": "2.8.0", "backend": "tensorflow"}'
with open('config.json', 'w') as json:
json.write(config)
model = keras.models.model_from_json(config)
model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
dense_3 (Dense) (None, 128) 100480
dense_4 (Dense) (None, 10) 1290
=================================================================
Total params: 101,770
Trainable params: 101,770
Non-trainable params: 0
_________________________________________________________________
单独保存权重参数
weights = model.get_weights()
weights
[array([[-0.03163181, -0.03311502, -0.01678237, ..., 0.00484214,
0.00507489, 0.07994471],
[ 0.07406162, 0.03743618, -0.04003109, ..., -0.05603823,
0.04950785, -0.02904386],
[-0.03722822, -0.08018699, 0.04622041, ..., -0.02586809,
-0.05746298, 0.07074406],
...,
[-0.00759631, -0.08016491, 0.06419612, ..., -0.0620749 ,
-0.05708606, -0.07594812],
[-0.00171831, -0.04605167, 0.01561846, ..., 0.00809828,
0.01899965, -0.03814888],
[-0.07117902, -0.03221583, -0.08086707, ..., -0.04226859,
0.07105846, 0.07983869]], dtype=float32),
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0.], dtype=float32),
array([[-0.1327894 , 0.10800423, 0.08740102, ..., -0.19229129,
-0.19148389, -0.03068186],
[-0.05255331, 0.16116448, 0.19605024, ..., 0.14159529,
0.19689383, -0.06574619],
[ 0.0045159 , -0.14738384, 0.05060841, ..., -0.08603981,
0.15959124, -0.09571127],
...,
[ 0.2048781 , 0.02784759, -0.06796595, ..., -0.009524 ,
0.13251056, 0.01718692],
[ 0.09738623, 0.02646992, 0.0650634 , ..., 0.0030406 ,
0.18429981, -0.05338566],
[-0.02800542, 0.04104777, 0.03463137, ..., 0.16927035,
-0.11355665, 0.1305703 ]], dtype=float32),
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], dtype=float32)]
model.save_weights('weights.h5')
model.load_weights('weights.h5')
















 210
210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











