







1.1 简介
MobileNet v2是Google研究团队在2018年推出的一种高效、轻量级的卷积神经网络架构,它是MobileNet v1的升级版,主要目标是在保持高精度的同时减少模型大小和计算成本,特别适合在移动设备和资源受限的环境中运行。
该模型发表于《MobileNetV2: Inverted Residuals and Linear Bottlenecks》,下面我们看一下这篇论文的主要内容。
1.2 MobileNet V1的局限
1.没有残差连接。
2.很多Depth Wise卷积核训练出来是0。原因有三点:(1)卷积核权重数量和通道数太少太“单薄”
(2)Relu函数:它会把小于0的数都置为零,抹零之后就意味着他前向传播的这个张量为零,反向传播梯度也为0,那么它将永远陷在0这个地方。(3)低精度的浮点数表示
1.3 MobileNet V2的创新
相比于MobileNet V1,MobileNet V2引入了多项关键改进和新特性,使其在保持较小模型尺寸的同时,提高了模型的预测精度。MobileNet V2的主要特点:
-
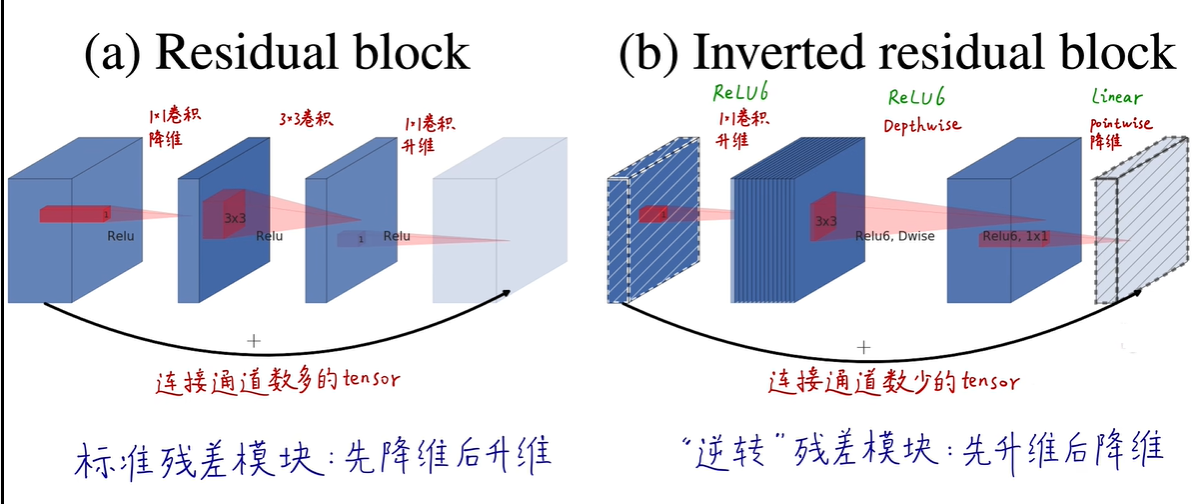
Inverted Residuals(逆残差结构):这是MobileNet V2最显著的改变之一。传统的残差块先降维再升维,而MobileNet V2中的逆残差结构则首先通过1x1的卷积层升维,然后应用深度可分离卷积处理特征,最后再通过1x1卷积降维。这种结构允许在网络的较宽部分进行更多的计算,提高了模型的表达能力。
-
Linear Bottlenecks(线性瓶颈):在逆残差模块的升维和降维之间,去除了非线性激活函数(如ReLU),只保留线性层。这有助于模型学习更丰富的特征表示,同时保持计算效率。
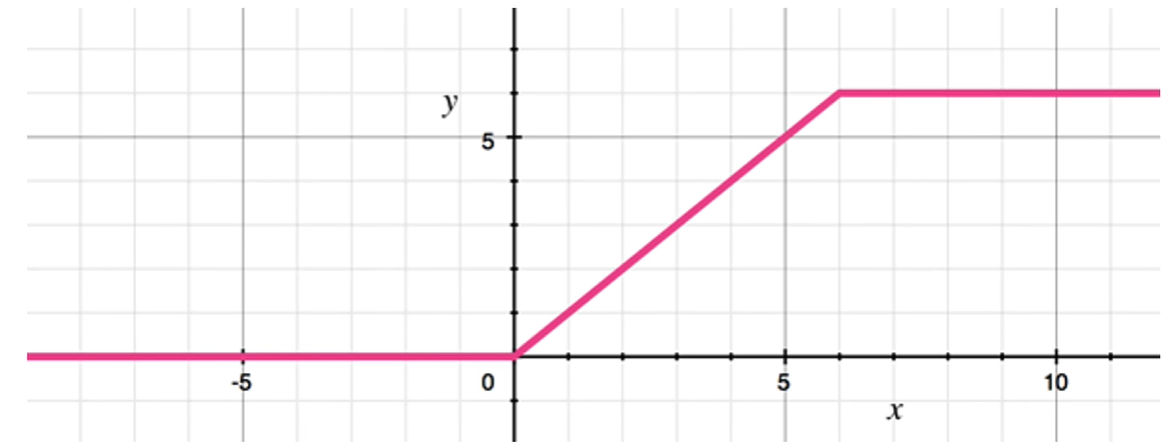
1.4 Relu6激活函数
ReLU6是ReLU(Rectified Linear Unit)函数的一种变体,其作用主要体现在以下几个方面:
-
区间限制:标准的ReLU函数定义为f(x)=max(0,x),即当输入 x 大于0时输出 x,否则输出0。而ReLU6则限制了输出的最大值为6,定义为f(x)=min(max(0,x),6)。这意味着无论输入 x 多么大,ReLU6的输出都不会超过6。这个上限可以帮助避免因ReLU激活的输出过大而导致的梯度爆炸问题,并且在某些情况下有助于模型的稳定训练。
-
量化友好:在移动端或嵌入式设备上,模型往往需要进行量化以降低计算和存储成本,即将浮点数转换为整数。ReLU6的输出范围限定在[0, 6]内,非常适合8位或更少位宽的整数表示,有利于量化过程,保持模型的精度。
-
硬件加速:特定的硬件加速器(如GPU、TPU)可以更高效地处理具有明确边界的操作,ReLU6的界限清晰,便于硬件直接实现并加速计算过程。
-
模型压缩与效率:在不牺牲太多模型表现的前提下,ReLU6通过限制输出范围,可以在一定程度上减少模型的复杂度,特别是在某些层可能不需要完整动态范围的情况下。
1.5 与其他网络的比较
与V1比较
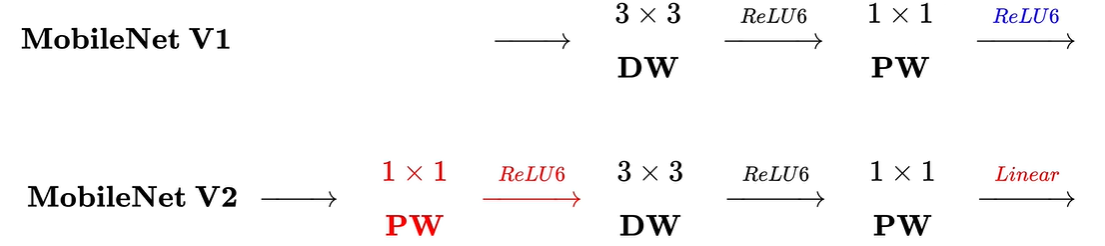
(左)V1与V2(右)的区别

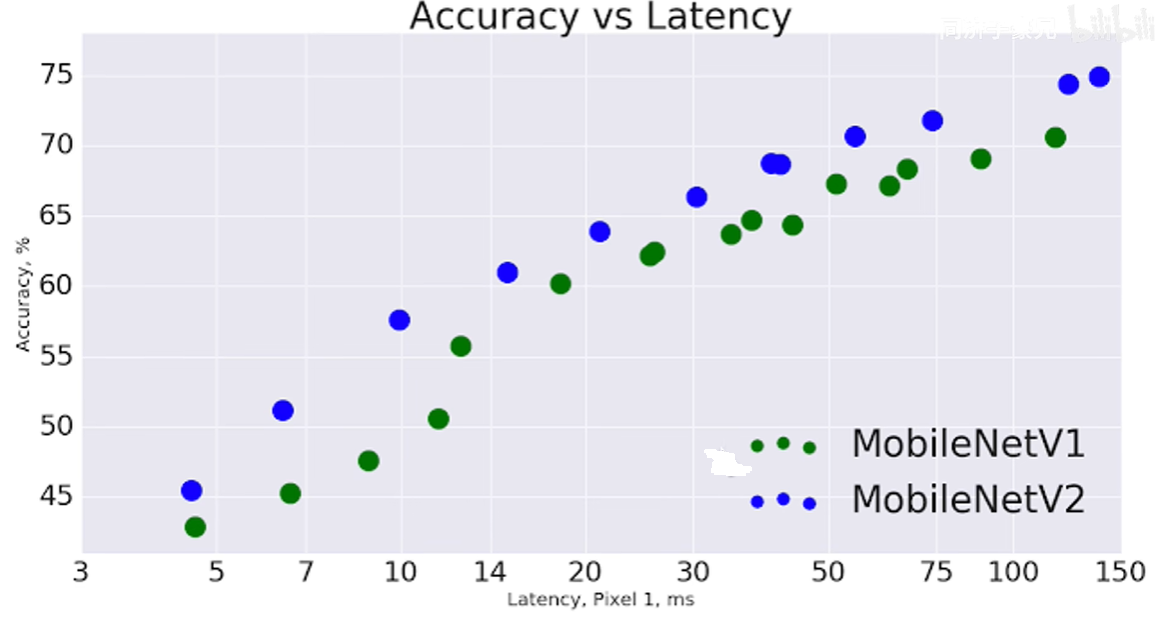
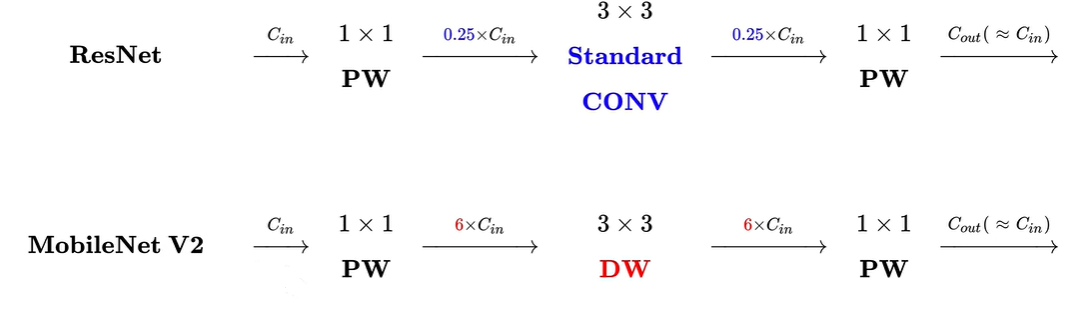
与Resnet的比较
Resnet是先降维后升维,而V2是先升维后降维
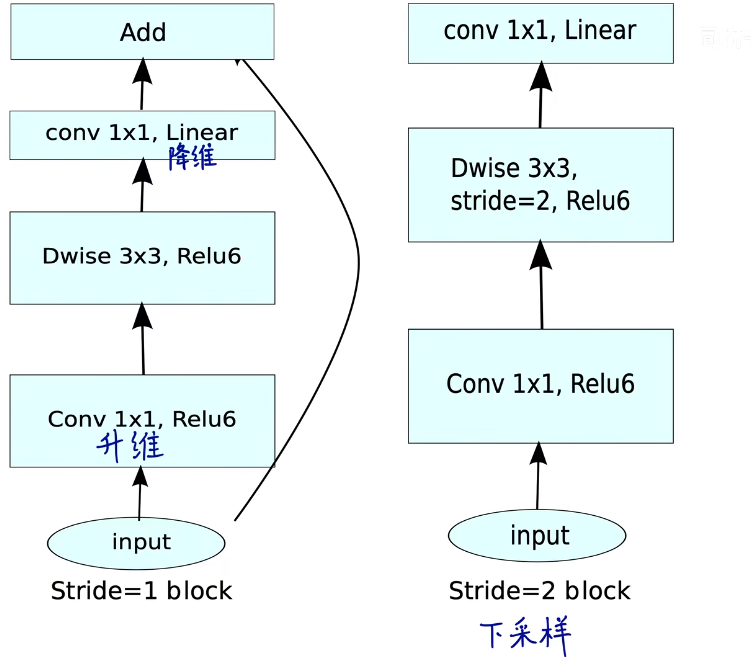
与其他网络的比较
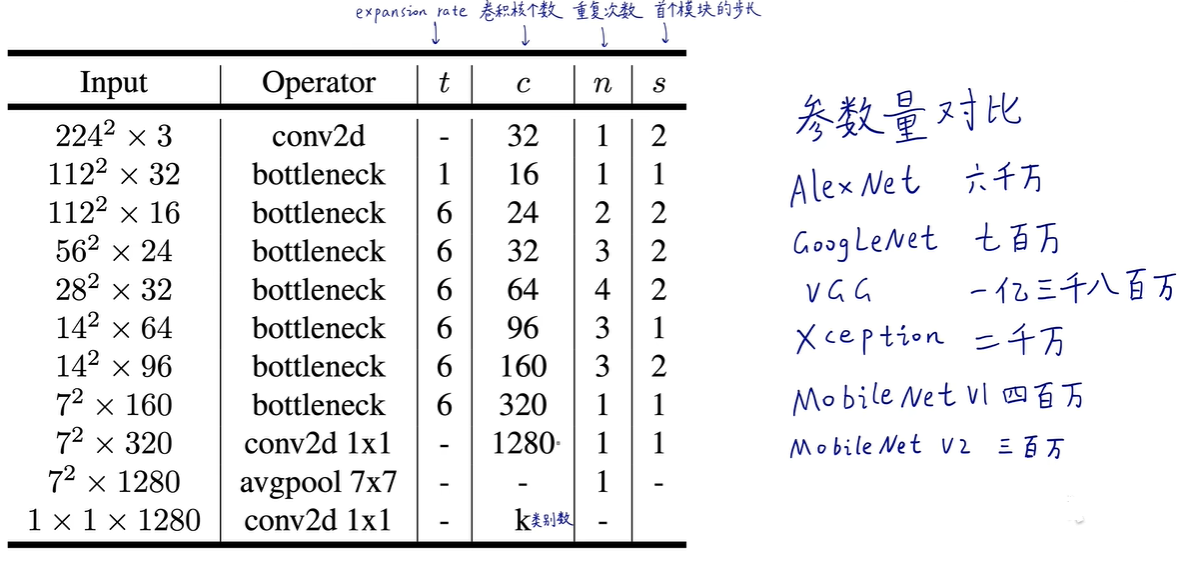
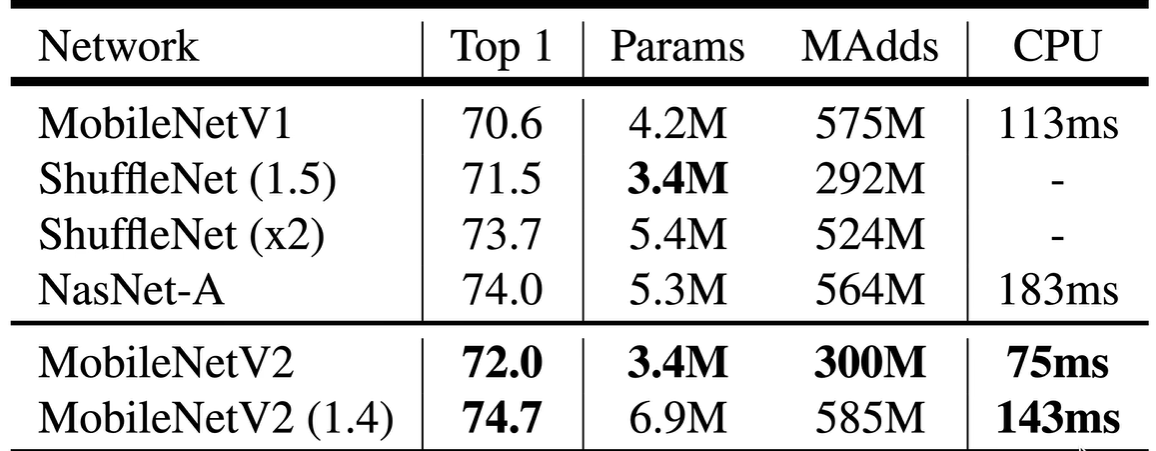
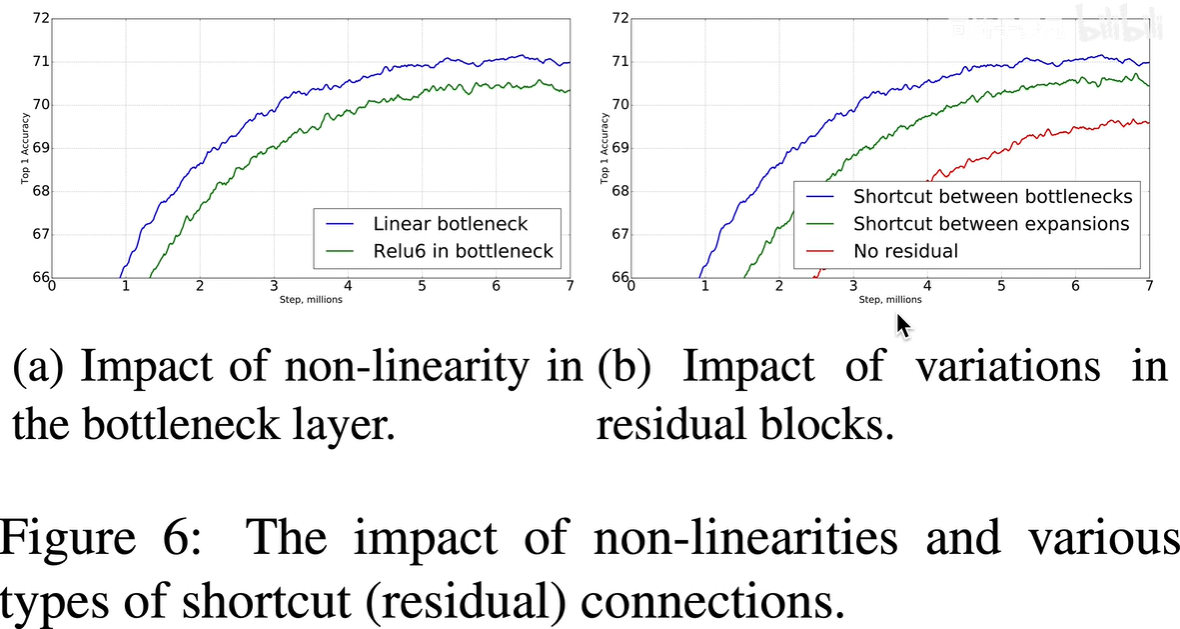
1.6 实验比较
1.是用线性激活函数还是用非线性(Relu6)激活函数?
2.残差连接是连接高维的expansions还是低维的bottlenecks?他们与不用残差块有什么性能差异?
1.7 invert升维的数学原理
如图所示,输入的数据是一个二维空间的螺旋线,在m非常小的情况下信息丢失很严重,如m=2,m=3等,只有在高维空间下大部分信息才会保留下来,也就是说,在低维空间下Relu会造成信息丢失。

我们也可以通过神经网络的模型来理解。
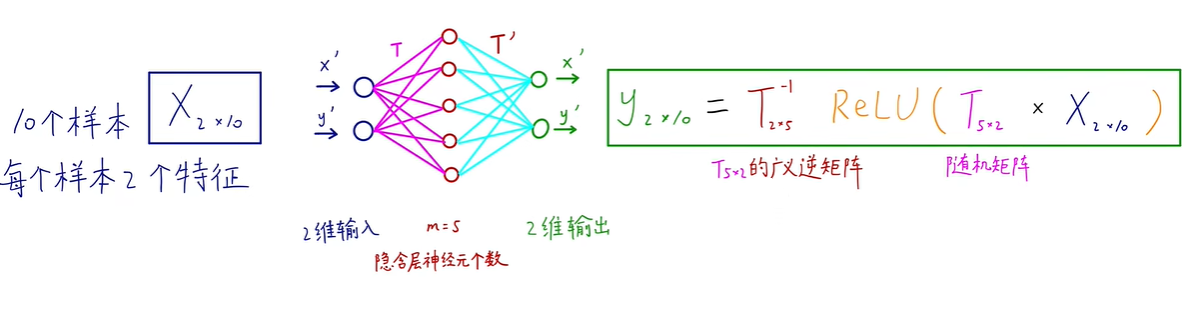
论文附录的引理的数学证明:
(当神经元的个数M远大于输入特征维数N,那么升维后容易保持可逆)

2.pytorch代码复现
# Author:SiZhen
# Create: 2024/5/31
# Description: pytorch实现mobilenetV2网络
import torch
import torch.nn as nn
import torchvision
#分类个数
num_class = 5
#DW卷积
def Conv3x3BNRelu(in_channels,out_channels,stride,groups):
return nn.Sequential(
# stride=2 ,wh减半,stride=1,wh不变
nn.Conv2d(in_channels=in_channels,out_channels=out_channels,
kernel_size=3,stride=stride,padding=1,groups=groups
),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True)
)
#PW卷积
def Conv1x1BNRelu(in_channels,out_channels):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels,out_channels=out_channels,
kernel_size=1,stride=1),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True)
)
#PW卷积(Linear),没有使用激活函数
def Conv1x1BN(in_channels,out_channels):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels,out_channels=out_channels,
kernel_size=1,stride=1),
nn.BatchNorm2d(out_channels)
)
#倒残差
class InvertedResidual(nn.Module):
# t = expansion_factor ,也就是扩展因子,论文中取6
def __init__(self,in_channels,out_channels,expansion_factor,stride):
super(InvertedResidual, self).__init__()
self.stride = stride
self.in_channels = in_channels
self.out_channels = out_channels
mid_channels = (in_channels*expansion_factor)
#先1x1卷积升维,再1x1卷积降维
self.bottleneck = nn.Sequential(
#升维:扩充维度是(in_channels*expansion_factor)
Conv1x1BNRelu(in_channels,mid_channels),
#DW卷积降低参数量
Conv3x3BNRelu(mid_channels,mid_channels,stride,groups=mid_channels),
#降维操作,将维度(in_channels*expansion_factor)降到指定out_channels维
Conv1x1BN(mid_channels,out_channels)
)
#第一种:stride=1,才有shortcut,此方法让原本不相同的channels相同
if self.stride==1:
self.shortcut = Conv1x1BN(in_channels,out_channels)
# 第二种: stride=1 且 in_channels=out_channels 才有 shortcut
# if self.stride == 1 and in_channels == out_channels:
# self.shortcut = ()
def forward(self,x):
out = self.bottleneck(x)
#第一种:
out = (out +self.shortcut(x)) if self.stride==1 else out
#第二种
#out = (out+x)if self.stride == 1 and self.in_channels == self.out_channels else out
return out
class MobileNetV2(nn.Module):
#num_class 为分类个数,t为扩充因子
def __init__(self,num_classes = num_class,t=6):
super(MobileNetV2, self).__init__()
# 3->32 groups=1 不是组卷积 只是单纯的卷积操作
self.first_conv = Conv3x3BNRelu(3,32,2,groups=1)
# 32->16 stride=1 wh不变
self.layer1 = self.make_layer(in_channels=32, out_channels=16, stride=1, factor=1, block_num=1)
# 16->24 stride=2 wh减半
self.layer2 = self.make_layer(in_channels=16, out_channels=24, stride=2, factor=t, block_num=2)
# 24->32 stride=2 wh减半
self.layer3 = self.make_layer(in_channels=24, out_channels=32, stride=2, factor=t, block_num=3)
# 32->64 stride=2 wh减半
self.layer4 = self.make_layer(in_channels=32, out_channels=64, stride=2, factor=t, block_num=4)
# 64->96 stride=1 wh不变
self.layer5 = self.make_layer(in_channels=64, out_channels=96, stride=1, factor=t, block_num=3)
# 96->160 stride=2 wh减半
self.layer6 = self.make_layer(in_channels=96, out_channels=160, stride=2, factor=t, block_num=3)
# 160->320 stride=1 wh不变
self.layer7 = self.make_layer(in_channels=160, out_channels=320, stride=1, factor=t, block_num=1)
# 320 -> 1280 单纯的升维操作
self.last_conv = Conv1x1BNRelu(320, 1280)
self.avgpool = nn.AvgPool2d(kernel_size=7,stride=1)
self.dropout = nn.Dropout(p=0.2)
self.linear = nn.Linear(in_features=1280,out_features=num_classes)
self.init_params()
def make_layer(self,in_channels,out_channels,stride,factor,block_num):
layers=[]
#与ResNet类似,每层bottleneck单独处理,指定stride,此层外的stride均为1
layers.append(InvertedResidual(in_channels,out_channels,factor,1))
#这些叠加层stride均为1,in_channels = out_channels,其中block_num-1为重复次数
for i in range(1,block_num):
layers.append(InvertedResidual(out_channels,out_channels,factor,1))
return nn.Sequential(*layers)
#初始化权重操作
def init_params(self):
for m in self.modules():
if isinstance(m,nn.Conv2d):
nn.init.kaiming_normal(m.weight)
nn.init.constant_(m.bias,0)
elif isinstance(m,nn.Linear) or isinstance(m,nn.BatchNorm2d):
nn.init.constant_(m.weight,1)
nn.init.constant_(m.bias,0)
def forward(self,x):
x = self.first_conv(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
x = self.layer6(x)
x = self.layer7(x)
x = self.last_conv(x)
x = self.avgpool(x)
x = x.view(x.size(0),-1)
x = self.dropout(x)
x = self.linear(x)
return x
if __name__=='__main__':
model = MobileNetV2()
model = torchvision.models.MobileNetV2()
input = torch.randn(1,3,224,224)
out = model(input)
print(out.shape)















 3697
3697

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









