







详解pytorch实现猫狗识别98%附代码
前言
前段时间间做了猫狗识别的项目,采用的是pytorch这个框架,准确率达到了98%,其中对于神经网络 构建也采用了很多种方式,采用过迁移学习使用resnet50、resnet18、vgg16和vgg19,也尝试过自己构建神经网络(自己构建的准确率比较低,但是目的在于熟悉图片维度的计算)
一、为什么选用pytorch这个框架?
首先我们要知道深度学习常用的几个框架有哪些,例如:TensorFlow、Keras、Pytorch等。
TensorFlow:这个框架是目前非常常用的
- 优点:适合在大范围内进行操作,尤其是对于跨台或者是在实现嵌入式部署的时候更具优势
- 缺点:静态框架计算的流程处于固定状态,不灵活的运算方式会导致在结算结果上效率比较低下
Keras:封装的比较好,容易上手,相对简单点
- 优点:极简,只需几行代码就能构建一个神经网络(对TensorFlow进行封装,相当于一个api)
- 缺点:速度慢
Pytorch:
- 优点:是一个动态的框架,在运算过程中,会根据不同的数值,按照最优方式进行合理安排
- 缺点:在短时间内建立结果和方案更适合于计算机程序爱好者或者是小规模项目
二、实现效果
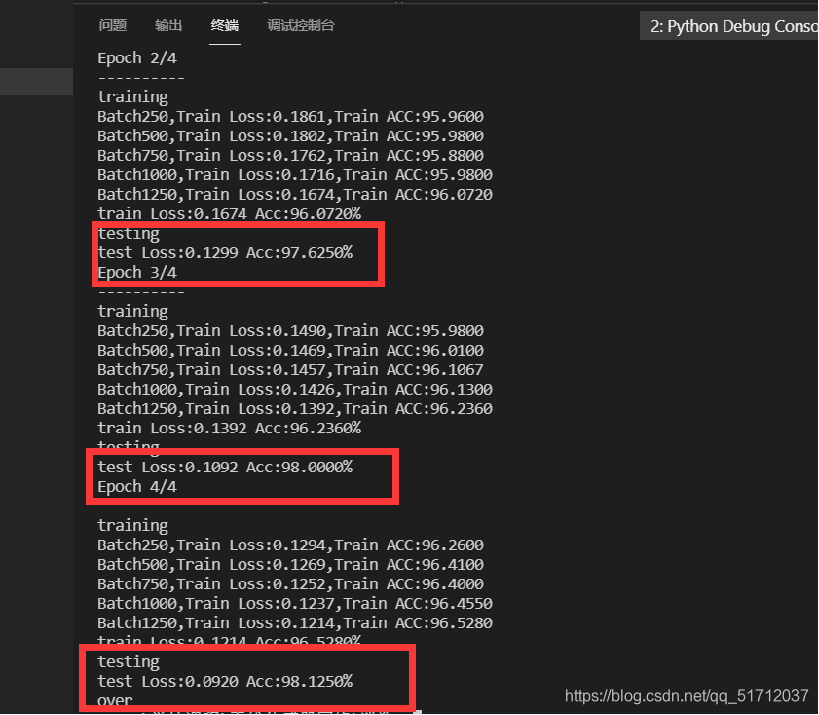
1.下面采用resnet50损失值和准确率,准确率在97%以上
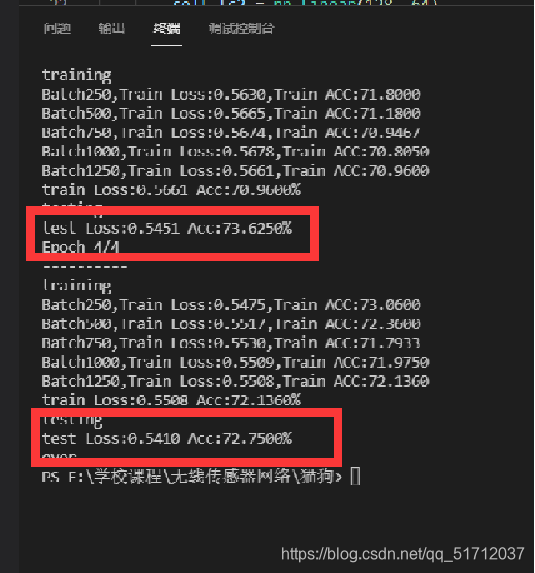
2.自定义的神经网络准确率及损失值,由于自己写神经网络的目的在于了解神经网络的处理一张图片的计算流程 ,所以没太去深究提高准确率
三、神经网络从头到尾
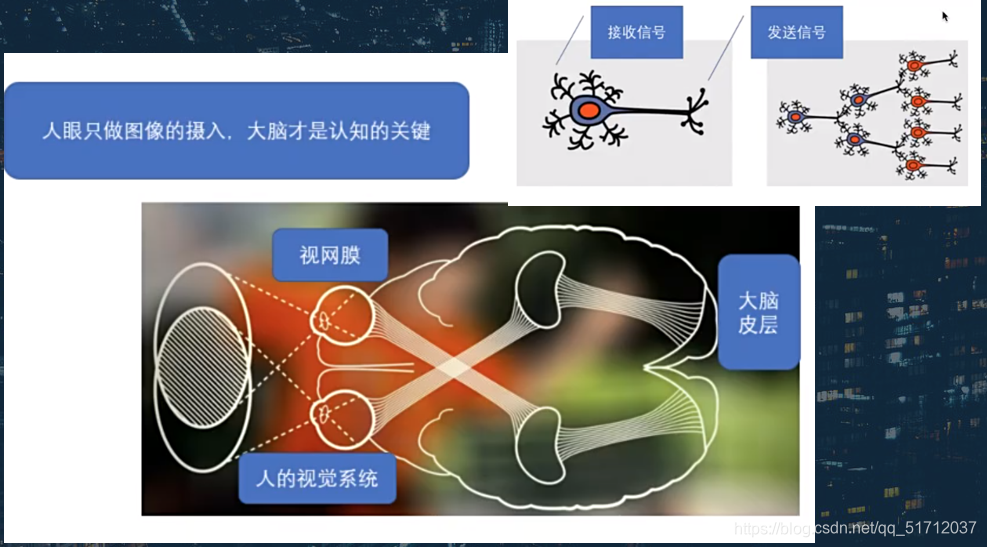
1.来源:仿照人为处理图片的流程,模拟人们的神经元处理信息的方式
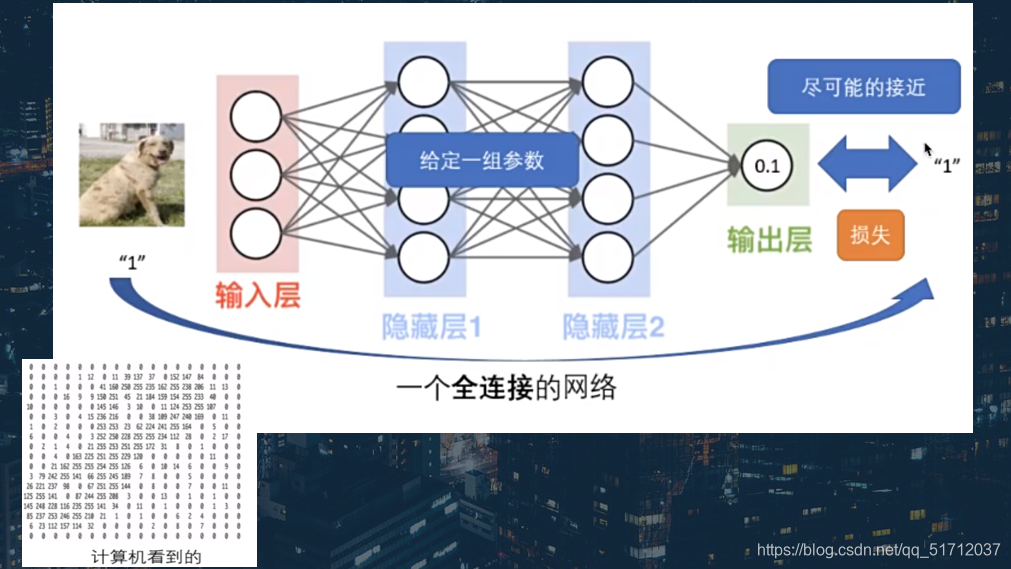
2.总览神经网络
下面这张更容易理解一点,计算机看到的一张图片是如下图右下角的图片,整体流程中包含输入层、隐藏层和输出层,中间的圈相当于人脑中的神经元
更加详细的一个卷积神经网络的处理过程,包括卷积层、池化层和全连接层
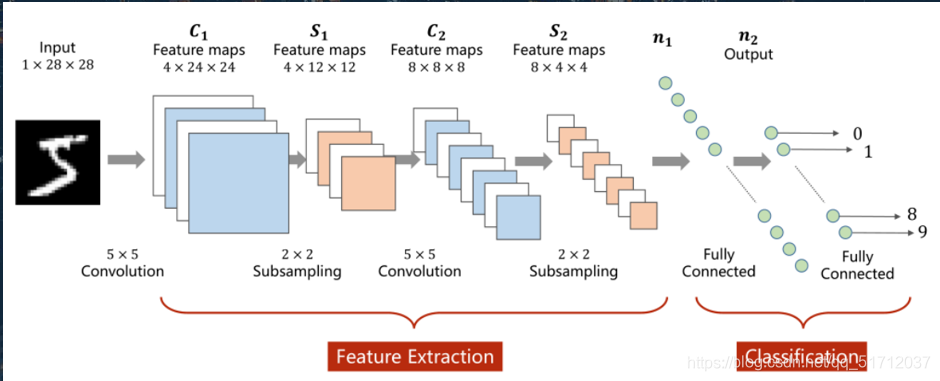
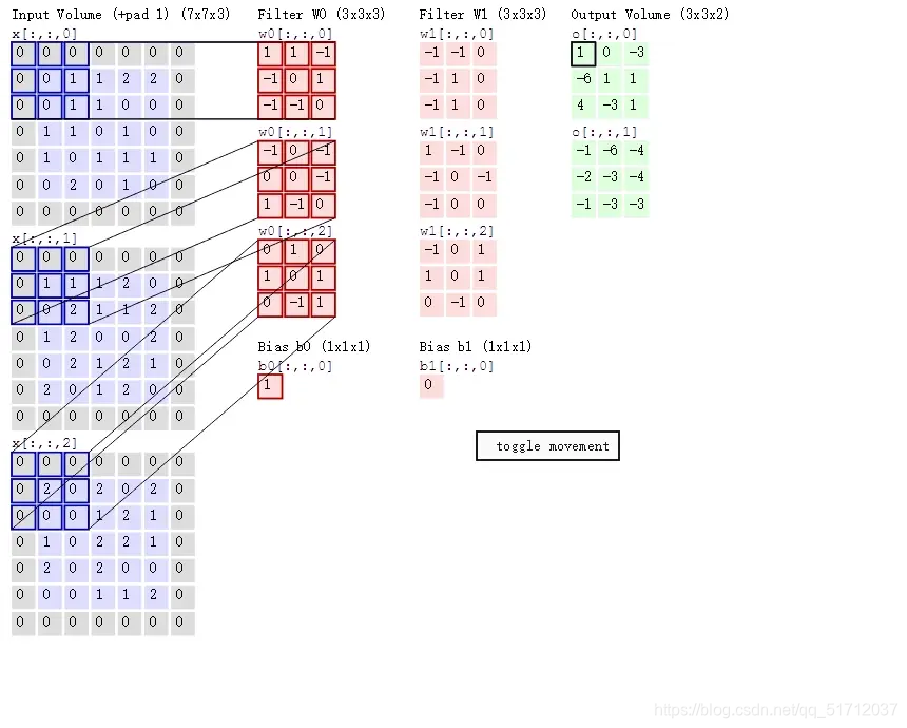
3.卷积层(Convolution)
卷积层的作用是对输入的数据做特征提取,而完成该功能的是卷积核,如图为卷积核如何在卷积层进行运算(下图也是在网上经常见到的,备注:引用的图片)
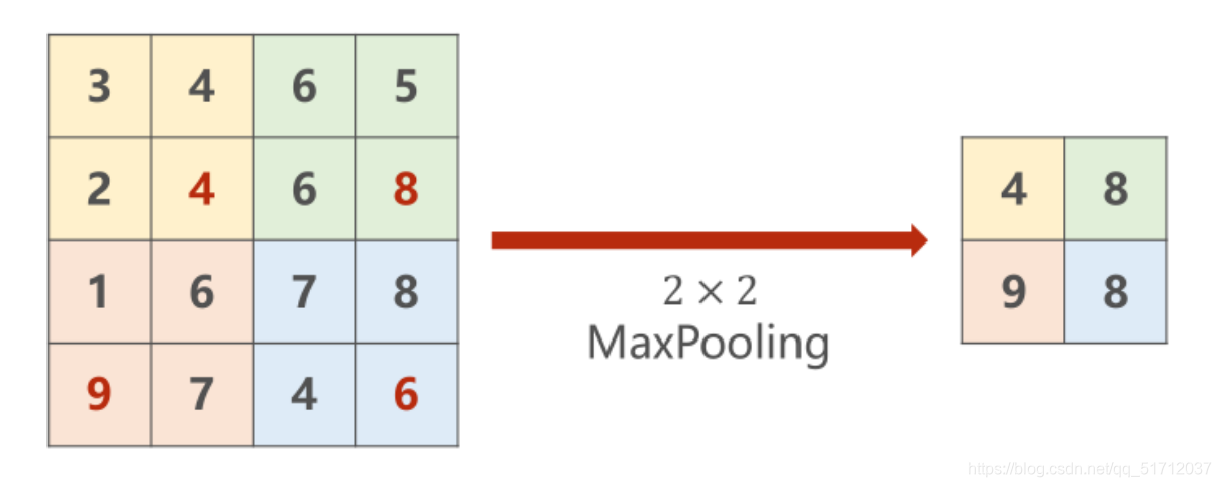
4.池化层(Subsmpling)
池化层一般对数据进行进一步的特征提取,不仅实现对数据的压缩,还大量减少了参与模型计算的参数,从某种意义上讲,提升了计算效率,池化的方式有取最大、取最小以及取平均值
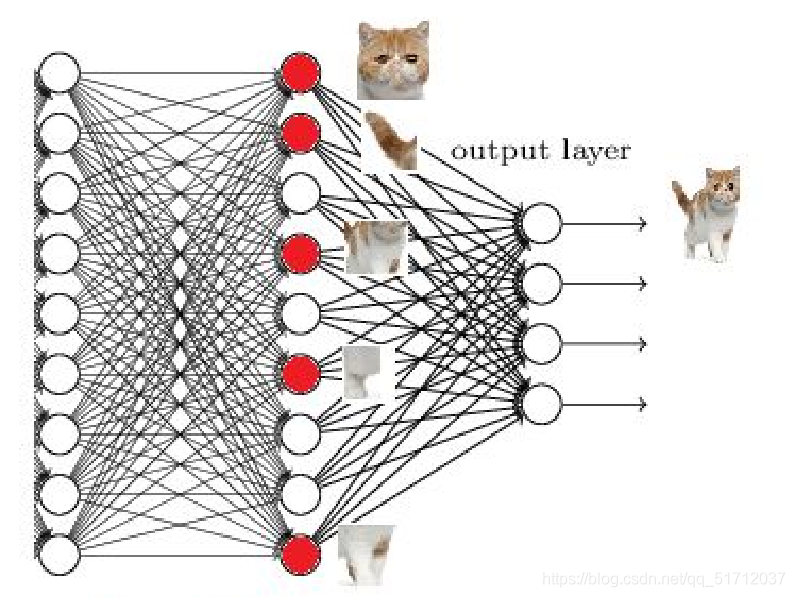
5.全连接层(Fully Connected)
全连接层主要作用是将输入的图像在经过卷积核池化操作后提取的特征进行压缩,并根据压缩的特征完成模型的分类功能。
四、项目架构
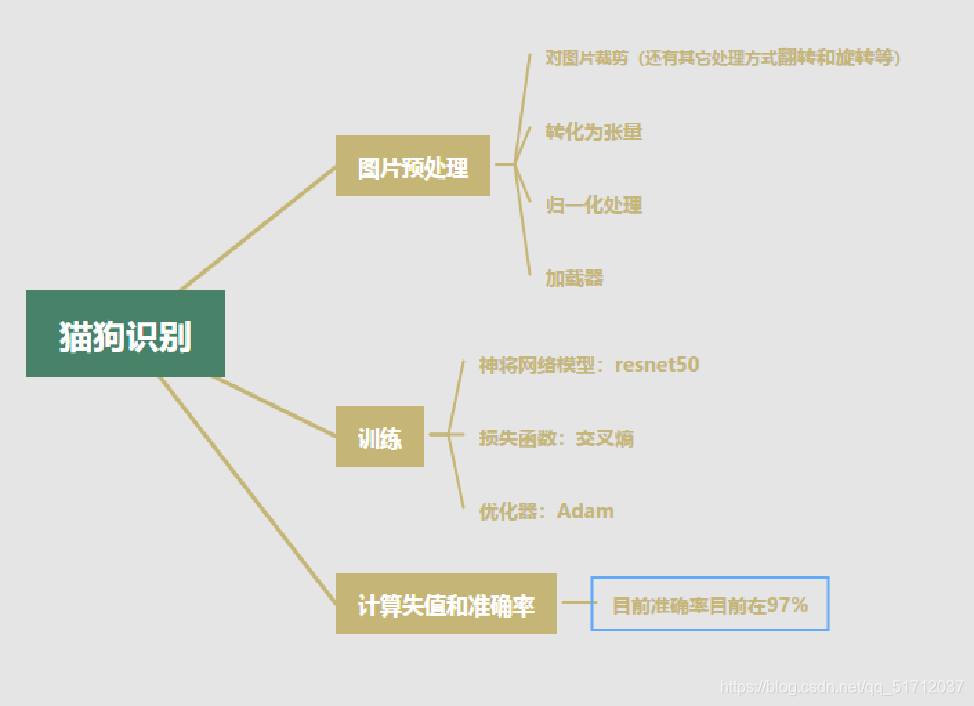
下面是我画的一个项目的思维导图,看图完全就可以看懂整个项目的流程,就不多用文字介绍了
五、代码实现
下面是采用迁移学习resnet50实现的代码,用vgg16以及其它的网络模型的时候只需要更换网络模型即可,注释掉的class类是自定义的神经网络,想要学习流程的话可以看看,代码后面有注释
import torch
import torchvision
from torchvision import datasets,models,transforms
import os
from torch.autograd import Variable
import torch.nn as nn
import torch.utils.data
import torch.nn.functional as F
#from network import Net
# class Net(nn.Module): # 新建一个网络类,就是需要搭建的网络,必须继承PyTorch的nn.Module父类
# def __init__(self): # 构造函数,用于设定网络层
# super(Net, self).__init__() # 标准语句
# self.conv1 = torch.nn.Conv2d(3, 16, 3, padding=1) # 第一个卷积层,输入通道数3,输出通道数16,卷积核大小3×3,padding大小1,其他参数默认
# self.conv2 = torch.nn.Conv2d(16, 16, 3, padding=1)
# self.fc1 = nn.Linear(56*56*16, 128) # 第一个全连层,线性连接,输入节点数50×50×16,输出节点数128
# self.fc2 = nn.Linear(128, 64)
# self.fc3 = nn.Linear(64, 2)
# def forward(self, x): # 重写父类forward方法,即前向计算,通过该方法获取网络输入数据后的输出值
# x = self.conv1(x)
# x = F.relu(x)
# x = F.max_pool2d(x, 2)
# x = self.conv2(x)
# x = F.relu(x)
# x = F.max_pool2d(x, 2)
# x = x.view(x.size()[0], -1)
# x = F.relu(self.fc1(x))
# x = F.relu(self.fc2(x))
# y = self.fc3(x)
# return y
data_dir = "F:/猫狗识别二/DogsVSCats"
#图片处理
data_trainsforms = {
"train":transforms.Compose([
#transforms.RandomResizedCrop(300),
transforms.Resize((224,224)),
#transforms.RandomCrop((224,224)),
#transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]),
# transforms.ToTensor()
]),
"test":transforms.Compose([
#transforms.RandomResizedCrop(300),
#transforms.RandomHorizontalFlip(),
transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]),
]),}
#拼接路径
image_datasets = {
x:datasets.ImageFolder(root=os.path.join(data_dir, x),
transform=data_trainsforms[x])
for x in ["train", "test"]
}
#数据加载器
data_loader = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=20, shuffle=True) for x in ["train", "test"] }
X_example,y_example = next(iter(data_loader["train"]))
example_classees = image_datasets["train"].classes
index_classes = image_datasets["train"].class_to_idx
#迁移学习模型
model = models.resnet50(pretrained = True)
#自定义模型
#model = Net()
Use_gpu = torch.cuda.is_available()
for parma in model.parameters():
parma.requires_grad = False#屏蔽预训练模型的权重,只训练最后一层的全连接的权重
model.fc = torch.nn.Linear(2048,2)
# print(model)
if Use_gpu:
model = model.cuda()
#损失函数和优化器
loss_f = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.fc.parameters(),lr = 0.00001)
#optimizer = torch.optim.Adam(model.parameters(),lr = 0.00001)
epoch_n = 5
for epoch in range(epoch_n):
print("Epoch {}/{}".format(epoch,epoch_n - 1))
print("-"*10)
for phase in ["train","test"]:
if phase == "train":
print("training")
model.train(True)
else:
print("testing")
model.train(False)
running_loss = 0.0
running_corrects = 0
for batch,data in enumerate(data_loader[phase],1):
X,y = data
if Use_gpu:
X,y = Variable(X.cuda()),Variable(y.cuda())
else:
X,y = Variable(X),Variable(y)
y_pred = model(X)
_,pred = torch.max(y_pred.data,1)
optimizer.zero_grad()
loss = loss_f(y_pred,y)
if phase == "train":
loss.backward()#反向传播计算当前梯度# 误差反向传播,采用求导的方式,计算网络中每个节点参数的梯度,显然梯度越大说明参数设置不合理,需要调整
optimizer.step()#优化采用设定的优化方法对网络中的各个参数进行调整
running_loss += loss.item()
running_corrects += torch.sum(pred == y.data)
if batch%250 == 0 and phase == "train":
print("Batch{},Train Loss:{:.4f},Train ACC:{:.4f}".format(batch,running_loss/batch,100*running_corrects/(20*batch)))
epoch_loss = running_loss*20/len(image_datasets[phase])
epoch_acc = 100*running_corrects/len(image_datasets[phase])
print("{} Loss:{:.4f} Acc:{:.4f}%".format(phase,epoch_loss,epoch_acc))
#torch.save(model.state_dict(),'model.ckpt1')
# torch.save(model.state_dict(),'model.pth'
print("over")
六、数据集
数据集采用两万五千张图片,来源于kaggle官网。先测试代码的话可以先用我上传在资源里面的测试集把它分一部分作为训练集就好,训练集太大不好上传。
总结
猫狗识别对于深度学习来说是入门级的教程,但是对于新手真的很有必要完全弄懂这个例子,通过代码去回顾一些基本知识,例如权重、损失函数、数据加载器等一些基本知识和其对最后的准确率的影响。

















 2224
2224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









