







目录
一、随机森林定义
1、随机森林
随机森林属于集成学习里面Bagging模型的一种,关于什么是集成学习,什么是Bagging,我会单独在集成学习章节中详细讲解,因为我们刚学习过决策树算法,所以随机森林(Random Forest)和决策树(Decision Tree)之间的关系可以简单地理解为:随机森林是由多个决策树组成的集成学习模型。在随机森林中,每个决策树都是独立构建的,并且在构建过程中引入了随机性。最终,随机森林通过投票或平均的方式,将所有决策树的预测结果组合起来,得到最终的预测结果。
用公式表达这种关系,可以写为:
Random Forest
=
{
Decision Tree
1
,
Decision Tree
2
,
…
,
Decision Tree
n
}
\boxed{\text{Random Forest} = \{ \text{Decision Tree}_1, \text{Decision Tree}_2, \ldots, \text{Decision Tree}_n \}}
Random Forest={Decision Tree1,Decision Tree2,…,Decision Treen}
其中,
n
n
n是随机森林中决策树的数量。
由于训练数据存在一些差异,对决策树算法进行Bagging处理得到的多棵树高度相关,因此其带来的方差减少效果有限。
随机森林通过以下方式降低树的相关性:
- 随机选择一部分特征
- 随机选择一部分样本
随机森林在很多应用案例上被证明是有效的,但牺牲了模型的可解释性。
- 森林:由多棵树组成
- 随机:对样本和特征进行随机抽取
2、Bagging在随机森林中起的作用
在随机森林中,Bagging(Bootstrap Aggregating)是一种集成学习方法,用于提高模型的稳定性和准确性。Bagging通过构建多个模型(通常是决策树),然后将它们的预测结果进行汇总来工作。下面是Bagging在随机森林中的具体应用步骤:
-
自助采样(Bootstrap Sampling):
- 从原始训练数据集中随机抽取样本,允许重复抽样,形成一个新的训练数据集。这个过程称为自助采样(Bootstrap Sampling),因为每个样本被选中的概率是相同的,并且可以被多次选中。
- 由于是随机抽取,新数据集的大小通常与原始数据集相同,但内容可能有所不同。
-
构建决策树:
- 使用自助采样得到的数据集来构建决策树。在随机森林中,每棵树都是在不同的数据集上训练的,因此它们之间是相互独立的。
- 在构建每棵树的过程中,还会引入额外的随机性,即在每个决策节点,不是使用所有特征,而是随机选择一部分特征进行分裂。
-
汇总预测结果:
- 对于分类问题,通常采用投票机制,即每棵树给出一个预测结果,最终的预测结果是得票最多的类别。
- 对于回归问题,通常采用平均值,即每棵树给出一个预测值,最终的预测结果是所有树预测值的平均。
-
降低方差:
- 由于每棵树都是在不同的数据集上训练的,它们的错误往往是不同的,这样可以通过投票或平均来减少整体的方差。
- 随机森林通过引入随机性,减少了模型对特定数据集的依赖,从而降低了过拟合的风险。
-
提高模型的泛化能力:
- 随机森林通过集成多个决策树,提高了模型的泛化能力,使得模型在面对新的、未见过的数据时,能够给出更稳定和准确的预测。
总的来说,Bagging在随机森林中的应用,通过构建多个基于不同数据集和特征子集的决策树,并将它们的预测结果进行汇总,从而提高了模型的稳定性和准确性,同时降低了过拟合的风险。
3、随机森林中的采样技术
随机森林中的采样主要指的是在构建每棵决策树时对训练数据进行的随机抽样过程。这种采样方法称为自助采样(Bootstrap Sampling),是Bagging(Bootstrap Aggregating)集成学习算法的关键组成部分。以下是随机森林中采样过程的详细解释:
1)自助采样(Bootstrap Sampling)
在随机森林中,每棵决策树的训练数据都是通过自助采样从原始训练数据集中获得的。具体步骤如下:
- 从原始训练数据集中有放回地随机抽取样本,即允许同一个样本在新的训练数据集中出现多次,同时也允许某些样本不被选中。
- 通常,自助采样得到的新数据集与原始数据集的大小相同,但由于是随机抽取,新数据集中的样本分布可能会有所不同。
- 每棵决策树都是使用不同的自助采样数据集进行训练的,这意味着每棵树可能会看到不同的样本。
2)特征采样
除了对样本进行自助采样外,随机森林还在构建每棵决策树的过程中对特征进行随机抽样:
- 在每个决策节点,随机森林不是考虑所有特征来寻找最佳分割点,而是从所有特征中随机选择一部分特征。
- 具体来说,如果原始数据集有( m )个特征,随机森林可以随机选择( \sqrt{m} )(对于分类问题)或( m/3 )(对于回归问题)个特征进行考虑。
- 这种方法可以减少树之间的相关性,提高模型的多样性和泛化能力。
3)采样的优点
- 减少过拟合:通过自助采样和特征采样,随机森林能够减少单棵决策树的过拟合风险,因为每棵树都是在不同的数据和特征子集上训练的。
- 提高泛化能力:随机森林通过集成多棵在不同数据和特征子集上训练的决策树,提高了模型对新数据的泛化能力。
- 增强模型稳定性:由于每棵树的预测结果可能会有所不同,随机森林通过投票或平均的方式汇总这些预测结果,从而增强了模型的稳定性。
4)采样的实现
在Scikit-Learn库中,随机森林的采样可以通过RandomForestClassifier或RandomForestRegressor类的bootstrap参数来控制。默认情况下,bootstrap=True,表示启用自助采样。特征采样的数量可以通过max_features参数来设置。
from sklearn.ensemble import RandomForestClassifier
# 创建随机森林分类器,启用自助采样,设置特征采样数量
rf_classifier = RandomForestClassifier(n_estimators=100, bootstrap=True, max_features='sqrt', random_state=42)
通过这种方式,随机森林能够有效地利用采样技术来提高模型的性能和稳定性。
4、Scikit-Learn中的随机森林
Scikit-Learn实现了两种包含随机树的森林模型:
-
随机森林(Random Forests)
-
极度随机森林(Extremely Randomized Trees)
极度随机森林在构建模型时引入了更多的随机性:
- 在进行分裂时,随机森林会寻找特征中最具判别力的阈值。
- 而在极度随机森林中,会随机选取每个候选特征的多个阈值,然后从这些随机选取的阈值中寻找最佳阈值。这个过程在每个节点上找到每个特征的最佳阈值,是决策树生长中最耗时的任务。
- 极度随机森林在减少方差方面的效果可能会更好一些,但可能会稍微增加一点偏差。
5、随机森林超参数调优
随机森林模型的参数众多,并且涉及到随机操作。在分类任务中,当不同类别的样本数目不均衡时,进行超参数调优需要格外慎重。
一般来说,调优过程应该先从包含随机性的参数开始:
- 先初步调整“子采样率”( s u b s a m p l e subsample subsample)和“分裂时考虑的最大特征数”( m a x _ f e a t u r e s max\_features max_features)。
- 然后调整叶节点最小样本数( m i n _ s a m p l e s _ l e a f min\_samples\_leaf min_samples_leaf)和“分裂所需最小样本数”( m i n _ s a m p l e s _ s p l i t min\_samples\_split min_samples_split)。
接下来,再调整那些不含随机性的参数:
- “最大深度”( m a x _ d e p t h max\_depth max_depth)或“最大叶节点数”( m a x _ l e a f _ n o d e s max\_leaf\_nodes max_leaf_nodes)。
6、推荐阅读
二、随机森林实践
因为本章节理论部分内容不多,主要是作为决策树算法的一个补充,其他关于集成学习的详细内容会在单独章节讲解。下面为了丰富本章内容,将代码实战环节作为补充。
1、导入函数库
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
2、读取数据
(*此数的数据与决策树案例分析使用的是同一数据)
# 加载数据
data = pd.read_csv('iris.csv')
# 查看数据的前几行
data.head()
3、特征抽取
# 分离特征和标签
X = data.drop('variety', axis=1)
y = data['variety']
# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
4、模型建立
# 创建随机森林分类器
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
5、模型训练
# 训练模型
rf_classifier.fit(X_train, y_train)
6、测试模型
# 在测试集上进行预测
y_pred = rf_classifier.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}')
# 输出分类报告
report = classification_report(y_test, y_pred)
print('Classification Report:\n', report)
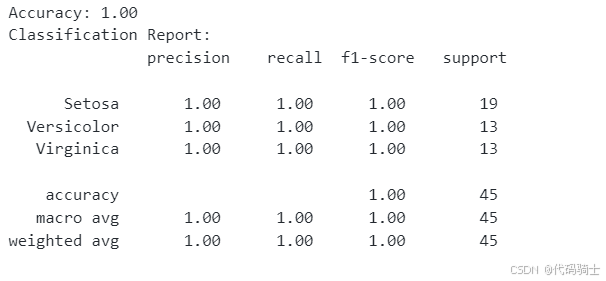
显然,模型存在过拟合。
7、模型调优
1)限制树的深度
from sklearn.ensemble import RandomForestClassifier
# 创建随机森林分类器,限制树的最大深度
rf_classifier = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=42)
# 训练模型
rf_classifier.fit(X_train, y_train)
# 评估模型
print(f'Accuracy on training set: {rf_classifier.score(X_train, y_train):.2f}')
print(f'Accuracy on test set: {rf_classifier.score(X_test, y_test):.2f}')
2)限制叶结点数
from sklearn.ensemble import RandomForestClassifier
# 创建随机森林分类器,增加叶节点最小样本数
rf_classifier = RandomForestClassifier(n_estimators=100, min_samples_leaf=5, random_state=42)
# 训练模型
rf_classifier.fit(X_train, y_train)
# 评估模型
print(f'Accuracy on training set: {rf_classifier.score(X_train, y_train):.2f}')
print(f'Accuracy on test set: {rf_classifier.score(X_test, y_test):.2f}')
3)使用交叉验证与网格寻参
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
# 定义模型参数范围
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [None, 5, 10],
'min_samples_leaf': [1, 5, 10]
}
# 创建随机森林分类器
rf_classifier = RandomForestClassifier(random_state=42)
# 使用网格搜索和交叉验证来选择最佳参数
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(estimator=rf_classifier, param_grid=param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
# 输出最佳参数和对应的准确率
print(f'Best parameters: {grid_search.best_params_}')
print(f'Best cross-validation accuracy: {grid_search.best_score_:.2f}')
# 使用最佳参数训练模型
best_rf_classifier = grid_search.best_estimator_
# 评估模型
print(f'Accuracy on training set: {best_rf_classifier.score(X_train, y_train):.2f}')
print(f'Accuracy on test set: {best_rf_classifier.score(X_test, y_test):.2f}')
8、模型可视化
1)显示重要特征
# 获取特征重要性
importances = rf.feature_importances_
# 可视化特征重要性
indices = np.argsort(importances)[::-1]
plt.title('Feature Importances')
plt.bar(range(X_train.shape[1]), importances[indices], color='lightblue', align='center')
plt.xticks(range(X_train.shape[1]), X.columns[indices], rotation=90)
plt.xlim([-1, X_train.shape[1]])
plt.show()
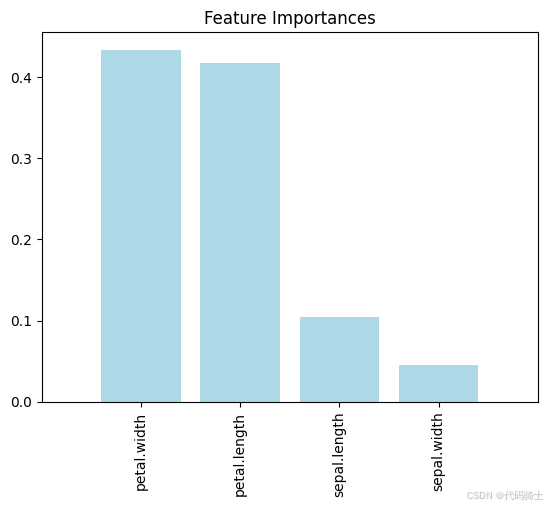
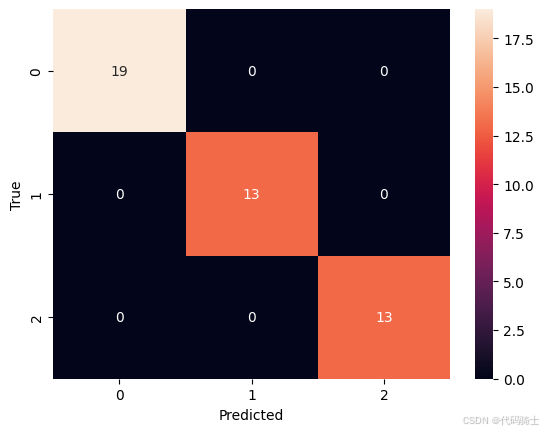
2)显示混淆矩阵
from sklearn.metrics import confusion_matrix
import seaborn as sns
# 预测测试集
y_pred = rf.predict(X_test)
# 计算混淆矩阵
cm = confusion_matrix(y_test, y_pred)
# 可视化混淆矩阵
sns.heatmap(cm, annot=True, fmt='d')
plt.xlabel('Predicted')
plt.ylabel('True')
plt.show()
3)绘制ROC、AUC曲线
from sklearn.metrics import roc_curve, auc, roc_auc_score
import matplotlib.pyplot as plt
from sklearn.preprocessing import label_binarize
# 假设你已经有了训练好的随机森林分类器 rf_classifier 和测试数据 X_test
# 使用测试集进行预测,获取预测概率
y_score = rf_classifier.predict_proba(X_test)
# 将标签二值化
y_test_bin = label_binarize(y_test, classes=['Setosa', 'Versicolor', 'Virginica'])
# 计算每个类别的ROC曲线和AUC
n_classes = y_test_bin.shape[1]
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test_bin[:, i], y_score[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# 绘制所有类别的ROC曲线
plt.figure(figsize=(10, 8))
for i in range(n_classes):
plt.plot(fpr[i], tpr[i], label=f'Class {i} ROC curve (area = {roc_auc[i]:.2f})')
plt.plot([0, 1], [0, 1], 'k--', lw=2)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic for multi-class')
plt.legend(loc="lower right")
plt.show()
# 计算微平均和宏平均ROC AUC
micro_auc = roc_auc_score(y_test_bin, y_score, multi_class='ovo', average='micro')
macro_auc = roc_auc_score(y_test_bin, y_score, multi_class='ovo', average='macro')
print(f'Micro-average ROC AUC: {micro_auc:.2f}')
print(f'Macro-average ROC AUC: {macro_auc:.2f}')
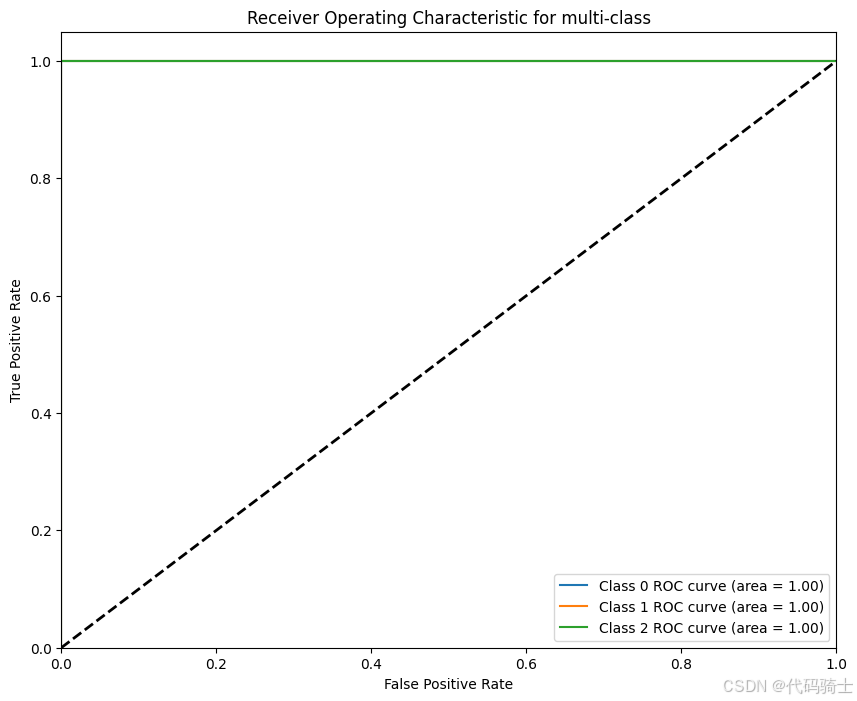
根据模型可视化的结果显示,无论是混淆矩阵还是ROC曲线的结果,都说明
- 模型在训练集上的表现非常好:所有类别的样本都被完全正确分类,没有出现任何误分类的情况。
- 模型的分类性能非常强:AUC值为1.00,表示模型在所有类别上的分类性能都是完美的。
但是,需要注意的是,虽然模型在训练集上的表现非常好,但这并不一定意味着模型在测试集或实际应用中也会有同样的表现。因为本次实验的数据集只有150条数据,所以这极大增加了模型过拟合的风险,随机森林适合更大规模的数据,后面我会举出更加严谨可靠的实例供大家参考学习。


















 1465
1465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











