







第一部分 --- 哈夫曼树的基本概念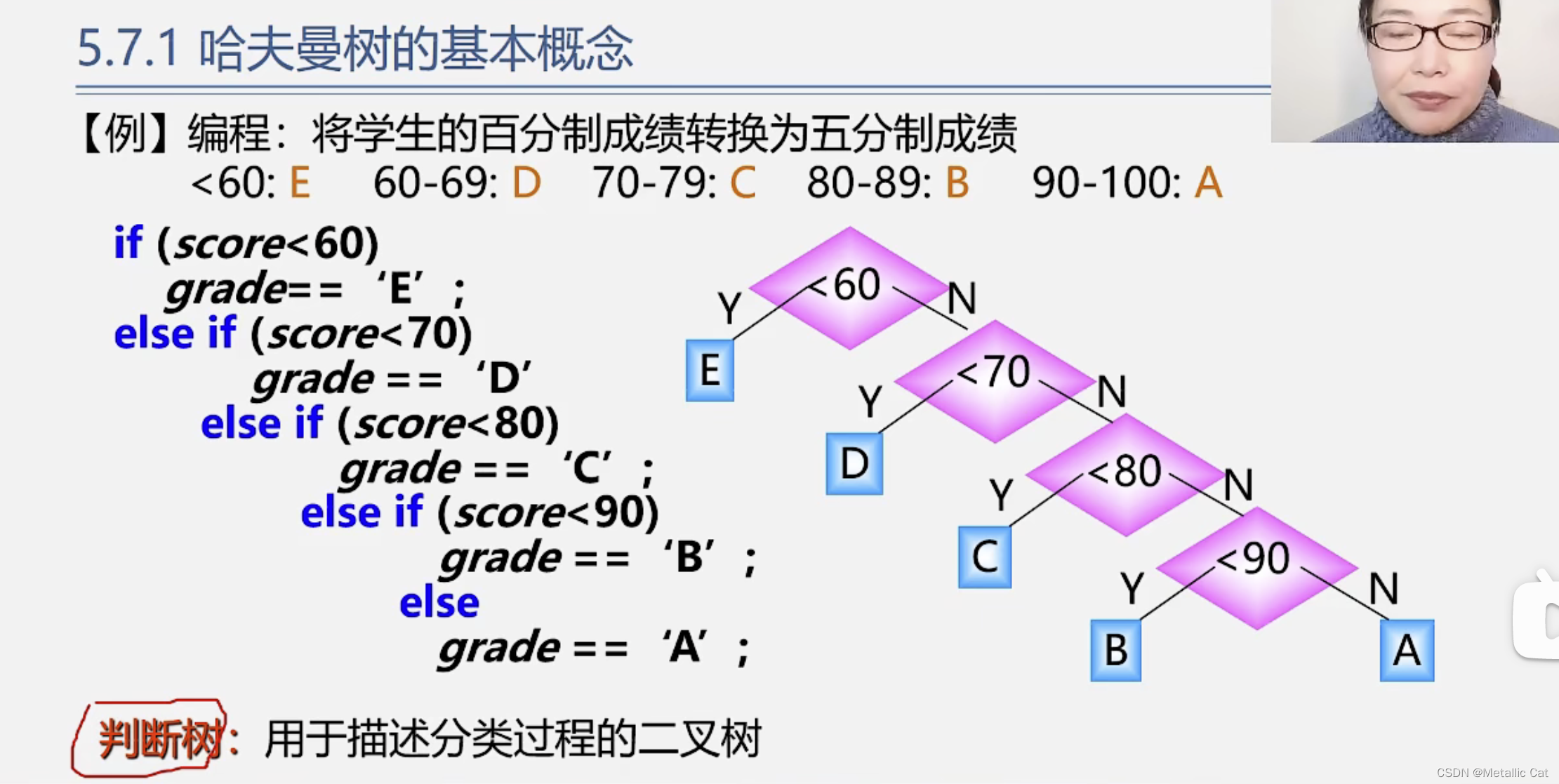
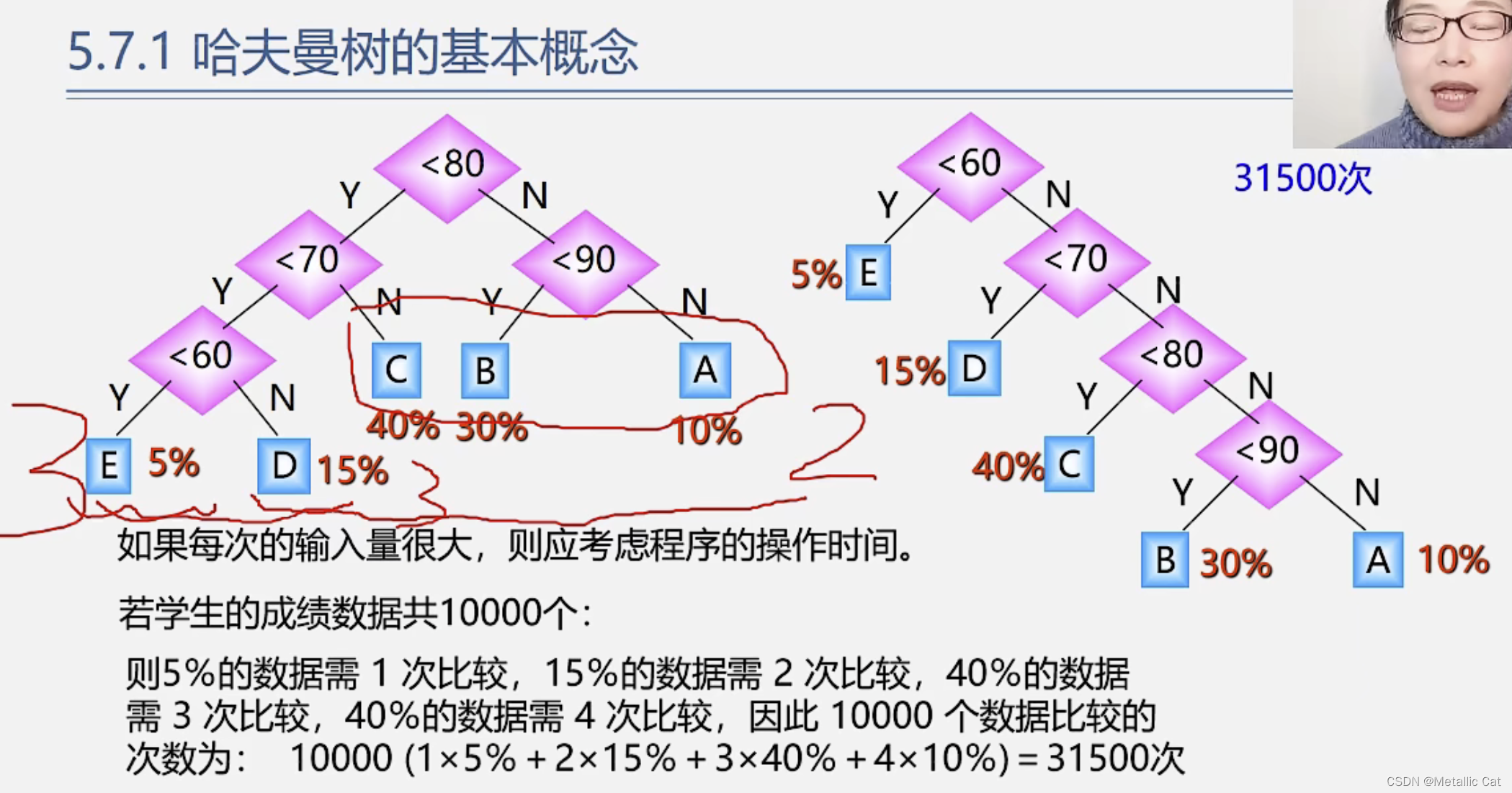
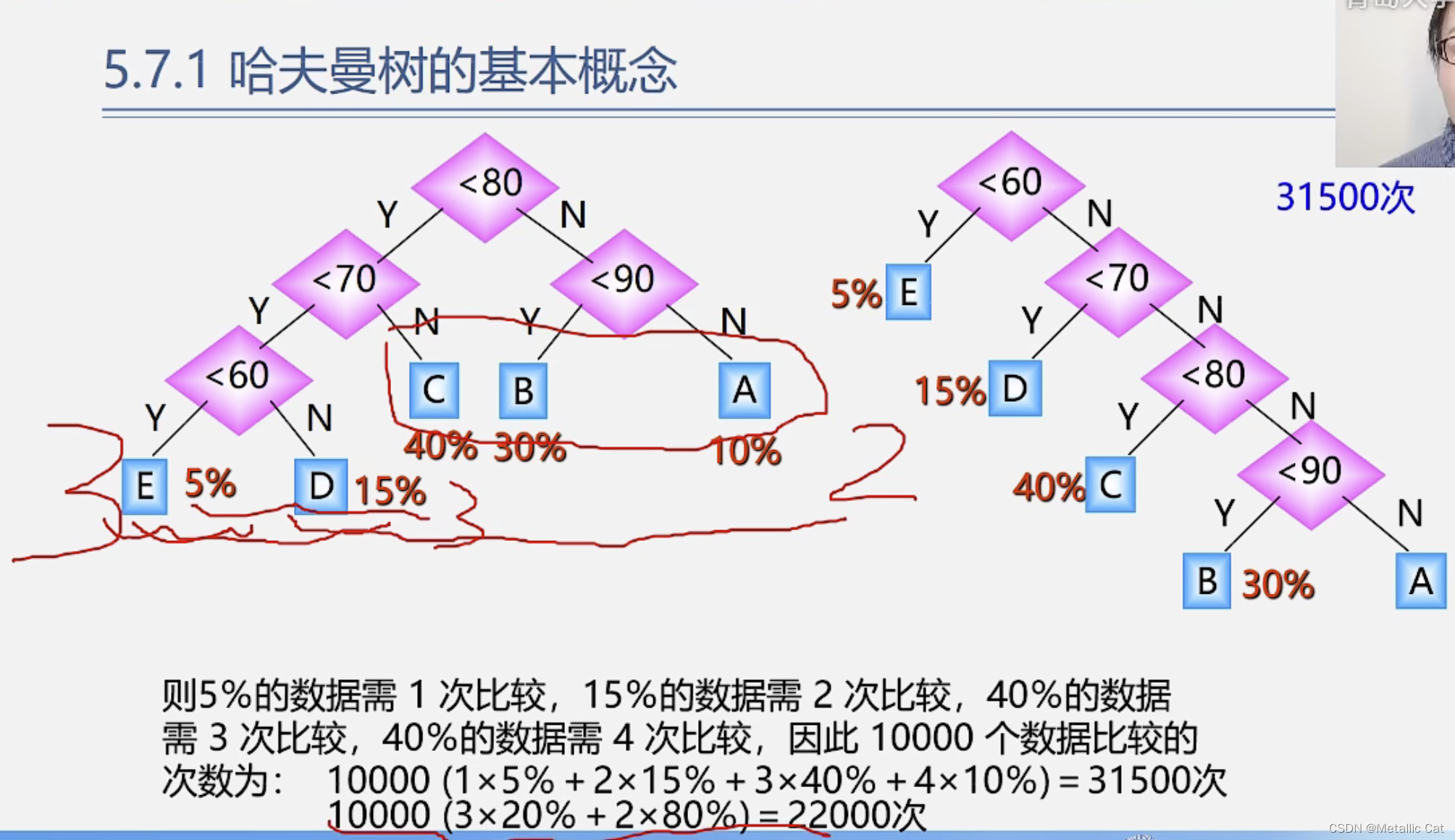
对一个判断树的判断次序进行改变后判断的总次数就可能截然不同
如上图,在面对一万个数据的时候,左边的判断树的判断总次数为22000次,右边的判断树的判断总次数为31500次,效率高了接近三分之一

效率最高的判别树又称为最优二叉树(哈夫曼树)-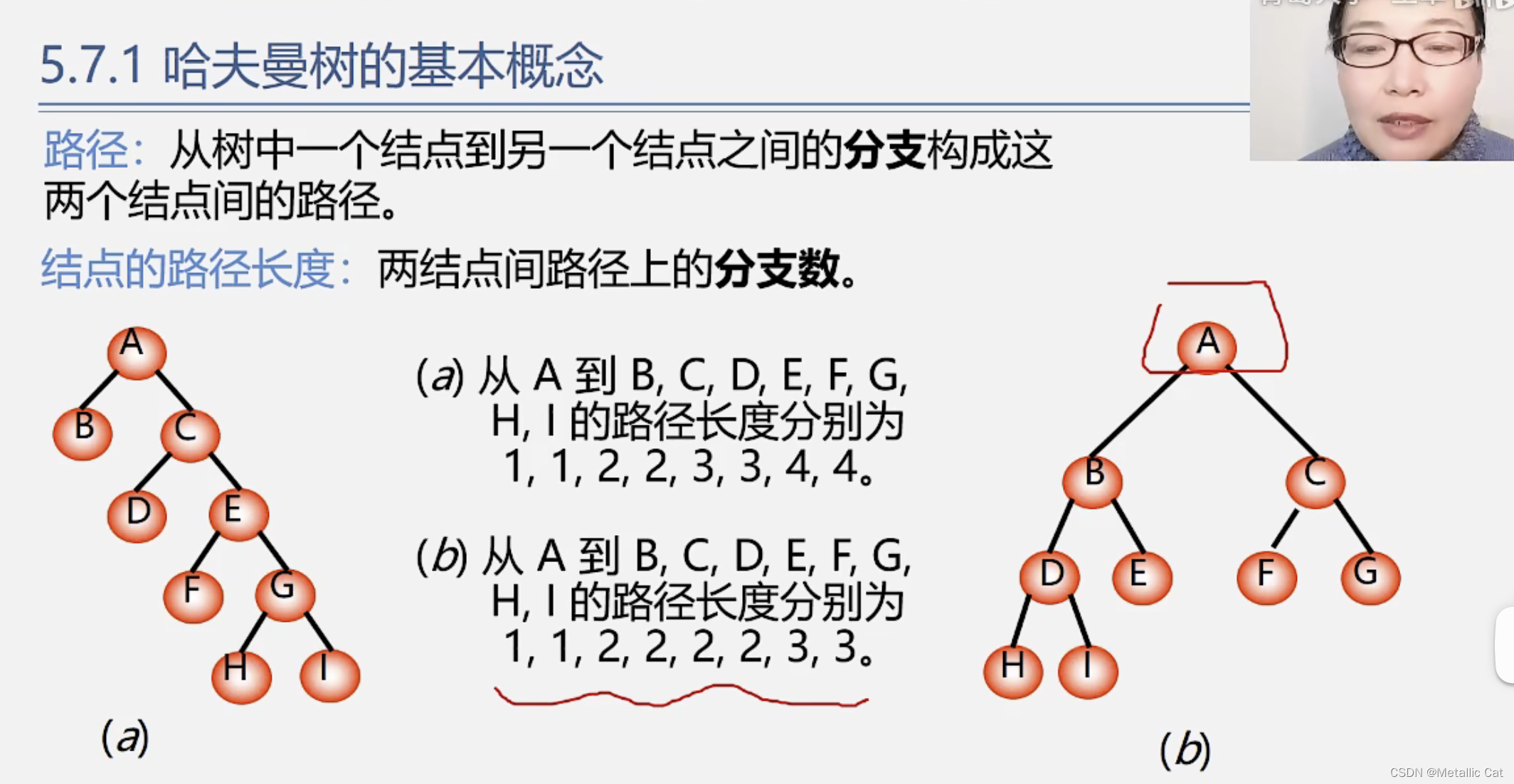
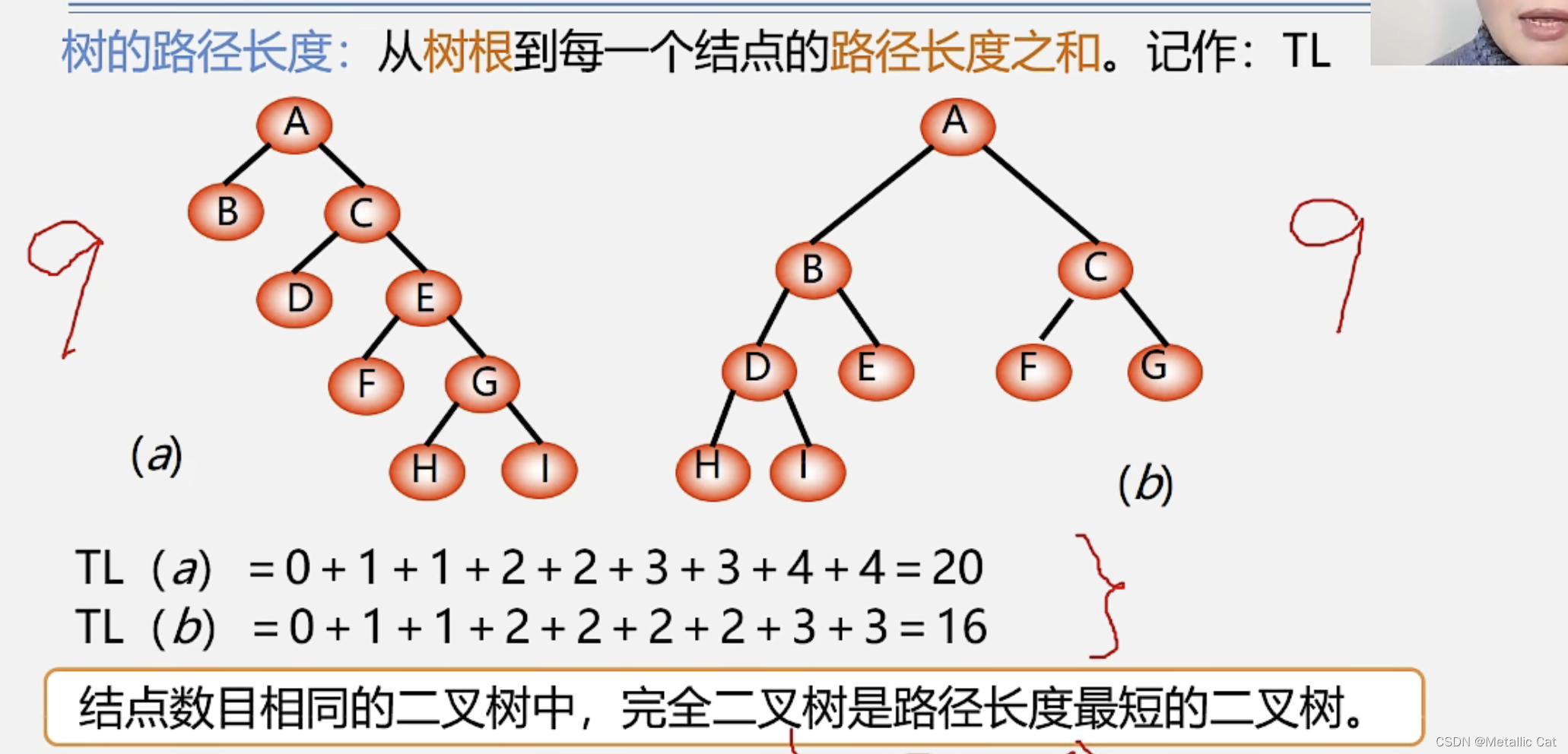
1.从树的根结点到树中的每一个结点的路径长度之和等于树的路径长度
2.关键点来了:完全二叉树是结点数目相同的二叉树中,路径长度最短的二叉树,但这只是一个充分条件,有完全二叉树就有这个条件,但是没有完全二叉树不一定没有这个条件(不满足必要性)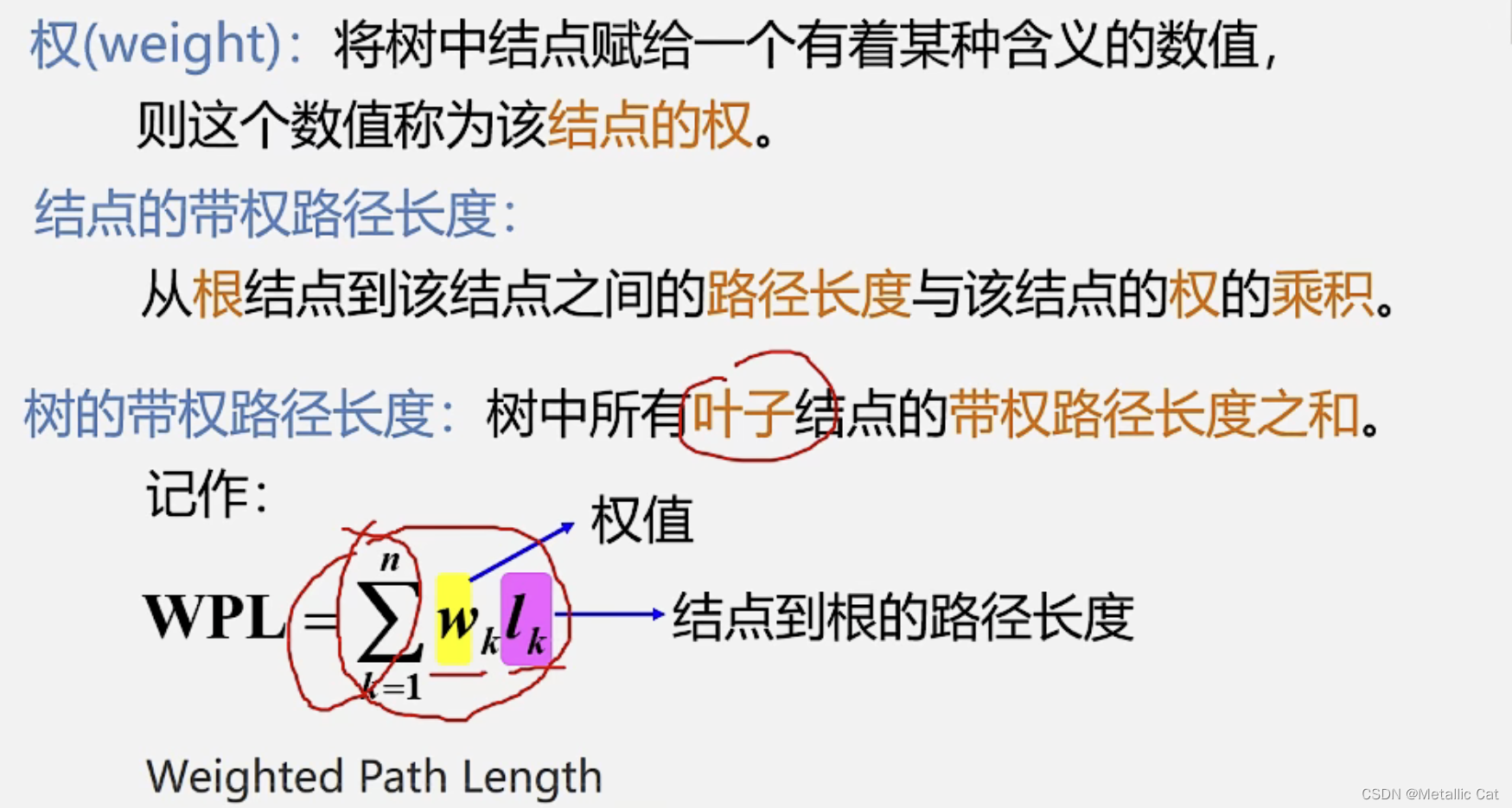
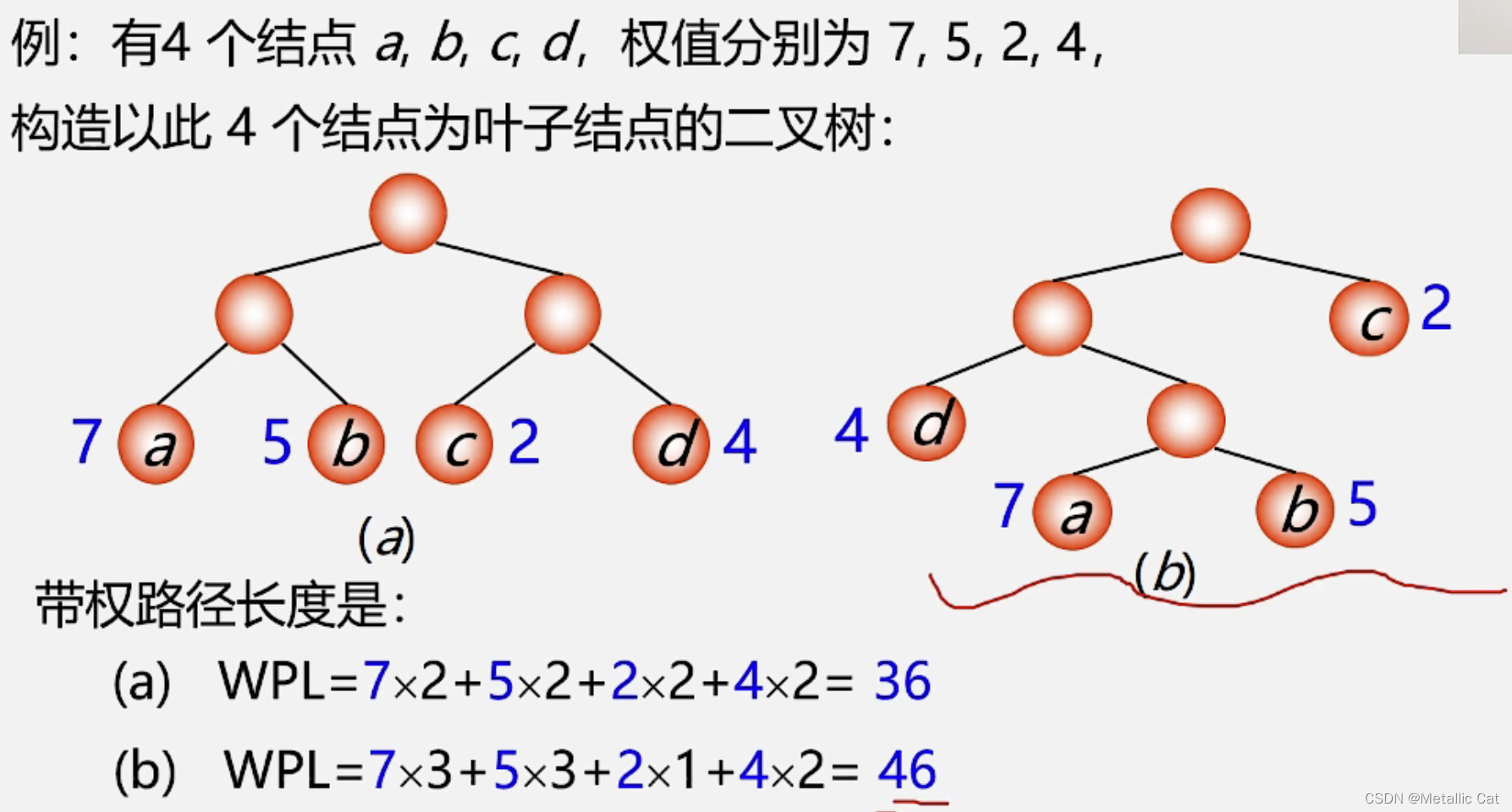

1.最优树这个最优是在度相同的树中比较出来的,比如最优二叉树,最优三叉树等等,而二叉树和三叉树这种度不相同的树之间是无法比较出最优的
在相同度的树中,最优树可能有多个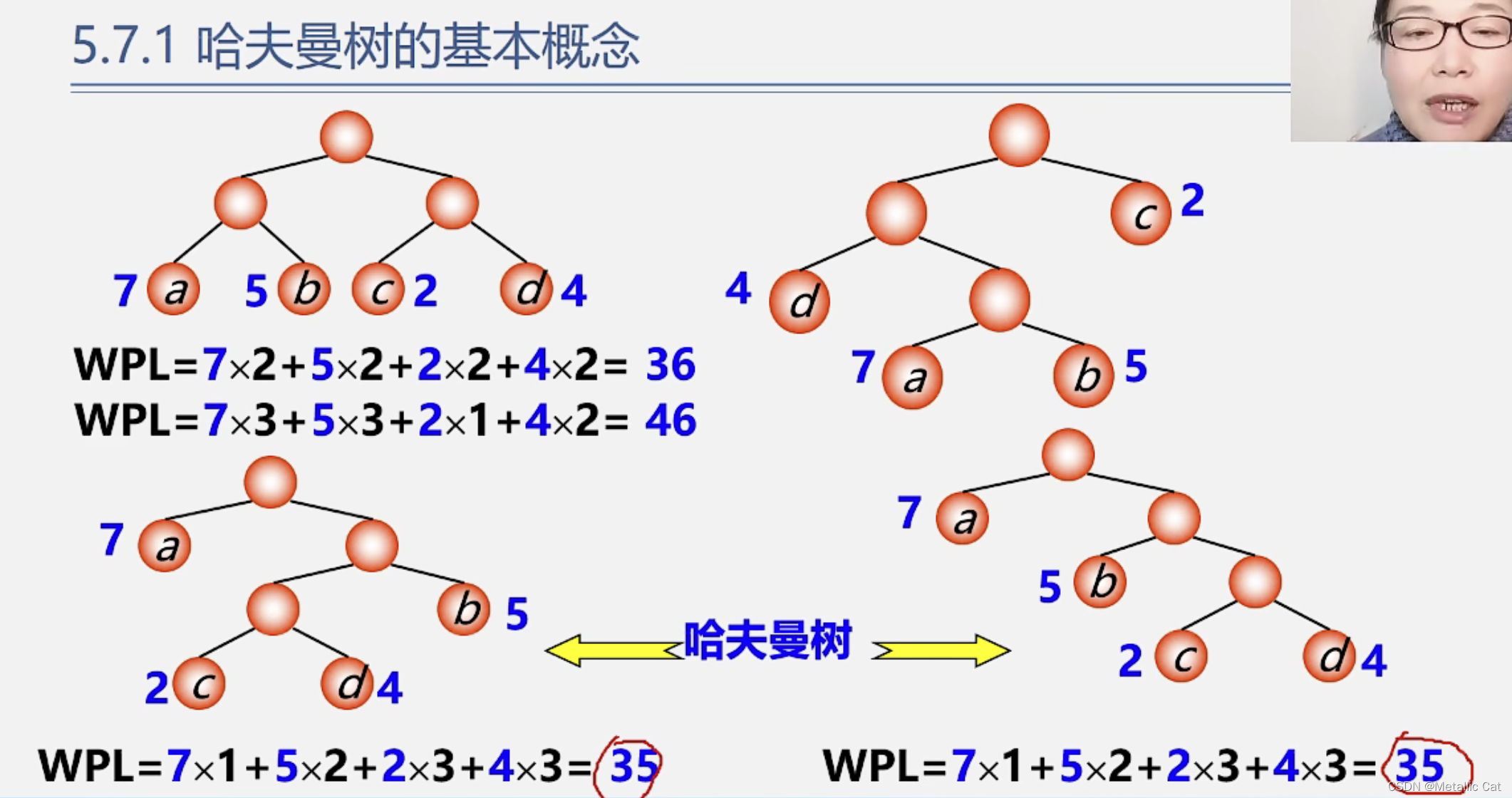
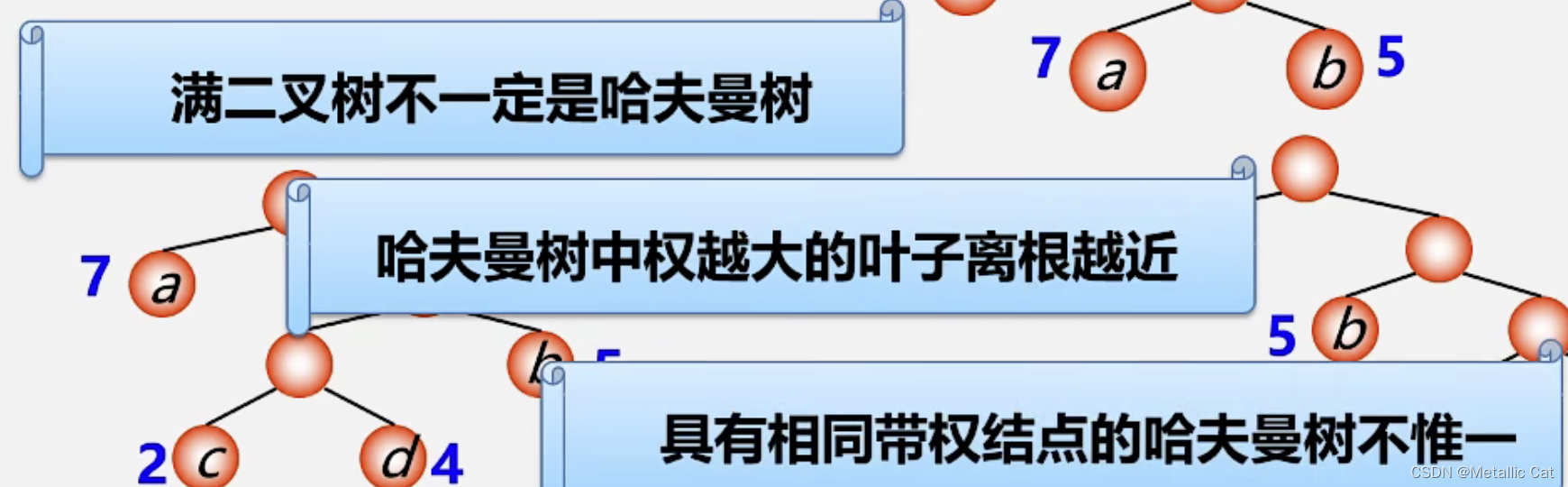
1.注意:树的带权路径长度是树的所有叶子的带权路径长度之和
2.上面最后一点的意思是具有相同带权结点的最优树(哈夫曼树)不唯一
第二部分 --- 哈夫曼树的构造算法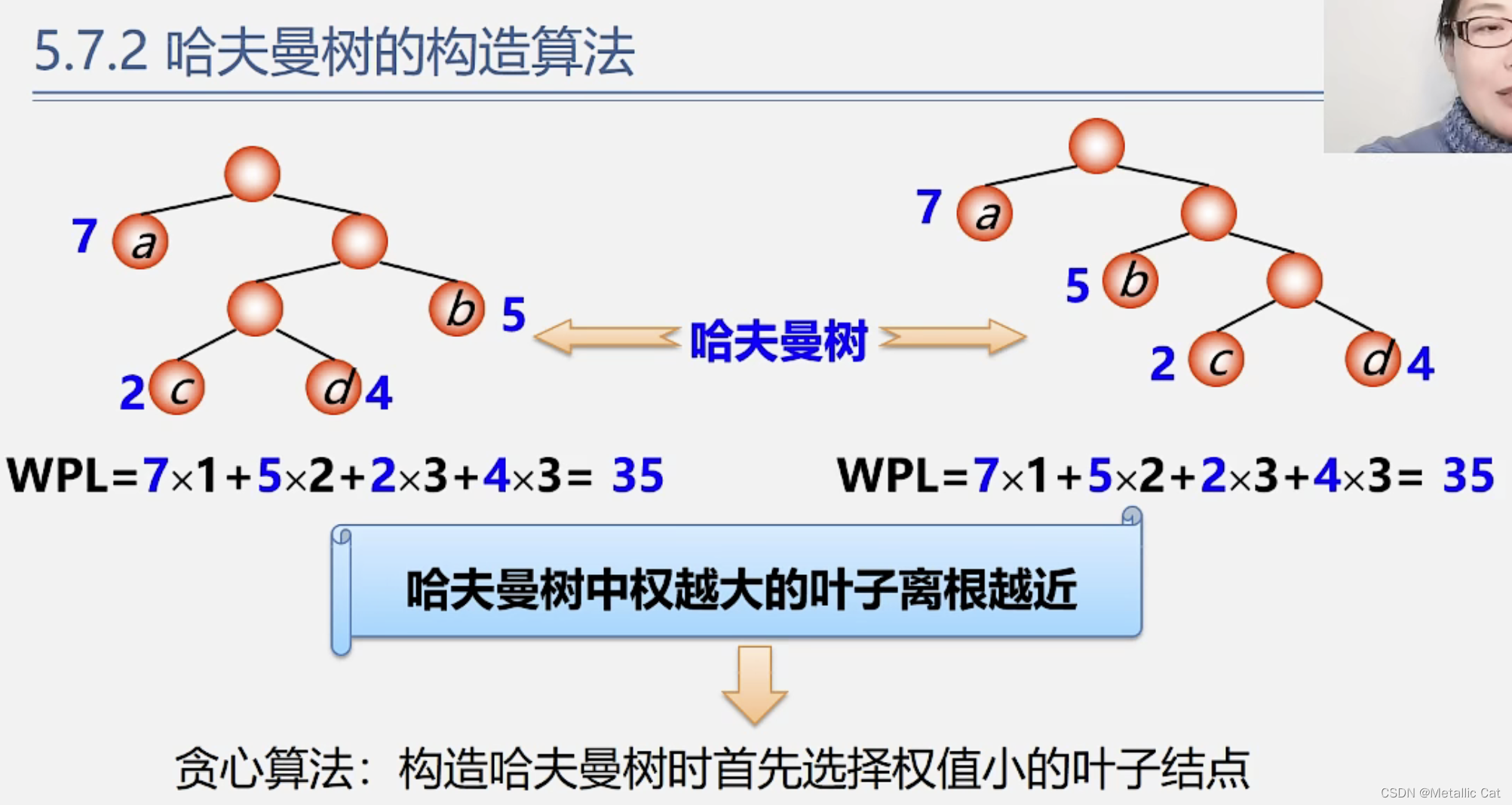
先用权重小叶子构造二叉树,然后再用权重大的叶子构造二叉树,保证权重大的叶子离根近,权重小的叶子离根远
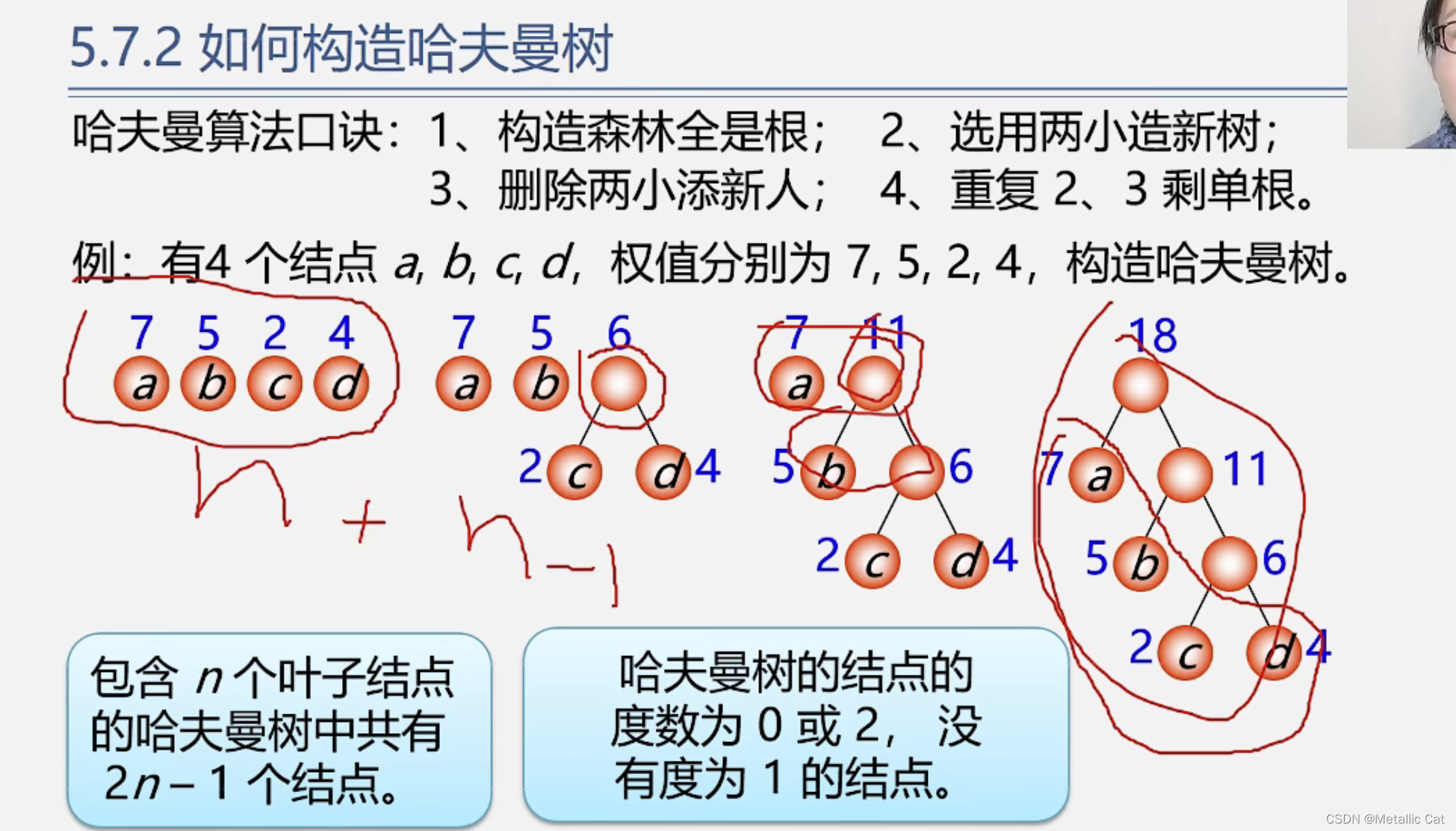
1.右边蓝色框的结论可由哈夫曼树的构造过程来解释:由于我们是“选用两小造新树”,所以新树的根结点有且只有两个子树(度数为2)

第三部分 --- 哈夫曼树构造算法的实现
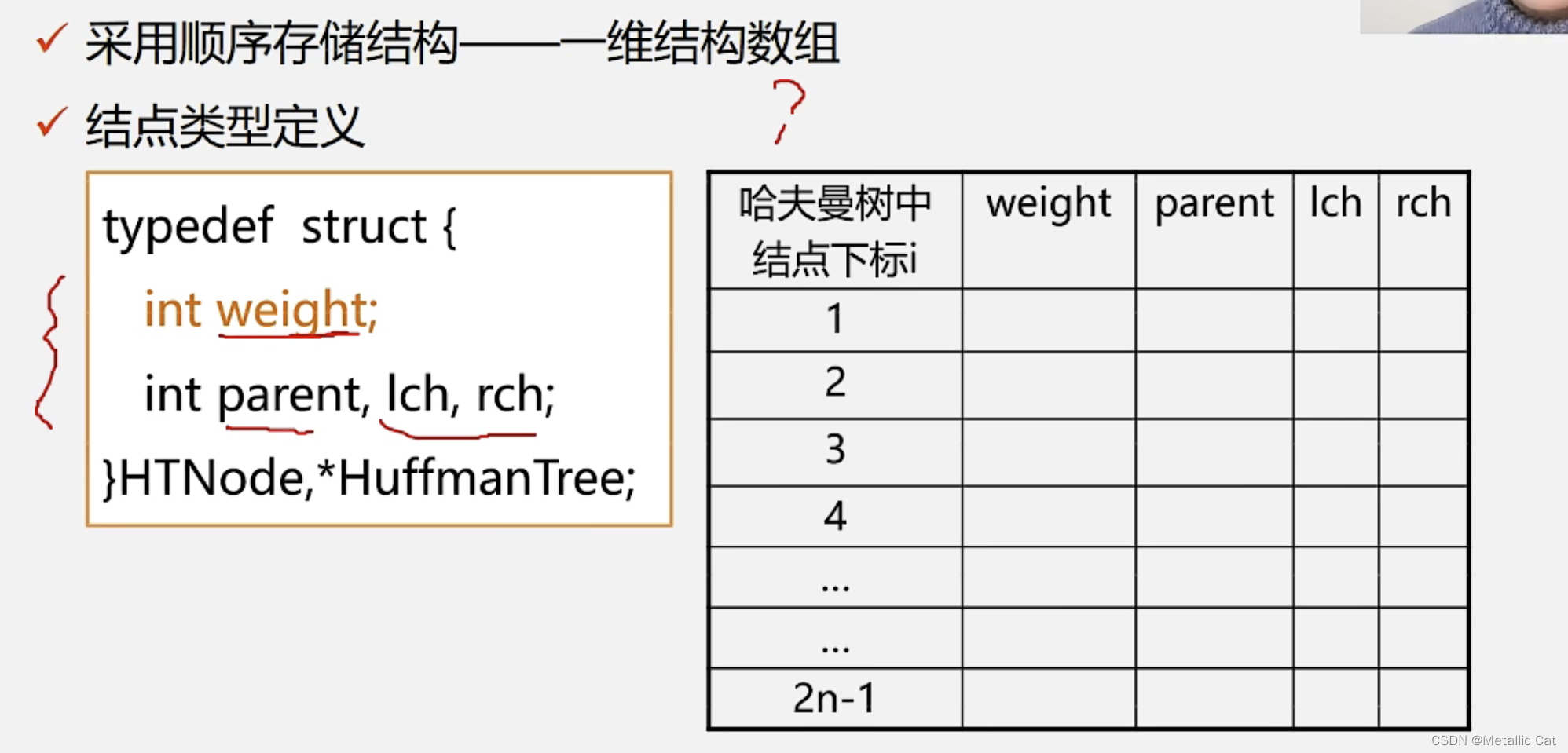
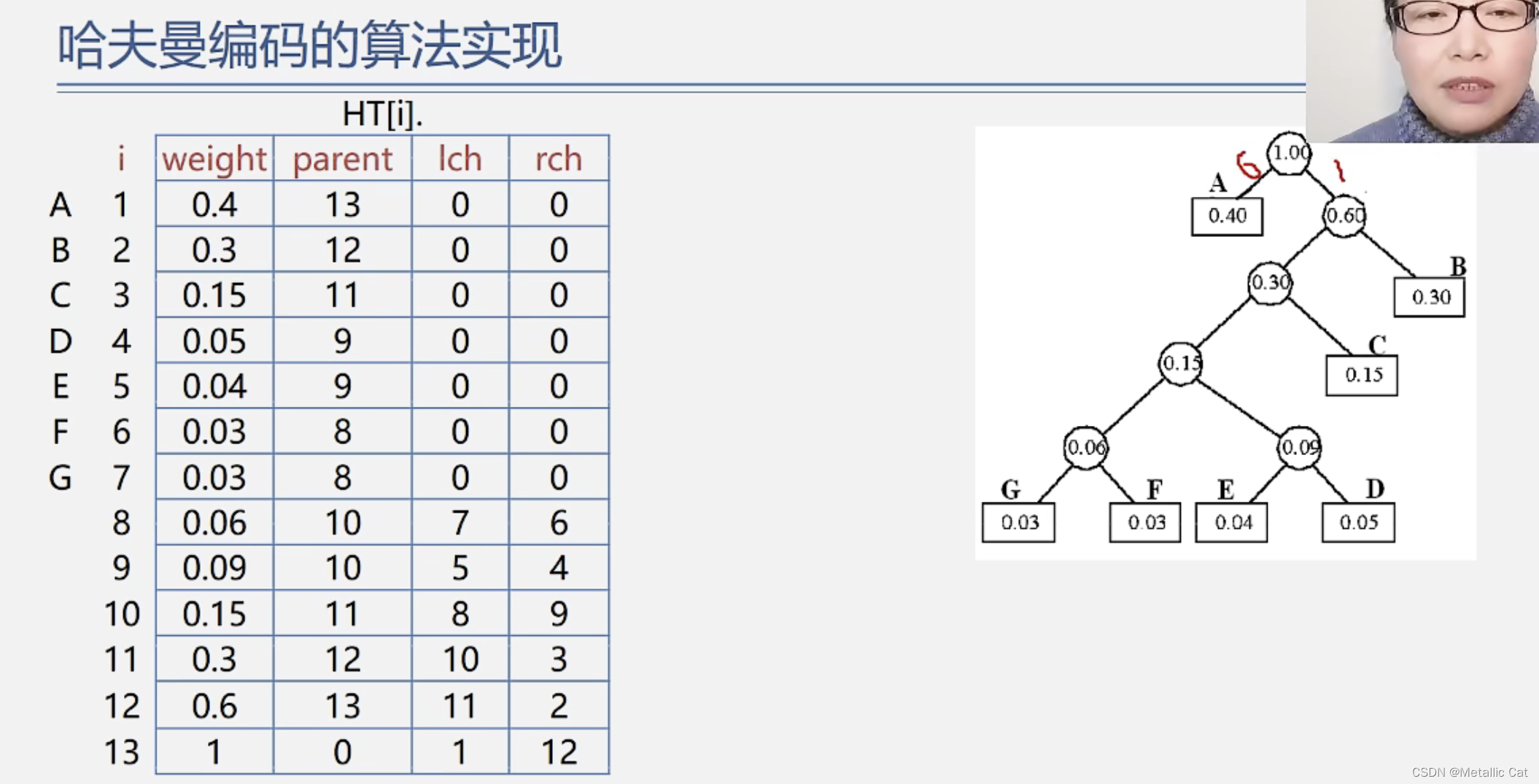
1.用顺序表存储哈夫曼树的时候我们需要一个一维结构数组(数组中的元素是结构体)
2.这个结构体元素中包含四个部分:结点的权重,结点的双亲结点在数组中的下标,结点的左孩子在数组中的下标和右孩子在数组中的下标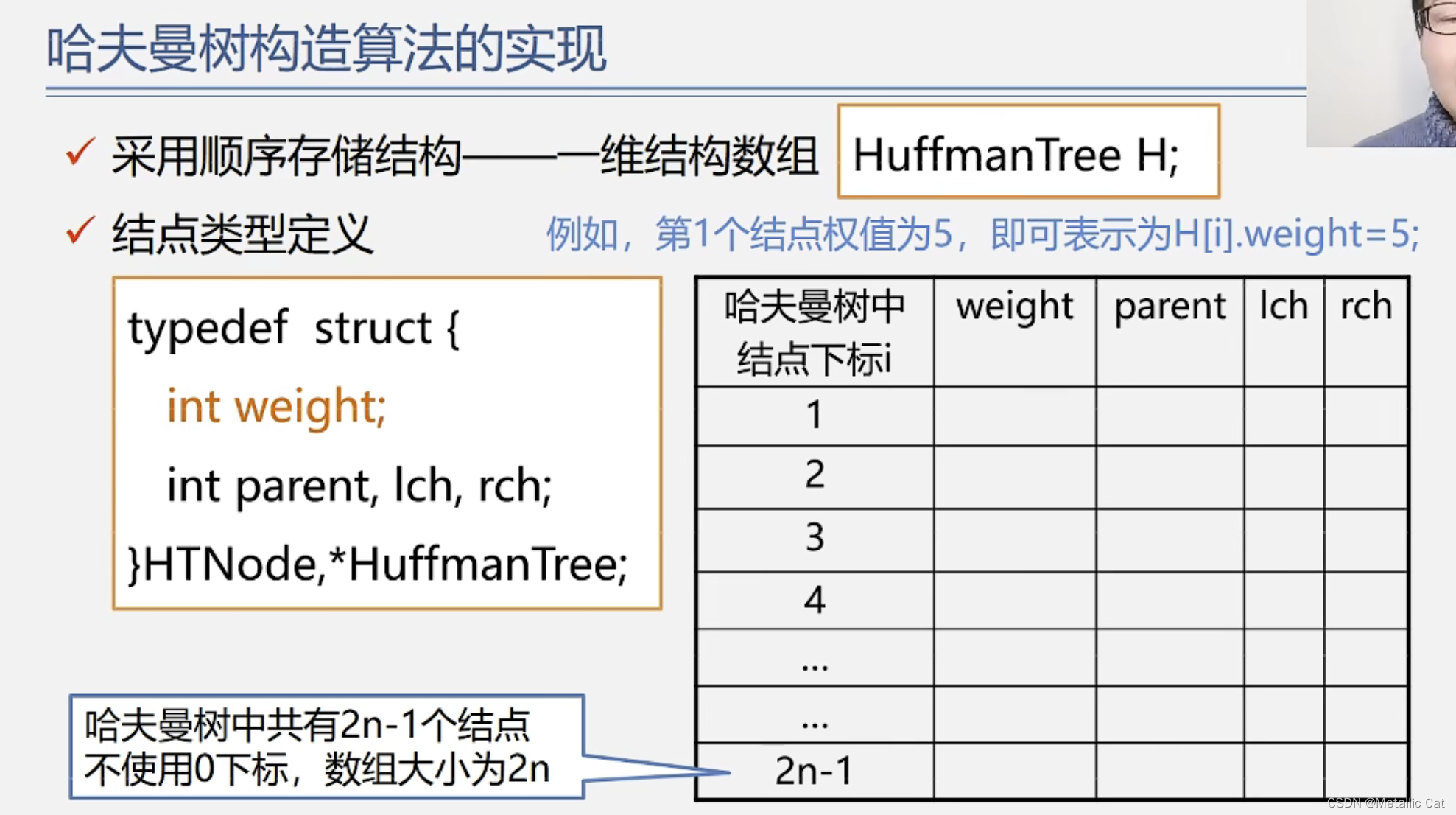
我们创建的用来存储哈夫曼树的数组的大小为2n,数组中下标为0的位置不使用,我们从下标为1的位置开始存储元素。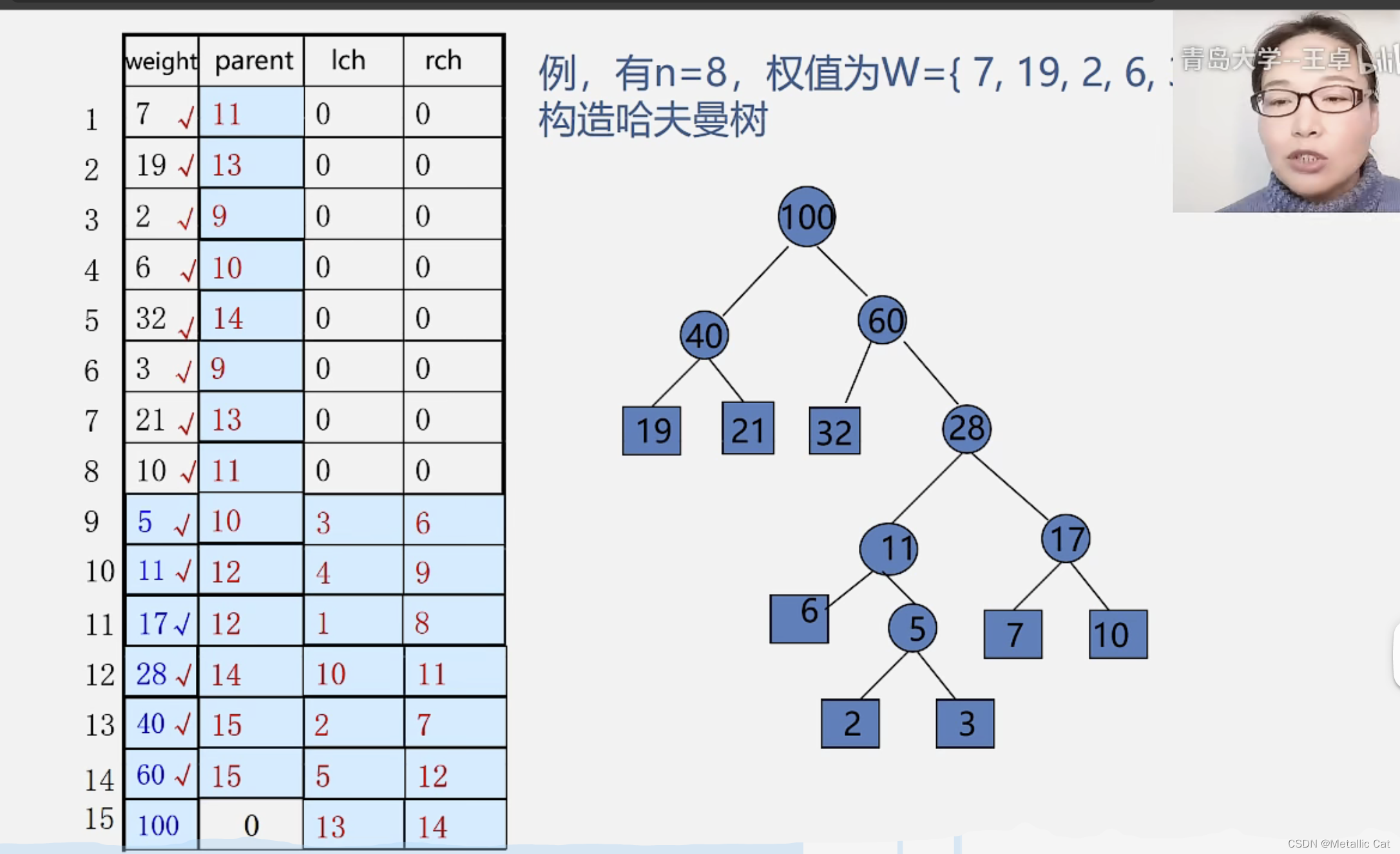
1.第一步将所有已知权重的结点存到顺序表中(构建所有树都是根结点的森林)
2.第二步在没有双亲结点的结点中选择权重最小的两个结点,构造二叉树。
将这个二叉树的根结点(根结点的权重值是选择的两个结点的权重值之和)存储到数组中
3.将选择的两个结点的双亲结点下标从0改为我们新存入的结点在数组中的下标,以及将我们存入到数组中的结点的左右孩子下标由0分别改为我们选择的两个结点在数组中的下标
4.重复2,3步,直到数组中下标为2n - 1的位置也存储了元素为止

第四部分 --- 哈夫曼树的应用
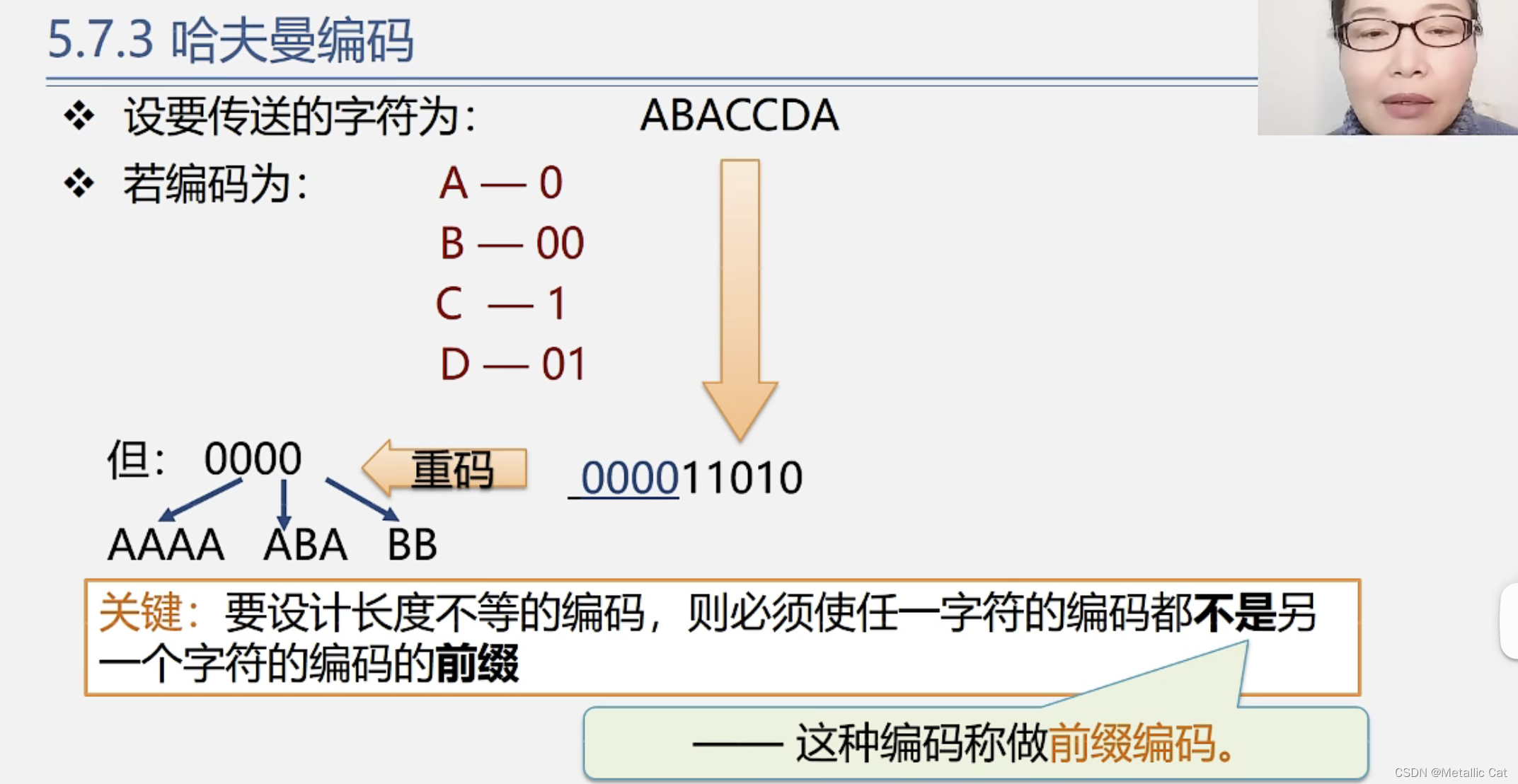
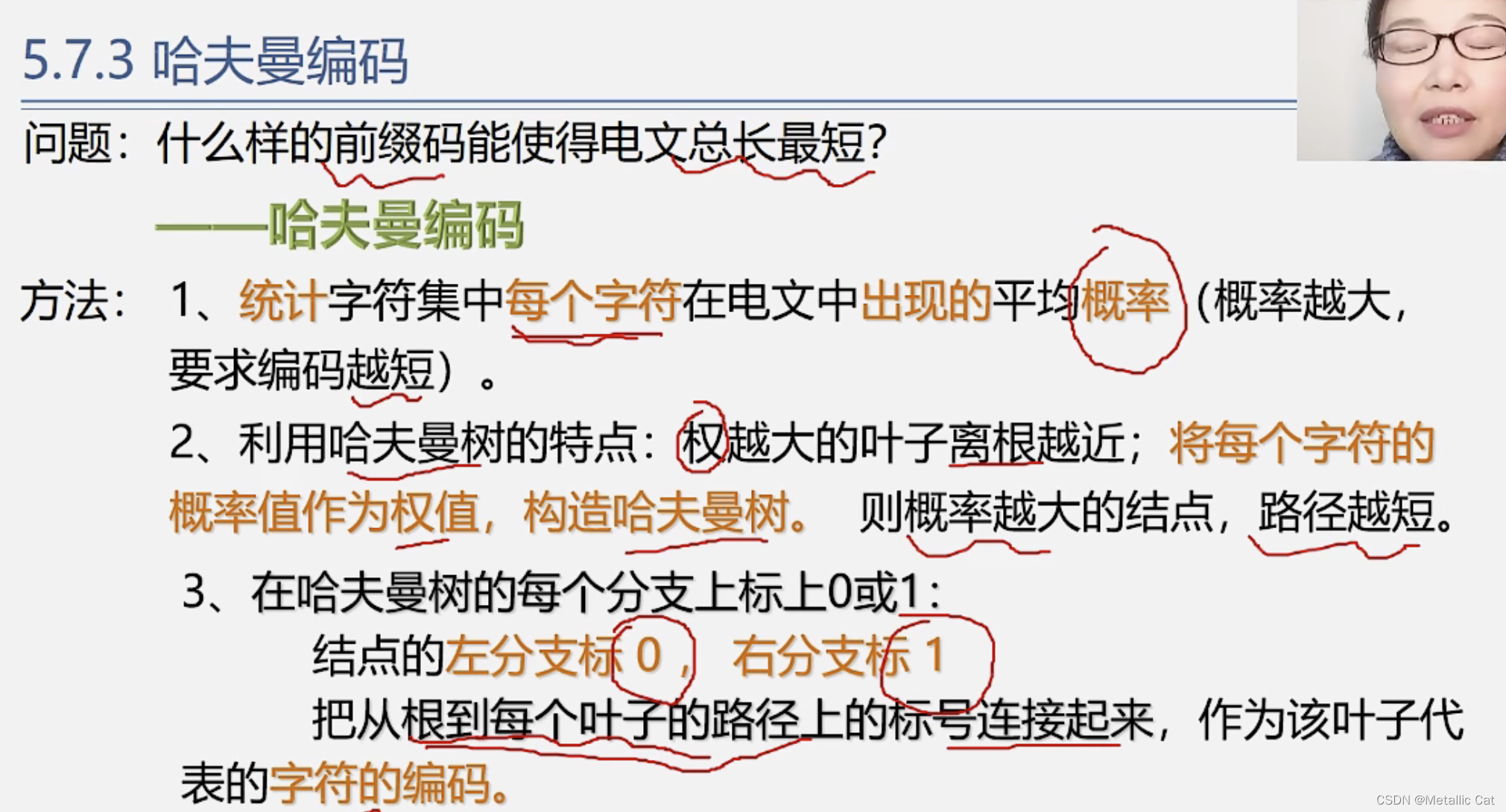
1.怎样编码才能够使得不等长编码即是前缀编码,且还让编码总长度最短呢?
答案就是哈夫曼编码 --- 哈夫曼编码是左分支为0,右分支为1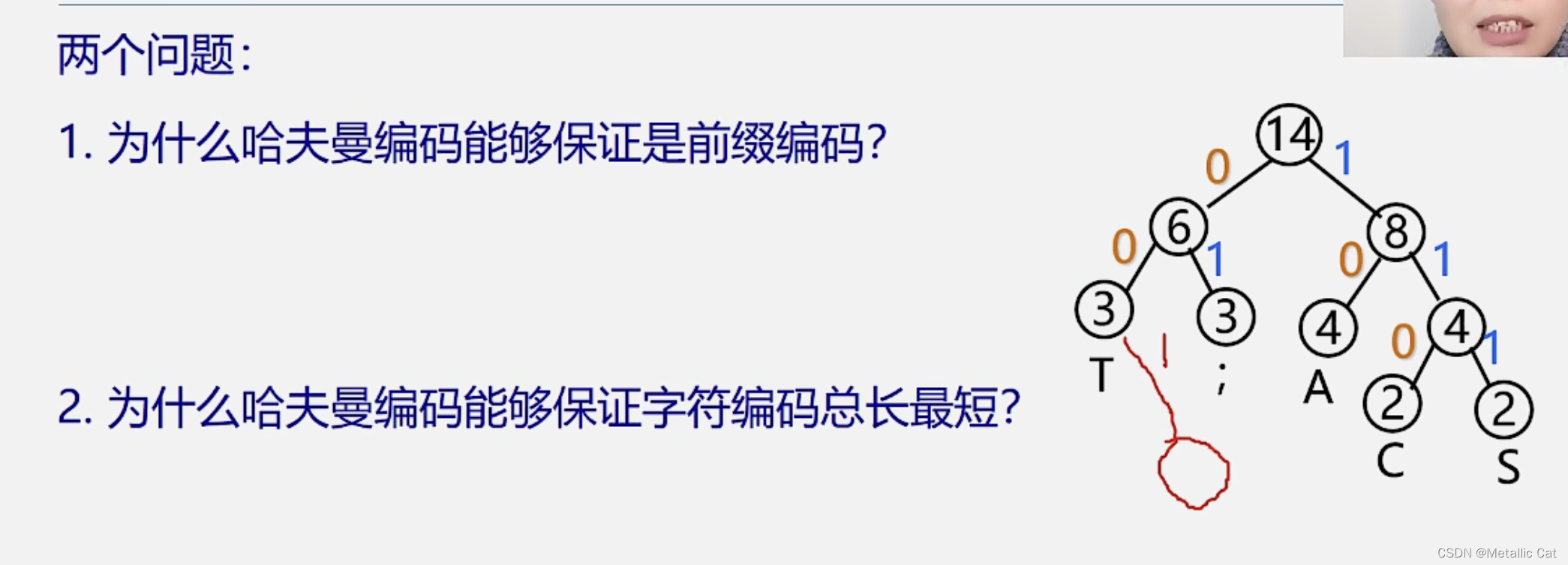
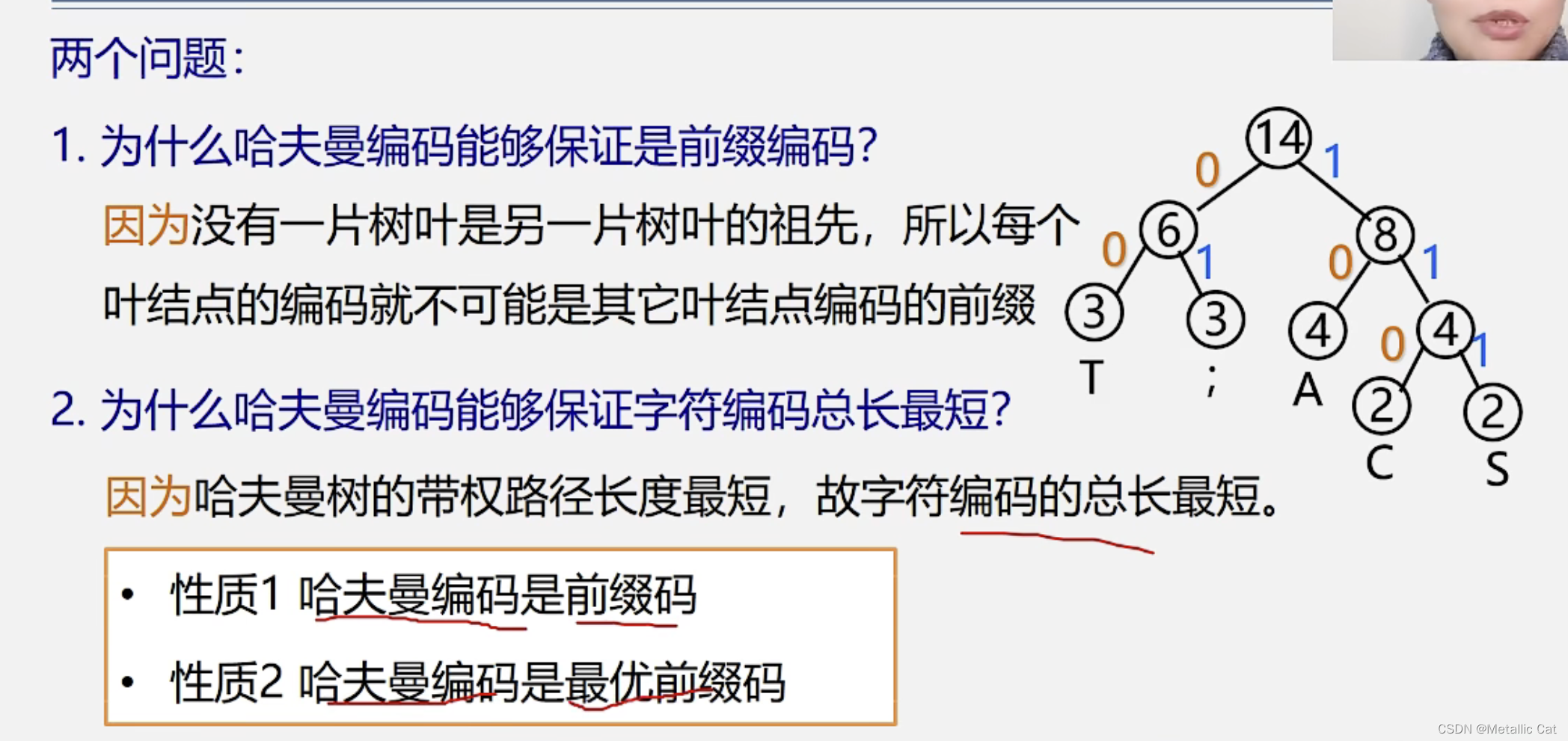
1.如果非等长编码是前缀编码的话,就表示不存在字符A的编码是另一个字符B的编码的前缀,反映到树中就是当我们在到达字符B对应的结点的时候一定不会先经过字符A对应的结点,而当我们将要编码的字符作为哈夫曼树的叶子结点时,就符合这个条件
所以通过哈夫曼树得到的哈夫曼编码一定是前缀编码(通过其它树也是一样,只要保证要编码的字符是树的叶子结点就可以)
2.哈夫曼树是同结点的树中,带权路径长度最小的树,而总编码次数 = 总字符数 *(字符出现的频率(权)* 字符的编码长度) = 总字符数 * 树的带权路径长度,总字符数是个常量,而我们通过哈夫曼树得到的则是在同结点的树中的带权路径长度的最小值
1.存储哈夫曼树的数组中的最后一位置存储的一定是哈夫曼树的根结点
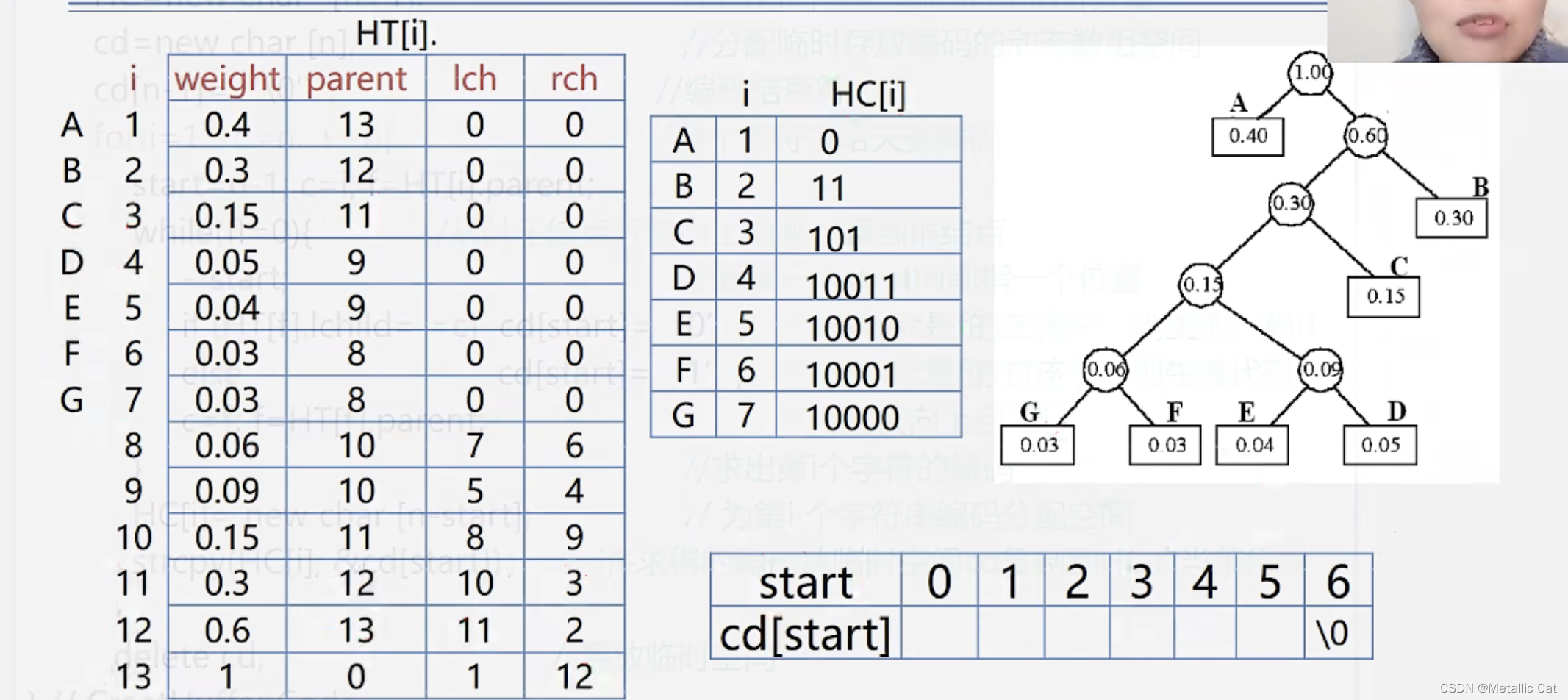
2.哈夫曼编码的算法实现是通过栈来实现的,具体步骤:
一.从我们要找编码的字符对应的叶子结点开始往上找,首先找到叶子结点的双亲结点
二.判断叶子结点是双亲结点的左孩子还是右孩子 --- 左孩子则将0入栈,右孩子则将1入栈
三.找双亲结点的双亲结点,并重复第二步
四.重复二,三步直到出现双亲结点为空时停止寻找(到达根结点了)
五.将栈中元素出栈,出栈后得到的编码就是我们的字符要找的编码
(哈夫曼树关于文件的编码和解码的应用)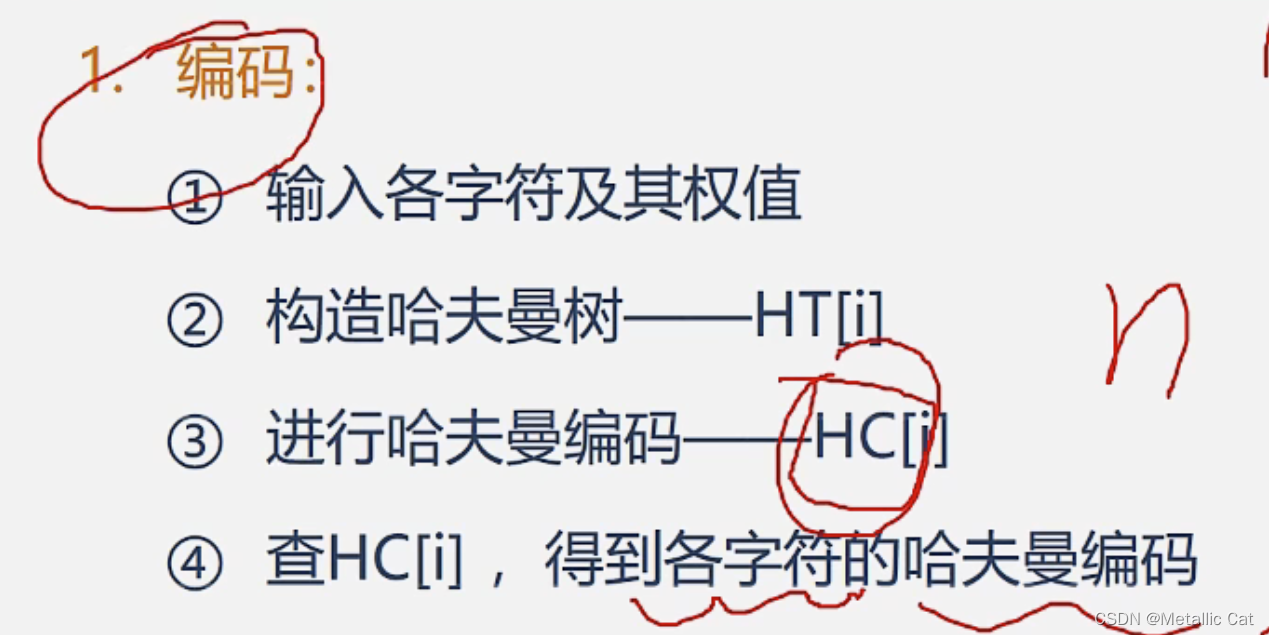

1.指导改为直到
根据给定的字符频度表构造哈夫曼树,然后再通过上面的步骤将进行过编码步骤的文件进行解码















 2928
2928











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









